
词法分析器是编译器的前端,作用是将源代码的字符串分解成具有独立意义的最小单位,也就是计算机所认识的单词。这篇文章中,通过一个实验报告来明确这个词法分析器的需求,然后带大家通过代码的方式来实现一个简单的词法分析器(另一个方法是通过flex自动生成词法分析器)。
一、实验目的:
通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
二、实验内容
编制一个单词获取程序,从文件输入的源程序中,识别出各个具有独立意义的单词,即关键字、标识符、整数、小数、字符串、分隔符、运算符等七大类。并依次输出各个单词的内部编码及单词符号自身文本串(遇到错误时可显示“Error”,然后跳过错误部分继续显示)。
注意:单词类型大小写不敏感(即不区分大小写)
三、实验要求
1、词法规则
- 关键字: program、const、var、integer、decimal、string、procedure、begin、end 、if、then、else、while、do、call、read、write、not
- 标识符: 字母或“_”打头的由字母、数字串或“_”组成的任意长度的符号串。
- 整数: 数字串。
- 小数: 数字串·数字串
- 字符串: 由一对“”括起来的任意长度的符号串。注意:可以多行。
- 分隔符: {、}、(、)、;、空格
- 运算符: :=、=、<、<=、>、>=、+、-、*、/
2、设计词法分析函数getToken( ),完成以下功能:
- getToken( )每调用一次就分析出一个单词;
- 返回单词类别、单词自身文本串、单词在源文件中的行列号;
3、编写测试程序,反复调用函数getToken ( ),输出单词信息。
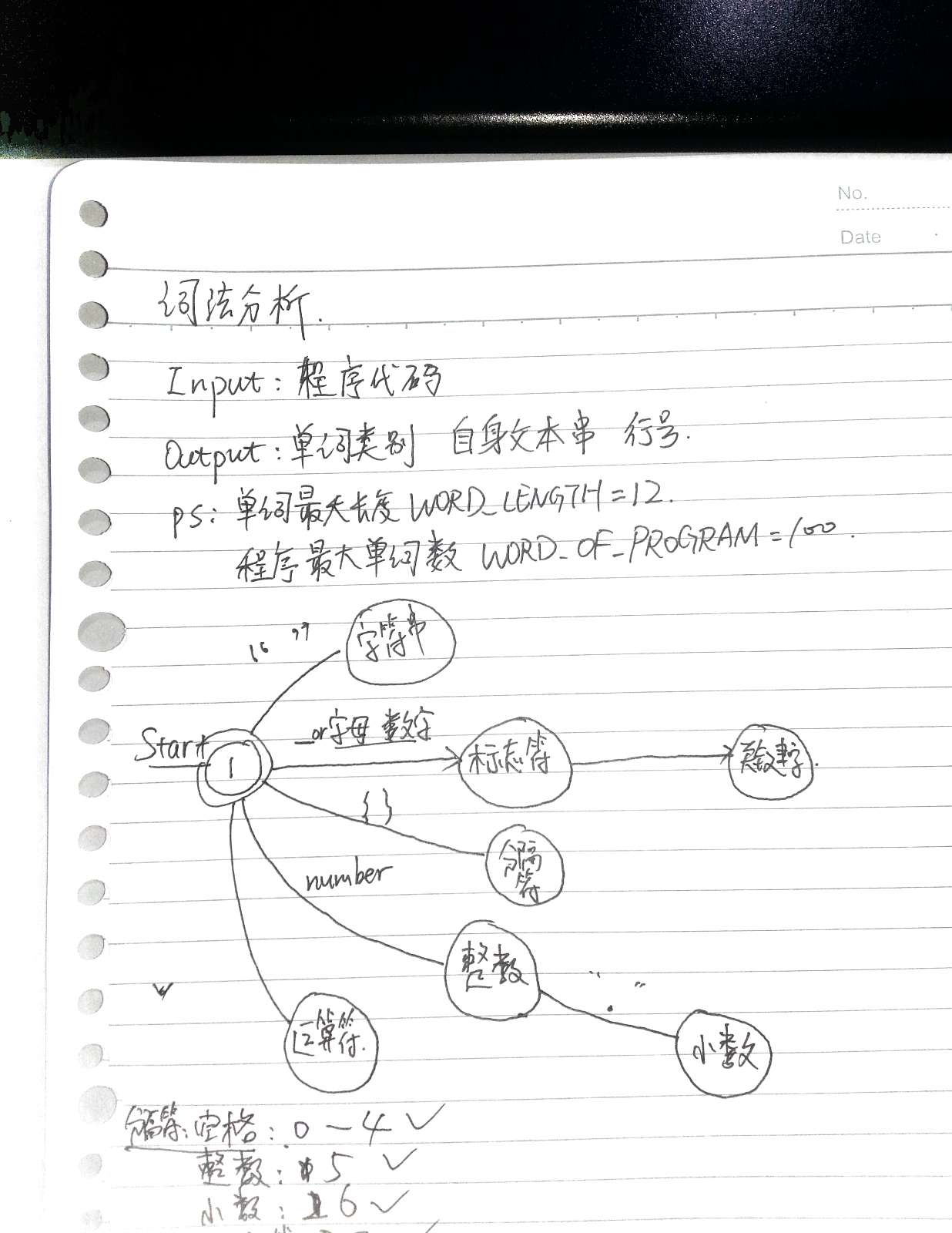
我的实现思路是:
- 先将源程序代码全部读入缓冲区中。这一步可以有三种方法:一个一个字符读,一行一行读,全部读入。其中,1的代码可读性有点差,所以这里不采用。按行读实现起来是最难的,因为要处理换行的字符串问题。全部读入之后,只通过词判断,并没有换行的区别,只要识别出一个单词,就重新开始,识别出下一个单词。
- 调用getToken()从缓冲区的第一个字符开始,按照上图的状态转换图往后读,直到分析出一个单词;
- 输出这个单词的判定类别,返回,继续读取一个字符。
源代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 |
#include<stdio.h> #include<string.h> #include<iostream> using namespace std; #define WORD_LENGTH 130 // 单词最大长度 #define WORD_OF_PROGRAM 1000 //最大单词数 char prog[WORD_OF_PROGRAM*WORD_LENGTH],token[WORD_LENGTH]; char ch; int syn,p,m=0,n,row; double sum =0; //类型为整数或者小数的时候,用于保存源数据 int syn_of_rwtab; //遍历关键字数组 int locate_line; //单词在行中的位置 char *rwtab[18]={"program","const","var","integer", "decimal","string","procedure","begin", "end ","if","then","else","while","do", "call","read","write","not"}; //保存关键字 void getToken(){ /* 这里一共有7类,每一类都有一个if判断 */ for(n=0;n<WORD_LENGTH;n++) token[n]=NULL; ch=prog[p++]; //****************第6类 分隔符***********************************// if(ch==' '||ch==';'|| ch=='{'||ch=='}'|| ch=='('||ch==')'){ syn = 6; token[0] = ch; } //***************2 标识符 1 关键字*********************************// else if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||ch=='_') //可能是标示符或者变量名 { m=0; while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||ch=='_') { token[m++]=ch; ch=prog[p++]; } token[m++]='\0'; p--; syn=2; for(n=0;n<18;n++) //将识别出来的字符和已定义的标示符作比较, if(strcmp(token,rwtab[n])==0) { syn=1; syn_of_rwtab=n; break; } } //*****************3 整数 4小数********************************// else if((ch>='0'&&ch<='9')) { bool flag = false; //是否是小数 sum=0; while((ch>='0'&&ch<='9')) { sum=sum*10+ch-'0'; ch=prog[p++]; } if(ch=='.'){ flag = true; ch=prog[p++]; double tag = 0.1; //记录小数的位数 while((ch>='0' && ch<='9')){ sum+=(ch-'0')*tag; tag=tag*0.1; ch=prog[p++]; } }//if p--; if(flag) syn = 4; else syn = 3; if(sum>32767) syn=-1; } //********************5 判断是不是字符串****************************// else if(ch=='\"'){ syn = 5; m=0; token[m++] = ch; while((ch=prog[p++])!='\"') token[m++] = ch; token[m] = ch; // p--; } //*******************7 运算符*******************// else switch(ch) { case'<': m=0; token[m++]=ch; ch=prog[p++]; if(ch=='>') { syn=7; token[m++]=ch; } else if(ch=='=') { syn=7; token[m++]=ch; } else { syn=7; p--; } break; case'>': m=0; token[m++]=ch; ch=prog[p++]; if(ch=='=') { syn=7; token[m++]=ch; } else { syn=7; p--; } break; case':': m=0;token[m++]=ch; ch=prog[p++]; if(ch=='=') { syn=7; token[m++]=ch; } else { syn=7; p--; } break; case'*':syn=7;token[0]=ch;break; case'/':syn=7;token[0]=ch;break; case'+':syn=7;token[0]=ch;break; case'-':syn=7;token[0]=ch;break; case'=':syn=7;token[0]=ch;break; case'#':syn=0;token[0]=ch;break; case'\n':syn=-2;locate_line=0;break; default: syn=-1;break; } } int main() { p=0; row=1; cout<<"Please input string:"<<endl; do { cin.get(ch); prog[p++]=ch; } while(ch!='#'); int temp = 0; //不区分大小写,全部转换成小写。 while(prog[temp]!='#'){ if(prog[temp]<='Z' && prog[temp]>='A') prog[temp]+='a'-'A'; temp++; } p=0; do { getToken(); locate_line++; switch(syn) { case 1: cout<<row<<" "<<locate_line<<" "<<"("<<syn<<","<<rwtab[syn_of_rwtab]<<")"<<endl;break; case 2: cout<<row<<" "<<locate_line<<" "<<"("<<syn<<","<<token<<")"<<endl; break; case 5: cout<<row<<" "<<locate_line<<" "<<"("<<syn<<","<<token<<")"<<endl; break; case 6: cout<<row<<" "<<locate_line<<" "<<"("<<syn<<","<<token[0]<<")"<<endl; break; case 3: cout<<row<<" "<<locate_line<<" "<<"("<<syn<<","<<sum<<")"<<endl; break; case 4: cout<<row<<" "<<locate_line<<" "<<"("<<syn<<","<<sum<<")"<<endl; break; case -1: cout<<"Error in row "<<row<<"!"<<endl; break; case -2: row=row++;break; } } while (syn!=0); } |
参考:一条鱼、尹雁铃(更详细的词法分析器讲解)