我们需要在一个 VPC 网络环境中采集一些服务的 metrics,TSDB 存储在中心机房中,存储节点、中心节点和采集端的网络是不通的,要访问的话必须开通防火墙配置。网络架构大体如下:
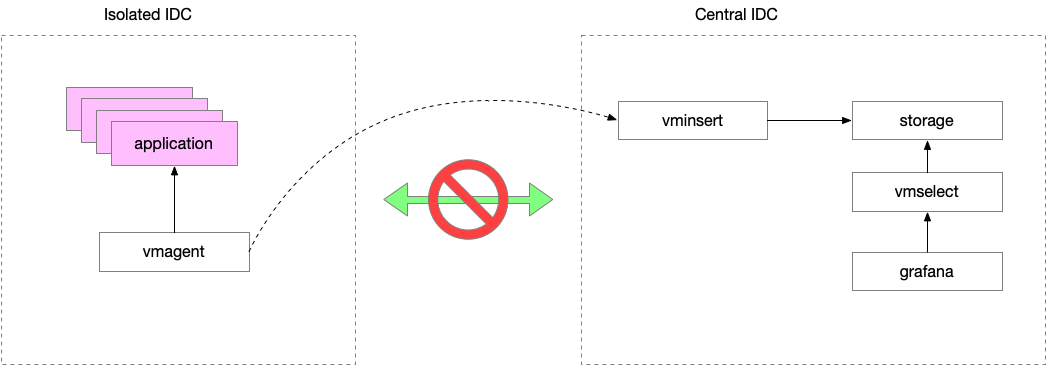
直接从 central 去访问应用的 metrics 暴露端口采集数据,肯定不显示,这样的话要开通的防火墙太多了,也就失去了防火墙的意义。
怎么才能尽可能少的开通防火墙,又保证数据采集呢?
最直观的方法是,直接用 vmagent 部署在 VPC 本地采集数据,采集之后将数据发送到 central 机房。
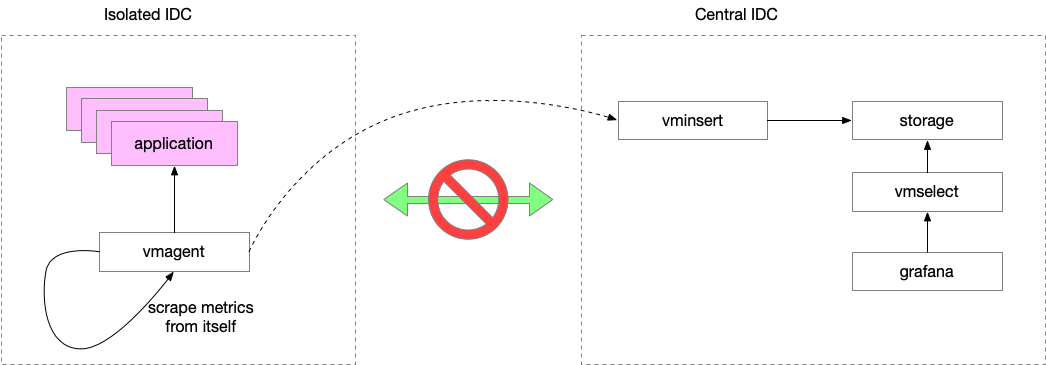
那么又有了一个问题:监控的监控。我们怎么去监控采集端 vmagent 的健康呢?简单的方法是,直接开一个双向的防火墙白名单,我们从 central 直接去监控 vmagent。但是我想到一个方法,可以免掉这个防火墙。
第一步,我们将 vmagent 的采集 target 加入到它自己的采集列表中,即,让它自己收集它自己的 metrics,然后发送到 central。
然后我们再配置 alert,难点就在这里。
Prometheus 触发 alert 的规则是:
- 如果表达式的 evaluate 结果是 null,说明不满足条件,不 fire
- 如果表达式的 evaluate 结果有值,说明满足设定的条件,fire
我们用如上的模式采集 vmagent 的 metrics,就会有这个问题:假如 vmagent 挂了,那么不会有人把 metrics 发回来,也就不会有 prometheus 的 up metric, 如果我们设置一个 alert rule: up < 1 , 也就不会 fire。就遇到了这个问题:没来的请举手。
解决方法是,既然已经确定这个 target 必然会存在,可以将默认值设置为 0,如果有值的话,会被 overwrite 成1.
PromQL 原生的表达式:
|
1 |
(up{instance="10.129.118.111:7429"}OR on() vector(0)) < 1 |
MetricsQL:
|
1 |
(up{instance="10.129.118.110:7429"} default 0) < 1 |
这样,只有确定采集端 vmagent 是 up 的时候,才不会触发 alert。
这个查询表达式对 Push 到 Prometheus 的模式也同样适用。
另外还有一个方法可以解决这个问题,就是在 VPC 中搭建两个 vmagent,互相采集对方的 metrics,发送回来。这样有一个缺点,就是如果中间的网络有问题,那么两个 vmagent 就会一起挂掉了,不会有 metrics,也就不会触发 alerts。
参考:
现在可以用 absent() 函数了。 https://prometheus.io/docs/prometheus/latest/querying/functions/#absent
嗯 确实,这个函数可以满足这个场景。谢谢。