这几天做了一个集群的迁移,我们搭建了一个新的集群,然后更新了 DNS 让域名访问新的集群,准备给老集群下线。下线的时候发现仍然有一部分请求到了老集群。看来是它们用了长链接,并没有根据新的 DNS 记录将请求发给新的地址。找到这些发送请求的客户端是谁,费了一番功夫,这里记录一下。
我们的架构如下:
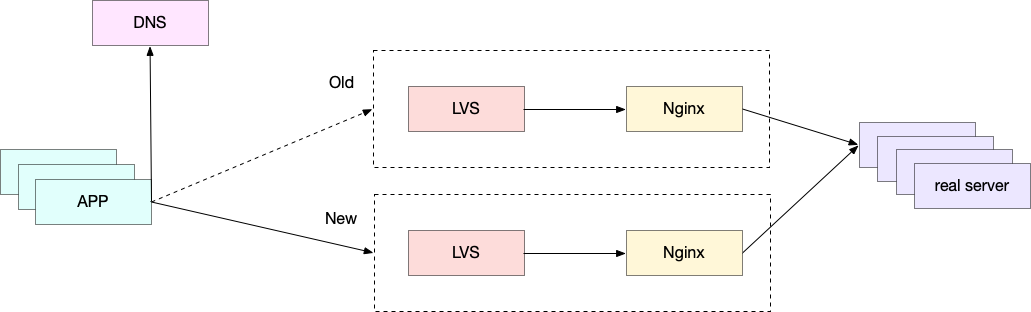
LVS 是一个四层代理,将请求转发到 Nginx,一个七层代理,然后转发给后端应用。
现在的情况是:
- Nginx 转发给后端的 real server,real server 是同一组,即,从后端 real server 这一层,不知道是谁还通过旧的集群进行访问;用户来源的名字写在了一个特殊的 header 中;
- 我们可以从 Nginx 的 access.log 找到这些请求的真实 IP,但是这是不够的,因为用户请求访问走了 NAT 进行了地址转换,我们仍然不知道这个 IP 是哪一个团队的;
但是我们有了 IP,有了 Header,只要通过 tcpdump -A host <ip> 就可以将用户请求的 HTTP 内容全部打印出来,也就包括 header,就能知道是谁了。
这里有一个问题,就是 Nginx 在 LVS 后面,我们在 Nginx 上面进行 TCP dump,看到的是 LVS 的地址,而不是用户的真实地址。
LVS 里面使用了一个模块,叫做 TOA, TCP_option_address. 即 LVS 进行转发的时候,会将用户的真实 IP 写在 TCP 的 option 字段中。如果要根据真实地址进行 tcpdump,我们要过滤的是这个字段而不是原生的 host 地址。
注意这个 TOA 只会在 SYN 握手阶段设置,然后双方会把这个信息记录在内存里面,后面的 TCP 通讯就不会一直带上这个信息了。所以,要找到用户的真实 IP,必须过滤 TCP 的 SYN 包。
现在需求就变成了:用 tcpdump 在 Nginx 上,filter 出来 IP 为 A 的请求的 HTTP header,以便根据 header 中的信息找到调用来源的团队,和他们沟通重建连接的问题。
通过阅读 TOA 的源代码可以发现,代码中还原用户真实的 IP 地址的方式:遍历 TCP Option 字段,直到找到 option code 为 254(TCP option 254 是一个实验字段,RFC3692-style Experiment 2 (also improperly used for shipping products), opsize 固定为 8 的 option,就读 16 bit load成端口,读 32 bit load 成 IP.
所以只要针对这个 tcp option filter 即可。
需要注意的是,tcpoption 对于 tcpdump 来说不被理解,所以需要转成 hex 来匹配。我在 xbin 上面放了几个工具:
- ipdecimal2hex 转换 IP 成 hex 形式
- decimal2hex 可以转换 decimal 成 hex 形式
匹配 IP 是 120.120.111.111 的话可以用下面的语句:
|
1 |
tcpdump 'tcp[tcpflags] & tcp-syn != 0 and tcp[24:4]=0x78786F6F' |
其中:
tcp[tcpflags] & tcp-syn != 0是取SYN的 flag 为 1,即只抓取 SYN 包;tcp[24:4]=0x78786F6F是匹配 tcp option 字段中的 IP
如果要匹配 port 的话,就偏移两位即可:
|
1 |
tcpdump 'tcp[tcpflags] & tcp-syn != 0 and tcp[24:2]=0xacb0' |
这样做其实还有一些问题:
- 上面说过 tcp option 里面有 IP 只发生在握手阶段,所以这样是抓不到后续的数据的。没找到 tcpdump follow tcp stream 的方法,可能还是全 dump 下来,然后去 wireshark 里面过滤比较好。不过我们这里 SYNACK 的时候已经有 HTTP 请求内容了,所以只过滤握手第三个包也足够;
- 还有一个问题是,看 TOA 的代码,它是遍历所有的 TCP option,根据 option Kind + option size 去查是不是自己的 port + IP 字段。也就是说,port + IP 未必一定是在 TCP option 的开头,偏移未必一定是
tcp[24:4]。一个解决方法是把可能的都 dump 下来,然后用 wireshark 过滤,wireshark 支持搜索全部 TCP 包内容包含某个 hex value。比如:tcp.options contains fe:08:78:78:6f:6f. - 因为我们要找到的是长连接的用户,所以这些连接我们是没有 SYN 包的。所以本文描述的方法其实对本文提出的问题……无效。现实中我们通过其他的方法找到用户了。这篇文章权当是看个热闹吧。