最近因为遇到了一个和 MSS 有关的问题,所以花了很多时间学习相关的东西。过程中又发现网上有很多相关的内容是错误的,或者介绍的东西其实现实世界已经不用了。(感觉网络相关的知识经常有这种情况,介绍一种完全过时,现实世界已经不再是用的东西。比如我很久都搞不清 IP 分 Class 有什么意义,后来看到 RIP 才明白原来这古老的路由协议假设全世界的网络号都是 classful 的,让路由结构简单了很多。)我看到这些资料的时候有了无数的疑问,然后又花了很长时间,这些疑问现在基本上都有了一个合理的解释。这篇博客就来总结一下和 MTU, MSS 有关的内容。有可能也写不完“一切”,但是预料到会写的很长。所以你现在去冲一杯咖啡,我们从最简单的地方开始。
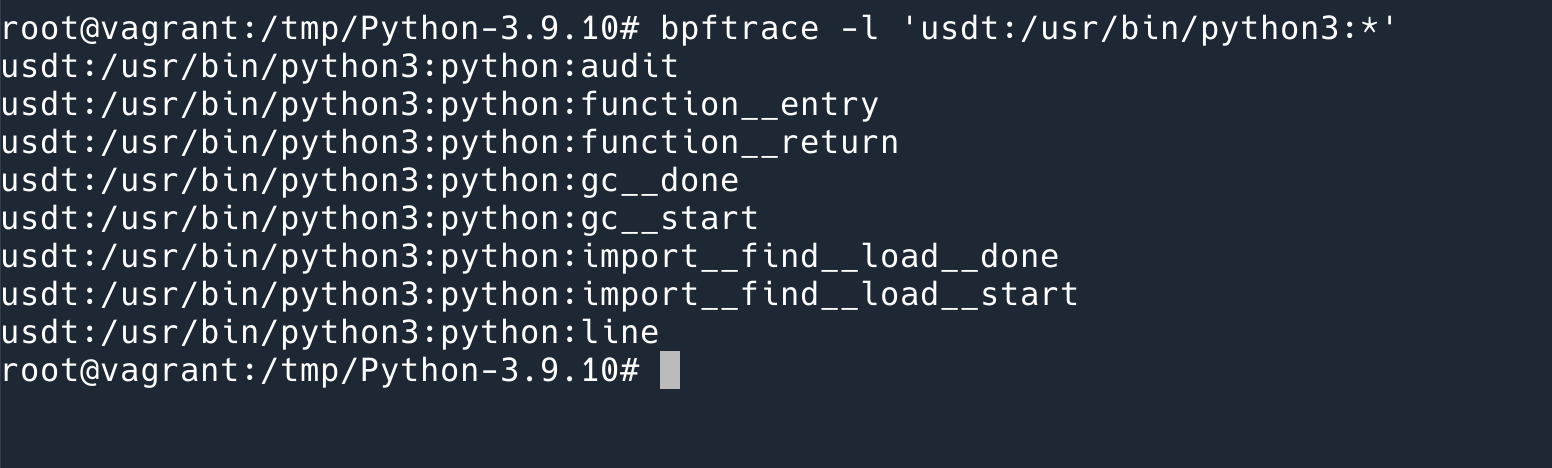
MTU
MTU 指的是二层协议里面的最大传输单元。
这是一个很简单的概念。但这是我最初的问题来源,不知道你看到这个之后是否也会有相同的疑惑:
- 为什么需要 MTU?
- 为什么是我看到过的 MTU 都是 1500?
- 如果传输的数据(在二层我们叫做 Frame)超过了 MTU 会发生什么?
- 那什么时候发送的数据会超过 MTU?
我们从最简单的说起……
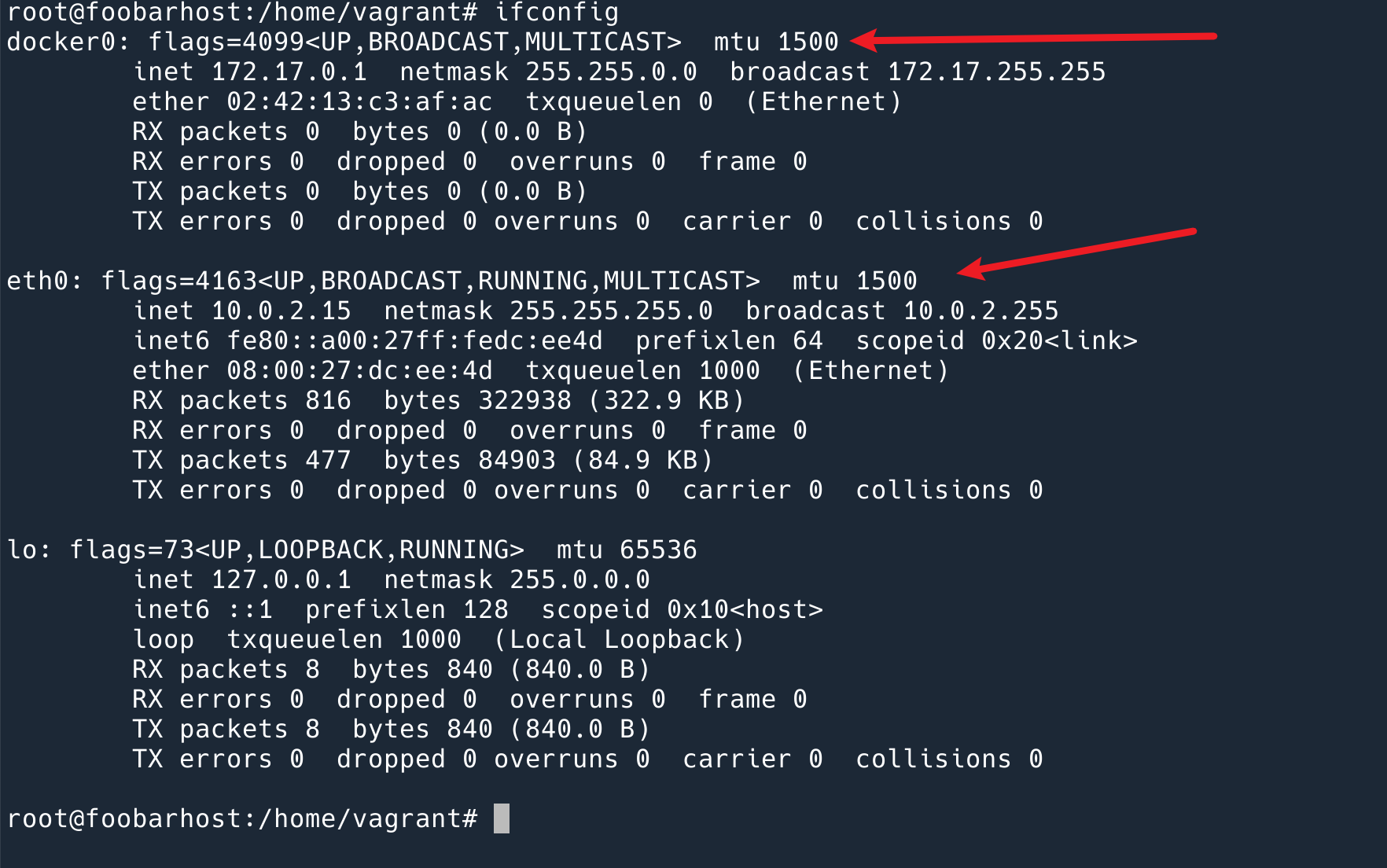
为什么需要 MTU,以及它的大小为什么到处都是 1500bytes?
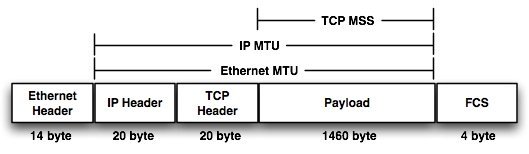
MTU 的存在很合理,Frame 不可能无限大,发送小的数据是可以的。所以就设定了一个最大值。我们在网卡上看到的 MTU 一般都是 1500bytes,要注意这个值指的是 Frame 内容的最大值,并不包括 Ethernet Frame 的 header 和 FCS。一个 Ether Frame 最大是 MTU + Header 14bytes + FCS 4 bytes = 1518 bytes.
那么为什么 MTU 都设置成 1500 呢?
可以说是历史原因。维基百科有这么一句话:
Larger MTU is associated with reduced overhead. Smaller MTU values can reduce network delay.
第一句话很好理解,更大的包,header 占据整个包的比例就更小,那么链路上更多的资源就花在了数据的传输上,协议消耗的 overhead 就会很小。
第二句话呢?
我觉得 Ethernet 最精髓的地方就在于,它和我们说话一样。如果两个人在交谈,突然同时说话了,会发生什么?两个人都是停下来,等一段时间,然后一个人又开始说了,那么另一个人要等他说完再说。
那么就意味着,更大的包就会让一个人占据链路的时间更长,所以总体上延迟就会变大。此外:
- 更大的包意味着出错的概率更大,所以会增加重传的比例;
- 重传的代价也更大,一大段数据里面如果有一个 bit 出错了,这一大段就会整个重传;
- 以太网是分组交换网络,即存储,转发,在转发给下一跳之前,路由设备或者交换机要存储还没发完的数据,更大的 MTU 就对设备的性能有更高的要求,意味着更高的成本;
综上,1500 其实是一个 Trade Off。
其实,不同的 2 层协议有不同的 MTU:
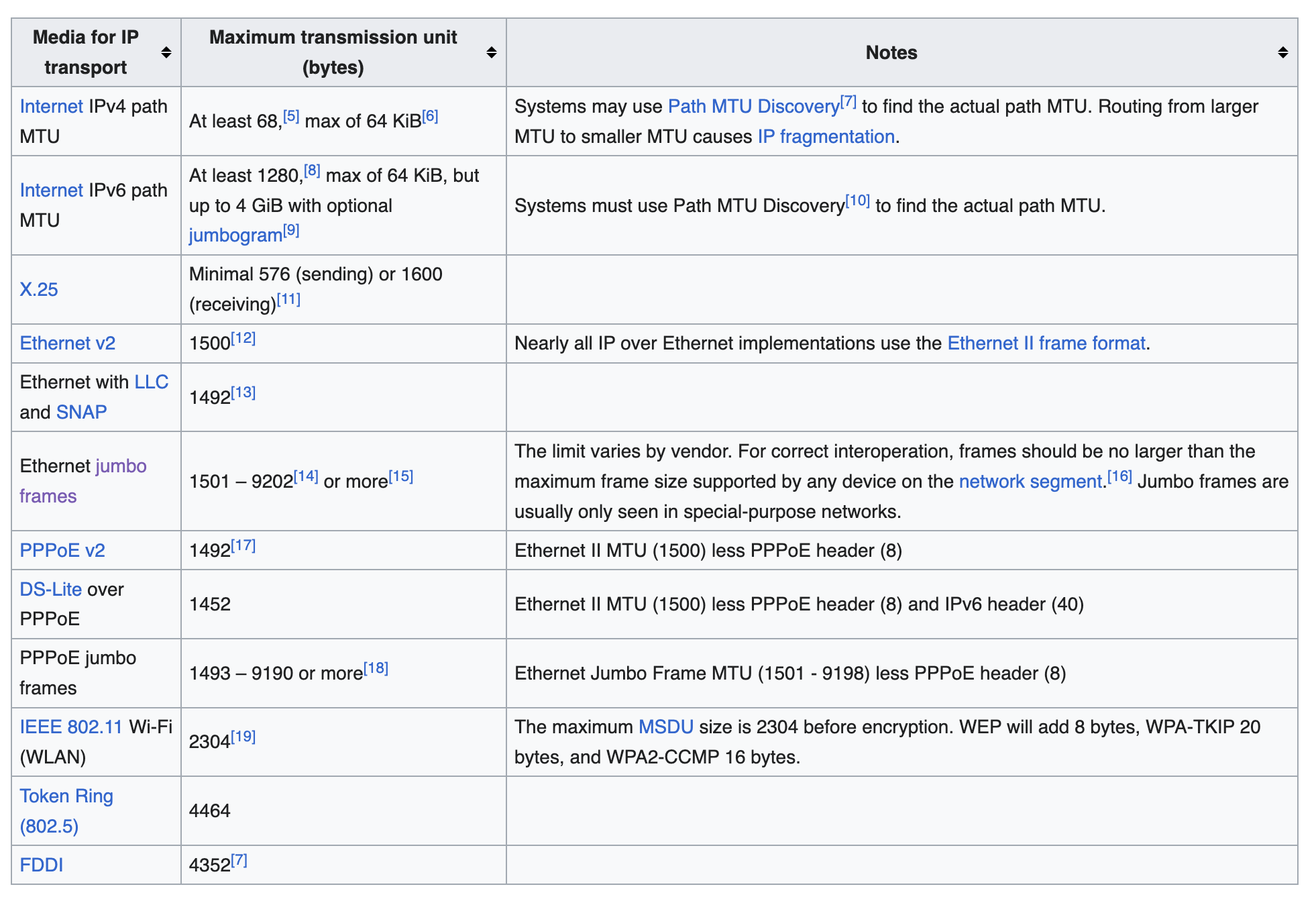
这就是为什么一般 MTU 都是 1500.
这里要提一下 Jumbo Frame,可以最大支持 9000 bytes,提高传输的速率。不过现实中基本上见不到,Internet 上更见不到。因为 Ethernet 是 2 层协议,负责点对点的传输,如果因特网上如果一个 Jombo Frame 要能从用户传到另一个用户或服务,这需要所有点对点设备都要支持才行。而现实的世界里,基本上网络上所有的路由,交换设备,端设备,路由器,设置的 MTU 都是 1500.
这就有了下一个问题:那如果超过了这个大小呢?
超过 MTU 的 Frame 会发生什么?
Drop. 这是最简单的处理方法。也是现实世界很多软件,硬件的处理方式。
但是显然这取决于软硬件的实现方式,比如 Cisco 的交换机就可以支持一个 Baby Giant feature(好可爱的名字): 交换机可以转发超过 1500 bytes ,但又不超过很多的 MTU。有些软件和设备支持类似 feature,有些不支持,大部分都会直接 Drop。
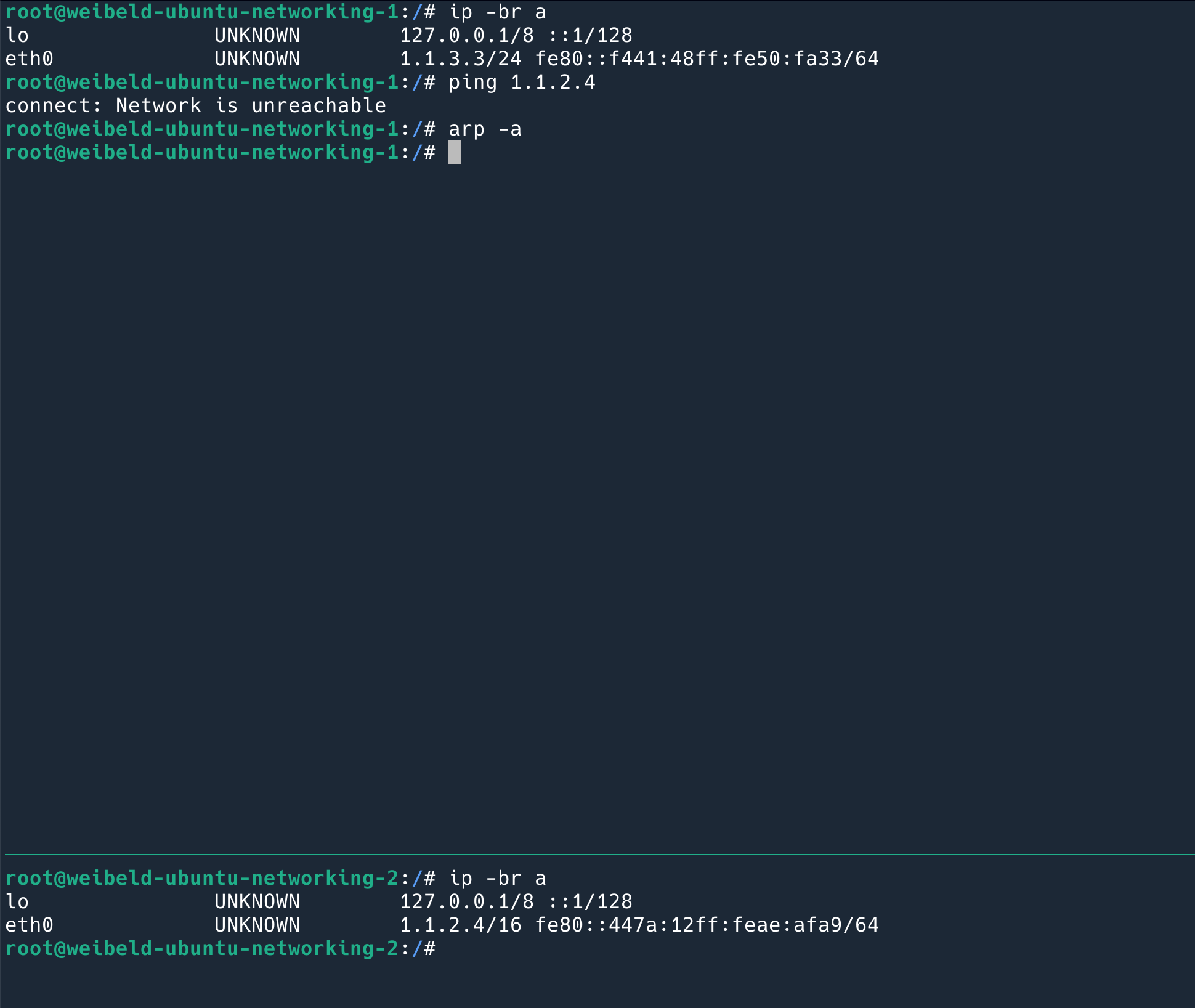
既然上文说到基本上所有的设备设置的 MTU 都是 1500,那么为什么还会出现超过 1500 的 MTU 呢?
什么时候发送的数据会超过 MTU?
最常见的是 VPN 和 overlay 网络。这种网络本质上就是将二层包再包一层,在底层互联网上建一个虚拟的二层网络。比如说 VXLan,它会在原来的 Ethernet Frame 基础上加一个 VXLan header,然后变成 UDP 包发出去。
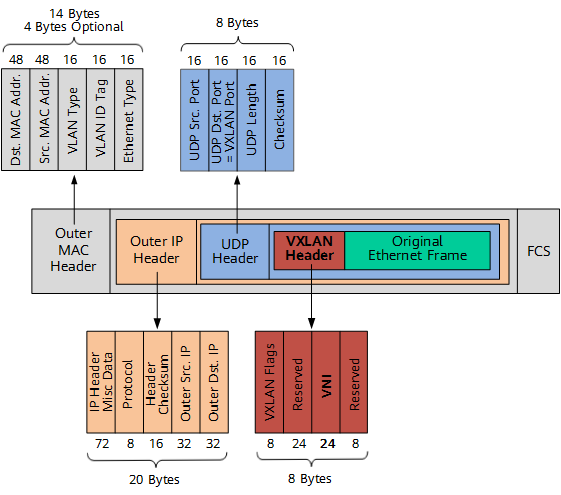
这样,假设我们原来的 Ethernet Frame 里面的数据是 1500 bytes,经过 VXLan 包装之后,就变成了:1500 + 14(原来的 Ethernet Frame header) + 8(VXLan header) + 8(UDP Header) + 20 (IP Header) = 1550 bytes, 超过了 50 bytes. (原来的 Frame 里的 FCS 不在里面,因为网络处理过了。)
如果抓包,就像下面这样:
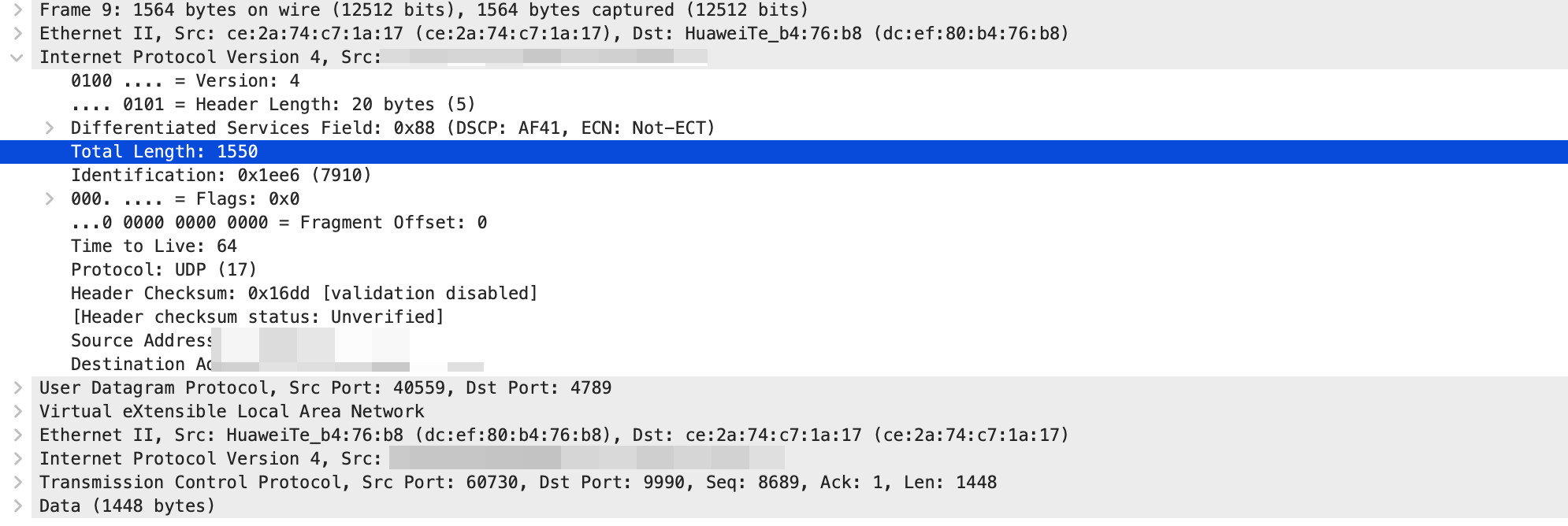
它是原来的 Ether II frame 变成了 UDP 的数据,被包起来了,又封装成 IP,Ether 发出去。
超过 MTU 的包大部分网络设备都会直接丢掉,所以我们就需要保证发送的数据不超过 MTU (上图是一个反例)。
如何保证发送的数据不超过 MTU?
很显然,我们需要分成多份发送。如果我们要让 2 层网络发送(意思就是包括 IP header 在内一共) 4000 bytes 的数据,那么就要分成 3 个 Etherframe 来发送:第一次发送 1500 bytes,第二次 1500 bytes,第三次 1000 bytes.
要让最终传给 2 层协议的 Frame 数据大小不超过 1500 bytes,就要保证上层协议每一层都没有超过这个大小。
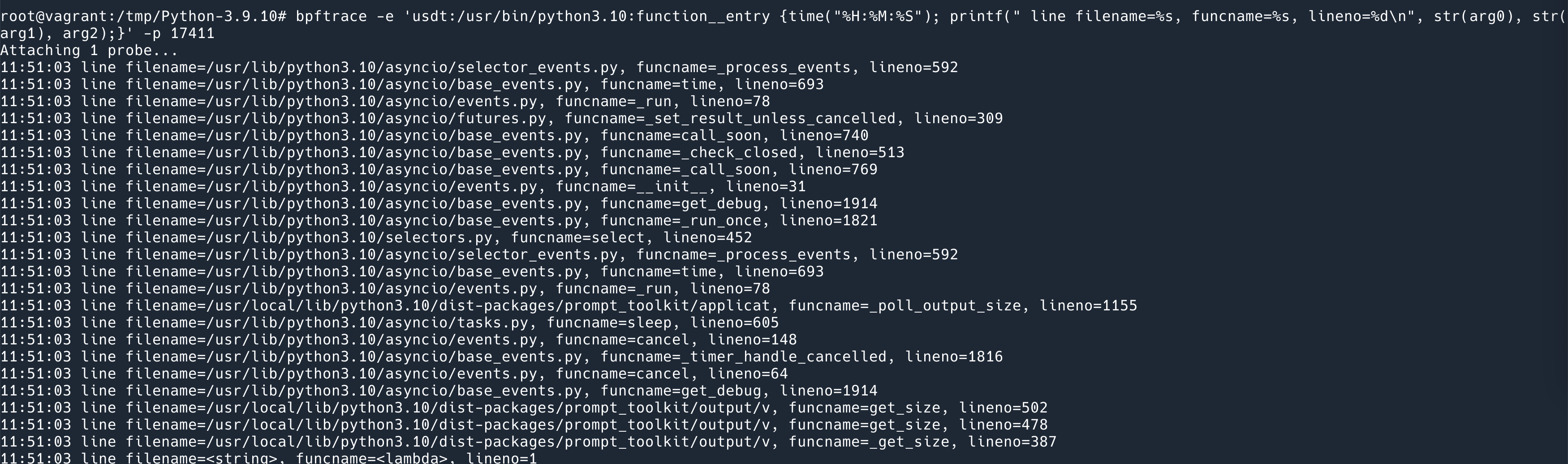
拿最常用的 4 层协议 TCP 来说,如果 MTU 是 1500,那么 IP 层就要保证 IP 层的 Packet 数据不超过 1480 bytes (1500 bytes – 20 bytes IP header), 对于 TCP 来说,它要保证每一个 Segment 数据大小不超过 1460 bytes (1460 bytes – 20 TCP header).
那么 TCP 层要怎么知道 2 层的 MTU 是多少呢?
- 网卡驱动知道 2 层的 MTU 是多少;
- 3 层协议栈 IP 会问网卡驱动 MTU 是多少;
- 4 层协议 TCP 会问 IP Max Datagram Data Size (MDDS) 是多少;
TCP 层的最大传输数据大小,就叫做 MSS (Maximum segment size).
对于 TCP 来说,我知道了自己这边的 MSS,但是其实并没有什么用,因为我作为接受端,收到的包大小取决于发送端,得让发送端知道自己的 MSS 才行。
所以 TCP 在握手的时候,会把自己的 MSS 宣告给对方。
MSS 通告
在 TCP 的握手阶段, SYN 包里面的 TCP option 字段中,会带有 MSS,如果不带的话,default 是 536. 对方也会把 MSS 发送过来,这时候两端会比较 MSS 值,都是选择一个最小的值作为传输的 MSS.
(博客显示的图片如果太小,可以点击图片放大查看)
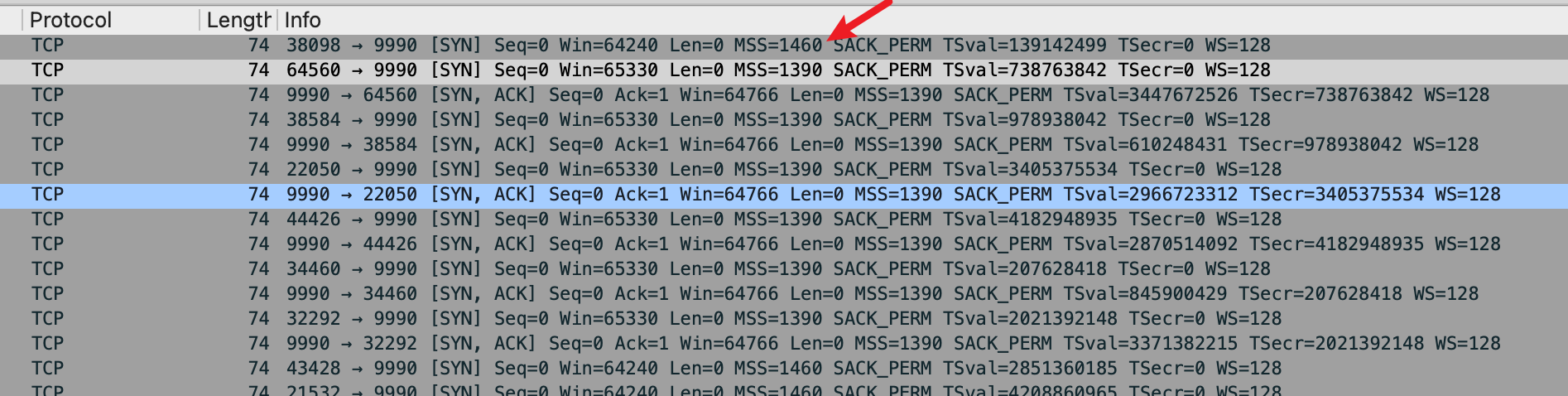
实际应用场景是什么?拿上文我们提到的 VXLan 封装举例,VXLan 封装的这一端知道自己需要 50bytes 的 overhead 来封装 VXLan,那么它就可以告诉对方,自己能接受的最大的 MSS 是 1410bytes (1500bytes MTU – 20 IP headers – 20 UDP headers – 50 bytes VLan),对方发过来的 MSS 是 1460 bytes(1500 bytes – 20 bytes – 20 bytes). 然后两端都会用 1410 bytes 作为 TCP MSS 值,即保证发送的 4层 segment 都不会超过 1410 bytes.
这里就有一个疑问:为什么 MSS 两端都使用一个共同的值,而不是 A -> B 1410 bytes; B -> A 1460 bytes, 这样不是可以更高效吗?
这个问题的答案我找了好久,感觉很多地方说法不一,比如这里就说:
TCP MSS is an option in the TCP header that is used by the two ends of the connection independently to determine the maximum segment size that can be accepted by each host on this connection.
但是很多地方也说两边的 MSS 会一样。
这个我自己测试了一下,手动调整一端的 MTU,另一段不调整,发现两端发送数据都会比较小的值。
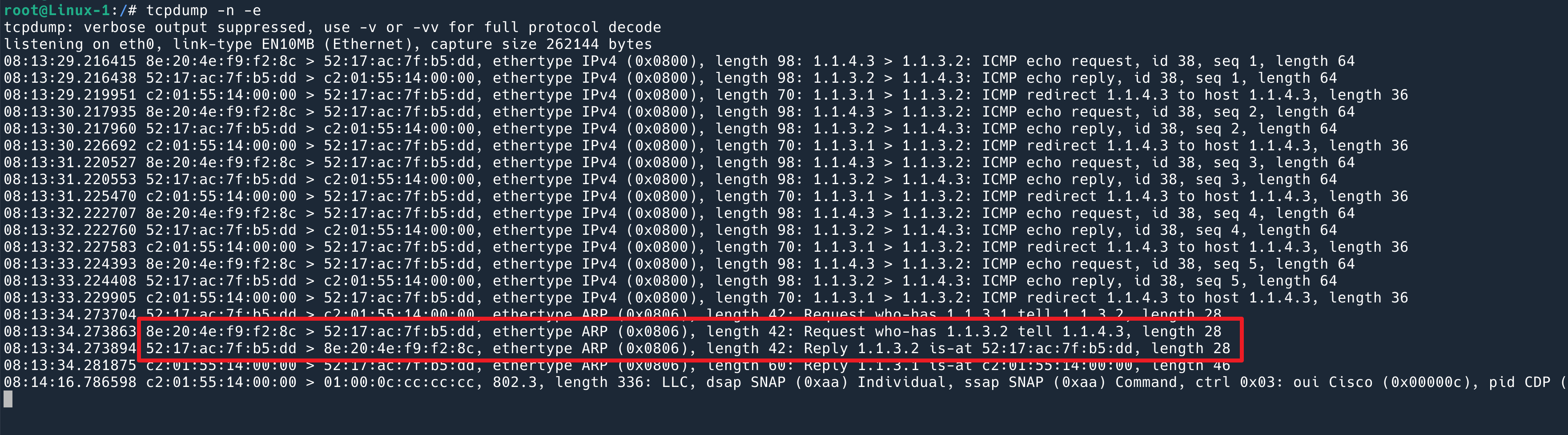
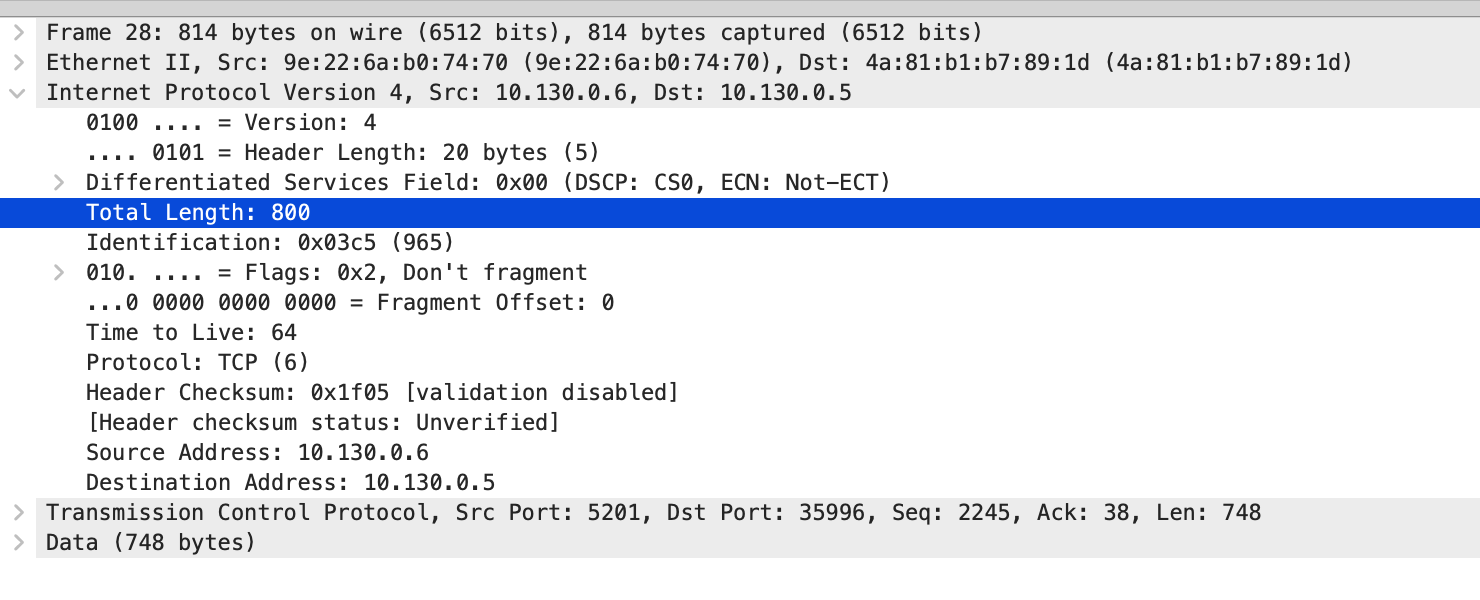
MTU 一段设置为了 800,另一段是 1500,在 TCP 握手阶段可以看到。

从 10.130.0.6 发送给 10.130.0.5 最大的包是 800.
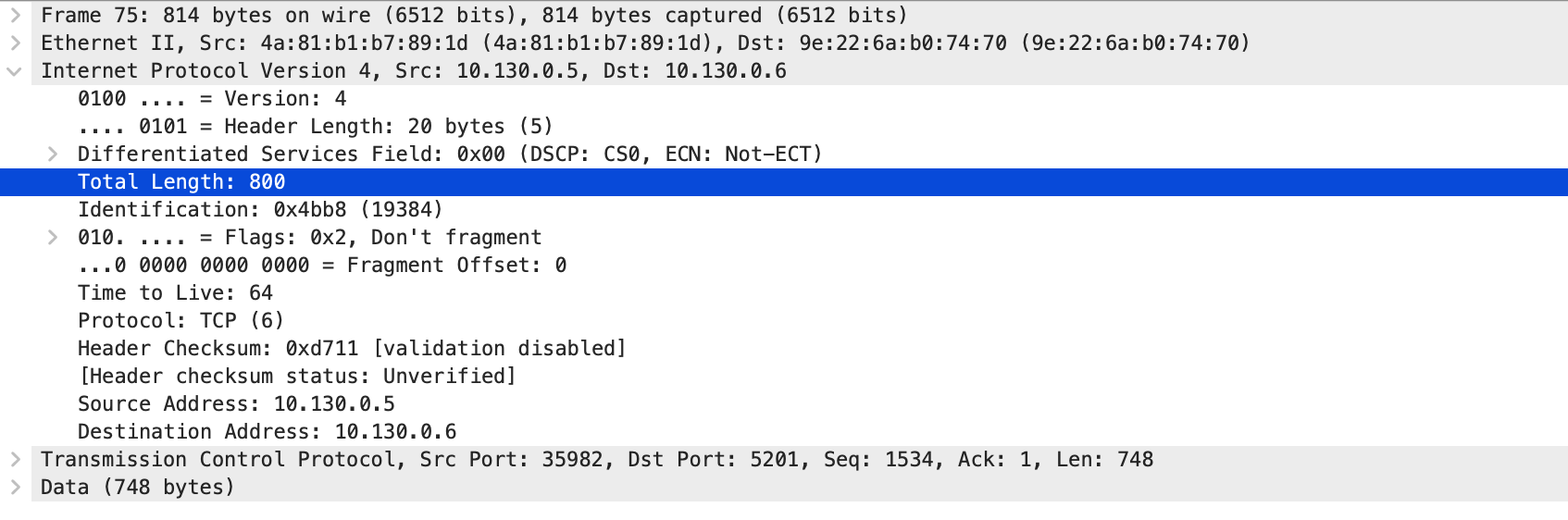
从 10.130.0.5 到 10.130.0.6 也是 800.
为啥双方用一个共同的最小值,这个我没找到确凿的原因,我觉得理论上两端分别用 MSS 是可以的,就像 TCP 的 rwnd 一样。但是,在现实的网络上,A 发送 B 有限制,那么 B 发送到 A 很大可能也有一样的限制。所以两边会把这个 MSS 作为链路上某一个点的瓶颈。毕竟,每一端都只知道自己这部分网络的情况,最好是基于自己和对方综合的信息来做决策。
MSS 设置的方法
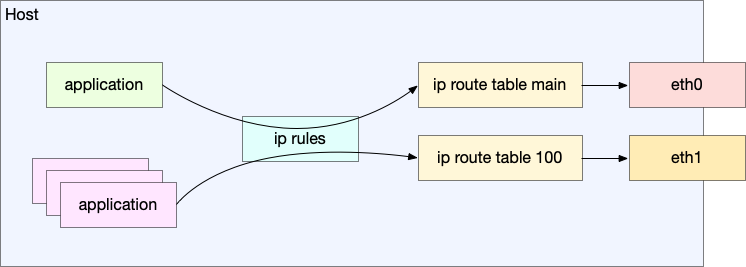
如果已知有明确的网络情况,可以调小自己的 MSS,设置的方法有 3 种:
- iptables:
iptables -I OUTPUT -p tcp -m tcp --tcp-flags SYN,RST SYN -j TCPMSS --set-mss 48 - ip route:
ip route change 192.168.11.0/24 dev ens33 proto kernel scope link src 192.168.11.111 metric 100 advmss 48 - 程序可以自己设置,本质上是自己往 TCP option 里写 MSS:
|
1 2 3 |
from scapy.all import * ip = IP(dst="192.168.11.112") tcp = TCP(dport=80, flags="S",options=[('MSS',48),('SAckOK', '')]) |
当然了,也可以直接调整网卡上的 MTU:ifconfig eth0 mtu 800 up. 这样 Kernel 的 TCP 栈在建立连接的时候会自动计算 MSS。(上文写过的这个过程)
我们这里说的都是 TCP 两端的设备如果清楚自己的网络情况的话,可以进行的一些设置。还有一些情况,比如说一些 VPN 和 overlay,端对此并不知晓,完全是中间的路由设备做的。中间设备需要预留 50bytes,有什么方法可以让两边都知道,发送的数据包要预留 50bytes 呢?
MSS Clamping
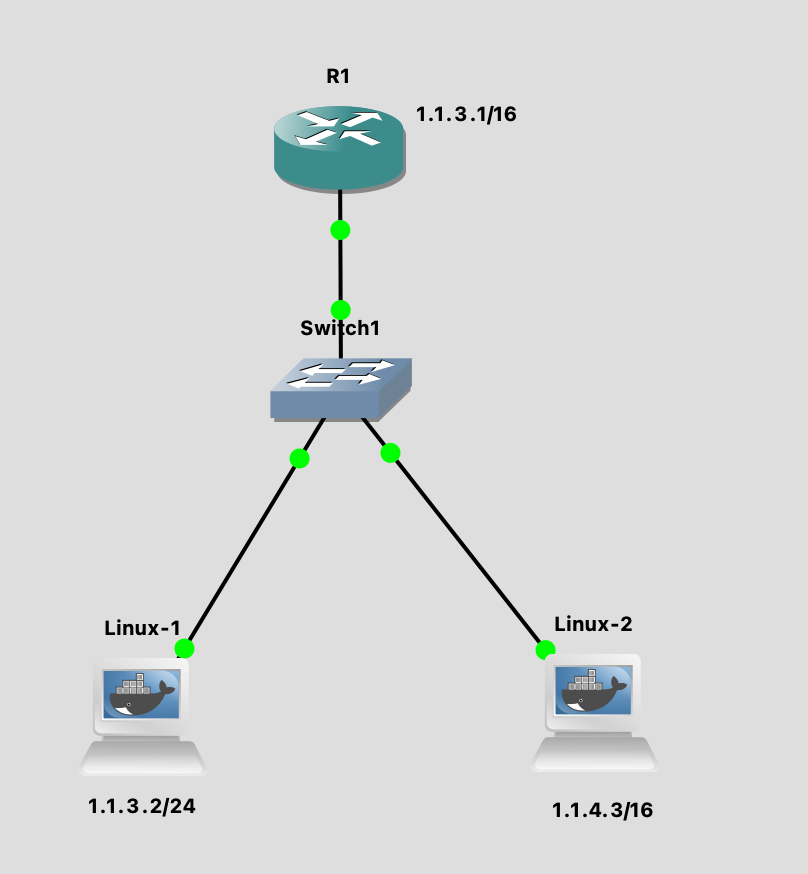
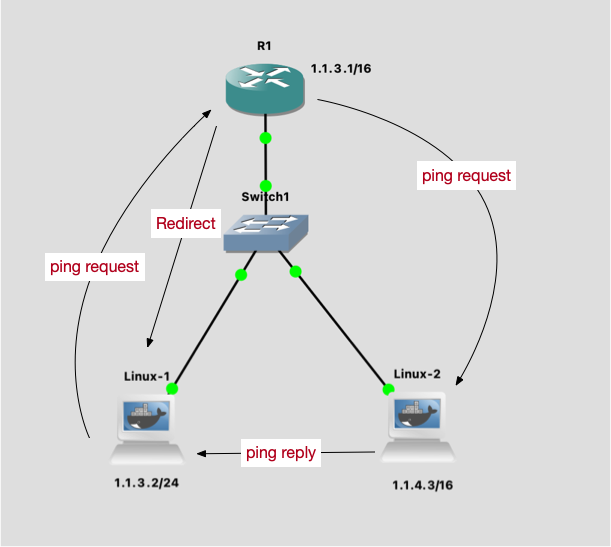
我们在一个 VPN 环境中测试一下,网络结构可以简单地理解为 [Client -> VPN] -> Server.


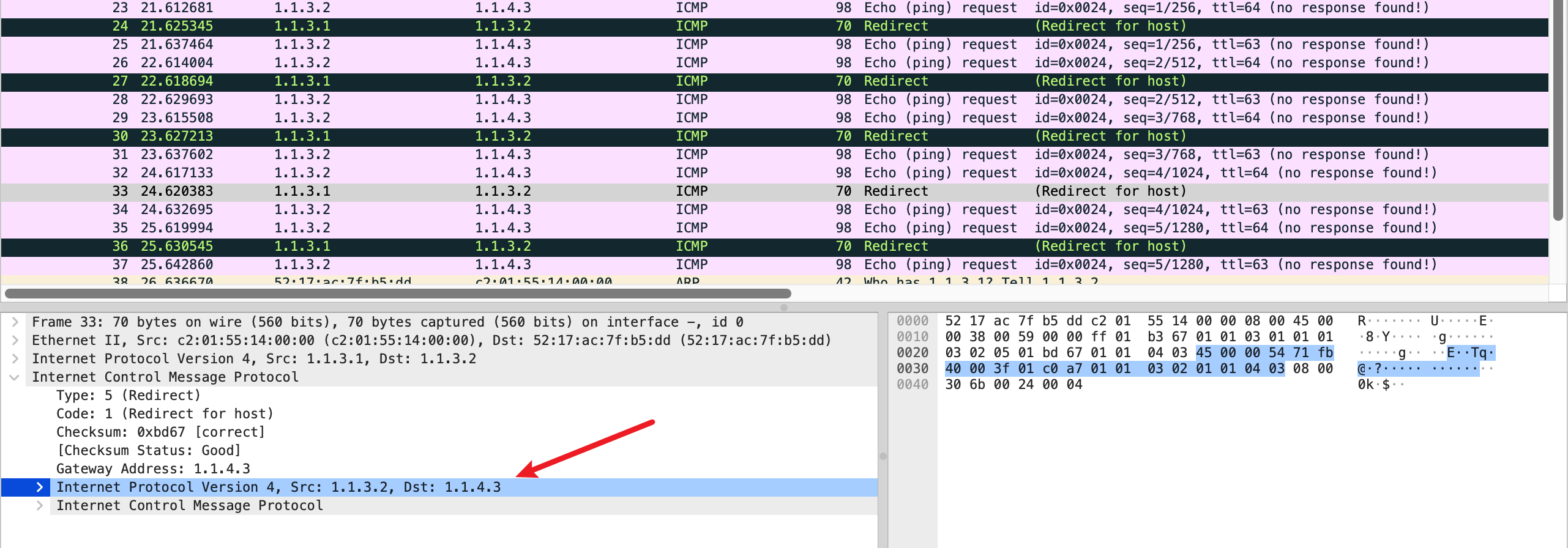
仔细观察 TCP 建立连接的过程,可以发现 Server 端抓包,发现 Server 发送给 Client 的 MSS 值是 1460 bytes,但是 Client 收到的时候变成了 1190 bytes.
这意味着,除了 TCP 的两端,中间的路由设备也可以做 MSS Clamping,影响两端选择 MSS 的过程,以确保网络中为其他协议的 overhead 预留出来了足够的空间。
以上说的都是,协议的每一层,都确保了自己递交给下一层协议的数据单元都没有超过下一层协议的最大长度。但是我们并不在一个完美的世界中,假设协议收到了超过最大数据单元的数据,会怎么做呢?
其实,每一层协议自己都会有机制,让自己发送的内容不超过下层协议能承载的最大内容(最大 PDU)。
We are not in a perfect world after all…
我们从下往上讲起。
Layer 2
二层协议一般都很简答,如果收到了超过 MTU 的包,一般会简单地 drop 掉,要依靠上层协议来保证发送的数据不超过 MTU。
但是也有协议可以支持拆分(Fragment),比如二层的 MLPPP。
Layer 3
IP 层的处理就比较经典了,自己收到的是上层协议发给它的内容,然后要负责通过 2 层来发送出去,上层的内容是无法控制的,但是要控制自己发送到下层的内容。
所以 IP 支持一个 feature 叫做 IP Fragmentation.

如果 IP Packet 超过了 1500bytes,IP 协议会将这个 packet 的 data 段拆分成多个,每一个分别上 IP header,以及 fragment header 标志这是拆分成的第几段。 接受端等收到所有的 IP 分片之后,再组装成完整的数据。
我们可以通过 ping 来发送一个超过 MTU 1500 bytes 的数据。ping -s 2000 -I 172.16.42.21 172.16.42.22
抓包如下:
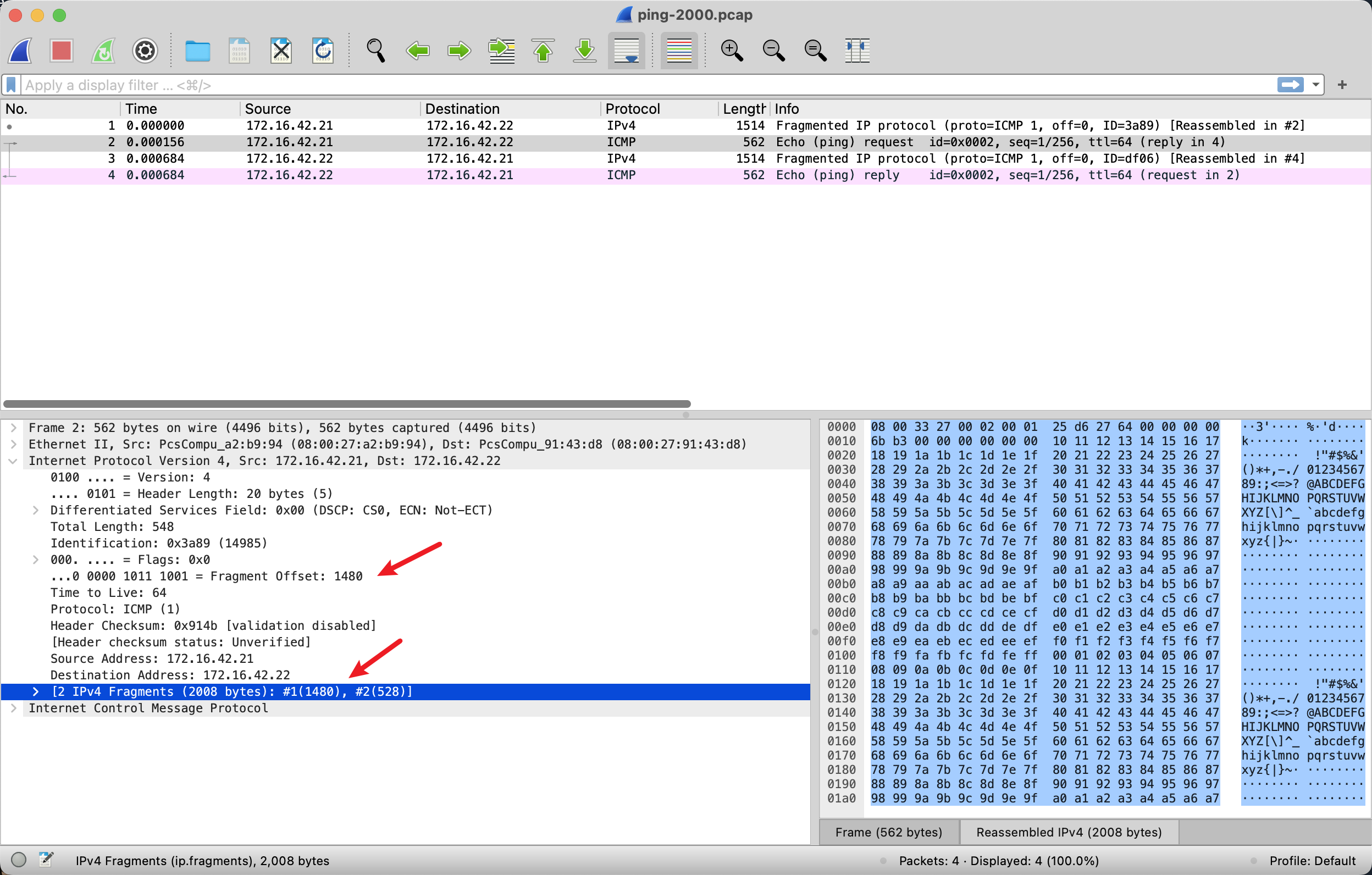
可以看到一个 ping 一共有 4 个 IP 包,2个完成 Echo 2 个完成 Reply. 其中 Echo request,第一个 IP 包总大小是 1500 bytes,除了 IP 包的 20bytes header,还剩下 1480 bytes 是 ICMP 的数据,第二个 IP 包里面有 528bytes 是 ICMP 数据,两个 IP 包带的数据一共 2008 bytes,是符合我们的预期的,8bytes 是 ICMP 的 header。
由此,可以发现 IP Fragmentation 其实是把上层的数据拆分到多个 IP 包里面,不管上层的数据是什么。说白了,第一个 frame 有 ICMP 的 header,第二个 ICMP 包没有。如果把承载 ICMP 协议换成 TCP 协议,我们就可以发现问题了:收到了 IP framented frame,是无法处理的,因为这个 IP 包的数据对于上层协议来说是不完整的,假设一个 IP 包被 fragment 成了 3 个 IP 包,我们就必须等到 3 个 IP 包全部到齐才可以处理。
所以说:IP Fragmentation is generally a BAD thing.
可能导致的问题有:
- 同上面提到的 MTU 为什么是 1500 一样的问题:假设拆分成了 3 个包,丢了一个包就相当于全丢了,丢包率直接变成(假设丢包率是 10%,那么3个包都不丢的概率就是 90%^3=72.9%)27%;
- 导致 TCP 乱序:现在网络很多设备都是针对 TCP 做优化的,比如,根据 TCP 的 port number 去 hash 到同一条路由上去,减少 TCP reorder 的概率。但是如果 IP fragmentation 发生的话,后续的 IP 包在路由器看来并不是 TCP 包,因为 TCP header 只在第一个 fragment 上才有,所以会导致 hash 失效,从而更容易发生 TCP 乱序;另外,对段会等齐所有的 fragment 到达才会交给上层,这也导致了延迟增加和乱序的发生;
- 产生一些比较难 debug 的问题;
- 不是所有系统都能处理 IP Fragmentation,比如 Google GCE;
此外,IP Fragmentation 本身就存在一些攻击面(见文末),我猜这也是 GCE 关闭了 IP Fragmentation 的原因?
所以,在现实的世界中,我们几乎看不到 IP Fragmentation 的,要依靠上层协议保证传给 IP 层的数据大小不需要 fragment.
Layer 4
上文已经提到了 MSS。但是我们平时写应用程序的时候,从没有自己分过 Segment,这是因为 TCP 是面向数据流的,你有一个 socket 之后,尽管向里面写就可以了,Kernel 的协议栈会负责给你将数据拆成正好能放到 IP 包里的大小发出去。注意这里是拆成多个 TCP segment 发送,在 IP 层并没有拆开,每一个 IP 包里面都有 TCP 的 header。
Layer 3 的 IP Fragment 会导致这么多问题,我们宁愿这个包被丢弃,也不要分成多个包发送。
DF(Don’t fragment bit)
IP 协议的 header 中有一位 bit 叫做 DF,如果这个 bit 设置了,就是告诉中间的路由设备不要分片发送这个包,如果大于最大传输单元的大小,直接丢弃即可。丢弃这个包的设备会发回一个 ICMP 包,其中,type=3 Destination Unreachable, Code=4 Fragmentation required, and DF flag set. RFC 1191
用 tcpdump 我们可以这么抓 ICMP 包:tcpdump -s0 -p -ni eth0 'icmp and icmp[0] == 3 and icmp[1] == 4'
发送端收到这个错误,就需要降低自己的 MSS 重新发送,重复这个过程,直到 MSS 满足条件为止。这个过程就做 PMTUD, 中间路径上的 MTU 探测 RFC 4821.
在 IPv6 中,行为基本上是一样的,但是 IPv6 没有这个 DF flag,所有的 IPv6 包都禁止中间的路由设备进行分片,也就是说等同于 IPv6 包永远是 DF=1,遇到 MTU 太大丢包发回来的是 ICMPv6(Of course!)
这里有一个问题,就是如果一些中间设备,因为安全原因(下文会解释)禁用了 ICMP(ping), 这样可能导致的问题是,TCP 连接能建立成功,但是数据一直发不出去,造成黑洞连接 RFC 2923。解决这个问题的核心,是要区分丢包到底是中间链路造成的,还是 MTU 太大造成的。TCP over IPv4 感觉没有特别好的办法,最好是允许 type 3 的 ICMP 包。RFC 4821 提出了一种不依赖 ICMP 的 PMTUD 方法,本质是使用小包开始,逐渐增大大小直到达到 MTU 上线,和 TCP 拥塞控制有异曲同工之妙。
至于这个“安全原因”,就比较有意思了。举一个例子:如果攻击者知道服务端的地址,即使攻击者不在 Client – Server 的路由链路上,它也可以发送一个 ICMP 包告诉 Client MTU too large, 让这个连接的双方降低 MSS 从而降低性能。
还可能有另一个问题,有些 DC 可能用了 ECMP 技术,简单来说,一个 IP 后面有多个服务器,ECMP 会根据 TCP 端口,和 IP 来做 hash,这样可以根据 IP + Port 来保证路由到正确的 Server 上,即使 IP 一样。但是对于 ICMP 包来说就有问题了,ICMP error 包可能被路由到了错误的服务器上,导致 PMTUD 失败。Cloudflare 就遇到过这个问题。
说到这里,基本上就讲完了最近看的资料和自己的实验的内容,因为是一边学习一边记录的笔记,所以可能有不正确的地方,还望指正。
下面说两个有意思的问题。
道理我都懂,但是我的抓的包怎么大??
如果你通过抓包去看一下 MSS 是否是有效的,里面每一个包的大小是否最大是 1500 bytes,你会怀疑人生。
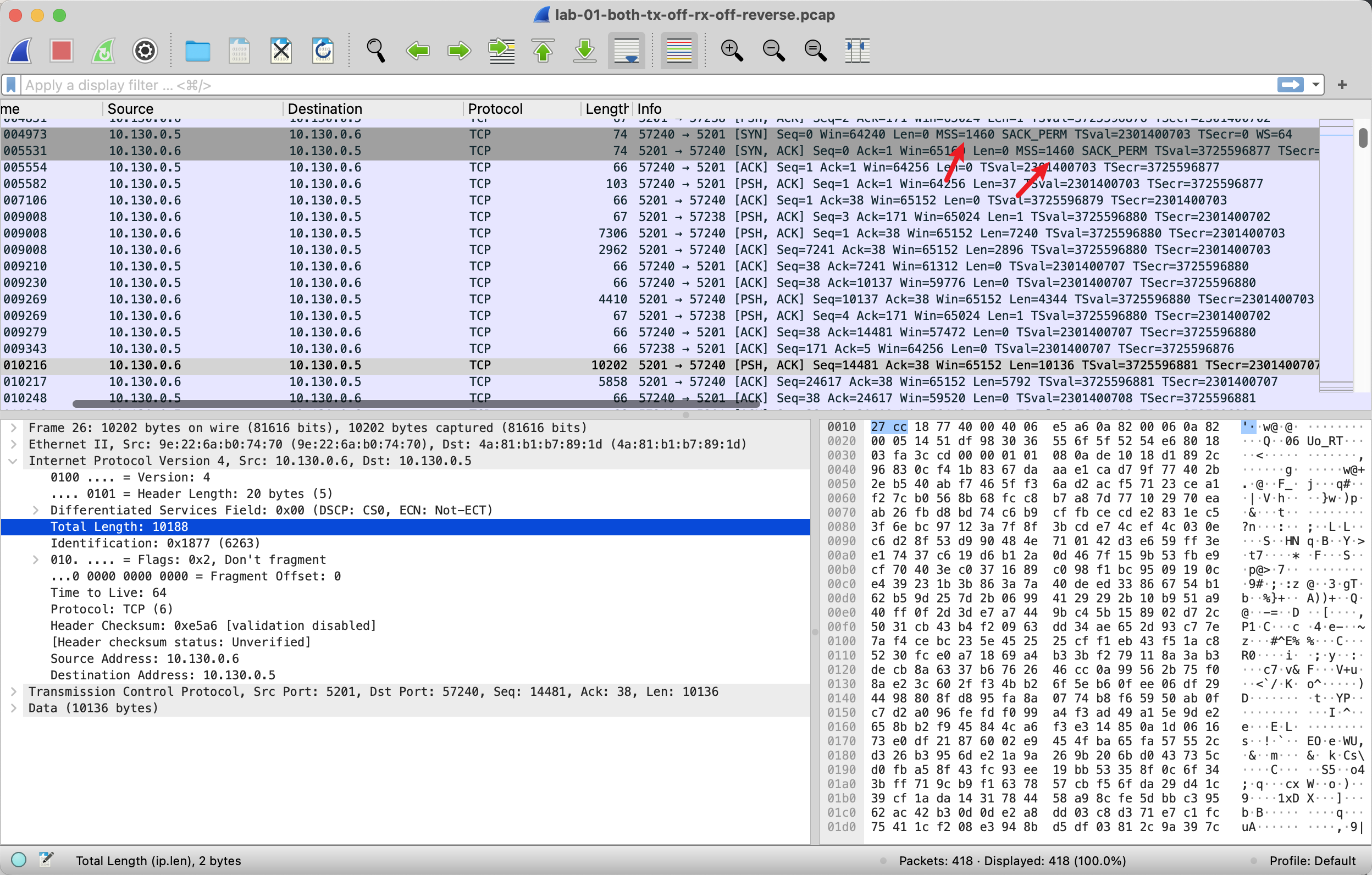
明明协商的 MSS 1460,但是后面的数据居然有 1万多bytes的??在接收端抓包也一样。
这个叫 TSO,TCP Segment Offload.
上面我们讲为了不发生 IP Fragment, Kernel 协议栈要负责把 TCP 分成一个个不超过 MSS 的小包发送,这部分工作是简单重复并且计算量比较大的,很显然,适合网卡来做这个工作。
所以 TSO,就是网卡 Driver 告诉 Kernel,这个工作可以交给我,做拆包我一直可以的,我可以一直拆包的,于是,Kernel 就发大包到网卡,网卡完成大包拆小包。
但是对于抓包来说,我们看到的就是 Kernel 发送了大包,因为抓包过程是看不到后面网卡具体做了什么的。
如果我们关闭 TSO 功能: ethtool -K eth0 tx off。然后再抓包,你就会发现抓到的每一个发送的包都是 1500 bytes 了。
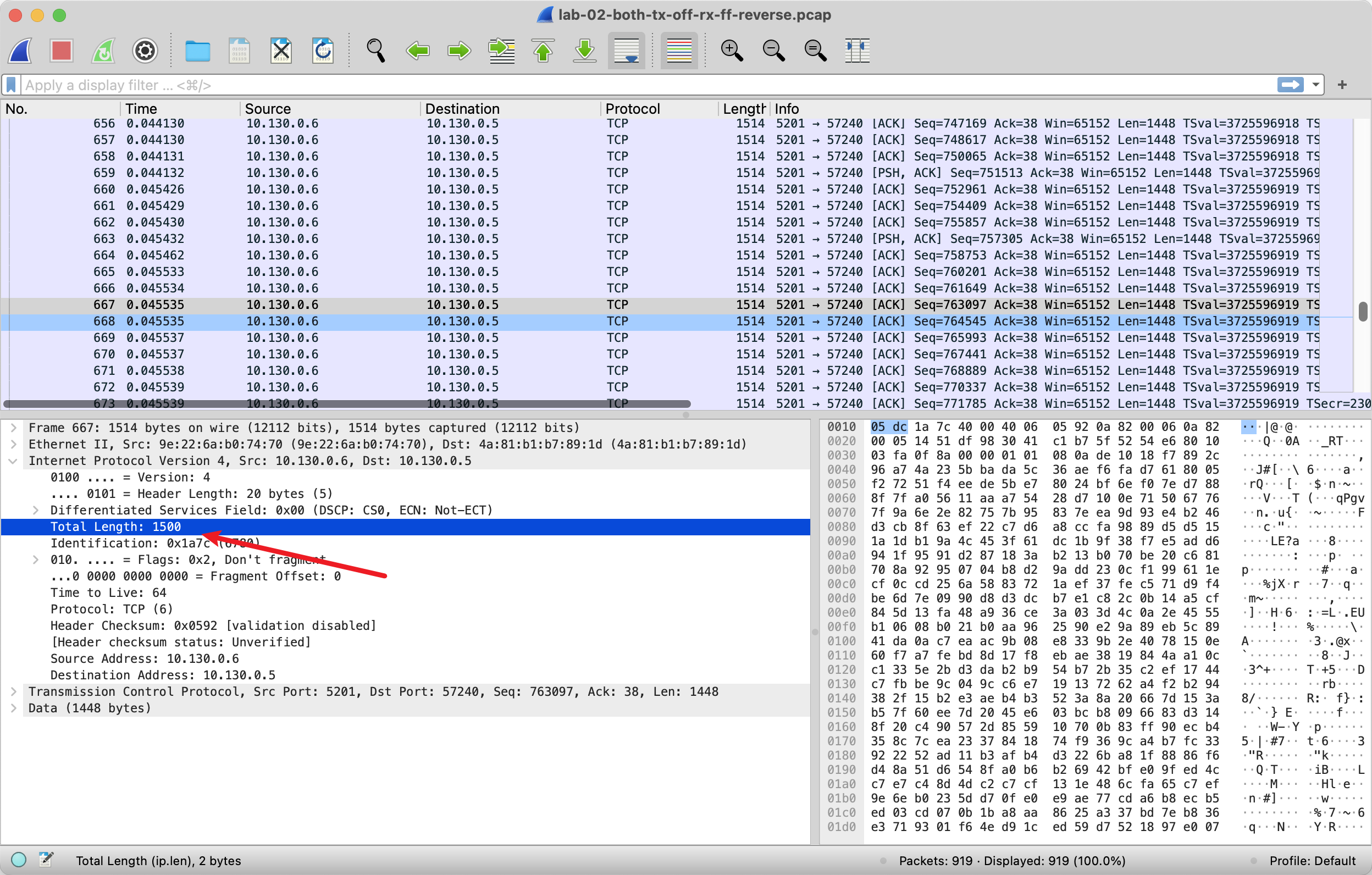
但是即使你按照 1500bytes 发送,然后这时候去接收端抓包,会发现还是有大包。发送端发送的都是小包,为啥到接收端就成了大包呢?显然网卡可以对发送做 offload,也可以对接收做 offload,网卡会攒一些 TCP 包,然后合起来发送给 Kernel 的协议栈。
这减轻了 Kernel 的不少 CPU 负担,转移到了硬件上完成。但是……分析 Sequence number 就是一个 pain in the ass 了。
第二个是工作中遇到的问题,也是我看这些东西的起因。
我们的 SDN 网络有一种这样的路由:
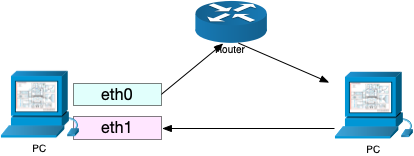
一种奇怪的“三角路由”,其中 Router 会添加 50bytes 的额外 header,然后发现 Router 这里发生了丢包。
最后发现,原因是我们对 eth0 设置了 MTU = 1450,但是忘记设置 ip route,导致握手阶段的包从 eth1 出去了,eth1 的默认 MTU 是 1500,PC 发送的 MTU(MSS actually) 也是 1500,就导致双方一致认为 MTU=1500,MSS=1460. 但是实际上到 Rrouter 这里加了 50bytes 的 overhead,就造成了丢包。
前面提到 IP Fragment 有很多安全问题,这里列举了其中一些:
- IP fragment overlapped:攻击者精心设计了很多 IP 分片,它们互相重叠,理论上这种包是无法在网络上出现的。如果服务器收到这些分片,可能无法正确处理(IP 实现的 Bug),那么可能会崩溃;
- IP fragment overrun:攻击者通过 IP 分片的方式,发送的 IP 包组装之后超过了 65535,可能造成服务器崩溃(溢出);
- IP fragmentation buffer full:攻击者一直发送 IP 分片,more-fragments 一直设置为 true,导致服务器收到 IP 包的时候,只能存储在 buffer 中试图将它们组装起来,直到内存耗尽 (DDoS);
- 其他构造的无法正确组装的 IP 包。可能导致 DDoS,或者可能导致 IDS(入侵检测系统)无法正确组装并识别这些包,导致这些包绕过安全系统进入了服务器,最终构造出攻击。参考 Rose Fragmentation Attack
- IP fragment too many packets
- IP fragment incomplete packet
- IP Fragment Too Small
参考资料,文中嵌入的链接就不再单独列在这里了: