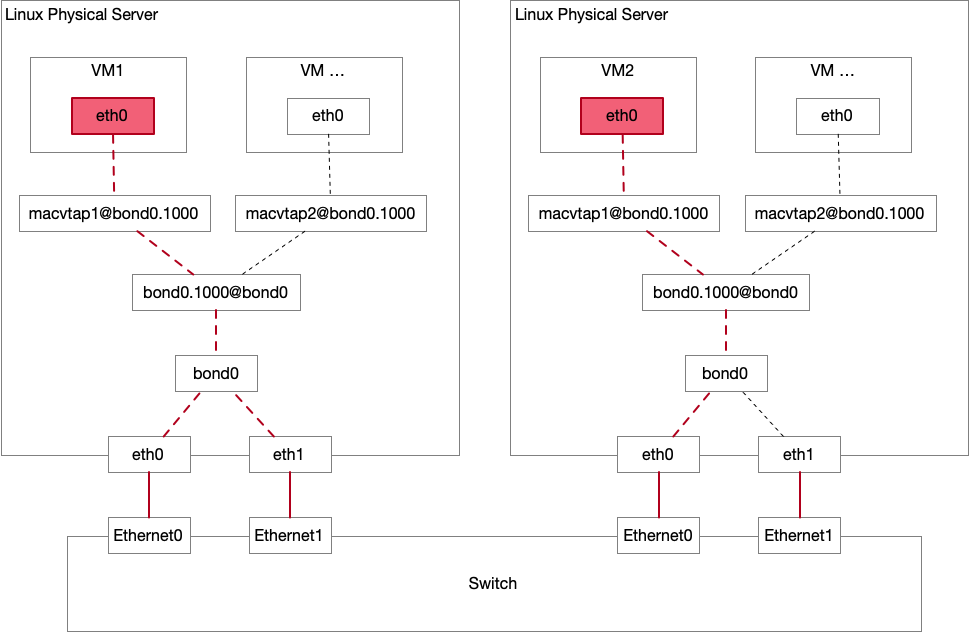
最近上线了一组规格比较高的 CPU 的机器。36 cores x 2 threads x 2 Sockets,在 htop 上可以看到 144 个 CPU。目的是用新机型来 POC。规格更高的硬件虽然更贵,但是总拥有成本 (TCO1) 会更低。机器运行成本只有一部分来自于购买硬件,还有 Rack 部署成本,电力等等,原来放 3 台机器,现在 1 台就够了。况且,在超售的情况下,10 个 CPU 可能可以当 12 个来用,100个 CPU 或许可以当成 150 个来用。超售的本质就是假设机器上的所有用户(容器)不会同时用满申请的 CPU capacity。那么更多的 CPU 就可以做更高的超售比例,因为资源池更大了。
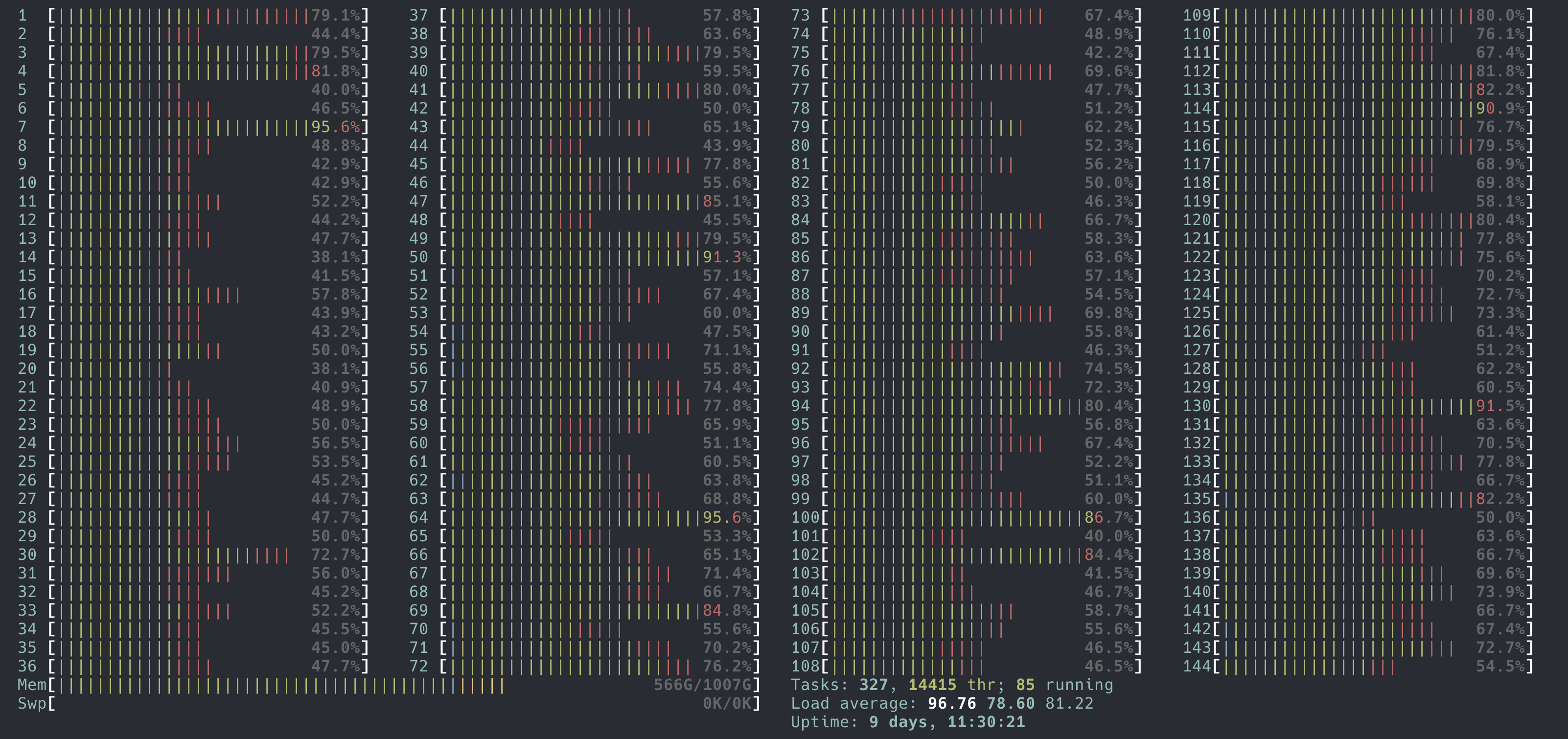
这是背景。然后有一天,用户报告这些机器上的网络延迟明显比较高。我使用 ping 确认了下,确实延迟已经高到可以让 ping 都感受到了。
现在已经排除用户程序的问题了,问题应该出在 kernel 的网络栈。
首先检查了 IRQ 队列相关的配置,都是正确的。就没有思路了。就去请教了另一位同事,原话引用如下:
什么情况下会引入延迟? 只有「多线程异步」操作能带来延迟,因为如果是单线程同步操作的话,那「延迟」几乎是恒定,因为就是纯代码执行而已了。
网络收包处理,在由网卡中断触发,Kernel 的中断处理分两部分:上半部分处理 hardirq,做的事情很少,只是处理中断信号然后 schedule softirq,即下半部分。softirq 会真正做协议栈的处理。
中断处理如果延迟了,就可能造成包的网络栈处理延迟。根据经验,问题发生在这里的概率较大。
同事推荐用 trace-irqoff2 这个工具来跟踪中断处理的延迟,这个工具能够统计中断被推迟处理的时间,以及导致中断处理推迟的栈。看了下代码,原理3应该是以一个 Kernel module 的方式运行,注册一个高精度计时器 hrtimer 定时执行硬中断,注册一个 timer 定时执行自己的代码,默认是 10ms 执行一次。每次执行的时候获取当前时间,和上次执行的时间对比。如果时间超过 10ms 太多,那就是因为某种原因导致 timer 没有定时执行了,同理,softirq 可能也被推迟了。timer 也是一种 interrupt,在 IRQ enable 的情况下会以抢占的方式运行,当我们的 timer 抢占进来的时候,可以打印出来抢占之前的 CPU stack,就可以知道在 timer 之前 CPU 在运行什么什么内容。
按照 trace-irqoff 的使用文档进行追踪,结果如下。
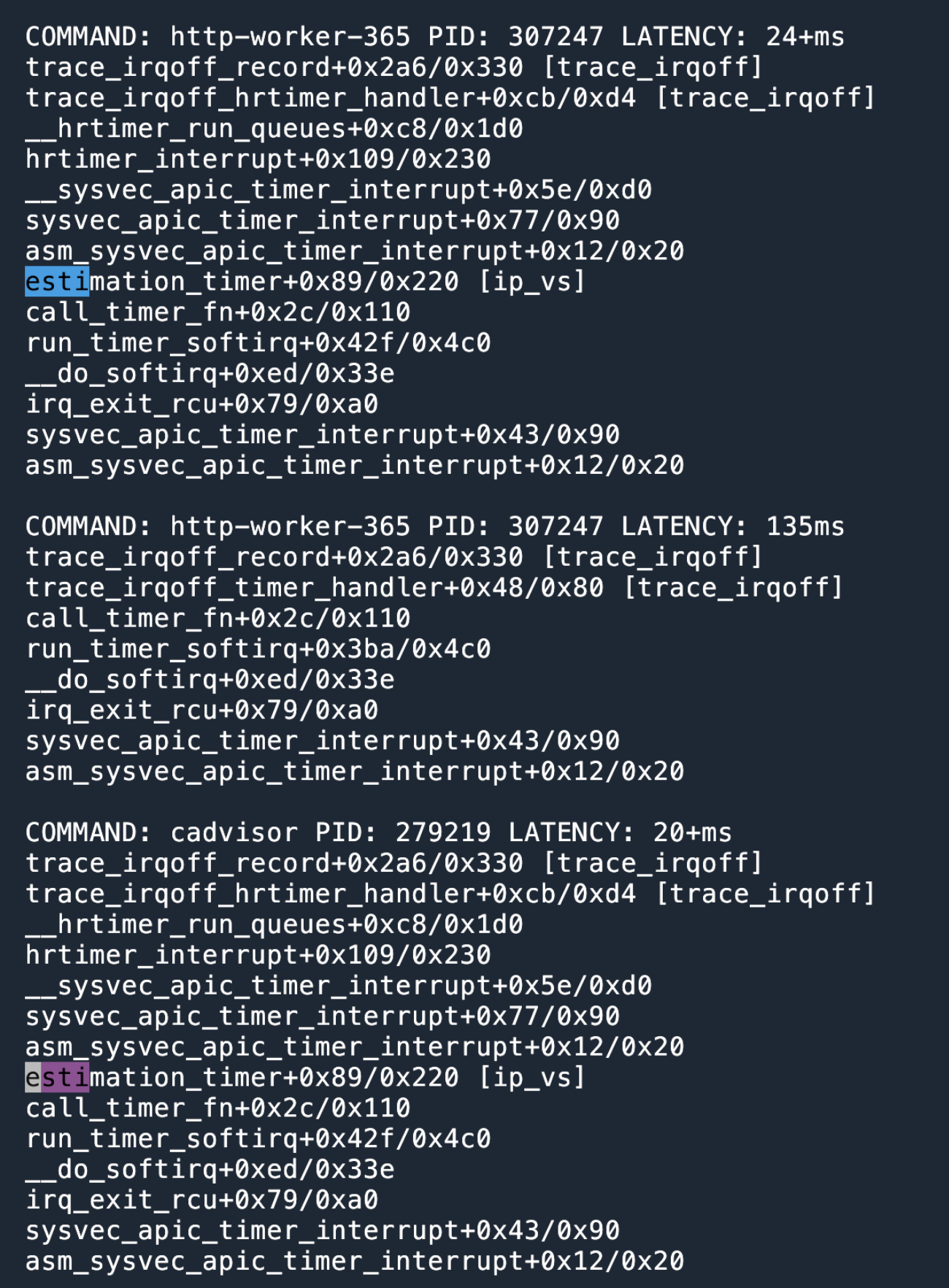
一个叫 estimation_timer 的函数夺人眼球。
查阅 Kernel 的源代码我们得知,这个是 IPVS 的统计函数。目的是遍历所有的 IPVS 相关的 rule4 (第一层循环),对于每一个 rule,读取每一个 CPU 的数据(第二层循环)。两层循环嵌套,就导致执行时间会比较长。这个函数也是以 timer 的形式注册,即每隔一段时间就会执行,执行期间 IRQ 是关闭的,即没有其他线程可以抢占 CPU,estimation_timer 函数会占据 CPU 直到执行结束。假设有 soft irq 调度到这个 CPU,那么延迟就增加了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
static void estimation_timer(struct timer_list *t) { struct ip_vs_estimator *e; struct ip_vs_stats *s; u64 rate; struct netns_ipvs *ipvs = from_timer(ipvs, t, est_timer); spin_lock(&ipvs->est_lock); list_for_each_entry(e, &ipvs->est_list, list) { // 在这里遍历所有的 rule s = container_of(e, struct ip_vs_stats, est); spin_lock(&s->lock); ip_vs_read_cpu_stats(&s->kstats, s->cpustats); // 这里会遍历所有的 CPU ... |
|
1 2 3 4 5 6 7 8 |
static void ip_vs_read_cpu_stats(struct ip_vs_kstats *sum, struct ip_vs_cpu_stats __percpu *stats) { int i; bool add = false; for_each_possible_cpu(i) { // 遍历所有的 CPU ... |
由于新机型 CPU 数量比较多,那么在相同的 rule 数量下,遍历所需要的时间也就更多。所以延迟也更高。之前的机型延迟也受此影响,不过不是很严重罢了。
通过和用户讨论,发现我们没有使用 IPVS 提供的这些统计信息,所以这个函数可以关闭。目前已经可以通过 sysctl 参数关闭了5,不需要打 patch:sysctl -w net.ipv4.vs.run_estimation=0。
趣头条的相同问题的排查记录,也很有趣,值得一读:https://www.ebpf.top/post/ebpf_network_kpatch_ipvs/ (不过这个网站的证书貌似过期了)。
- Total cost of own: https://en.wikipedia.org/wiki/Total_cost_of_ownership ↩︎
- 字节跳动开发的中断追踪工具 https://github.com/bytedance/trace-irqoff ↩︎
- 对原理的理解不是特别自信,有错误请读者指出。 ↩︎
estimation_timer函数的源代码https://elixir.bootlin.com/linux/v5.8/source/net/netfilter/ipvs/ip_vs_est.c#L191,ip_vs_read_cpu_stats遍历 CPU 的源代码:https://elixir.bootlin.com/linux/v5.8/source/net/netfilter/ipvs/ip_vs_est.c#L56 ↩︎- 相关的讨论:https://lore.kernel.org/netdev/[email protected]/T/ ↩︎