2022 年终于过去了,对于大多数人来说是糟心的一年,但我觉得也有一些指的记录的地方。
今年完成的最大的事情是10月份举办了婚礼。前前后后几乎策划了一年多,所幸举办的还算圆满。办完之后又办了很多手续,飞回新加坡回到工作中,本来是年底旅游的好日子,却几乎没出去旅游,躺平休息了 2 个多月。(办完婚礼之后觉得工作简直太轻松了)今后有了另一个身份,做一个好丈夫!
今年做的一些 side projects: 首先是 xbin.io, 时间太长,我都以为是去年做的东西了。这个项目的初衷是满足我自己的一些需求,现在看目的也达到了,个人对现在的形态比较满意,使用率也还可以。在新加坡使用 xbin 的 latency 是 5ms (ping RTT),如果不是在国外公司,自己是不会有这个想法做这么个东西的。
iredis 在今年几乎没有什么大的改变,只是在处理一些用户的 issue 和 bug. iredis 一直有一个问题,就是所有命令的补全都是我自己编入的,每一次 redis-server 有什么 command 的变更,我都要跟进,否则的话自动补全和校验系统就识别不出来新的命令,或者同一个命令的新的语法。我一直想把它替换成根据 redis-doc 中的文档自动补全的。现在这个文档已经越来越规范了,也许现在是时候迁移到自动生成的补全系统了。下一年花一些时间钻研一下语法树和补全系统,争取能完成这个。
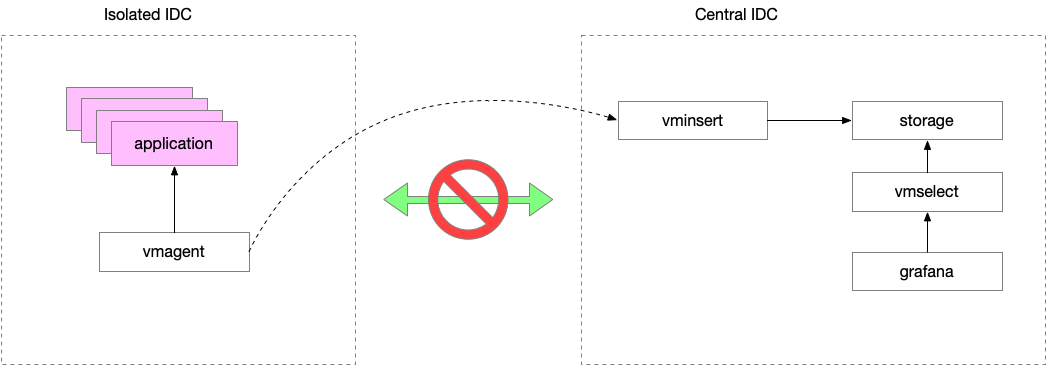
监控系统。做 SRE 的这段时间或多或少都在和监控系统打交道,今年为了解决我们团队遇到的问题,我从头搭建了一套监控系统,基于 VictoriaMetrics 上的,花了很多时间阅读他们的文档,也提交了一些 PR。今年还在 PromCon 上面分享了我们的一些经验。大部分的使用问题已经解决了,还有一个长久以来一直没有解决的问题:大规模的 recording rules, 比如,计算所有容器的 CPU 使用率。本质上,监控系统的数据是一个 OLTP 的问题,大部分场景只需要看到实时的数据就足够了,而且,也很少需要看到所有的 labels 加在一起的维度(只是看某一个 application)。但是我们有一些场景是需要对整个 AZ 做聚合,这有点像 OLAP 了。目前的解决方案是简单地作为一个客户端,去已有的数据里面查出来,然后做整体的计算,存储新的值。这样有很多问题:速度慢;占用太多资源。这个链路是有一些浪费的,raw metrics 首先被收集起来,然后存储到磁盘中,聚合进程再查出来,通过网络拿回来,再进行计算,一来一回消耗了很多磁盘、网络和 CPU 的资源。我在想能否直接让采集端发送 metrics 到聚合段,跳过读写磁盘的逻辑(原来 raw metrics 保存的链路是不变的)。这样或许可以提高一些性能。今年或许可以尝试一下。
做监控的时候也开源了一些项目:
- promqlpy: 一个 Python 库,可以解析 MetricsQL/PromQL 的语法;
- mepe: 一个命令行工具,可以 summary 应用暴露出来的 metrics,方便配置监控;
- metrics-render: 一个 Python 服务,可以根据 url 渲染出来 metrics 的图标,GET 请求,返回 png,这个库还存在一些问题;
- prometheus-http-sd: 一个给 Prometheus 的监控服务发现系统,支持 yaml/json,可用 Python 脚本方便地对接其他的系统;
这些完成的项目,没有完成的项目也有很多。反思这一年,我发现自己很大一个问题,就是学到什么东西之后急于投入使用,会有很多不成熟的想法,想实验一下行不行,于是会花很多时间做可行性调研,最后可能确定自己的想法是可行的,或者不可行的。但是已经并不重要了,自己这时基本上已经没有激情去实现了…… 这样就花了很多时间,但实际并没有什么产出。好处是可以有一些更有意思的想法,坏处是浪费时间。
所以今年就克制一下自己,除非工作必要,就不开新坑了。要学习的东西虚心去学习,不要急于卖弄学到的东西做出什么来证明自己的能力。
写到这里要穿帮一下,最近几年年终总结没有在年底准时写出来,是因为懒。今年是因为得了新冠。也不知道这几年在新加坡是怎么躲过去的,最近才得。今天(1月12日)终于算是没有症状了,于是开始继续写这篇文章。
对于去年的总结就到这里吧,新的一年,计划如下:
- 锻炼身体。年底回到新加坡之后买了两辆自行车跟太太一起到处骑,因为是折叠车,可以用公共交通蛙跳到各个地方去骑车,非常方便。新年就铁人三项:骑车、游泳、跑步,锻炼一个健康的身体吧。
- 打字训练:目前打字的速度是50 words per minute. 希望纠正自己的指法,速度提升到至少 70 words per minute.
- 学习:年底开始读一些 eBPF 的书,今年学习一下网络、Linux、CS 基础的内容,多总结,希望多写几篇博客。
最近有一个想法:假如喜欢编程这件事情并且想长久地坚持下去的话,比如 30 年,就会发现有些事情是不重要的,有些事情是重要的。比如一年工作的绩效考评,某一年的晋升,等等,放到30年里面,就不那么重要了。有一些事情是重要的,比如花1年时间熟练使用了一个高效的代码编辑器,比如提高代码的输入速度,比如掌握了画出精美的图片的技能,比如能写出通俗易懂的文档和博客的技巧,放到30年的编程生涯中,对于工作和个人的成长就很重要了。
这么一想,打算花 30 年去做一件事情,很多事情就会显的不那么急。我们就会有很多时间去寻找机会,也有很多时间去训练那种长远看来有益的事情。对于一些急功近利的事情也就看的不那么重要了。
说起来画图,我寻找合适的画图工具很多年了。尝试过 dot,(我还是 dot in Jupyter 的作者),OmniGraffle,D2,Mermaid, PlantUML 等等,还是没有一个满意的。就像一些数据库 ER 图 for dev, figma for design, 还缺少一个工具 for SRE. 对于我来说,这个工具应该是:
- 基于 text 的,text to diagram
- 命令式的,像编程语言一样描述动作。而不是声明式的
- 用户在使用的时候,应该快速的将所了解的事实通过这个语言表达出来,而不应该去考虑布局中每一个框的位置和排放,应该减少用户花在画图上的心智负担,将更多的精力放在所要表达的内容上面
过去一年也参考了很多其他的画图工具,也读了一些 DSL 设计有关的论文,今年看能不能把这个语言的设计实现出来。
就写这么多吧,杂七杂八写了很多不相关的东西。
2023年1月12日更新:上文中提到的这个 streaming aggregation metrics 的想法,生病期间朋友告诉我已经 VictoriaMetrics 官方已经实现了。
其他的年终总结列表: