上回书说到,旅行刷新了去过的最南端。上周又去了印尼,这次去刷新了去过的最高点。我们去 Lombok 爬了 Rinjani 火山。
与其说是旅行,这次更像是一个修炼,体力和耐力的挑战,回来之后身心俱疲,跟之前去旅行度假完全不同。
Rinjani 是印尼第二高的火山,一共 3726 米。火山相比于其他的山,有很多奇特的地方,比如奇特的地貌,火山湖,路上的火山灰等等。
这也是我第一次爬火山(可能也是最后一次了)。这篇还是流水账地记一记这几天的行程吧,如果你也想去的话,我在本文最后写一些注意事项。
Day 0: 到达 Lombok,看瀑布
第一天坐飞机愉快地到达了龙母岛 (Lombok),此时开开心心,完全没有意识到事态的严重性。
从机场到酒店需要 3 个小时,比较远。我们是直接住在了山脚下,如果爬山那天长途坐车的话,实在是吃不消。
路基本上是沿着岛的海岸线修的,所以路上左边时常可以看到大海。
我们住的酒店是 Rinjani Light House, owner 是一个美国人,看得出来老板很喜欢咖啡,店里有很多和咖啡相关的书籍和张贴。
酒店很漂亮,是很有乡村气息的小屋。价格也很便宜(比在新加坡租房都要便宜)。

酒店很漂亮,天气凉爽
办好入住之后,我们就去附近的一个瀑布逛一下。没想到的是,去这个瀑布要下这么多楼梯。回来的时候,几乎已经累倒了。

瀑布,在瀑布下感受水汽

瀑布入口,可以看到 Rinjani 山
瀑布的门票 2万 Rp。
晚上就早早的吃过饭,爬山的公司(我们选择的是 Rinjani Dawn Adventures)来酒店坐 briefing。告诉我们大体的路线和答疑解惑。通行的游客也可以互相认识一下。和我们同一家公司的有一队新西兰年轻夫妇,两个加拿大阿姨。但是大家其实不是一起走的,我们两个人是单独一个团,包括了一个 Guide 和 2 个 Porter,应该是每两个人都是这么个配置。Porter 会帮我们带食物,3 天的引用水,帐篷睡袋等。我们自己要背其他所有的个人物品,包括衣服,工具,等等。几乎一直要背一瓶 1.5L 的水,喝完了再跟 Guide 要一瓶,自己喝的水自己背着。(第二天才知道,加拿大阿姨的团还挺高级,人家自己不需要背东西的,Guide 可以帮忙背,可能买的套餐更贵吧,笑)

团队过来坐 briefing
Day 1: 从 Sembalun 出发,下午到达营地
早上6点起床,车准时来接,加拿大阿姨跟我们住同一家酒店,我们一起上车,然后去接上另外两个人。到了他们公司,又做了一次 briefing。
在公司 briefing again
在这里如果自己缺什么东西的话,可以跟他们借,比如头灯,冲锋衣什么的。最好重新检查一遍自己的装备,因为要带的东西很多,难免有遗漏。
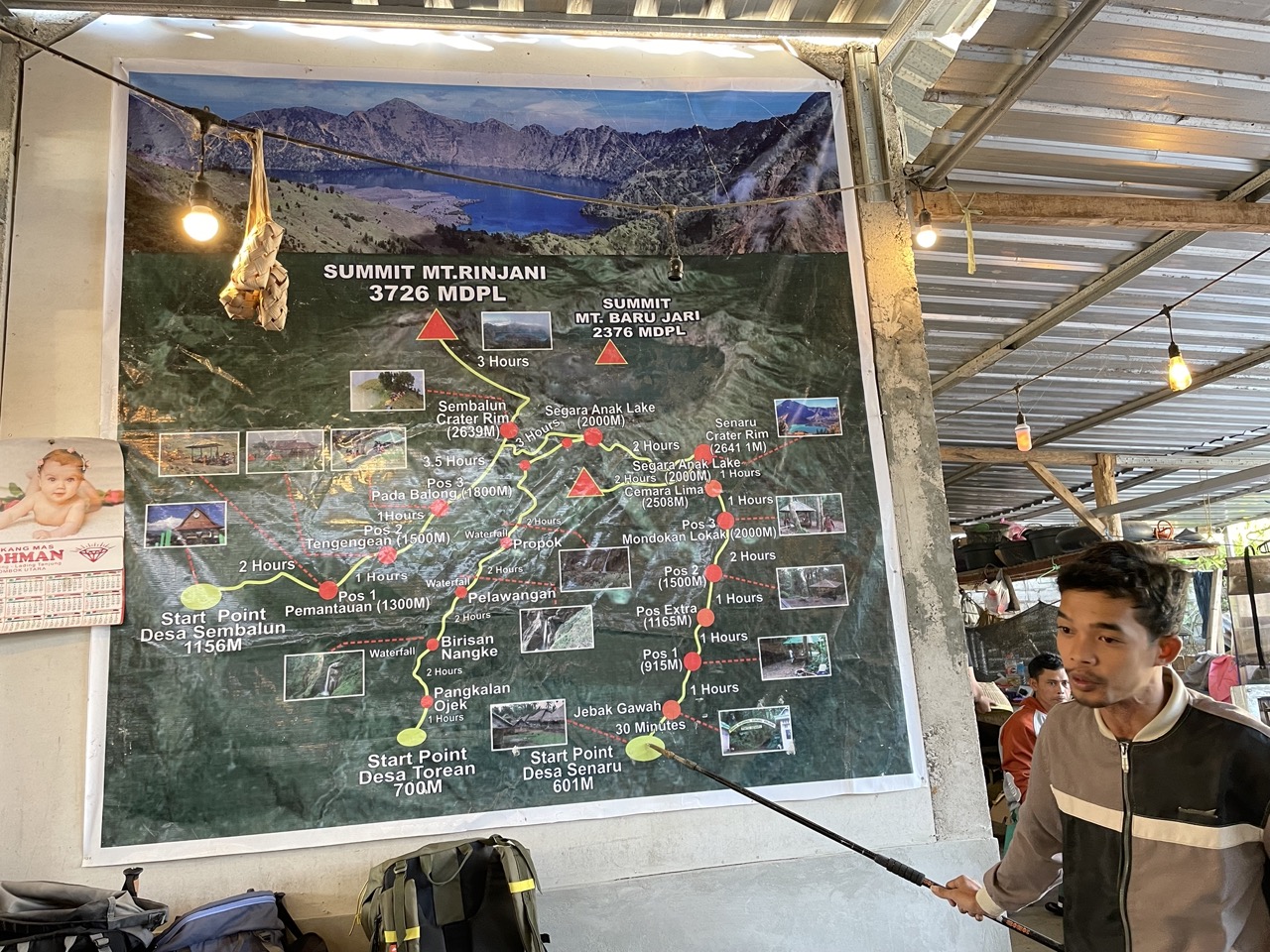
一切就绪就发车去起点。我们的路线是 Sembalun 上山,Senaru 下山。
去出发点之前先去了一个地方做 Medical Checkup. 其实就是填了个表,量了血压。然后再次坐车,终于到了出发点,我们的行程正式开始了。

到达山脚下
Porter 大队,很快就超过了我们,而且……都穿着人字拖。后面遇到了很多非常陡峭的路,近乎直上直下了,有些地方要借助绳子,梯子,不知道这些路 Porter 都是怎么过去的……

很快被 Porter 大队赶上了
今天的路线中,Pos 1 到 Pos 3 都很简单,路比较平缓,大概三个小时左右就可以了,但是 Pos 3 到营地非常陡,虽然路在地图上看起来很短,但是需要 3-4 小时。

路上的风景

POS1 路标
到 Pos 2,Porter 已经在等着我们了,我们到了之后他们就可以做午饭。

大家都在 POS2 吃饭
每一顿饭都有一个主食,软饮料,热饮料,水果盘。非常丰盛,每一顿都吃不完。

食物很赞
吃完饭之后继续出发。第一天感觉状态良好,在能力范围内,坚持一下就到目的地了。最后一段路上已经有一些火山灰了,比较滑,还摔了一跤。
从 Pos 3 往后,路上就是云雾缭绕的了,天气非常凉爽,虽然有些湿,但是因为不闷热,所以也还挺舒服。

路上云雾缭绕
在下午5点左右到达了营地。远处可以看到第二天要去的顶峰,此时还有一些云雾。不过过了一会就全散了,天空非常蓝,很纯净。几乎可以用风和日丽来形容,运气比较好。在这里欣赏了一个完整的日落。

到达营地




远处可以看到 Rinjani 山,来的比较早,看到了一个完整的云雾散去到日落的风景,很赞

无人机拍摄的营地
太阳下山之后,气温马上就降低了,今晚的饭正好是热汤,端在手里感觉非常幸福。哦对了,饭前吃了炸香蕉饼,也很好吃,只不过被猴子抢走了一个。

我们的帐篷

看着日落吃晚饭

观看日落


日落
吃过晚饭之后就钻到帐篷里面了,为第二天的冲顶养精蓄锐。
晚上睡觉还有一个小插曲,来了一只动物绕着我们的帐篷嗅了一圈,应该是野猪。
Day 2: 凌晨 2 点冲顶,下午徒步 6 小时到达第二个营地
凌晨两点准时起床,这顿饭是 extra breakfast,只是一碗泡面而已,事后证明根本不够。
冲顶的路分成三段,第一段是从营地走到山脊,非常难走,路上有梯子,绳子。大部分地形是在树林里面。路上可以看到远处一片亮闪闪的头灯。
第二段是沿着山脊上山,虽然坡度也不小,但是刚完成了第一段,会觉得这里好简单。
最后一段简直是让人绝望。整段路都是火山石,非常滑,走两步滑一步,又陡峭,两边的大斜坡看着像悬崖一样。

路海拔高,还比较陡
我的力气就在这一段感觉很快耗尽了,此时我们的海拔从营地的 2600m 上升到了 3000 多米,最后的 600m 尤为困难。此时的感觉就是迈不上去腿,无法使出力气,头感觉轻飘飘的,像随时要晕倒一样。(后来也有这个感觉,总结发现超过2000米就会这样,下降一段会好很多,应该是高原反应)。
时间已经到了6点,去山顶看日出是赶不上了,好在我们发现半山腰的日出也很美。就在这里看完了日出再继续。

在半山腰等日出
Guide 说他可以帮我,我可以拉着他的手。这时实在是一点力气都没有了,于是最后几百米大概就是这么上去的……
终于到达了山顶,其实说实话山顶的景色比较一般(可以对比一下后面下山的时候拍的照片)。在山顶稍作休息,我们就开始下山了。

山顶的风景 3726m
下山不需要什么力气,但是因为太阳出来了,马上就变得很晒,我们穿的又比较多,所以感觉被太阳 dry out 了。路上休息的不多,一路上想着感觉回去。

好像最近挺流行这么拍照
路上遇到了一只小猴子。

因为海拔比较高,所以路上都没有什么植物,一路顶着烈日,最后终于回到了营地,已经是筋疲力尽了。

这天中午的午饭又是油炸食品(感觉印尼的食物风格就是油炸,味精放的比较多),实在是没什么胃口,但是也强咽了几口。
时间已经是 10:45 了,回到营地的时候帐篷少了很多,一些团队已经开始下山了。因为我们下午还有六个小时的徒步(路上一想到这里就有一些绝望,笑,不过最后还是走下来了),所以吃完饭之后就抓紧收拾行李准备出发。
这里说一下行程:
- 最难的是我们这种 3D2N (三天两夜)的,第二天冲顶完成之后,下午要徒步去另一个营地,这天是最辛苦了;
- 次难的就是 2D1N 的,第一天到达营地,第二天冲顶然后接着下山。就是已经收掉的那些帐篷;
- 最轻松的还是 3D2N, 但是于 1 不同的是,第二天冲顶完成之后,选择放弃去另一个营地,下午就在原地休息,然后睡一晚上,第三天再下山。即 (2) 扩展成多一天休息;
路上 Guide 看到我的样子,跟我说如果我想放弃下午的徒步呆在这里,也是可以的,毕竟是私人的团。我想来都来了,还是坚持一下吧,所以还是选择了继续原来的行程。
帐篷经过上午太阳的暴晒已经非常闷热,在帐篷里收拾东西非常痛苦。打包好了,就开始了下午的徒步路线。出发的时候已经 12 点多了,计划是徒步 6 小时之后在营地 2 看日落,听说日落是很美的。但是以我的速度(拖团队的后腿了),可能赶不上。
下午的路程是三个小时下山,三个小时上山。基本上是环着火山湖(就是图片中的那个)走,先沿湖下山到湖边,然后绕着湖徒步半圈,最后上山爬升到另一个山上扎营。营地的位置其实就是第一天看日落(上文的图片就是)的时候,挡住太阳的那个山。所以今天的日落没有了山的遮挡,应该是很美的。
下山的路比我预期的要惊险很多,像是踩着长在悬崖上的石头上往下走,都跟攀岩差不多了。这里要感谢一下我的登山鞋,这是这次爬山我最感激买了的装备,火山灰,水,走石头路,泥泞路,都扛得住,非常耐造。
我们出发了一会,Porter 在后面收拾完帐篷等,就赶上来了。Porter 和我们走的路一模一样,没有近路。而且只穿着人字拖,感觉非常不可思议。
大约花了两个小时,石头路走完了,到了吃午饭的地方,还好午饭吃的不再是油炸食品,虽然胃口还是不好,但是也吃了不少。因为高反脑袋还有些晕,吃了一片 Panadol,好了很多。
午饭之后,是一个小时的路,较为平坦。现在的位置像是在一个山谷里面,离中间的火山湖已经很近了,路上云雾缭绕的,仙境一般。

被云雾笼罩的草地路
一个小时之后,来到了湖边。其实湖边有一个火山温泉的,但是我们已经顾不上去泡温泉了,只想着快点到目的地。

到了火山湖边

沿着湖边走了一段时间,来到了上山的路。
上山的路一路都很陡峭,就跟第一天最陡峭的那段一样。很多地方要借助绳子,梯子上去,梯子的斜度有点吓人。

一路上的景色还不错

从另一个方向看 Rinjani 山


在半路上看到的日落
最后在 7 点多到达了终点,日落已经没赶上了。吃过饭之后赶紧钻到帐篷里面去睡了。
Day 3: 下山
起床之后,对今天的行程就有信心多了,毕竟是一路下山,而且下山还不会有高反,哈哈。

早上起床看日出

下山走的是另一条路,一路上几乎都是丛林,没有太阳晒,好像没有啥好记录了,我们用四个办小时的时间完成了 5 个小时的路程,很顺利。

开始下山
回到旅馆冲了个凉水澡,好好休息了一下,第二天坐飞机回家了。
旅馆老板很有趣,给我们介绍咖啡,给我们看他的生豆(挑选过的,每一颗质量都不错),当晚给我们烘焙了一包,带了回家,第一次见到烘焙日期是当天的豆子。
以前以为印尼之后 Sumatra 这种浓烈的咖啡豆,没想到原来也有阿拉比卡,酸酸的,也挺好喝。
还买了一个手袋,这些周边产品老板说收入都会给本地的咖啡农和他们的孩子。
注意事项(仅供参考)
列了一些常见问题,如果你也想去的话(其实还蛮推荐的),可以参考一下:
山上有信号吗?
大部分地方没有,依照我的经验,超过 2000 米海拔的地方都没有信号,露营的地方没有。
小费给多少?
10新币(或100万Rp) * 参与人数 * 服务团队人数(包括 Guide 和 Porters)为最低标准。
如何购买?
参考上文链接。
我们是通过邮件和登山的公司交流的。另外注意每年的11月到次年的3月左右是雨季,封山。不要这个时间去。
总花费是多少?
我这次行程总共支出 4000 – 5000 人民币左右,包括:
- 机票(从新加坡飞 Lombok)
- 登山 Package,可以从我的连接看价格,3D2N 价格 240 USD 左右(3 个大哥带我们三天,伙食还跟饭店一样,感觉非常超值呀)
- 接送机
- 酒店(很便宜,一间可以住4个人,只要 250 CNY 左右……)
- 其他话费……
需要带什么装备?
- 衣服
- 冲锋衣
- 保暖层
- 长裤
- 速干衣(需要三件)
- 除了冲顶的保暖衣服之外,其他的地方可以短袖短裤足够,但是,路上杂草很多,推荐降自己全包起来,比如压缩袜,瑜伽裤,冰袖之类的。会安全许多
- 辅助配件
- 护膝
- 压缩袜
- 羊毛袜(非常推荐,一双可以穿两天,脚不起水泡)
- 水袋(比水瓶喝水方便)
- 耳塞(晚上营地会比较吵)
- 路餐(其实可以不带,Guide 带的已经足够)
- 卫生用品
- 卫生纸
- 湿巾(用了很多,一路上都没有洗漱用的水)
- 漱口水
- 拍摄器材
- 充电宝
- 相机,Go Pro,无人机,自己选择,能拍的景色很多
- 头灯
- 这个很容易忽略,单独放出来,实在忘记了可以在出发前跟公司借
- 一定要检查充好电了没有
- 100 流明左右已经足够了
- 药品
- 防晒霜(物理防晒也可以,冰袖,遮阳帽)
- 登山杖(主要是冲顶,踩着火山灰如果没有登山杖很难走)
- 登山鞋(必须)
我能走下来吗?
除非是体能特别差,比如体重过高(其实我就属于胖子),一般都是没问题的。
我的经验:不要只担心后面有多少路,不要担心过多,要有一个信念,只要向前一步,就距离终点近了一点。