教科书介绍的 TCP 内容通常比较基础:包括三次握手,四次挥手,数据发送通过收到 ACK 来保证可靠传输等等。当时我以为已经学会了 TCP,但是后来在工作中,随着接触 TCP 越来越多,我发现很多内容和书上的不一样——现实世界的 TCP 要复杂一些。
我们从一个简单的 HTTP 请求开始。发送一个简单的 HTTP 请求,tcpdump 抓包如下:
|
1 2 3 4 5 6 7 8 9 10 |
04:13:49.438293 IP foobarhost.53422 > 104.244.42.65.http: Flags [S], seq 637381086, win 64240, options [mss 1460,sackOK,TS val 2468293419 ecr 0,nop,wscale 7], length 0 04:13:49.577825 IP 104.244.42.65.http > foobarhost.53422: Flags [S.], seq 1622592001, ack 637381087, win 65535, options [mss 1460], length 0 04:13:49.578004 IP foobarhost.53422 > 104.244.42.65.http: Flags [.], ack 1, win 64240, length 0 04:13:49.578644 IP foobarhost.53422 > 104.244.42.65.http: Flags [P.], seq 1:38, ack 1, win 64240, length 37: HTTP: POST /apikey=1&command=2 HTTP/1.0 04:13:49.579110 IP 104.244.42.65.http > foobarhost.53422: Flags [.], ack 38, win 65535, length 0 04:13:49.702633 IP 104.244.42.65.http > foobarhost.53422: Flags [P.], seq 1:204, ack 38, win 65535, length 203: HTTP: HTTP/1.0 400 Bad Request 04:13:49.702662 IP foobarhost.53422 > 104.244.42.65.http: Flags [.], ack 204, win 64037, length 0 04:13:50.702170 IP 104.244.42.65.http > foobarhost.53422: Flags [F.], seq 204, ack 38, win 65535, length 0 04:13:50.702783 IP foobarhost.53422 > 104.244.42.65.http: Flags [F.], seq 38, ack 205, win 64037, length 0 04:13:50.703525 IP 104.244.42.65.http > foobarhost.53422: Flags [.], ack 39, win 65535, length 0 |
第一个和书上不一样的地方是,TCP 结束连接不是要 4 次挥手吗?为什么这里只出现了 3 次?
|
1 2 3 |
04:13:50.702170 IP 104.244.42.65.http > foobarhost.53422: Flags [F.], seq 204, ack 38, win 65535, length 0 04:13:50.702783 IP foobarhost.53422 > 104.244.42.65.http: Flags [F.], seq 38, ack 205, win 64037, length 0 04:13:50.703525 IP 104.244.42.65.http > foobarhost.53422: Flags [.], ack 39, win 65535, length 0 |
回顾 TCP 的包结构,FIN 和 ACK 其实是不同的 flags,也就是说,理论上我可以在同一个 Segment 中,即可以设置 FIN 也可以同时设置 ACK。
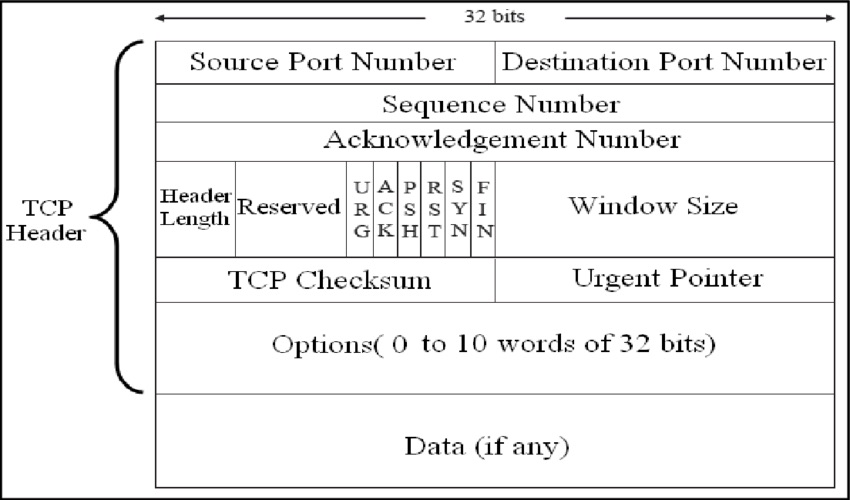
所以如果在结束连接的时候,客户端发送 FIN,这时候服务端一看:“正好我也没有东西要发送了。”于是,除了要 ACK 自己收到的 FIN 之外,也要发送一个 FIN 回去。那不如我一石二鸟,直接用一个包好了。
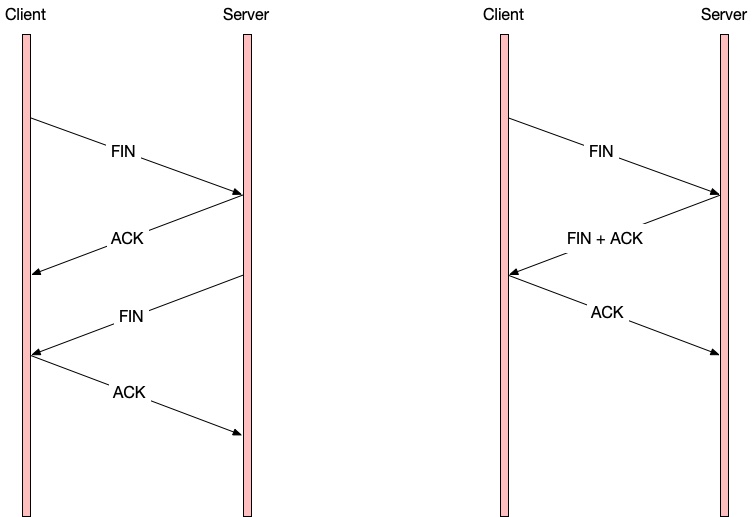
这个例子在 TCP可以使用两次握手建立连接吗? 中详细介绍过。
既然 FIN 可以附带去 ACK 自己收到的 FIN,那么数据是否也可以附带 ACK?也是可以的。
Delay ACK
TCP 是全双工的,意味着两端都可以同时向对方发送数据,而两端又需要分别去 ACK 自己收到的数据。
TCP 的一端在收到数据之后,反正马上也要发送数据回去,与其发送两个包:一个 ACK 和一个数据包,不如不立即发送 ACK 回去,而是等待一段时间——我反正一会要发送数据给你,等到那时候,我再带上 ACK 就好啦。这就是 Delay ACK。
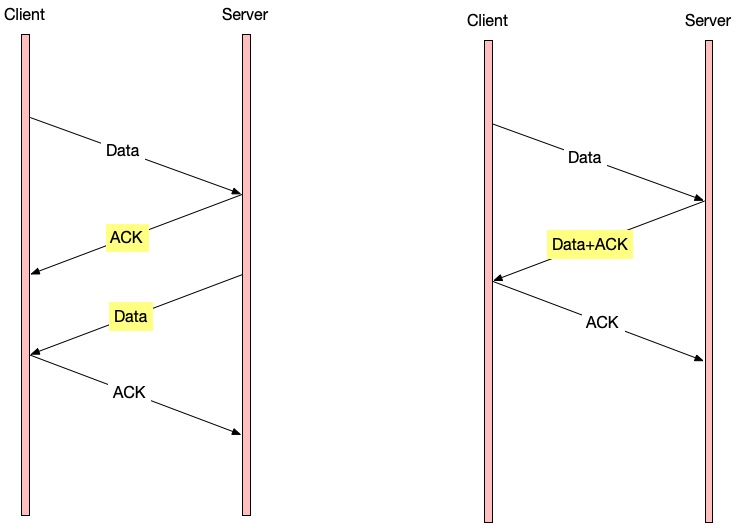
Delay ACK 可以显著降低网络中纯 ACK 包的数量,大概 1/3. 纯 ACK 包(即 payload length 是 0 ),有 20 bytes IP header 和 20 bytes TCP header。
Delay ACK 的假设是:如果我收到一个包,那么应用层会需要对这个包做出回应,所以我等到应用的回应之后再发出去 ACK。这个假设是有问题的。而且现实是,Delay ACK 所造成的问题比它要解决的问题要多。(下文详解)
Nagle’s Algorithm
现在再考虑这样一个问题:像 nc 和 ssh 这样的交互式程序,你按下一个字符,就发出去一个字符给 Server 端。每通过 TCP 发送一个字符都需要额外包装 20 bytes IP header 和 20 bytes TCP header,发送 1 bytes 带来额外的 40 bytes 的流量,不是很不划算吗?
除了像这种程序,还有一种情况是应用代码写的不好。TCP 实际上是由 Kernel 封装然后通过网卡发送出去的,用户程序通过调用 write syscall 将要发送的内容送给 Kernel。有些程序的代码写的不好,每次调用 write 都只写一个字符(发送端糊涂窗口综合症)。如果 Kernel 每收到一个字符就发送出去,那么有用数据和 overhead 占比就是 1/41.
为了解决这个问题,Nagle 设计了一个巧妙的算法 (Nagle’s Algorithm),其本质就是:发送端不要立即发送数据,攒多了再发。但是也不能一直攒,否则就会造成程序的延迟上升。
算法的伪代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
if there is new data to send then if the window size ≥ MSS and available data is ≥ MSS then send complete MSS segment now else if there is unconfirmed data still in the pipe then enqueue data in the buffer until an acknowledge is received else send data immediately end if end if end if |
简单来说,就是如果要发送的内容足够一个 MSS 了,就立即发送。否则,每次收到对方的 ACK 才发送下一次数据。
Delay ACK 和 Nagle 算法
这两个方法看似都能解决一些问题。但是如果一起用就很糟糕了。
假设客户端打开了 Nagle’s Algorithm,服务端打开了 Delay ACK。这时候客户端要发送一个 HTTP 请求给服务端,这个 HTTP 请求大于 1 MSS,要用 2 个 IP 包发送。于是情况就变成了:
- Client: 这是第一个包
- Server:… (不会发送 ACK,直到 Server 想发送数据给 Client,但是这里因为 Server 没有收到整个 HTTP 请求内容,所以 Server 不会发送数据给 Client)
- Client: … (因为 Nagle 算法,Client 在等待对方的 ACK,然后再发送第二个包的数据)
- Server: 好吧,我等够了,这是 ACK
- Client: 这是第二个包
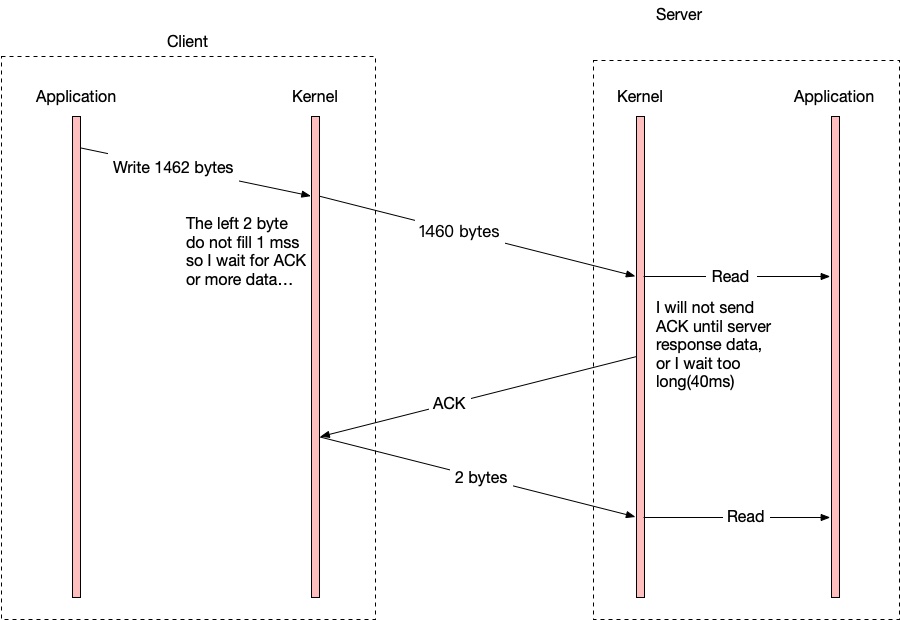
这里有一个类似死锁的情况发生。会导致某些情况下,HTTP 请求有不合理的延迟。
再多说一点有关的历史,我曾经多次在 hackernews 上看到 Nagle 的评论(Nagle 亲自解释 Nagle 算法!1,2)。大约 1980s,Nagle 和 Berkeley 为了解决几乎相同的问题,发明了二者。Berkeley 的问题是,很多用户通过终端共享主机,网络会被 ssh 或者 telnet 这样的字符拥塞。于是用 Delay ACK,确实可以解决 Berkeley 的问题。但是 Nagle 觉得,他们根本不懂问题的根源。如果他当时还在网络领域的话,就不会让这种情况发生。可惜,他当时改行去了一家创业公司,叫 Autodesk。
解决方法是关闭 Delay ACK 或者 Nagle’s Algorithm。
配置方法
关闭 Nagle’s Algorithm 的方法:可以给 socket 设置 TCP_NODELAY. 这样程序在 write 的时候就可以 bypass Nagle’s Algorithm,直接发送。
关闭 Delay ACK 的方法:可以给 socket 设置 TCP_QUICKACK,这样自己(作为 server 端)在收到 TCP segment 的时候会立即 ACK。实际上,在现在的 Linux 系统默认就是关闭的。
前面这篇文章提到:
如果在收到对方的第二次包SYN+ACK之后很快要发送数据,那么第三次包ACK可以带着数据一起发回去。这在Windows和Linux中都是比较流行的一种实现。但是数据的大小在不同实现中有区别。
如果我们关闭 TCP_QUICKACK ,就可以看到几乎每一次 TCP 握手,第三个 ACK 都是携带了数据的。
|
1 2 |
int off = 0; setsockopt(sockfd, IPPROTO_TCP, TCP_QUICKACK, &off, sizeof(off)); |
|
1 2 3 |
04:13:32.240213 IP foobarhost.57010 > 104.244.42.65.http: Flags [S], seq 1515096107, win 64240, options [mss 1460,sackOK,TS val 2468276221 ecr 0,nop,wscale 7], length 0 04:13:32.383742 IP 104.244.42.65.http > foobarhost.57010: Flags [S.], seq 1620480001, ack 1515096108, win 65535, options [mss 1460], length 0 04:13:32.384536 IP foobarhost.57010 > 104.244.42.65.http: Flags [P.], seq 1:38, ack 1, win 64240, length 37: HTTP: POST /apikey=1&command=2 HTTP/1.0 |
数据+ACK的图右侧ACK方向是不是反了?
哈哈,果然是,感谢,已改正。
博主写得很棒,拜读了