TLS 握手其中关键的一步,就是 Server 端要向 Client 端证明自己的身份。感觉有关 TLS 的内容,介绍握手的原理的有很多,但是介绍证书的并不多,证书是 TLS/SSL 非常关键的一环。本文就尝试说明,证书是用来干什么的,Google 是如何防止别人冒充 Google 的,证书为什么会频繁出问题,等等。
(后记:写了整整 10 个小时,这篇文章难度很低,不涉及数学内容,最多就是几个 openssl 命令,篇幅较长,读者可以打开一瓶啤酒,慢慢阅读)
证书是来解决什么问题的?
假设有一个银行叫做 super-bank.com,保存了客户一百亿的现金,客户可以通过登陆他们的网站转账。
这时候一个黑客走进了一家星巴克,连上了星巴克的 WiFi,通过伪造 DHCP 服务,告诉其他使用星巴克 WiFi 的用户:我就是网关,你们要上网的话,让我帮你们转发就可以了!这时候他就可以看到所有用户的用户名密码。
有读者说了,可以用 TLS 加密呀!
这时黑客不知道从哪里搞来了一张签发给 super-bank.com 的证书,然后伪造了一个服务器,告诉用户,相信我,我就是这家银行!
于是又把用户的密码偷走了……

那么这里问题出在哪里呢?
就是这张证书。证书的作用是:有且仅有证书的持有者,才是真正的 super-bank.com.
即,证明我是我。
有一个普遍的误解,就是只有证书机构才能签发证书。其实不是的,每个人都可以签发证书,我可以自己创建一个 Root 证书,也可以给任何域名签发证书。证书可以有很多,客户端必须只信任那些“有效”的证书。
那么哪一些证书是可以信任的证书呢?就是权威机构签发的证书。
这个问题有三个参与者:客户端,CA(Certificate Authority, 签发证书的机构), 和网站。
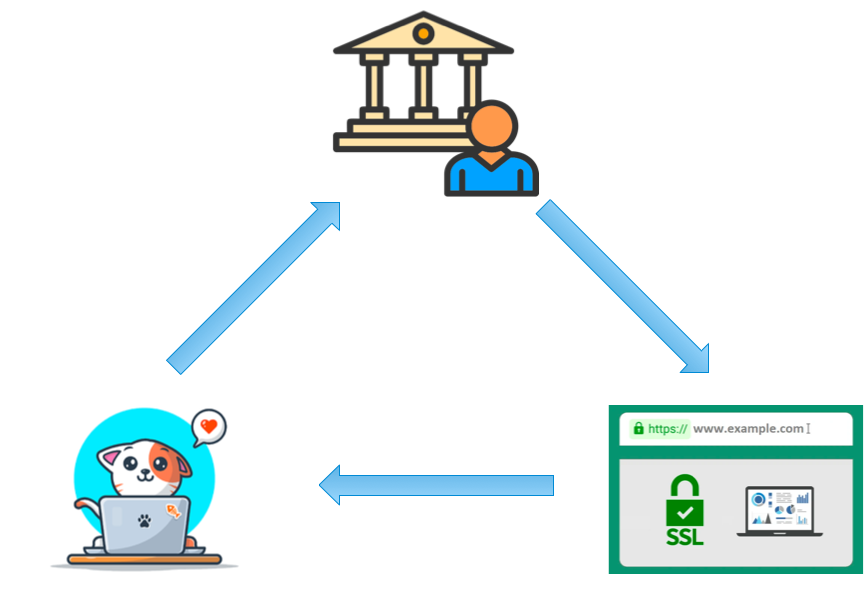
这个话题之所以讨论起来比较复杂,我觉得根本原因是因为这三者之间互相联系,又各司其职,在讨论的时候容易弄混了这是谁的指责而搞不清楚问题。所以,这篇文章我使用三个主要部分,对这三者要解决的问题和做的事情分别讨论,希望能够说清楚。
他们的关系是:
- 客户端信任 CA 机构;
- CA 机构给网站签发证书;
- 客户端在访问网站的时候,网站出示自己的证书,由于客户端信任 CA 机构,也就信任 CA 机构签发的证书;
有点像我们去吃饭,怎么知道是不是黑店呢?我们看饭店有没有工商局签发的营业执照,我们信任工商局,如果这家饭店持有工商局签发的营业执照,我们就信任这家饭店。
现在问题看起来非常简单,但是如果我们往坏处想一想,有没有破坏这个信任链的方法?就会发现这个简单的“信任”问题,解决起来并不简单。
比如,我向 CA 机构去申请一个签发给 super-bank.com 的证书行不行?CA 机构为什么不会签发给我这张证书呢?
证书机构
证书机构要做的事情有 3 件:
- 对网站:有人向我申请证书,我要验证申请人的身份,如果他不是 super-bank.com,那我就不能签发证书给他;
- 对自己:要保护好自己的根证书的 private key;
- 对客户端:要被客户端信任;
验证网站身份
我们不能签发证书给错误的人,这样的话,证书持有者不就可以冒充别人了吗?所以对于所有的申请者,我们都要确保他确实是有这个域名的控制权,才能给他签发证书。即要验证申请人的身份。
行业的标准叫做 ACME Challenge,大致的原理是:向我(CA)证明你是 super-bank.com, 你让 super-bank.com/.well-known/acme-challenge/foo 这个 URL 返回 bar 这个 text,来证明你有控制权,我就给你发证书。(其实还支持 DNS TXT 等其他的方式)
保管好自己的 Private Key
机构要保管好自己的 private key,因为 key 一旦泄漏了,意味着 (2) 也做不到了,key 的持有者可以随便签发证书了。所以,如果 Private Key 泄漏了,那会是很恐怖的,对于 CA 来说将是灭顶之灾。因为所有的客户端必须吊销这个 CA 签发出来的所有证书,网站必须重新部署证书,给 SRE 们带来的麻烦不说,假如有客户端没有及时吊销这个 CA,那么这个客户端访问的服务器,天知道还是不是真的服务器了,免不了被盗号骗钱。
对此,CA 机构对于使用 CA Root 证书的 private key 非常谨慎。用 Nginx 在公网上搭建加密数据通道 这篇文章中介绍过 private key 的管理制度之严格。
世界上有这么多网站需要申请(过期了也要重新申请)证书,如果每次签发证书 CA 都要从笼子里把 key 拿出来用,未免效率也太低了!
所以 CA Root 一般不会直接给网站签发证书,而是会签发一个中级证书,用这个中级证书给网站签发证书。
这就是 x509: 如果客户端信任 CA,那么客户端也应该信任 CA 签发出来的证书,那么客户端也应该信任 CA 签发出来的证书签发出来的证书…… 诶?!等等,既然这样,那是不是说,CA 给我签发的证书,我也可以拿来签发其他的证书?那岂不是人人都可以拿 CA 的信用签发证书了?
当然不行,CA 签发出来的证书,都有一个 X509v3 Basic Constraints: critical,值是 CA:FALSE.我把这个博客的证书下载下来,用 openssl 工具解析,可以看到这个证书链条中,Root 证书和中级证书都是 CA:TRUE, 只有我的证书是 CA:FALSE.

CA:FALSE 意味着即使签发出来证书,也不被信任。那我们可以修改一下这个字段,去签发证书吗?
答案是可以,但是如果我修改了我自己的证书,修改之后的证书就不再会被信任。
Client –trust–> Root CA –trust–> Intermediate CA –NOT trust –> kawabangga.com — NOT trust –> 我 sign 的 super-bank.com
为什么我改了这个证书,别人就不信了呢?
证书签发过程
证书的签发其实很简单,就是用了 private key 和 public key 的特点:
- private key 签名的数据,public key 可以验证;
- public key 加密的数据,private key 可以解密;
让我来跑个题,其实我觉得这么说有些复杂,我将其简化为:
- 一个 key 加密的数据,只有用另一个 key 可以解密;只不过我们将一个 key 发布出去作为 public key,一个自己藏起来作为 private key。
咦?为什么少了一条?
因为签名的原理,本质上也是加密:
- 我先把整个证书进行 hash,然后对 hash 的值,使用 private key 加密;
- 验证者将整个证书 hash,得到 hash 的值,然后使用我发布的 public key 对 (1) 拿到的秘文进行解密,对比 hash 值,如果一样,说明确实 private key 的持有者加密的;
客户端验证证书的过程如下,其实就是对比一下公钥解密之后的 Hash 值,和自己计算的 Hash 值是否一样。
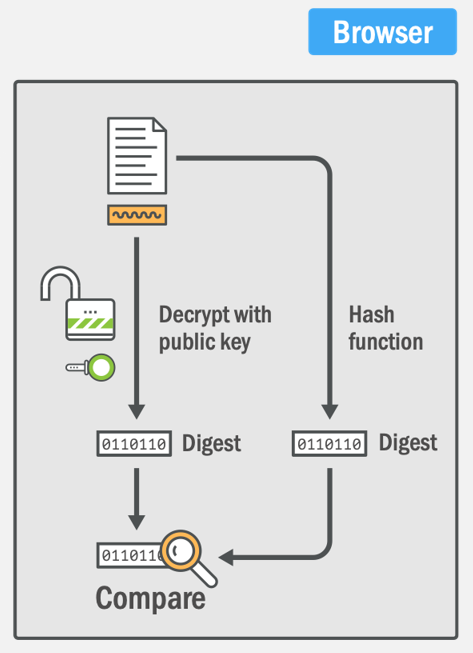
这样,签名就保证了以下几点:
- 签名者无法抵赖,因为只有 private key 的持有者才能进行签名;
- 签名之后的内容无法篡改,因为一旦篡改,验证的步骤就会失败;
如此,我们就会发现,CA 对证书签名之后,证书的任何部分都不能修改,包括 CA:FALSE,也包括有效期等。如果过期,必须重签证书,自己想修改一下日期继续用也是不行的(废话)。
这里我想重申一个误解:很多人认为证书签发是 CA 拿自己的证书签名,但是其实不是,CA 只是拿自己的 private key 给原证书 append 了一个加密的 hash 值而已。(后面会考的!)
证书机构要被客户端信任
啊,这一切的一切,都要有一个核心的基础:客户端要信任 CA,客户端对其他所有证书的信任都来源于对 CA Root 证书的信任。
而建立信任又是一个漫长的过程。(我去,这句话好有哲理,让我把它做成名言)
建立信任是一个漫长的过程。
–laixintao
那么客户端如何信任一个 CA 呢?答案是客户端会将 CA 存储在本地。具体本地的什么地方,取决于客户端是什么,比如 Linux,位置在 /etc/ssl/certs, Mac 可以用 keychain 来查看。Chrome 信任的证书在这里,Mozilla 的在这里。
哇,世界上有这么多客户端,增加一个新的 CA 得多困难呀!
其实也不是,10 年前(2013年),有几个人雄心勃勃得创建了一个组织 Let’s Encrypt:我们要给世界上所有需要 TLS/SSL 的网站免费签发证书!用友好的方式!因为我们想有一个更加安全和隐私的互联网。
一个新的 CA?信任从哪里来呢?
事实上,这个 CA 并不需要花很多年慢慢取得所有客户端的信任。如上面所说,它只要有一个 Root CA 信任即可——客户端信任一个老的 CA,老的 CA 给新 CA 做签名,客户端就会信任新 CA。这个老的 CA 在这里就是 DST Root CA X3。按照如上逻辑,客户端信任 DST Root CA X3,也就信任了 DST Root CA X3 签给 Let’s Encrypt 的证书,也就信任了 DST Root CA X3 签给 Let’s Encrypt 的证书签发的中级证书,也就信任了 DST Root CA X3 签给 Let’s Encrypt 的证书签发的中级证书签发的其他网站证书,也就信任了 DST Root CA X3 签给 Let’s Encrypt 的证书签发的中级证书签发的其他网站证书签发……等等,网站证书不能再签发证书了,CA: FALSE 还记得吗?
哇,有这么多证书,客户端应该怎么去验证呢?听起来很麻烦,我到底应该信任谁呀?
客户端
终于把 CA 机构做的事情说的差不多了,可见,作为 CA 并不是一件简单的事情,管理成本可不小,怪不得发证书要收钱呢!可见,Let’s Encrypt 可真是伟大的一个组织!
作为客户端,验证证书也不是一个简单的事情,介绍 TLS 握手的文章往往会提到 “服务器发回证书,客户端进行验证”,但实际上,通过上面的介绍,我们可以发现,服务器发回来的并不是一个证书,而是多个证书!
我们可以通过抓包确认这一点:
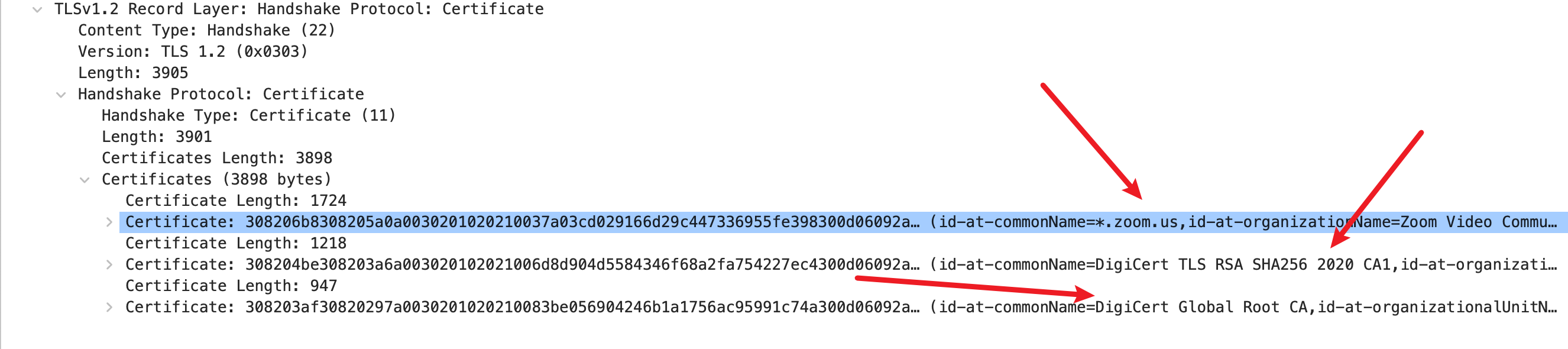
可以看到 Server 一股脑发送了三个证书回来(所以 TLS 建立的成本不小呀,这一下就是接近 4K 的数据了)。
那么客户端怎么去验证这些证书呢?
构建 Chain of Trust
客户端要相信这个证书,最终的目的一定是验证到一个自己信任的 CA Root 上去。一旦验证了 CA Root,客户端就信任了 Root 签发的证书,也就信任了……Sorry,忍住了,不会再说一遍了。
所以,首先客户端要构建出来一个签发的链条,通过这个链条去验证到 Root 上, 并且每向上找一步,都要确认这个验证过的证书是没问题的。
构建这个链条的依据,是从证书本身携带的 issuer 字段,每一个证书都标明了是谁签发给我的。
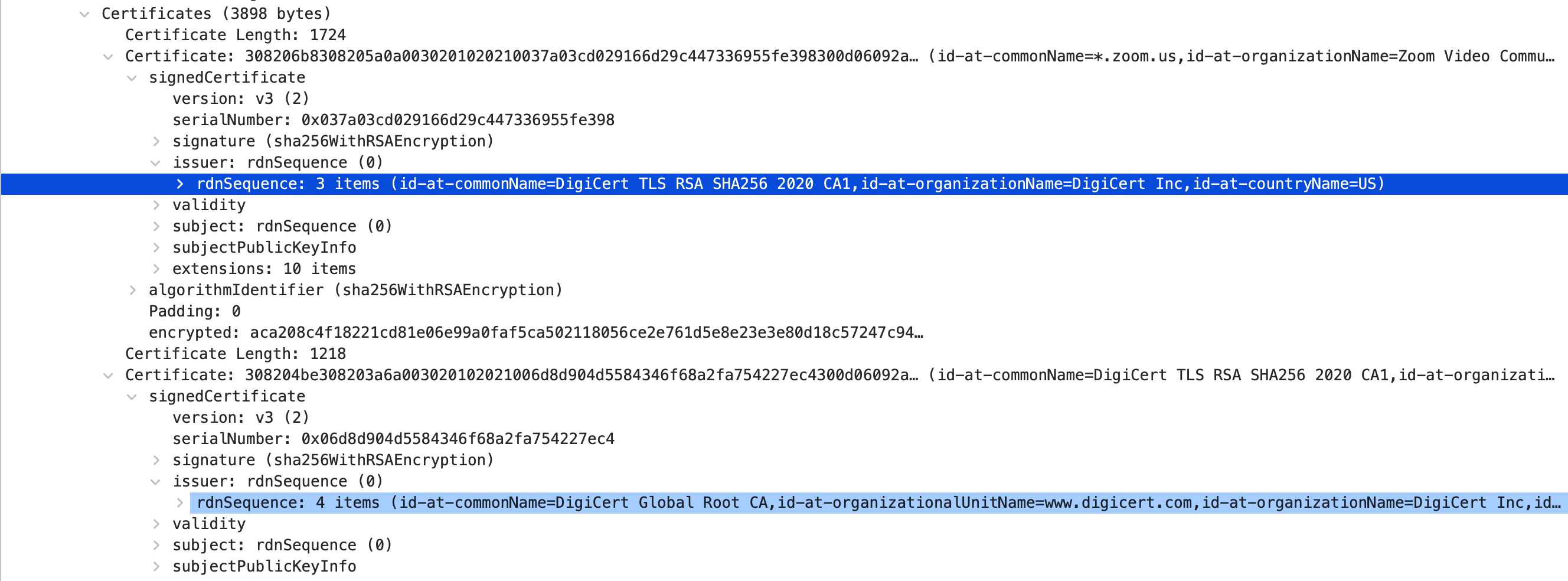
DigiCert TLS RSA SHA256 2020 CA1,而这个证书的签发者是 DigiCert Global Root CA。怎么才算是“没问题”呢?
- 证书时间不能过期;
- 使用 issuer 的 public key 验证签名没问题;
- issuer 必须是
CA:TRUE(如上文所说); - ……
验证步骤就是从 zoom.us 的证书开始,如果没问题就验证它的 issuer。直到遇到一个证书,issuer 是自己,这就表示到了 Root 了。Root 证书不会相信 Server 发回来的,就算发回来也没用,Root 证书,客户端只会信任自己本地存储的。如果本地存储的 Root 证书能验证通过中级证书,说明就没问题了。
验证的过程可以用下面的伪代码标识:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
def validate(cert): now = datetime.now() if now < cert.not_before or now > cert.not_after: return False, "Expired certificate" for issuer_cert in lookup_cert_by_name(cert.issuer): if now < issuer_cert.not_before or now > issuer_cert.not_after: continue if validate_signature(cert.data, cert.signature, issuer_cert.public_key): if cert.issuer is None: if is_trusted_root_ca(cert): return True, "Valid certificate" else: return False, "Uknown root CA" return validate(issuer_cert) return False, "No parent certificate" |
(代码来自这里)
用俺这个脚本可以打印出来网站的证书链:
|
1 2 3 4 5 6 |
$ echo | openssl s_client -showcerts -connect zoom.us:443 -servername zoom.us 2> /dev/null | grep -A1 s: 0 s:C = US, ST = California, L = San Jose, O = "Zoom Video Communications, Inc.", CN = *.zoom.us i:C = US, O = DigiCert Inc, CN = DigiCert TLS RSA SHA256 2020 CA1 -- 1 s:C = US, O = DigiCert Inc, CN = DigiCert TLS RSA SHA256 2020 CA1 i:C = US, O = DigiCert Inc, OU = www.digicert.com, CN = DigiCert Global Root CA |
以上面的 zoom.us 为例,验证过程是:
- 验证
*.zoom.us证书,通过DigiCert TLS RSA SHA256 2020 CA1进行签名验证(签名过程上文介绍过); - 验证
DigiCert TLS RSA SHA256 2020 CA1,通过它的 issuerDigiCert Global Root CA进行签名验证,DigiCert Global Root CA读取本地的文件,而不是使用 Zoom Server 发回来的这个。
我们可以用 openssl 来手动验证这个 cert,来更加了解证书验证的过程。
首先,我写了一个脚本,可以下载网站的 TLS 证书到本地:
|
1 2 3 4 5 6 7 8 9 |
download_site_cert_chain () { openssl s_client -showcerts -verify 5 -connect $1:443 < /dev/null | awk '/BEGIN CERTIFICATE/,/END CERTIFICATE/{ if(/BEGIN CERTIFICATE/){a++}; out="cert"a".pem"; print >out}' for cert in *.pem do newname=$(openssl x509 -noout -subject -in $cert | sed -nE 's/.*CN ?= ?(.*)/\1/; s/[ ,.*]/_/g; s/__/_/g; s/_-_/-/; s/^_//g;p' | tr '[:upper:]' '[:lower:]').pem echo "${newname}" mv -v "${cert}" "${newname}" done } |
使用方法是 download_site_cert_chain zoom.us。
下载完成之后将在本地得到这两个证书:
|
1 2 |
$ ls digicert_tls_rsa_sha256_2020_ca1.pem zoom_us.pem |
使用下面这个命令验证 zoom_us.pem:
|
1 2 3 4 |
$ openssl verify zoom_us.pem C = US, ST = California, L = San Jose, O = "Zoom Video Communications, Inc.", CN = *.zoom.us error 20 at 0 depth lookup: unable to get local issuer certificate error zoom_us.pem: verification failed |
验证失败。因为 zoom.us 的 issuer 并不是一个 openssl 认识的 CA,而是一个中级 CA。openssl 并不信任这个中级 CA,所以我们要告诉 openssl,链条中还有一个证书——中级 CA 的证书,通过这个中级 CA 的证书,openssl 可以发现,哦,原来你这个 digicert_tls_rsa_sha256_2020_ca1.pem 是 DigiCert 签发的呀!你早说不就得了:
|
1 2 |
$ openssl verify -untrusted digicert_tls_rsa_sha256_2020_ca1.pem zoom_us.pem zoom_us.pem: OK |
这下子就 OK 了。
我们还可以验证一下,openssl 有没有在本地去读 CA 文件。
我们使用 strace 看下 openssl 都打开了哪些文件:strace openssl verify -untrusted digicert_tls_rsa_sha256_2020_ca1.pem zoom_us.pem 2>&1 | grep open

openssl 打开的文件可以看到,openssl 打开过我们给的两个 .pem 证书文件。但是看不出来哪一个是 CA Root 证书。
其实是最后一个:/usr/lib/ssl/certs/3513523f.0 就是。
不知道读者有没有发现,上面的过程貌似缺少了一步:客户端是怎么根据服务器发回来的证书,对应到本地 CA Root 文件的?
答案是通过中级证书的 issuer,openssl 给所有的 Root 证书 subject 制作了一个重命名的 Hash,用这个 hash 做了符号链接(不确定为啥,是为了查找起来更快吗?),查找的时候,根据中级证书的 issuer (即 Root 证书的 subject)进行 hash,就可以找到本地证书文件。
|
1 2 |
$ ls -l /usr/lib/ssl/certs/3513523f.0 lrwxrwxrwx 1 root root 27 Aug 9 2022 /usr/lib/ssl/certs/3513523f.0 -> DigiCert_Global_Root_CA.pem |
我们查看这个证书的 subject,跟中级证书的 issuer 显示一样:
|
1 2 |
$ openssl x509 -in /usr/lib/ssl/certs/DigiCert_Global_Root_CA.pem -noout --subject subject=C = US, O = DigiCert Inc, OU = www.digicert.com, CN = DigiCert Global Root CA |
然后可以手动计算一下 hash:
|
1 2 |
$ openssl x509 -in /usr/lib/ssl/certs/DigiCert_Global_Root_CA.pem -noout --subject_hash 3513523f |
和 /usr/lib/ssl/certs/3513523f.0 恰好匹配。咦,还有个 .0 呢?这里让读者自己想一下吧。答案在这里。
Root CA 交叉签名
前文提到了,一个新的 CA 在打开市场之前,需要找一个大哥罩着自己。那么具体是怎么工作的呢?
我们用上文的脚本去拿到维基百科的证书(使用的是 Let’s Encrypt 签发的证书,Let’s Encrypt 可真是伟大的一个组织!):
|
1 2 3 4 5 6 7 8 |
0 s:CN = wikipedia.com i:C = US, O = Let's Encrypt, CN = R3 -- 1 s:C = US, O = Let's Encrypt, CN = R3 i:C = US, O = Internet Security Research Group, CN = ISRG Root X1 -- 2 s:C = US, O = Internet Security Research Group, CN = ISRG Root X1 i:O = Digital Signature Trust Co., CN = DST Root CA X3 |
可以看到有三个证书,这时候,客户端从验证 wikipedia.com 开始:
- 验证
R3签发的wikipedia.com,如果成功: - 验证
ISRG Root X1签发的R3,但是如果客户端在本地存储了(即信任)ISRG Root X1,就会用本地的验证,然后验证结束,验证成功。否则: - 验证
DST Root CA X3,客户端信任DST Root CA X3,验证结束。
这就是交叉签名的验证原理。
2021 年发生过一个印象深刻的小插曲,2021年9月30日,是当时 DST Root CA X3 的过期时间。这意味着,2021年9月30日过后,如果客户端不信任 ISRG Root X1,那么客户端就无法信任 Let’s Encrypt 签发的任何证书。此时,Let’s Encrypt 的接受程度已经很大,主流浏览器和操作系统都已经直接信任了(Let’s Encrypt 可真是伟大的一个组织!)。这意味着几乎不会发生任何问题。
但是,有一些 Ubuntu 16.04 服务器由于很久不更新(只有更新才能获取到新的 CA,很合理吧)(2021年了还在用不更新的 Ubuntu 16.04?这是什么草台班子?!),所以一直没有信任 ISRG Root X1。这导致,在2021年9月30日那一天,很多服务器访问其他网站和 API 出错。这就是客户端部分没有做好 CA Root 维护的一个例子。
中级 CA 交叉签名
现在来到真正麻烦的话题了。上文的 Root CA 交叉签名是一种方式,也是最通用的方式。只有一个链条:Cert > R3 > X1 > DST,客户端这样验证下去就可以了。
但是中级 CA 也可以被交叉签名。
这里重申几个(我之前困惑)要点:
- 一个证书只能有一个 issuer,因为 issuer 是证书的固定字段,不是一个 List;
- 签名的本质,只是 append 一个 private key 加密的 hash 值;
- 中级证书不被客户端直接信任,客户端信任的只有 Root CA;
有了这些,我们来看之前 Let’s Encrypt 的 R3 中级证书交叉签名的方式(这是之前签名的一种方式,现在已经不用了,请读者不要跟上面实际抓包的例子混淆,现在基本上不使用中级证书交叉签名的方式了,都是 X1 Root 证书直接被 DST Root 来签名,下面只是历史的一个简化例子,而且忽略了其他证书链的存在):
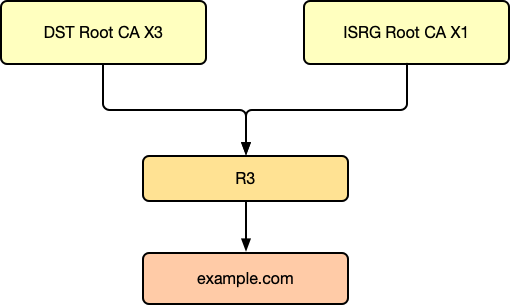
咦?一个证书不是只能有一个 issuer 吗?为什么这个图的 R3 有两个 issuer?
没错,很多图会这么表示中级 CA 被多个 Root CA 交叉签名,但是实际并不是这样的,实际上是两个证书!R3 证书拿去找 DST Root CA X3 签名,得到一个签名后的证书;然后 R3 再去找 ISRG Root CA X1 签名,又得到一个证书,现实中,证书链应该是如下这样:
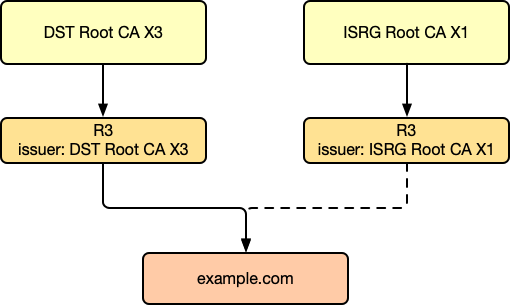
R3 得到了两个签名后的证书!这时候 example.com 来找 R3 进行签名了,R3 应该用哪一个签名呢?
答案是用任意一个都行!
请回忆我们上文讨论过的签名的原理,其实就是 append 一个加密的 Hash 值,那么 R3 使用相同的证书去找不同 Root 签名两次,本质上,得到的两个证书,证书自己的 public key 和 private key 都是一样的。所以 R3 在给其他网站签发证书的时候,使用任意一个证书的 private key,给网站证书计算出来的 hash 值,是一模一样的。
这里的核心是需要理解,证书签发本质上是用 private key 对 hash 值进行加密。
这就意味着,我们的中级 CA 其实可以被无数个 ICA 签名,只不过多个签名就多一个证书,而这些所有的中级 CA 证书,都需要让网站返回给客户端的。因为客户端需要这些中级证书来知道签发的 Root CA,来构建出来 Chain of Trust.
如上例子,网站拿到 R3 签名的证书,在和访客建立 TLS 连接的时候,需要返回:
- example.com 网站的证书;
- DST Root CA X3 签发的 R3 证书;
- ISRG Root X1 签发的 R3 证书;
这样,客户端无论是信任 DST Root CA X3 还是 ISRG Root X1,最后都可以达成信任。
这里有一个事故的例子,就是因为他们的网站找 Let’s Encrypt 签发证书之后,只返回了:
- example.com 网站的证书;
- DST Root CA X3 签发的 R3 证书;
缺少了一个 R3,而 DST Root CA X3 在 2021 年9月过期了,导致网站不被信任。
话说回来,这部分内容其实没有实际验证,因为我用脚本下载了很多网站的证书链,发现没有一个是使用中级证书来交叉验证的,都是使用 Root CA 来交叉验证。这里提到说,即使缺少了一个中级证书,客户端也能自己找到信任链,然后成功验证。这点我对此表示怀疑,可能真的取决于客户端的行为吧。其实通过验证对客户端来说也是没问题的,因为这些证书本质上是完全合法的,只是因为无法完成 Chain of Trust 而无法完成验证而已。
为什么找了这么多案例,没有一个是用中级证书来做交叉验证的?我认为可能是,如果用 Root CA 去找老 CA 验证,那么客户端的验证过程是没有分叉的一条链;如果是中级证书交叉验证的话,那验证过程就会复杂一些吧。但是这部分没有资料证实,如果读者知道,欢迎赐教。
客户端修改本地 CA 的行为
一般来说,客户端的证书是由软件或者操作系统维护的,但是毕竟证书只是文件而已,客户端的用户可以自己维护这些文件。但是这有什么问题呢?
拿上文的中间人攻击的例子来说,由于只有拥有网站的证书才可以被客户端信任,中间人没有此证书,所以,即不能看到通讯内容,也无法篡改通讯内容,如果伪装自己就是目标网站,也会因为没有合法证书而被识破。
假设有一个比较坏的 CA Root 给某个黑客签发了 google.com 的证书,而客户端信任这个 CA Root,然后黑客伪造了网站,那么客户端的浏览器就会信任此网站。
这在历史上是真实存在的。VeriSign Class 3 Public Primary Certification Authority – G5 就因为错误签发过 google.com 的证书,而被很多操作系统吊销 Root CA(即不在信任)。上周的一个新闻。
我之前在阿里巴巴公司工作的时候,公司有一个办公软件叫“阿里郎”,如果不让它在个人手机上安装它自己的证书的话,很多功能无法使用。现在读者可以理解安装的后果了吗?如果安装了它的证书,那么也就信任了它签发的任何证书,这就意味着它作为中间人,可以看到用户手机上的所有流量,包括聊天记录,HTTPS 登陆的用户名密码等等。(当然了,公司声称绝不会收集用户隐私)
MITMProxy 可以用来对 HTTPS 抓包,它的原理也是在你电脑上安装一个证书,然后模拟中间人攻击。你访问 exmaple.com 的时候,MITM 会收到你的请求,然后给你返回 MITM 的证书而不是 exmaple.com 的证书,因为你信任了 MITM 的证书,所以对于客户端来说,就认为自己在访问真正的 example.com,然后在这个连接上发送内容,这个代理可以看到你的明文请求,再转发给真正的目标。这样就实现了对 HTTPS 抓包的效果,经过 MITM 的内容都可以被明文看到。
那有一些应用不想被抓包呢(可能偷偷收集了什么东西而不想被用户看到?),有一种技术,就是在客户端的代码中拒绝信任所有 CA,只信任自己的证书。
Client Certificate Pinning
其实道理很简单,比如有些程序就不使用系统维护的证书,而是自己维护一份信任的 CA 列表,比如 Chrome。
那客户端将信任的列表进一步缩小,缩小到只有信任自己签发的证书(或者自己签发的 CA),就是 Client Certificate Pinning。其实抖音 App 就是这样,我们即使用 MITMProxy 也无法对其抓包,因为无法让它信任 MITM 签发的证书,它只信任自己硬编码的证书。(也许你找到这部分证书存放在哪里然后进行修改,就可以绕过去了)。
网站
最后说到网站了。我们前面说了很多 CA 和客户端在证书方面可能出的问题,但是最经常出问题的部分,还是网站——很多网站(包括本博客,嘻嘻)都经历过的问题:就是证书过期。
网站要确保两个事情:
- 确保自己的证书不会过期;
- 保护自己的 Private key 不泄漏,因为如果其他人有了 Private key,证书就失去“只有我才能证明是我”的意义了。找 CA 签发证书原则上只提交 public key 让其签名即可,所以,只有网站自己才持有 private key;
记得更新你的证书哦!
第一点看似简单,但是很多网站都出现过类似问题(说明大部分团队……都是草台班子)。隐藏的一点是,所有的证书都有过期时间,即使是 CA Root 和中级 CA,网站要确保证书链的每一环都没有过期。
可能这一点难做的原因,就是证书签出来两年,两年之后……可能大部分人都会记得换新的(如果你在一家大公司工作过,你可能就会理解保证“2年后记得做某件事”实际上有多么困难)。
所以,Let’s Encrypt 就出了一个绝妙的点子:我们签发的所有证书只有 90 天有效期,没有例外!(可见,Let’s Encrypt 可真是伟大的一个组织!)
这样做有两个好处:
- Private key 相当于密码一样,每 90 天换一次,更加安全;
- 谁会喜欢每 3 个月走遍流程呀?这就鼓励网站使用自动化 renew 的流程,每 60 天换一次,这样也更不容易出问题了。
Private key 保护的问题
Private key 如此重要,因为拿到它的人就可以欺骗所有的客户端——我就是这个网站了。所以保证 key 不泄漏就至关重要了。
但是,万一泄漏了呢?Private key 要部署在直接让客户端访问的服务器上,如果服务器遭到攻击,不就会泄漏 Private key 吗?常在河边走,哪有不湿鞋!
对已签发的证书吊销
读到这里,不知读者是否发现另一个问题:假设网站的证书还剩下 6 个月,然后 private key 泄漏了,开始部署假网站,那么目前为止我们介绍过的方法都无法阻止假网站,因为假网站拿到了证书(证书链可以直接从原网站下载到,然后部署)有了 private key 就可以跟客户端建立 TLS 连接。这个证书是权威 CA 签发的,完全合法。
客户端只能吊销 CA,但是因此吊销 CA 是不现实的,其他没有漏泄 key 的网站也要跟着遭殃吗?
所以我们需要一种机制,对于已签发的证书进行吊销。
原理上,就是 CA 证书自身带有这个信息,告诉客户端在校验证书的时候,应该去访问这个 URL 列表,查看自己要验证的证书是否在吊销列表中,如果在,就不要信任。
CRL
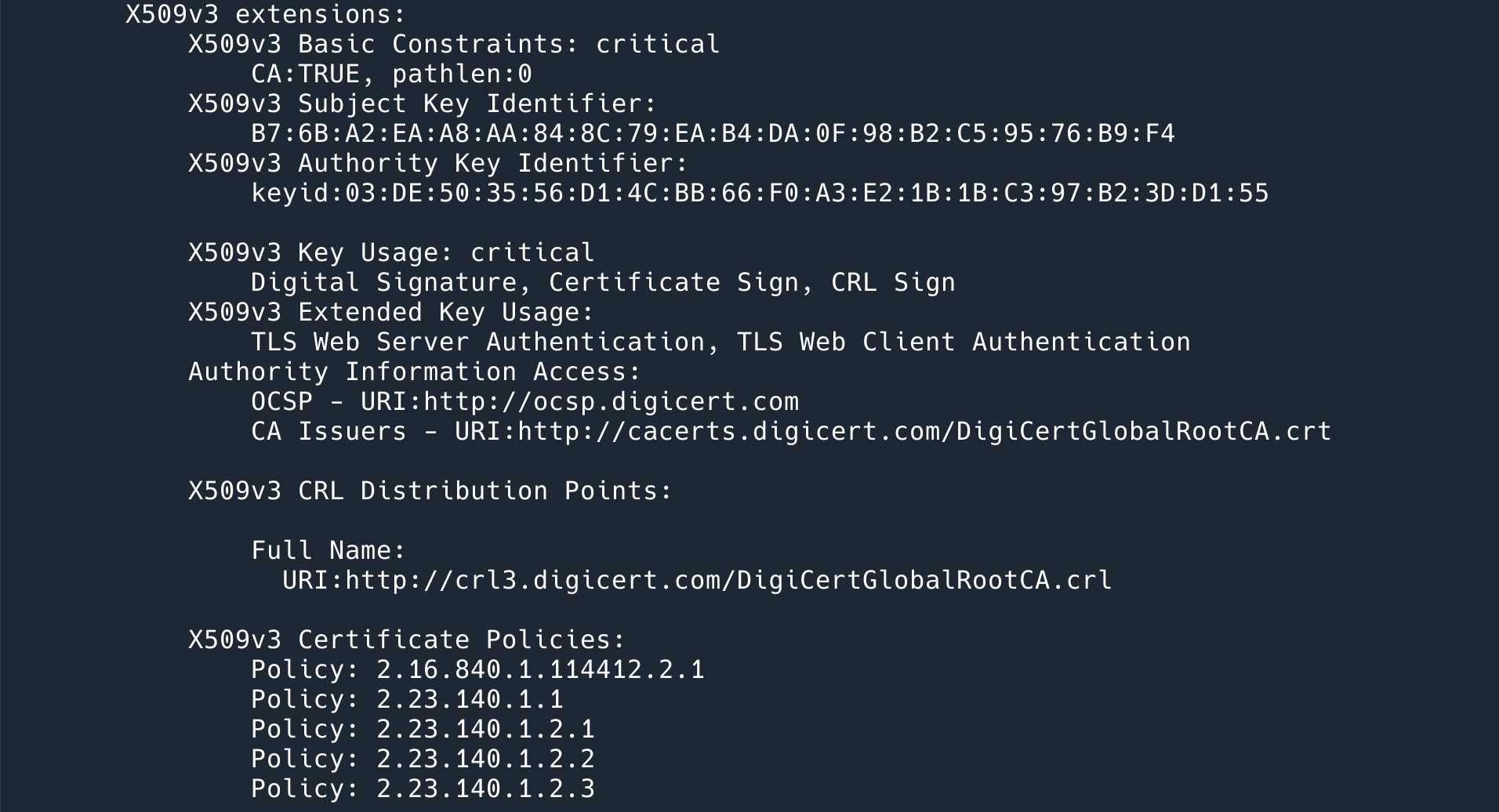
以 CRL 为例,我们可以使用下面这个命令,从上文下载到的 digicert 证书中拿到 CRL 的地址:
|
1 2 3 4 5 |
$ openssl x509 -in digicert_tls_rsa_sha256_2020_ca1.pem -noout -text | grep "X509v3 CRL Distribution Points" -A 4 X509v3 CRL Distribution Points: Full Name: URI:http://crl3.digicert.com/DigiCertGlobalRootCA.crl |
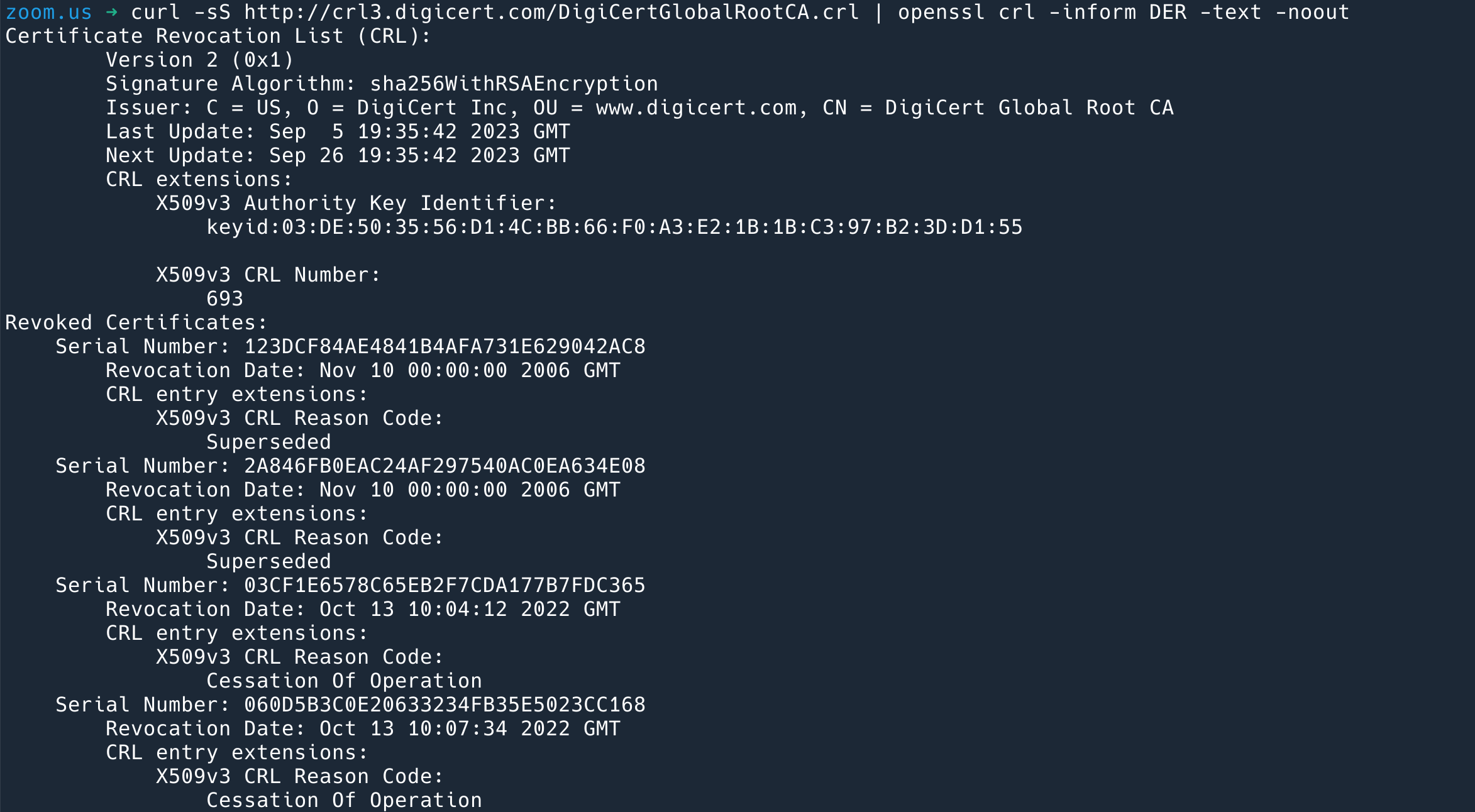
然后去这个 CRL 地址下载下来内容(是 DER 格式),用 openssl 来解开 DER 格式,就可以看到这个 CA 吊销过的一些证书:
|
1 |
$ curl -sS http://crl3.digicert.com/DigiCertGlobalRootCA.crl | openssl crl -inform DER -text -noout |
OCSP 也是类似的原理。
那么这样做会不会有什么问题呢?客户端要验证这个证书,还要去请求一次这个 URL 验证证书的合法性,显然,这会带来几个问题(用 OSCP 来举例):
- 网站本身的性能会下降,因为多出来一次请求 CA 的时间;CA 的 OCSP 服务器会成为访问的热点,可能被客户端过载;
- 隐私问题,CA 就会知道客户端访问了哪一些域名。因为这个问题,Let’s Encrypt 就在 2024年7月决定终止支持 OCSP 了;
- 潜在的安全问题:假设现在 CA OCSP 服务挂掉了,客户端有两个选择:
- 选择忽略验证,继续信任目标网站——这样的话就失去 OCSP 的意义了,已被吊销证书的持有者,只要想办法打挂 CA 的 OCSP 服务,或者(如果有权限的话)block 掉客户端对 OCSP 的访问,就可以让自己的证书信任;
- 选择不相信目标网站——这会因为 CA 的问题造成对目标网站的不可用,对目标网站来说是无法接受的;
OCSP Stapling
OCSP Stapling 可以解决以上问题。它的核心原理是:
- 网站定期去访问 CA 的 OCSP 服务,确认自己的证书是没有被吊销的,拿到 OCSP Response;
- 客户端访问网站的时候,网站连同证书一起出示 OCSP Response,证明自己的证书是没有被吊销的;
这样就没有了客户端和 CA 之间的依赖,就解决了以上问题。
等等,那如果网站伪造 OCSP Response 呢?
这是不可以伪造的,因为 OCSP Response 是经过 CA 签名的,客户端要验证这个签名,证明 OCSP Response 确实是 CA 确认的。
可以使用如下命令查看到 OCSP Response:
|
1 |
openssl s_client -connect kawabangga.com:443 -status -servername kawabangga.com |
以下是一个 OCSP Response 内容的示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
OCSP response: ====================================== OCSP Response Data: OCSP Response Status: successful (0x0) Response Type: Basic OCSP Response Version: 1 (0x0) Responder Id: D5FC9E0DDF1ECADD0897976E2BC55FC52BF5ECB8 Produced At: Aug 28 12:31:36 2023 GMT Responses: Certificate ID: Hash Algorithm: sha1 Issuer Name Hash: EC4A2797F8915935139678B3E8C8A21D097B312E Issuer Key Hash: D5FC9E0DDF1ECADD0897976E2BC55FC52BF5ECB8 Serial Number: 4BEA45B1F5C6C0310D047BC9EB5449FA Cert Status: good This Update: Aug 28 12:31:36 2023 GMT Next Update: Sep 4 11:31:35 2023 GMT Signature Algorithm: sha256WithRSAEncryption Signature Value: 5c:e0:44:17:a0:84:e1:5d:83:f5:0e:ad:18:2d:da:98:8a:be: 9d:38:bd:f6:9a:d5:82:c2:14:08:2f:ac:6b:b4:78:4e:25:bc: a0:55:19:9b:75:b9:e8:54:d5:79:fa:a8:9b:ab:7a:3f:37:b0: 9d:8d:f5:d4:67:95:80:e1:cd:bf:d5:ac:5f:fc:8c:22:a7:0f: 2c:35:0a:de:4f:a9:63:67:ce:59:0f:f1:b7:9d:69:e9:dc:ce: 06:7b:64:a0:60:19:bf:48:2e:af:f4:5c:85:69:54:4e:71:d0: 09:75:0d:c5:54:0b:d8:49:1f:bf:18:65:97:03:2d:01:88:bf: 9b:48:c5:30:f3:f5:59:34:b6:b5:89:81:6f:b0:01:e4:9a:26: 6b:4d:51:0b:e7:12:86:33:8a:4e:cc:f4:4e:80:b7:63:29:df: 6c:c6:8b:2e:2f:c1:6f:60:25:7d:4b:5b:4e:9f:48:9d:d0:8a: 08:25:3d:e2:c0:2c:83:d4:5f:3c:66:4d:0d:71:da:19:c8:b5: 58:64:b6:98:9f:46:f2:e4:a0:1c:e3:3b:a1:74:59:41:02:51: 5d:74:43:31:24:02:d2:02:d6:ca:a5:ff:f2:ad:e7:87:89:83: 40:ec:38:b4:90:1b:92:d3:36:23:f4:71:0d:02:c7:47:14:8f: d3:dc:d6:ff ====================================== |
如此,如果客户端收到了网站发送的 OCSP Response,就直接进行验证即可;如果没有收到,就自己查询 CA,如果收到了但是验证没有通过,就直接停止连接,不信任网站。唯一的问题就是证书吊销之后会有一段延迟,OCSP Response 的时间过期才行。但是是可以接受的。
HTTP Public Key Pinning
网站也能做点什么,有一个叫做 HPKP 的技术,就是客户端在访问网站的时候,网站返回的 HTTP 响应中,包含一个叫做 Public-Key-Pins 的 Header,这个 key 就是证书的 Public key hash。哪一个证书呢?可以直接 pin 此网站的证书,亦可以是中级证书,或者某一个 CA 的 Root 证书。一旦返回如此的 HTTP 响应了,就是告诉客户端,你应该只信任此证书,(如果 pin 的是 CA 的 Root 证书的话,就是告诉客户端只信任此 CA 签发给我的网站的证书),这样,就可以避免其他人签发出来假冒伪劣的证书了。
比如我们的 super-bank.com 和某 CA 建立了强烈的信任关系,但是 super-bank.com 作为这么重要的一个网站,又担心其他 CA 乱签发出来 super-bank.com 的证书,super-bank.com 就可以在客户端访问他的时候,pin 这个 CA 的 Root。意在告诉客户端,我这个网站呀,只会用 甲CA 签发证书,一旦有别的 CA 签发出来我这个网站的证书呀,即使你信任这个 CA,也一定是假冒伪劣的!
那假如网站真的要更换证书呢?岂不是客户端也不会信任了?所以如果要用 HPKP,必须要有一个 backup key,如果没有 backup key,HPKP 不会生效。
Certificate Transparency
Certificate Transparency, 翻译过来叫做“证书透明化”,这部分需要客户端、CA、网站一起才能支持,所以放到最后来讨论。
它要解决的问题是什么?
就是 CA 错误签发其他网站证书的问题。有一些 CA 内部管理其实是及其混乱的。比如,这里有篇文章,讲的是这位作者如何拿到了 github.io 等域名的证书的,这个证书就是从沃通拿到的,可见沃通存在的问题很多,后来被 Mozilla 和 Google 移除信任。沃通还提出过申诉(还有脸申诉,你干过啥自己没数吗?),称只服务于中国区的用户(好嘛,这不就是说“中国人只坑中国人”?),最后当然是被驳回了,因为我们知道,一个不被信任的 CA 是无法控制作用范围的,管理不当会对全世界的网站和用户造成安全问题。(所以沃通你到底知道不知道自己在做什么?)
为了防止类似的事情发生,Google 牵头发起了 Certificate Transparency. 要解决的就是 CA 乱签证书的问题。如果要详细了解 CT 的话,他们的官方网站解释的太清楚了。
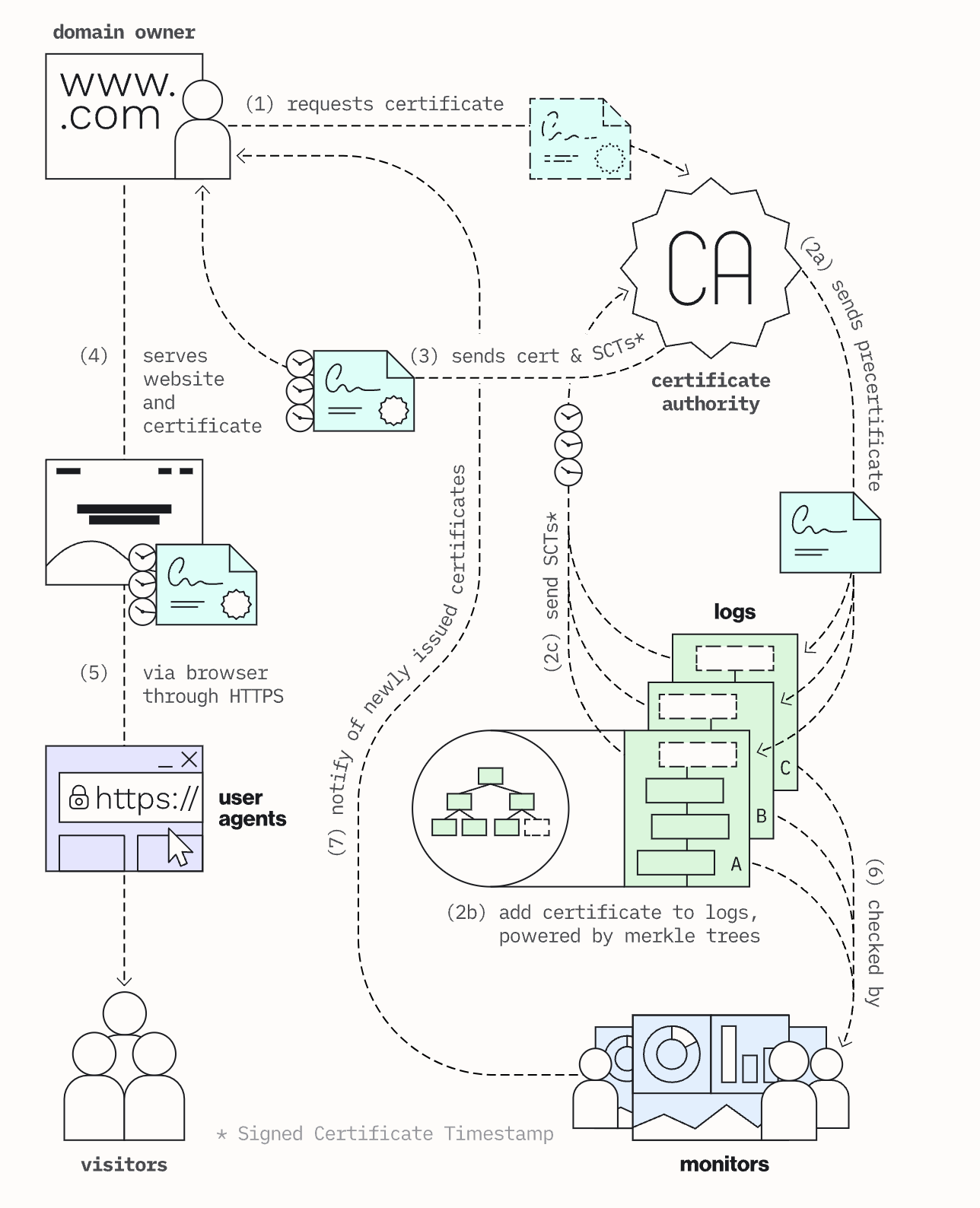
这我按照自己的理解解释一下,三方分别要做的事情:
- CA 在签发证书的时候,必须将签发的证书放到 CT 数据库中,CT 会给证书加 SCT;CA 将签名的证书发回给网站,这个证书是带有 SCT 的;
- 客户端访问网站时候,只有证书带有 SCT 才会信任;这样,就保证了所有客户端信任的证书,都在 SC 数据库里面有记录;
- 网站可以监控 SC 数据库,关注是否有 CA 签发了自己不知情的证书;
如此,就没有 CA 可以偷偷签发某一个网站的证书,被客户端信任而不被网站知道了。
啊,终于写完了。我的酒也喝完了。本文的内容我都尽量自己验证尝试过了,但是不能保证完全正确,如果读者中有专家发现其中错误,欢迎不吝赐教。本来标题想起一个类似英文的 All I Know About Certificates, 但是发现好像没有对应的比较顺口的中文标题。就写了个《有关 TLS/SSL 证书的一切》,其实只是我知道的一切而已,请见谅。
2023年9月2日更新:补充了 OCSP Stapling 和 Certificate Transparency 的内容。
2023年9月2日更新:文章发出来之后,网友贴了一些他们写的博客,也非常好: