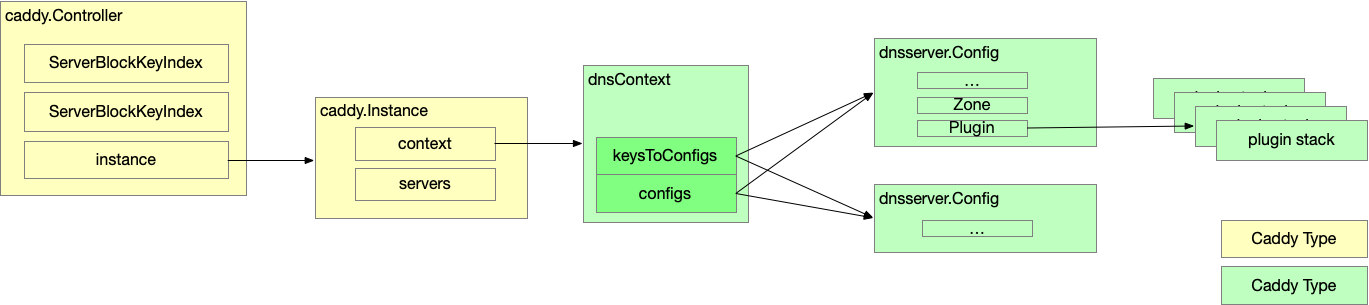
今天看到一段代码,是用 Prometheus 的 client_go 暴露 metrics 的代码。里面不是简单的将对应的一个 metric counter inc()的操作,而是自己实现了一个非常奇怪的逻辑:
- 当程序需要将 counter +1 的时候,没有直接操作对应的 metrics,而是将要增加的 metrics 用自己的格式打包出一个对象,然后将对象发送到一个 channel,每一个 metric 都对应一个 channel
- 程序启动之初就会启动全局唯一的 worker goroutine, 这个 goroutine 负责操作所有的 metrics:它从不同的 channel 中拿到消息,然后解包出来,找到对应的应该增加的 metrics,然后执行最终的增加操作。
实际的操作还要复杂的多,先创建一个 MetricsBuilder,然后 MetricsBuilder 有 Add() 函数,实际上是往 Channel 里面发送了一条信息,Channel 里面读出来,又通过一些系列的层层调用执行到 metrics + 1 上。
事先声明, 本人不会写 golang,本文可能写的不对,请读者指正。
感觉本身就是一行 metrics.Add() 的事情,为什么要搞这么复杂呢?思来想去,我觉得唯一可能的解释就是:这是一个负载极高的系统,希望将 metrics 的操作变成异步的操作,不占用业务处理的时间。但是用 channel 还涉及到打包和解包,真的能快吗?
一开始我以为 channel 可能是一种高性能的无锁的操作,但是看了 golang 的 runtime 部分,发现也是有锁的,如果多个线程同时往一个 channel 里面写,也是存在竞争条件的。
而 Prometheus 的 client_golang 只是执行了一个 Add 操作:atomic.AddUint64(&c.valInt, ival)
虽然 atomic 也是一个 CAS 操作,但直觉上我觉得用 channel 是不会比 atomic 快的。
写了两段代码来比较这两种情况(测试代码和运行方式可以在 atomic_or_channel 这里找到):
直接用 atomic 代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
func AtomicAdd() uint64 { var wg sync.WaitGroup var count uint64 count = 0 for i := 1; i <= CLIENTS; i++ { wg.Add(1) go func() { defer wg.Done() for l := 0; l < LOOP; l++ { atomic.AddUint64(&count, 1) } }() } wg.Wait() return count } |
模拟开一个 channel 负责增加的情况:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
func ChannelAdd() uint64 { var wg sync.WaitGroup var count uint64 count = 0 numCh := make(chan *uint64, 10240) // start worker go func() { for value := range numCh { atomic.AddUint64(&count, *value) } }() one := uint64(1) for i := 1; i <= CLIENTS; i++ { wg.Add(1) go func() { defer wg.Done() for l := 0; l < LOOP; l++ { numCh <- &one } }() } wg.Wait() close(numCh) return count } |
参数如下,意在模拟 100 个并行连接,需要增加1百万次:
|
1 2 |
var LOOP = 1000000 var CLIENTS = 100 |
实际运行的结果也和我想的一样,atomic 要比 channel 的方式快了 15 倍。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
➜ go run . ChannelAdd() Done! count=99991670 took 33.95414173ss AtomicAdd() Done! count=100000000 took 1.92393346ss ➜ go test -bench=. -count=10 goos: darwin goarch: amd64 pkg: github.com/laixintao/atomic_or_channel cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz BenchmarkAtomic-12 1 1947990739 ns/op BenchmarkAtomic-12 1 1957558508 ns/op BenchmarkAtomic-12 1 1984851549 ns/op BenchmarkAtomic-12 1 1957678020 ns/op BenchmarkAtomic-12 1 1953746756 ns/op BenchmarkAtomic-12 1 1957197155 ns/op BenchmarkAtomic-12 1 1964173594 ns/op BenchmarkAtomic-12 1 1962058130 ns/op BenchmarkAtomic-12 1 2342306683 ns/op BenchmarkAtomic-12 1 2313845157 ns/op BenchmarkChannel-12 1 35211801199 ns/op BenchmarkChannel-12 1 40597364557 ns/op BenchmarkChannel-12 1 38452709531 ns/op BenchmarkChannel-12 1 40201893971 ns/op BenchmarkChannel-12 1 41802617846 ns/op BenchmarkChannel-12 1 41463031707 ns/op BenchmarkChannel-12 1 41985476702 ns/op BenchmarkChannel-12 1 43106978329 ns/op BenchmarkChannel-12 1 45582670783 ns/op BenchmarkChannel-12 1 43751655673 ns/op PASS ok github.com/laixintao/atomic_or_channel 432.885s |
atomic 2s 就可以完成模拟 100 个客户端并行增加1百万次,即可以支持5千万的 QPS (还只是在我的笔记本上),而相同的操作用上文描述的 channel 的方式需要 30-40s。慢了15倍。
虽然我在有些地方说 atomic 很慢,但是这个速度对于 metrics 统计的这个场景来说,是完全足够了。
Twitter 上的 @Kontinuation 提醒有一种优化的方式,我觉得这个很好:
每一个 thread 维护自己的 threadlocal 变量,这样完全不需要锁。只是在 collect metrics 的时候采取收集每一个 thread 的 counter 等。TiKV 中就是使用这个方法实现的 Local 指标(@_yeya24),即每一个线程保存自己的指标在 Thread Local Storage,然后每 1s 刷新到全局变量(其实我觉得可以只有在 metrics 被收集的时候才刷新?),这样可以减少锁的次数。
但是在 golang 里面,从这篇文章发现 go 语言官方是不想让你用 thread local 的东西的,而且为此还专门让 go id 不容易被获取到。那我就像不到什么比较好的实现方法了。