昨天同事报告了一个 Linux 机器网络问题,现象是:一台服务器无法 ping 192.168.1.253,但是可以 ping 192.168.1.252 和 192.168.1.254. 这三个 IP 都是交换机的 IP,并且和和服务器的 IP 在同一个子网下。
服务器使用了 bond1 分别连接两台交换机2,两台交换机通过 VRRP 协议提供一个高可用的网关 IP3。其中,网段的最高位一般是 VRRP 的 VIP,即 192.168.1.254,而最高位 -1 和 -2 分别是两个交换机的物理 IP,即 192.168.1.253 和 192.168.1.252 分别是两台交换机。
于是,看到这个现象,自然而然地想到是其中一台交换机有问题,192.168.1.253 已经挂了,192.168.1.252 还存活,并且担任了 192.168.1.254 的 VIP 的责任。
先去这台服务器 ping 了一下,果然是 ping 不通的,ping 显示的错误信息是 Destination Host Unreachable。然后在服务器抓包,确认下 ICMP reply 确实没有发送回来。tcpdump -i bond0 icmp. 抓包确实没有看到 ICMP reply 包,但是奇怪的是,居然连 ICMP echo 也没有抓到。
之后又去检查了交换机的配置,包括 channel-group,VLAN 配置,ACL 等等,也确认了下两台交换机之间的横连状态是正常的。这时候看起来不像是交换机的问题了。使用另一台服务器 ping 了一下这三个 IP,.252, .253, .254 都是通的。那应该是服务器的问题而不是交换机的问题。
其实这部分有些走弯路,因为 ping 明确显示 Destination Host Unreachable,说明这个包并没有发出去;而且 tcpdump 也没有抓到包,也可以印证。
接下来继续在服务器上定位问题。
ICMP 发包有问题,就先检查一下发包链路。之前遇到过类似错误,是 iptables 的 OUTPUT chain 把包 drop 了,于是先检查了 iptables,确认没有相关的 DROP。
ICMP 是基于 IP 层的协议,IP 层的协议依赖 ARP 协议来找到 MAC 地址,然后封装成二层 Frame,才能发出去,接下来去检查 ARP。(其实上一步直接检查 iptables 是不合理的,ARP 是第一步,有了 ARP 才可能构造出来完整的 Frame 开始发送,应该先从 ARP 开始排查)。
检查 arp -a | grep .253,发现 ARP 的 cache 结果是 <incomplete>. 然后用 arping 192.168.1.253 验证 ARP request 是否能得到正常的 reply,发现结果都是 Timeout。
到这里已经知道为什么 ping 会失败了,因为服务器得不到这个 IP 对应的 ARP 请求,所以 ping 无法将 ICMP request 的包发送出去,直接报错了。
接下来就定位为什么 ARP 会失败。
正常来说,ARP 应该从 bond0 接口发送出去一个 request,然后收到一个 reply,刷新服务器的 ARP cache entry。
服务器的 interface 配置如下,服务器所在的 VLAN 是 1000,和交换机做了 Trunking4,发送包的路由是走 bond0.1000@bond0 这个 interface,bond0.1000@bond0 是一个虚拟 interface,主要的功能是,发包的时候对包进行 802.1Q VLAN 封装,然后通过底层的 interface——在这里是 bond0——发送出去,收包的时候对 VLAN 进行解封装。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
root@ubuntu-1:/$ ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether b6:db:e6:76:dd:8a brd ff:ff:ff:ff:ff:ff 3: bond0.1000@bond0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether b6:db:e6:76:dd:8a brd ff:ff:ff:ff:ff:ff 4: eth0.1000@eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether b6:db:e6:76:dd:8a brd ff:ff:ff:ff:ff:ff 143: eth0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bond0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether b6:db:e6:76:dd:8a brd ff:ff:ff:ff:ff:ff 144: eth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bond0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether b6:db:e6:76:dd:8a brd ff:ff:ff:ff:ff:ff |
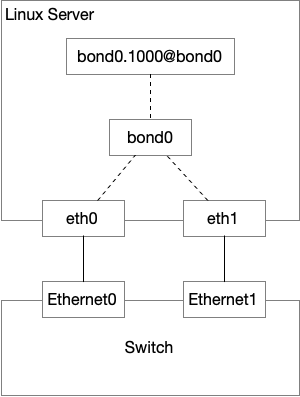
我首先在 bond0 抓包,确认 ARP 的发送和接收在协议上是正常的。
结果在这一步就发现问题了,bond0 抓包发现,只有发出去的包,没有收到的包。
为啥交换机不响应 ARP 了呢?
这时候又怀疑是交换机的问题,去检查了交换机的两个端口配置。没有发现问题。而且在其他机器上,ping 和 arping 都是没有问题的,交换机设备的问题可能性比较小。
也不会是服务器安全策略的问题,如果是的话,tcpdump 也会先抓到包的,在后面才会被 iptables 之类的 DROP 掉。
于是仔细想一想交换机和服务器之间经过了哪些组件,网卡收包,中断,网卡 driver,bond driver,协议栈处理。抓包都没抓到,说明问题出在协议栈之前,于是怀疑到 bond driver 头上去。
下一步,在物理 interface 上抓包,确认物理 interface 到底收到了 ARP reply 了没有。结果是,发现 eth0 这个 interface 收到了 ARP reply!
ARP reply 在 eth0 上收到了,但是 bond0 上没收到。这下感觉快要得到答案了。bond 有两个 slave,我把 eth0 shutdown 了,只留下 eth1,然后网路正常了。那要么是 bond driver 真的有问题,要么是我们的配置有问题。从经验上看,Linux driver 存在 bug 的概率要远远小于我们的配置错误。于是我去检查 bond 相关的配置。
检查 bond 状态 (/proc/net/bonding/bond0 文件), bond 配置,都没发现问题。可能是 eht0 这个接口有问题?
在重新看 interface 的时候(即上面的 ip link 命令和输出),我发现了可疑的一条 interface:
|
1 2 |
4: eth0.1000@eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether b6:db:e6:76:dd:8a brd ff:ff:ff:ff:ff:ff |
这里多出来一个 VLAN interface。
所以,实际上的 interface 配置应该是如下这样。由于 eth0.1000 的存在,我怀疑 eth0 收到的 ARP reply 实际上是送给了 eth0.1000@eth0 而不是 bond0,然后在 ARP 协议处理的时候,Linux 认为我们没有从 eth0.1000 发送出去 ARP request,但是却收到了 ARP 响应,属于 Gratuitous ARP5. 而发送 ARP request 的 bond0,从来没有收到 ARP reply。ARP cache 是 per interface 的,所以 bond0 无法发送 ICMP 出去。
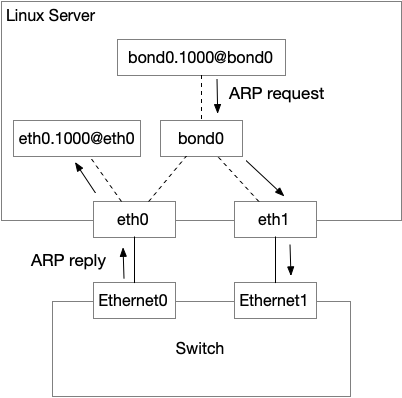
证明这个猜测很简单,只要在 eth0.1000@eth0 抓包,看是否有 ARP reply 就好了。抓包发现果然有。
并且把这个接口的 arp_accept 打开,让其接受 Gratuitous ARP,发现 ARP cache 出现了如下记录:
|
1 2 |
proot@ubuntu-1:/$ arp -a ? (192.168.1.253) at c6:34:22:fc:78:b4 [ether] on eth0.1000 |
说明这个结论是正确的。到这里就发现,其实问题不仅仅是 ARP 的问题,因为 bond 的两个 slave 有一个不对,收包的时候可能是从 eth0 收,也可能是从 eth1 收,取决于交换机的 hash 策略6。如果从 eth0 进来,那么协议栈的 skb 的 device 就会是 eth0.1000@eth0,所有有连接的协议处理都匹配不上。
于是我 shutdown eth0.1000@eth0 这个接口,理论上机器的配置应该都是对的了。
结果不是,问题依然存在,有点让人怀疑人生。由于接口 down 了就无法抓包了,不太好确认包是不是还在往 eth0.1000@eth0 送了。此处又花了一些时间排查,因为怀疑自己的推论是错误的,是不是有别的地方导致这个问题?一通误打误撞,决定删除这个多余的接口,然后网路就完全恢复了。从结果看,只 shutdown 这个接口不能阻止包往这个 vlan 接口送,得删除才行。
事后我们得知,这台服务器在 infra 团队交付的时候存在问题,应该配置 bonding,但是没有配置,只是在一条线(eth0)上配置了 VLAN。我们的同事拿到机器之后修复了 bonding 问题,但是并没有删除 eth0.1000@eth0 这个 VLAN 虚拟接口,导致产生了非预期的行为。
后来看了下源代码,发现 VLAN 的处理确实优先级比较高,在 __netif_receive_skb_core7 这里就会执行 vlan_do_recieve8,然后会把 device 的 id 设置在 skb 上。这个逻辑比 bond driver 的逻辑靠前,导致后续协议栈的处理,会认为这个包是从 eth0.1000@eth0 收到的,而不是从 bond0 收到的。
- 数据中心网络高可用技术之从服务器到交换机:802.3 ad ↩︎
- 数据中心网络高可用技术之从交换机到交换机:MLAG, 堆叠技术 ↩︎
- 数据中心网络高可用技术之从服务器到网关:首跳冗余协议 VRRP ↩︎
- VLAN Trunking Protocol ↩︎
- 特殊的 ARP 用法:Gratuitous ARP, ARP Probe 和 ARP Announce ↩︎
- 数据中心网络高可用技术之从服务器到交换机:链路聚合 (balance-xor, balance-rr, broadcast) ↩︎
- https://elixir.bootlin.com/linux/v6.12.6/source/net/core/dev.c#L5457 ↩︎
- https://elixir.bootlin.com/linux/v6.12.6/source/net/8021q/vlan_core.c#L10 ↩︎