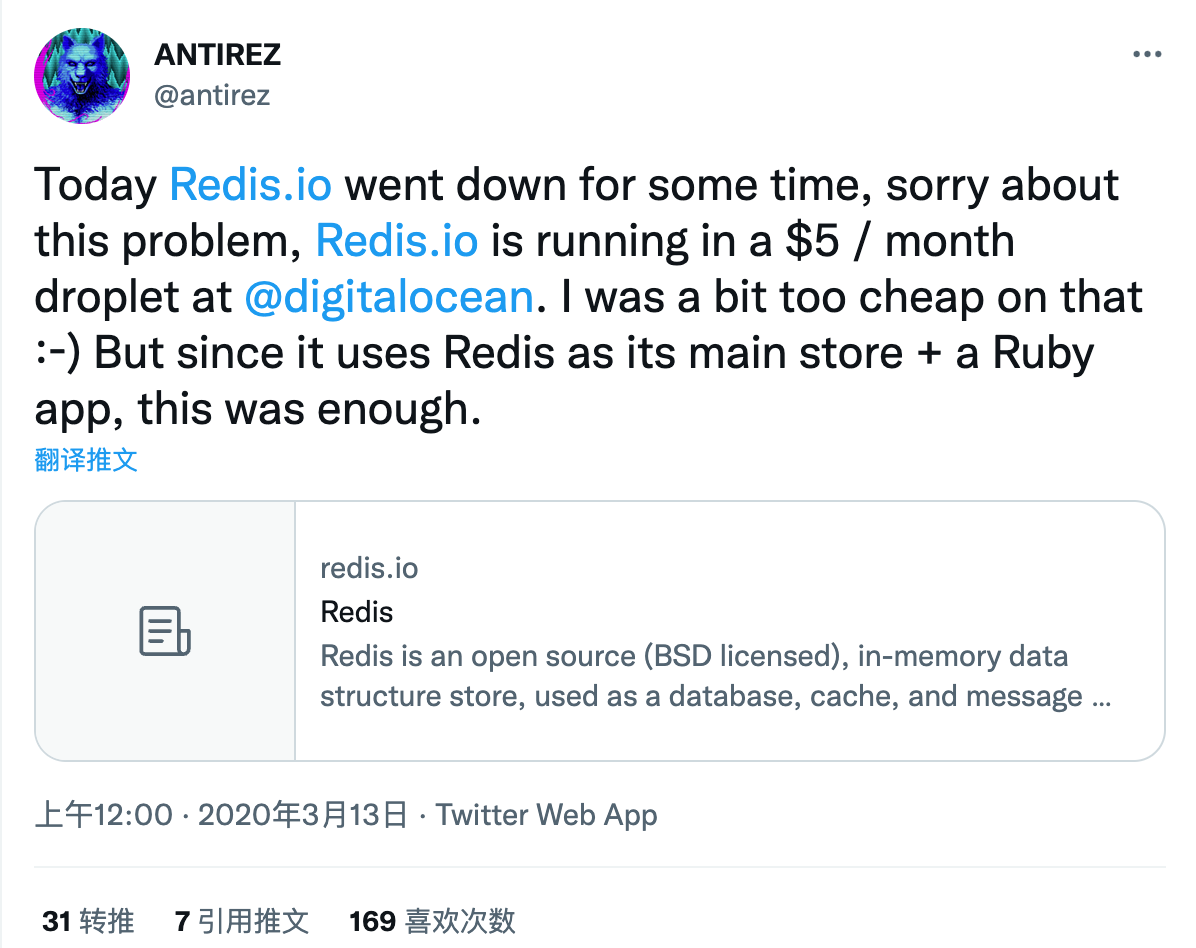
有时候,人们会忘了今天的计算机资源已经如此强大,一台 $5/月 的机器可以干多少事情。
之前有人在讨论 redis.io 这个官网上,访问量一定巨大,而且可以实时运行 Redis 命令,一定用了很多机器,是一个分布式的系统。但其实就是跑在一个 $5/月的 VPS 单机上。
我在工作之余会做一些出于兴趣的 Hobby Project,这些 Project 可以分成两种:
- 工具和库之类的,只要下载就可以使用,用户量再大也不会增加我的成本;
- 提供服务的网站类型,需要花钱购买域名和服务器,并且要付出维护成本;
对于第二种类型,只有减少成本,项目才可能持续:
- 每一个项目刚开始的时候可能都没有什么人,如果不节省成本,很可能在一开始就没什么用户,以及高昂的运行成本而做不下去
- 成本低可以长时间积累用户
这篇博客写一些如何降低运行成本的方法。
运行平台
如果是静态网站,选择就很多了,cloudflare, Vercel, netlify, 都可以。只需要把前端的文件上传上去就可以了。
如果是动态网站,近几年也有很多不错的 SaaS 平台可以选择:Sass 部署可以选择 fly.io, heroku, serverless 可以选择 cloudflare, aws 等等。这些平台的免费额度基本都可以覆盖很多场景了。
但是我做的小东西基本上都需要运行用户提交的代码,所以我一般用 DigitalOcean 的虚拟机。好处是便宜,自己完全可以用控制 VM,而且账单透明。不会有 vendor lock, 随时可以换另一家的 VM 用。
部署
如果选择 SaaS 的话,就需要根据使用的 SaaS 平台写部署描述文件。
如果使用虚拟机来部署的话,我一般使用 ansible 来管理部署:
- 将代码放在一个 repository, 可以公开,也可以私有
- 使用一个 私有的 repository, 存放 ansible 配置文件,包括一些 secret 文件,host inventory 都放在这里面
- 每次发布版本的时候,在代码 repository 提交 tag,build binary
- 然后在 ansible repository 修改部署的 tag,提交一次部署(这一步其实可以集成到 CI 里面去,每次改动都去自动运行一下 Ansible)
- 保持一个原则:就是给你一组新的 IP,能够在几分钟之内搭建好一模一样的集群(这样可以不用担心原来的集群坏掉,没有运维负担)
Logs 和 Metrics
Logs 也有一些 Saas 平台可以使用,比如 Datadog, sematext, 但是我都没有用过,一个是会提高管理成本,也会提高运行成本,即使 Saas 是免费的,你也需要流量把 log 发出去,而且我比较习惯使用命令行的工具看日志。
关于 Metrics, 其实可以不必关心,小型的服务一开始用 jvns 介绍的方法完全足够了:Monitoring tiny web services,即使用黑盒监控探测,以及定时 curl 网站的方式,从小时级别确保网站在正常运行。这样已经可以检测足够多的东西了,比如 SSL 证书过期,数据库挂了等情况。
如果要更精确的监控,一个比较好的方法是部署 Prometheus + Grafana, 两个组件一个是收集 metrics 的一个是用来展示 metrics 的,都可以用 docker 来启动,然后用 Ansible 管理配置文件,做监控代码化,也能做到随时迁移。
如果要运行用户代码的话……
之前做的一个项目叫 clock.sh, 是一个定时执行用户代码的服务,可以理解成 serverless crontab. 最近还在跑的一个项目叫 xbin.io, 提供一些命令行工具,不用安装就可以运行。这两个项目都需要运行用户代码。
Jvns 在她的博客写过很多解决类似需求的工具分析,基本上和我想要的一样,非常推荐阅读一下:
- Firecracker: start a VM in less than a second
- Notes on running containers with bubblewrap
- Running containers without Docker
我现在使用的方案是:Docker + runsc, 使用最新版的 docker,避免 0day 攻击。然后用 runsc 只能允许有限的 syscall,就可以满足大部分的安全需要了(暂时还没出过问题)。
开发和测试
前面说了这么多有关运维部署的事情,其实写代码也有一些技巧。就是尽量不要自己从头自己实现一个功能或者模块,你的代码应该只去实现核心模块。(除非你要写的东西很好玩)。因为业余的时间有限,要把一件事情做成,就要把时间用在关键的地方。几个原则:
- 如果一个功能需要很复杂的实现,就用现成的库。比如登录功能,涉及反垃圾,验证邮箱,管理 session,那么直接用 Oauth 库 + Github 账号登录,几行配置就解决了;
- 如果一个功能不算复杂,但是现有的库的实现都比较复杂,那么自己写。比如你的一个服务去调用另一个服务,只有一个 API,用 protobuf + gRPC 太复杂了,不如自己设计一个 TCP 协议,或者直接用 HTTP;
- 实现的时候写的代码越少越好。代码越少,bug 越少,1年之后你在看自己的代码也看的懂。
有关测试:
- 可以只写关键地方的测试,以及复杂的地方的单元测试,核心目的是避免自己以后修改代码的时候不注意改错了复杂的地方;
- 可以不写集成测试,因为集成测试都很复杂,即使通过了集成测试,你也不会很有信心一定没问题。所以集成测试即使通过了,一般你也会手动再去验证一下,所以意义不大;
- 不是一定需要 CI 自动运行测试,你可以在 merge 之前手动在本地跑一下测试。因为 CI 的调试和维护也很花时间,只有自己一个人的话,makefile 反而更好用。
最后一点
对于业余的项目,应该让自己的精力放在比较重要的(快乐)事情上。自己维护的东西要越少越好。
比如要实现一个功能的话,现成的 SaaS > 基于库实现 > 自己从软件方面实现 > 使用新的开源项目额外部署系统来实现。问题尽量从软件自身解决。举个例子,比如每小时要清理一下不在运行的容器,一个方法是写一个脚本做成 crontab 运行,但是一个更好的方法是在软件本身开一个后台线程,每隔一个小时就检查一遍。这样,就不需要维护 crontab 了(实际上是由 crond 运行的)。