前几天同事问我一个问题:Python 代码中,两个函数装饰器部分的代码太多了,而且有很多重复的,能否复用?这个问题我一开始也没完全听明白需求是啥,不过看了他的代码就明白了。
这里,我将他的代码简化如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
@you_decide_what_to_say("good day!") @bark @decorating_bark @add_args("foo", "foo1") @add_args("bar", "bar1") def hello_world(foo, bar): print("hello world!") print("foo=", foo) print("bar=", bar) @you_decide_what_to_say("good day!") @bark @decorating_bark @add_args("foo", "foo1") @add_args("bar", "bar2") def hello_world2(foo, bar): print("hello world2!") print("foo=", foo) print("bar=", bar) |
这里,hello_wold 和 hello_world2 的装饰器部分几乎相同,唯一不同的部分是 @add_args("bar", "bar1") 的第二个参数不同。所以他想要服用装饰器部分的代码。想要达到的效果如下面这个写法,希望能和上面的代码完全等同。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@general_decorator("bar1") def hello_world(foo, bar): print("hello world!") print("foo=", foo) print("bar=", bar) @general_decorator("bar2") def hello_world2(foo, bar): print("hello world!") print("foo=", foo) print("bar=", bar) |
这个需求是用 click 这个库定义子命令的时候,子命令之间有很多重复的。在 golang 中,使用 cobra 库可以将一部分参数都抽象出来,复用这部分代码。在 Python 中,click 库看起来不太容易做到这一点。我觉得也许可以抽象出来命令 Group 来解决这个问题,但是同事听了直摇头,觉得 command sub1 sub2 这种敲下去两层子命令不太好,一层子命令是能接受的极限了。
有没有一种方法,能够复用这部分重复的代码,还不影响命令的 UI(怎么,Cli 也是一种 UI!)
回来试了一下,发现是完全可以做到的。
如果了解装饰器基础知识,可以直接跳到文末看答案。上面没有列出源代码的四个装饰器,源代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
def decorating_bark(func): print("旺旺!") return func def bark(func): def real_func(*args, **kwargs): print("旺~旺~") return func(*args, **kwargs) return real_func def you_decide_what_to_say(worlds): print("say: ", worlds) def function_wrapper(func): return func return function_wrapper def add_args(argname, argvalue): def function_wrapper(func): def real_func(*args, **kwargs): kwargs[argname] = argvalue return func(*args, **kwargs) return real_func return function_wrapper |
Python 中的函数是一等公民
这句话的意思是,Python 中的函数和其他变量一样,可以被创建,修改,赋值,可以作为参数。
下面是一个 decorating_bark 函数,这里面什么也没有做,传进来一个函数,拿到一个函数,只是为了证明函数可以作为一个参数一样传递和返回。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def cat_say(): print("miao") def decorating_bark(func): print("旺旺!") return func cat_say = decorating_bark(cat_say) print("---> cat say") cat_say() |
输出结果是:
|
1 2 3 |
旺旺! ---> cat say miao |
当然,也可以做点什么,这段代码中的 bark 拿到函数之后,返回了一个新的函数,新的函数先是 print 了一下,然后调用原来的函数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
def bark(func): def real_func(*args, **kwargs): print("旺~旺~") return func(*args, **kwargs) return real_func def cat_say(): print("miao") cat_say = bark(cat_say) print("---> cat say") cat_say() |
注意在 cat_say = bark(cat_say) 这一行,bark 所返回的新的函数赋值给了原来的 cat_say。运行的结果如下:
|
1 2 3 |
---> cat say 旺~旺~ miao |
两行内容都是打印在 cat_say() 调用的时候发生了,说明它的行为被 bark(cat)的返回值给替换了。
这两个函数 decorating_bark 和 bark 就是上面的装饰器,但是这一段内容中我们没提起过装饰器,都是在讲函数。
Python 中装饰器是什么?
cat_say = bark(cat_say) 这一行,我们也可以这么写:@bark。但是这一行必须要写在 def 的上方:
|
1 2 3 |
@bark def cat_say(): print("miao") |
这就是装饰器了。所以,装饰器只是一个语法糖。它没有给 Python 添加新的功能,只是让代码看起来更漂亮简洁了一些。
可以传入参数的装饰器
下面这个例子复杂了一些:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
def you_decide_what_to_say(worlds): print("say: ", worlds) def function_wrapper(func): return func return function_wrapper @you_decide_what_to_say("oh!") def cat_say(): print("miao") print("---> cat say") cat_say() |
但是我们只用上面学过的内容,不需要任何新的知识,就可以理解它。
you_decide_what_to_say("oh!") 只是一个函数调用,我们将 @ 这个语法糖去掉,就变成了下面这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
def you_decide_what_to_say(worlds): print("say: ", worlds) def function_wrapper(func): return func return function_wrapper def cat_say(): print("miao") cat_say = you_decide_what_to_say("oh!")(cat_say) print("---> cat say") cat_say() |
看起来还是有一些复杂,我这么写,就简单了:
|
1 2 |
decorator = you_decide_what_to_say("oh!") cat_say = decorator(cat_say) |
对照最初的语法糖,可以看到所谓“带有参数的装饰器”,本质其实就是一个函数调用,这个函数调用会返回一个函数,返回的函数才是装饰器,用来装饰 def 的函数。
换句话说,“带有参数的装饰器” 的本质是一个装饰器制造器(decorator maker,我发明的叫法)。
由于这个例子中,实际的装饰器什么也没做,所以看起来还相对简单。有了这些知识,我们可以来看最后一个装饰器,它比上一个增加的内容,就是对函数本身做了修改。
|
1 2 3 4 5 6 7 8 9 |
def add_args(argname, argvalue): def function_wrapper(func): def real_func(*args, **kwargs): kwargs[argname] = argvalue return func(*args, **kwargs) return real_func return function_wrapper |
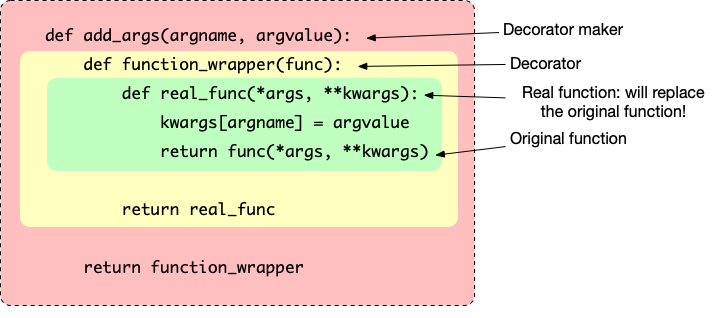
其中,add_args 是一个制造装饰器的函数,function_wrapper 是它制造出来的装饰器,real_func 是真正会返回的函数,会去替换原来的函数,它的内部调用了原来的函数,不过调用之前,它先修改了入参。
我还专门画了一个直观的图:
答案
到这里,可以发现装饰器的代码也是可以复用的,因为我们可以将其当作函数来调用:
|
1 2 3 4 5 6 7 8 9 10 |
def general_decorator(bar_value): def function_wrapper(func): func1 = you_decide_what_to_say("good day!")(func) func1 = bark(func1) func1 = add_args("foo", "foo1")(func1) func1 = add_args("bar", bar_value)(func1) return func1 return function_wrapper |
注意,包装的顺序很重要,因为装饰器是有顺序的,最里面的会先执行,最外面的后执行。读者可以复制到前面的代码中,会发现输出完全一样。这样做我们只是删除了语法糖,只使用了最原始的函数。(其实,代码中没有地方在定义装饰器,而只是在定义函数!装饰器是函数调用的语法糖)
但是,我们是否可以继续使用语法糖来复用这部分代码呢?答案是可以的。
因为 @ 必须在 def 的上方使用,所以我们必须要有 def 才行。那要 def 什么呢?我们只是想组合起来已有的装饰器,并不想改变原来的函数的行为。那就随便 def 一个新函数好了,只是新函数的内部啥也不用做,原原本本将原来的函数返回即可。
最后,上文中的 general_decorator 的实现可以如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def general_decorator(bar_value): def function_wrapper(func): @you_decide_what_to_say("good day!") @bark @add_args("foo", "foo1") @add_args("bar", bar_value) def func1(*args, **kwargs): return func(*args, **kwargs) return func1 return function_wrapper |
读者若有兴趣,可以看下之前写过的另一篇有关装饰器的内容:Python装饰器兼容加括号与不加括号的写法。之后,相信如果看到装饰器的代码,就可以信心满满地说:“哈,我知道,这只不过是函数而已!”
不过,装饰器切不可滥用。一般定义装饰器的场景是制作框架,比如像 Flask 这种 web 框架,或者 Celery 这种异步框架。框架的制作者将装饰器定义好,用户就可以使用这些装饰器,好处是,用户看起来是在写普普通通的函数,但是确能通过装饰器告诉框架一些额外的信息,和框架配合工作地很好。
作为一个语法糖,装饰器可以很好的标记出来函数一些特殊的属性。它的目的是提高代码的可读性。可惜的是,笔者遇到过很多使用装饰器的代码,解决的问题确是普通的显式函数调用就可以完成的,使用装饰器反而让代码看起来更加复杂,语义上也说不过去,降低了代码的可读性。
什么时候该用函数调用,什么时候该用装饰器?这其实是需要在朝着写好代码的漫漫长路上不断练习的。但是我有一个捷径:如果你要标记这个函数的属性,比如标记它是异步任务,标记它失败需要自动重试(@retry),标记它和某一个 @api_route 关联,那么几句设计成装饰器;如果这个是函数本身的逻辑,比如需要先干这个再干那个,这三个函数都需要先干这个再干其他的。“这个”就是显式函数调用的场景。