最近在跨机房做一个部署,因为机房之间暂时没有专线,所以流量需要经过公网。对于经过公网的流量,我们一般需要做以下的安全措施:
- 只能允许已知的 IP 来访问;
- 流量需要加密;
第一项很简单,一般的防火墙,或者 Iptables 都可以做到。
对于加密的部分,最近做了一些实验和学习,这篇文章总结加密的实现方案,假设读者没有 TLS 方面的背景知识,会简单介绍原理和所有的代码解释。
TLS/SSL 的原理
TLS 是加密传输数据,保证数据在传输的过程中中间的人无法解密,无法修改。(本文中将 TLS 与 SSL 作为同义词。所以提到 SSL 的时候,您可以认为和 TLS 没有区别。)
传输的加密并不是很困难,比如双方用密码加密就可以。但是这样一来,问题就到了该怎么协商这个密码。显然使用固定的密码是不行的,比如每个人都要访问一个网站,如果网站使用固定的密码,那么和没有密码也没有什么区别了,每个人都可以使用这个密码去伪造网站。
TLS 要解决的问题就是,能证明你,是你。现在使用的是非对称加密的技术。非对称加密会有两个秘钥,一个是公钥,一个是私钥。公钥会放在互联网上公开,私钥不公开,只有自己知道。只有你有私钥,我才相信你是你。非对称加密的两个秘钥提供了一下功能(本文不会详细介绍这部分原理,只简单提到理解后续内容需要的知识):
- 公钥加密的数据,只有用私钥可以解密;
- 私钥可以对数据进行签名,公钥拿到数据之后可以验证数据是否由私钥的所有者签名的。
有了这两点,网站就可以和访问者构建一个加密的数据通道。首选,网站将公钥公开(即我们经常说的“证书”),访客连接到网站的服务器第一件事就是下载网站的证书。因为证书是公开的,每个人都能下载到此网站的证书,那么怎么确定对方就是此证书的所有者呢?客户端会生成一个随机数,并使用公钥进行加密,发送给服务器:请解密这段密文。这就是上文提到的 功能1,即公钥加密的数据,只有私钥才能解密。服务器解密之后发回来(当然,并不是明文发回来的,详细的 TLS 握手过程,见这里,客户端就相信对方的确是这个证书的所有者。后续就可以通过非对称加密协商一个密码,然后使用此密码进行对称加密传输(性能快)。
但是这样就足够验证对方身份了吗?假设这样一种情况,我并不是 google.com 这个域名的所有者,但是我生成了一对证书,然后自己部署,将用户访问 google.com 的流量劫持到自己这里来,是不是也能使用自己的证书和用户进行加密传输呢?
所以就有了另一个问题:访客不仅要验证对方是证书的真实所有者,还要验证对方的证书的合法性。即 google.com 的证书只有 Google 公司可以拥有,我的博客的证书只有我的博客可以拥有。私自签发的证书不合法。
为了解决这个问题,就需要有一个权威的机构,做如下的保证:只有网站的所有者,才能拥有网站的证书。然后访客只要信任这个“权威的机构”就可以了。
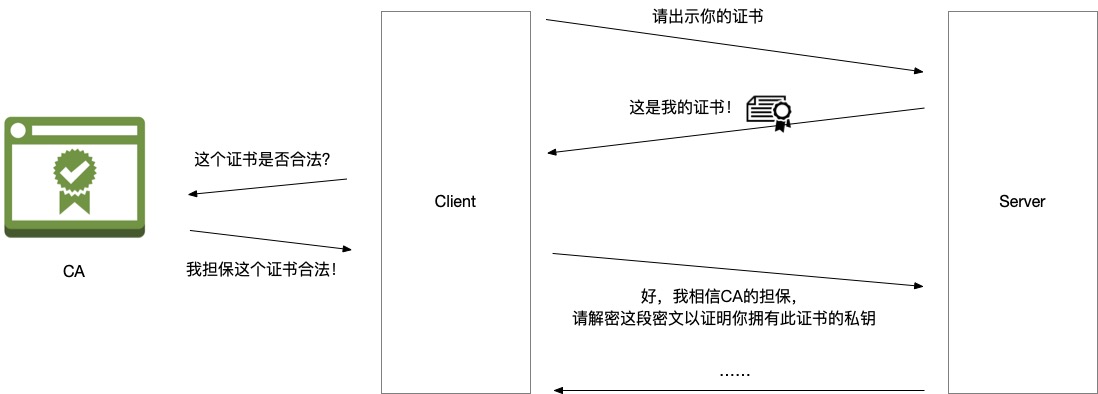
CA 扮演的角色
CA 的全称是 Certification Authority, 是一个第三方机构,在上述加密的流程中,扮演的角色同时被访客和网站所信任。
网站需要去 CA 申请证书,而 CA 要对自己颁发(签名)的证书负责,即确保证书颁发给了对方,颁发证书之前要验证你是你。申请证书的时候,CA 一般会要求你完成一个 Challenge 来证明身份,比如,要求你将某个 URL 返回特定内容,或者要求你将 DNS 的某个 text record 返回特定内容来证明你的确拥有此域名(详见 validation standards)。只有你证明了你是你,CA 才会签证书给你。
访客是怎么验证证书的呢?这就用到了上文提到的 功能2:“私钥可以对数据进行签名,公钥拿到数据之后可以验证数据是否由私钥的所有者签名的。” CA 也有自己的一套私钥公钥,CA 使用私钥对网站的证书进行签名(担保),访客拿到网站的证书之后,使用 CA 的公钥校验签名即可验证这个“担保”的有效性。
那么 CA 的公钥是怎么来的呢?答案是直接存储在客户端的。Linux 一般存储在 /etc/ssl/certs。由此可见,CA 列表更新通常意味着要升级系统,一个新的 CA 被广泛接受是一个漫长的过程。新 CA 签发的证书可能有一些老旧的系统依然不信任。比如 letsencrypt 的 CA,之前就是使用交叉签名的方式工作,即已有的 CA 为我做担保,我可以给其他的网站签发证书。这也是中级证书的工作方式。每天有这么多网站要申请证书,CA 怎么签发的过来呢?于是 CA 就给很多中级证书签名,中级证书给网站签名。这就是“信任链”。访客既然信任 CA,也就信任 CA 签发的中级,也就信任中级签发的证书。
被信任很漫长,被不信任很简单。
CA (以及中级证书机构)有着非常大的权利。举例,CA 假如给图谋不轨的人签发了 Google 的证书,那么攻击者就可以冒充 Google。即使 Google 和这个 CA 并没有任何业务往来,但是自己的用户还是被这个 CA 伤害了。所以 CA 必须做好自己的义务:
- 保护自己的私钥不被泄漏;
- 做好验证证书申请者身份的义务;
- 如果 (2) 有了疏忽,对于错误签发的证书要及时吊销;
案例:赛门铁克证书占了活跃证书的 30% – 45%(当时),但是被 Google 发现其错误颁发了 3万个证书,发现后却不作为。因此逐步在后续的 Chrome 版本中吊销了赛门铁克的证书。
案例2:let’sencrypt 今年1月份发现自己的 TLS-ALPN-01 chanllege 有问题,于是按照规定,在5天后吊销了这期间通过 TLS-ALPN-01 颁发的所有证书。
说道这里我想继续跑一个题。我以前给博客部署证书的时候(2017年)就想:CA 给我发一个证书居然要收我的钱?这个不是零成本的东西吗?他们想发多少就发多少。看到现在读者应该明白了,这并不是一个零成本的事情:签发证书的验证服务需要花钱,而 CA Root key 的保护要花更多的钱。整个 CA 公司(组织)的核心资产就是一个 key,如果这个 key 暴露了,后果不堪设想。所以,一个无比重要却要一直使用的 key 在一个上千万人的组织里怎么被使用而不暴露给任何一个人呢?这是要花很多钱的。Root key 的生成会有一个仪式(Key ceremony),全程录像,有 20 多个不同组织的代表会现场参加并监督,会有 3000 多个人观看实时录像,确保 key 的生成是标准流程。在 Root key 的保存和使用上,Root key 只会签中级 CA,以减少使用次数以及 Root key 需要被 revoke(代价太大)的风险。Root Key 保存在一个特殊的硬件中(HSM, Hardware security module),完全离线保存,HSM 也放在特殊的机房中,7×24 有人看守,并离线录像,机房有 Class 5 Alarm System,有多把锁,没有一个人可以单独进入。使用这个 Root Key 必须物理上进入这个机房,使用过程全程录像,并且记录使用过程,如果有问题可以很快地将 Root Key 签的内容 revoke。这里有一个视频介绍 Key Signing Ceremony,非常有趣。所以说 CA 机构并不是一个摇钱树,Let’s Encrypt 这种组织简直就是慈善机构。
以上就是 TLS,证书,CA 大致的工作原理,稍稍有些跑题,有了这些知识我们就可以利用 TLS 来建立一个加密的数据通道了。后续几乎都是实际的操作。笔者对这部分也不是精通,如果有错误,欢迎指出。
对应用透明的加密通道的方案
背景
上文是通过网站部署 HTTPS 来讲的 TLS 的工作原理。其实网站部署 HTTPS 还算是比较简单:你只需要找一个 CA,申请证书,完成 CA 的验证,部署证书,就可以了。
现在要解决的问题更加复杂一些:我们的两个组件之间是通过自己研发的协议通讯(基于 TCP),现在要分别部署在两个机房,通过公网进行通讯。
我们的方案要对通讯的两边做好安全防护:
- 数据要进行加密传输;
- 要对两边做身份验证,比如 A 向 B 发起连接,A 要验证 B 的身份,B 也要验证 A 的身份;
- 最好对于应用来说透明,即应用完全不修改代码,依然按照原来的方式工作,但是我们将中间的流量进行加密;
mTLS
mTLS 的全称是 Mutual TLS. 即双向的 TLS 验证。HTTPS 只是访客验证了网站的身份,网站并没有验证访客的身份。其实要验证也是可以的,网站发送证书之后可以跟访客说:“现在该轮到你出示你的证书了”。如果访客不能提供有效的证书,网站可以拒绝服务。
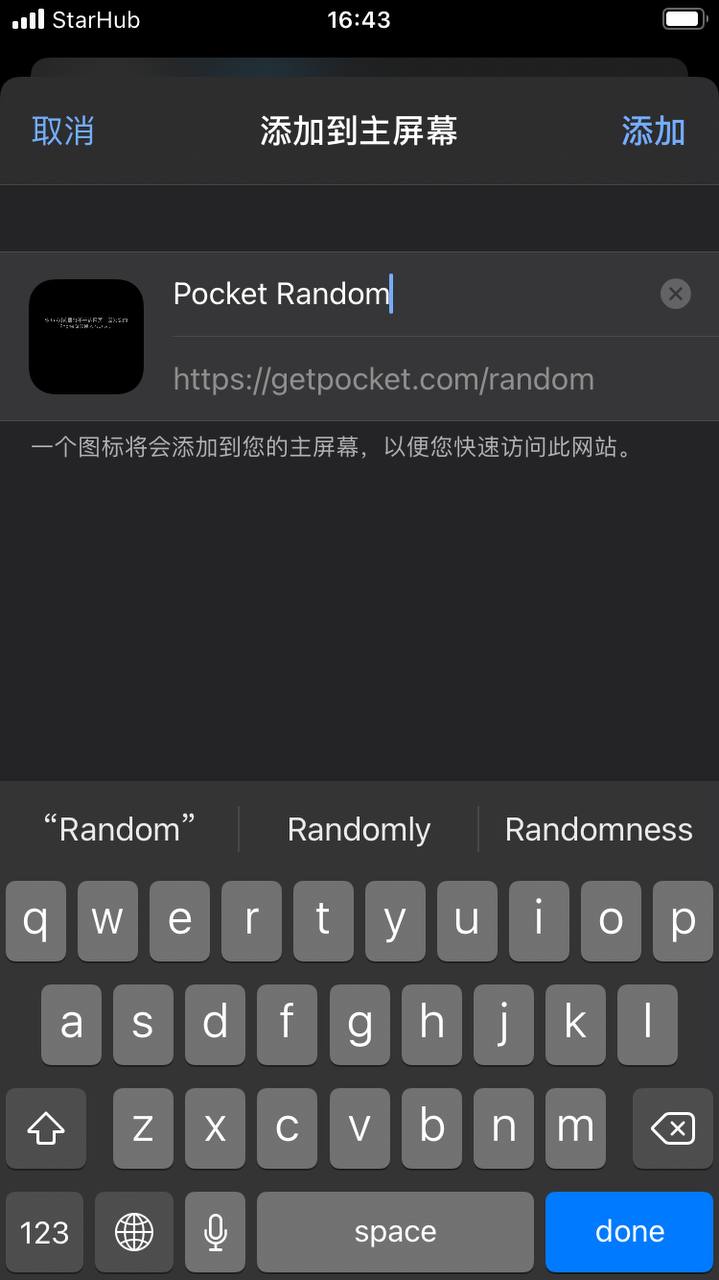
其实,ssh 方式就是一个双向验证的过程。我们都知道通过 ssh key 登录 server 的时候,需要让 server 信任你的 key(即将你的 pubkey 放到 server 上去)。但是还有一个过程容易被忽略掉,在第一次通过 ssh 连接服务器的时候,ssh 客户端会给你展示 server 的 pubkey,问你是否信任。如果之后这个 key 变了,说明有可能你连接到的并不是目的服务器。
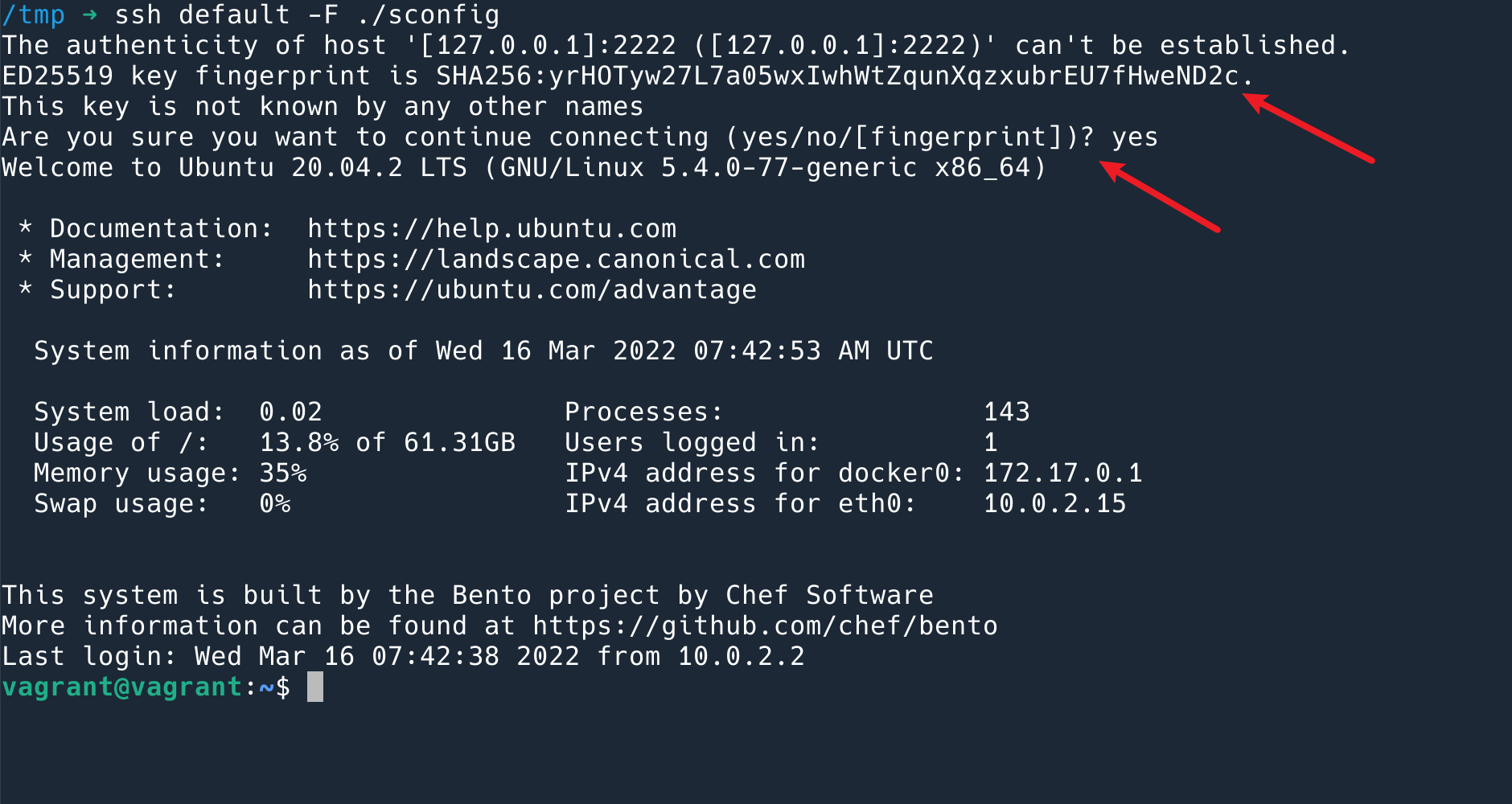
第一次连接到服务器的提示
如果之后这个 key 变了,ssh 客户端就会拒绝连接。
Git 也是通过走 ssh 协议的,所以也是一个双向认证。你在使用 Github 的时候要互相信任对方:
- Github 信任你的方式是:你将自己的 pubkey 上传到 Github (设置,profile,keys)
- 你信任 Github 的方式是:Github 将自己的 pubkey 公布在网上。
解决方案
为了实现对应用透明的加密通讯,我们在两个机房各搭建一个 Nginx,这里两个 Nginx 之间通过 mTLS 相互认证对方。应用将请求明文发给同机房的 Nginx,然后 Nginx 负责加密发给对方。对于应用来说,对方机房的组件就如同和自己工作在相同机房一样。最终搭建起来如下图所示。
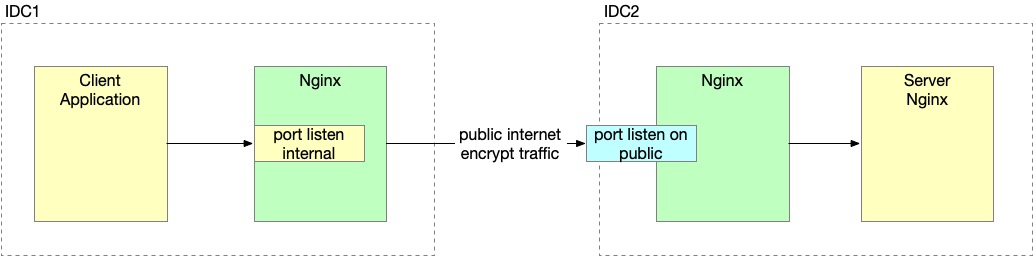
搭建过程
因为用 HTTP 流量来搭建,相关的工具和日志会更友好一些。所以我们会先用 HTTP 将这个通道搭建起来,然后换成 tcp steam。
准备证书
我们一共需要两套证书,一套给 Client,一套给 Server. 因为我们这里主要要解决的问题内部互相信任的问题,不需要开给外面的用户,所以这里我们采用 self signed certificate. 即,我们自己做 CA,给自己签发证书。自签发证书的好处是很灵活,方便,坏处是有一些安全隐患(毕竟不像权威机构那样专业)。所以我把这个过程写在博客上,请大家帮忙看看流程有没有问题。
首先我们创建一个 CA 的 key,即私钥。CA 的 key 最好给一个密码保护,每次使用这个 CA 签发证书的时候,都需要输入密码。
生成 key 的命令:
|
|
openssl genrsa -des3 -out ca.key 4096 |
输出(其中按照提示输入密码):
|
|
Generating RSA private key, 4096 bit long modulus (2 primes) .............................................................++++ ....................................................................................................................................................................................++++ e is 65537 (0x010001) Enter pass phrase for ca.key:<passphrase> Verifying - Enter pass phrase for ca.key:<passphrase> |
命令的解释:
openssl: cert 和 key 相关的操作我们都用 openssl 来完成;genrsa: 生成 RSA 私钥;-des3: 生成的 key,使用 des3 进行加密,如果不加这个参数,就不会提示让你输入密码;4096: 生成 key 的长度;
这里我们假设所使用的密码是 hello.
然后我们来生成 CA 的公钥部分,即证书。
|
|
openssl req -new -x509 -days 365 -key ca.key -out ca.crt |
这时会询问你一些信息,比如地区,组织名字之类的。其中,Organization Name 和 Common Name 需要留意。CA 的这一步填什么都可以。Common Name 又简称 CN,就是证书签发给哪一个域名(也可以是 IP)的意思。
输出会是如下所示:
|
|
You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [AU]: State or Province Name (full name) [Some-State]: Locality Name (eg, city) []: Organization Name (eg, company) [Internet Widgits Pty Ltd]:CertAuth Organizational Unit Name (eg, section) []: Common Name (e.g. server FQDN or YOUR name) []: Email Address []: |
命令的解释:
req: 创建证书请求;-new: 产生新的证书;-x509: 直接使用 x509 产生新的自签名证书,如果不加这个参数,会产生一个“证书签名请求”而不是一个证书。-days 365: 证书1年之后过期,也可以省略这个参数,设置为永不过期;key: 创建公共证书的私钥,会被提示输入私钥的密码;-out: 生成的证书。
到这里,我们有了一对 CA 证书,ca.key 和 ca.crt 两个文件。接下来申请 server 端的证书。
Server 端证书依然是先生成一个 key,这里就不需要密码保护了:
|
|
openssl genrsa -out server.key 4096 |
然后这里下一步不是直接生成证书,而是生成一个证书请求。但是那些问题依然是要回答一遍的。
|
|
openssl req -new -key server.key -out server.csr |
回答问题的时候要注意两个地方:
- Organization Name: 不能和 CA 的一样;
- Common Name: 必须要写一个,可以写一个不存在的域名,比如
proxy.example.com。否则,会有错误:“* SSL: unable to obtain common name from peer certificate”。
否则证书无法使用。
到这里其实也可以看出,CA 的证书和其他的证书没有什么不同,也是一个普通的证书而已。
这个 .csr 文件是 Ceritifcate Signing Request,即请求签名。接下来我们使用我们的 CA 给这个 Server 证书签名(作担保!)。
|
|
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key -set_serial 01 -out server.crt |
这个命令需要输入 CA key 的密码,就是刚刚说的 hello。
命令的解释:
x509: 公有证书的标准格式;-CA: 使用 CA 对其签名;-CAkey: CA key(没有这个岂不是人人可以用 CA 证书签名了?);-set_serial 01: 签发的序列号,如果证书有过期时间的话,过期之后,可以直接用这个 .csr 修改序列号重新签一个,不需要重新生成 .csr 文件;
如此,就得到了 server.crt 文件。
我们可以使用这条命令验证生成的证书是 ok 的:
|
|
# openssl verify -verbose -CAfile ca.crt server.crt server.crt: OK |
重复此流程再签发一个 client 端的证书。
结束后,我们有以下内容:
ca.keyca.crt- CA 的密码,需要保存
server.keyserver.crtserver.csr: 部署不需要用到,可以只保存在安全的地方即可;- Server 证书签发序列:只保存即可;
client.keyclient.crtclient.csr: 部署不需要用到,可以只保存在安全的地方即可;- Client 证书签发序列:只保存即可;
然后接下来就可以部署起来了。
搭建远程 Server 端的 Nginx
为了模拟转发到后端应用的场景,这里的 Nginx 不使用静态文件,而是用一个 fastapi 写的样例程序来做后端:
|
|
from typing import Optional from fastapi import FastAPI app = FastAPI() @app.get("/") def read_root(): return {"Hello": "World"} |
启动的命令是:
程序默认会运行在 8000 端口。
然后修改 Nginx 的配置,nginx.conf 不变,我们只修改 default 的配置,将 default rename 成 remote_server,然后修改成成如下配置:
|
|
server { listen 443 default_server ssl; listen [::]:443 default_server ssl; server_name _; ssl_certificate /home/vagrant/cert/server.crt; ssl_certificate_key /home/vagrant/cert/server.key; location / { proxy_pass http://127.0.0.1:8000; } } |
这就是一个很简单的 Nginx HTTPS 配置,证书配置上了我们刚刚自己签发的证书:
ssl_certificate: 告诉 Nginx 使用哪一个公有证书;ssl_certificate_key: 此证书对用的私钥是什么,服务器需要有私钥才能工作。
证书已经配置好了。这时候我们去 cURL 443 端口会出现错误:“curl: (60) SSL: unable to obtain common name from peer certificate”,cURL 不信任这个服务器的证书。这是当然了,因为这个证书是我们自己作为 CA 签的。
要正常访问,必须使用 cURL --ca ./ca.cert 来告诉 cURL 我们信任这个 CA (所签发的所有证书)。
另外还要注意的是,记得我们之前的 Server 证书是签发给 proxy.example.com 的吗?我们这里必须要访问这个域名才行。需要这样使用:
|
|
curl -v https://proxy.example.com --cacert ./ca.crt --connect-to proxy.example.com:443:127.0.0.1:443 |
--connect-to 的意思是,所有发往这个域名的请求,都直接发给这个 IP。
Client 对 Server 的验证就配置好了,接下来再配置 Server 对 Client 的验证。
我们只需要将上面的配置文件改成如下即可:
|
|
server { listen 443 default_server ssl; listen [::]:443 default_server ssl; server_name _; ssl_certificate /home/vagrant/cert/server.crt; ssl_certificate_key /home/vagrant/cert/server.key; ssl_verify_client on; ssl_client_certificate /home/vagrant/cert/ca.crt; location / { proxy_pass http://127.0.0.1:8000; } } |
添加的内容的含义:
ssl_verify_client: 需要验证客户端的证书;ssl_client_certificate: 我们信任这个 CA 所签发的所有证书。
这里有一个小插曲:Nginx 的文档上说,ssl_trusted_certificate 和 ssl_client_certificate 这两个配置效果都是一样的,唯一的区别是 ssl_client_certificate 会将信任的 CA 列表发送给客户端,但是 ssl_trusted_certificate 不会发。发送是合理的,因为客户端如果有很多证书,让客户端一个一个去尝试哪一个能建连是没有意义并且很浪费的。ssl_trusted_certificate 的作用是验证 OCSP Response。但是我尝试了 ssl_trusted_certificate,Nginx 会直接 fail 掉语法检查:
|
|
The server fails to start with error: nginx: [emerg] no ssl_client_certificate for ssl_verify_clientb |
这里发现一个 ticket 询问和我一样的问题:https://trac.nginx.org/nginx/ticket/1902,不过至今没有回复。我以为是 Nginx 版本的 Bug,然后尝试了最新的版本依然是一样的结果。如果读者知道可以指点一下,谢谢。
这样配置之后 reload Nginx,就开启了对客户端的证书验证了。这时候我们继续使用上面那个 cURL,就无法得到响应。
|
|
<head><title>400 No required SSL certificate was sent</title></head> |
Nginx 会要求你提供证书。
如下的 cURL,带上证书,就可以正常拿到响应。
|
|
curl -v https://proxy.example.com --cacert ./ca.crt --connect-to proxy.example.com:443:127.0.0.1:443 --cert client.crt --key client.key |
这样,远端的 Nginx 就配置好了,它会提供证书证明自己的身份,也会要求客户端提供证书进行验证。
接下来搭建本地的 Nginx,将明文请求加密对接到远端的 Nginx。
搭建本地 Client 端的 Nginx
本地机房开启一个 Nginx,监听 80 端口,转发到远程的 443 端口。
配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
upstream remote{ server 127.0.0.1:443; } server { listen 80 default_server; listen [::]:80 default_server; server_name _; location / { proxy_pass https://remote; proxy_ssl_trusted_certificate /home/vagrant/cert/ca.crt; proxy_ssl_verify on; proxy_ssl_server_name on; proxy_ssl_name proxy.example.com; proxy_ssl_certificate /home/vagrant/crt/client.crt; proxy_ssl_certificate_key /home/vagrant/cert/client.key; } } |
这个配置可以分成两部分看,第一部分,是要验证对方的证书:
- proxy_ssl_verify: 需要对方提供证书;
- proxy_ssl_trusted_certificate: 我们只信任这个 CA 签发的所有证书;
- proxy_ssl_server_name: 不像 cURL 的
--connect-to 选项,这里我们直接指定目标 IP 转发,但是我们使用 SNI 功能来告诉对方我们要连接哪一个 domain,来验证相关 domain 的证书;
- proxy_ssl_name: 我们需要哪一个 domain 的证书。
然后第二部分是提供自己的证书:
- proxy_ssl_certificate: 我的证书;
- proxy_ssl_certificate_key: 我的私钥,不会发送给对方,只是本地 Nginx 自己使用。
然后就可以 cURL 本地的 80 端口了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
curl http://127.0.0.1 -v * Trying 127.0.0.1:80... * TCP_NODELAY set * Connected to 127.0.0.1 (127.0.0.1) port 80 (#0) > GET / HTTP/1.1 > Host: 127.0.0.1 > User-Agent: curl/7.68.0 > Accept: */* > * Mark bundle as not supporting multiuse < HTTP/1.1 200 OK < Server: nginx/1.18.0 (Ubuntu) < Date: Wed, 16 Mar 2022 03:49:05 GMT < Content-Type: application/json < Content-Length: 17 < Connection: keep-alive < * Connection #0 to host 127.0.0.1 left intact {"Hello":"World"} |
可以看到我们从客户端(cURL)发出明文 HTTP 请求,到服务端(fastapi)收到明文 HTTP 请求,两边都不知道中间流量加密过程,但是走公网的部分已经被加密了。就实现了本文开头的需求。
代理 TCP steam
以上是 HTTP 的配置,将其换成 TCP Steam 的代理也很简单,相应的配置修改一下就可以。这里我们以 Redis 服务为例来展示一下配置。
/etc/nginx/nginx.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
user www-data; worker_processes auto; pid /run/nginx.pid; include /etc/nginx/modules-enabled/*.conf; events { worker_connections 768; } stream { ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3; # Dropping SSLv3, ref: POODLE ssl_prefer_server_ciphers on; include /etc/nginx/conf.d/*.conf; include /etc/nginx/sites-enabled/*; } |
Remote Server 的配置:/etc/nginx/sites-enabled/remote_server
|
|
server { listen 443 ssl; proxy_pass 127.0.0.1:6379; ssl_certificate /home/vagrant/cert/server.crt; ssl_certificate_key /home/vagrant/cert/server.key; ssl_verify_client on; ssl_client_certificate /home/vagrant/cert/ca.crt; } |
local_client 的配置:/etc/nginx/sites-enabled/client_server
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
upstream remote{ server 127.0.0.1:443; } server { listen 80; listen [::]:80; proxy_pass remote; proxy_ssl_trusted_certificate /home/vagrant/cert/ca.crt; proxy_ssl_verify on; proxy_ssl_server_name on; proxy_ssl_name config.example.com; proxy_ssl on; proxy_ssl_certificate /home/vagrant/cert/client.crt; proxy_ssl_certificate_key /home/vagrant/cert/client.key; } |
基本上就是把 HTTP 代理换成了 TCP 代理指令。
这样配置好之后,我们就可以用 redis-cli 去连接本地的 80 端口了。
|
|
redis-cli -p 80 127.0.0.1:80> get foo "bar" |
一些参考资料:
- Nginx 反向代理相关的文档。http://nginx.org/en/docs/http/ngx_http_proxy_module.html
- CA 如何保存 key?https://security.stackexchange.com/questions/24896/how-do-certification-authorities-store-their-private-root-keys
- 自签名证书的风险:https://www.preveil.com/blog/public-and-private-key/
- TLS 建联的展示,每一个字段都有详细的展示,非常好看:https://tls.ulfheim.net/
- 什么是 mTLS? https://www.cloudflare.com/zh-cn/learning/access-management/what-is-mutual-tls/