Coredns 的启动流程不是很好阅读,因为它本质上是一个 caddy server, 是基于 caddy 开发的。也就是说,它是将自己的逻辑注入到 caddy 里面去,相当于把 caddy 当做一个框架来用,实际的启动流程其实是 caddy 的启动流程,Coredns 里面不会看到很明确的准备启动,Start server 之类的代码,而大部分都是注册逻辑到 caddy 代码。类似于 Openresty 和 Nginx 的关系。这就导致一开始阅读源码不是很好上手,需要搞清楚哪些东西是 Coredns 的,哪些接口是 caddy 的。而 caddy 的文档又不是很多,而且 Coredns 所使用的 caddy 已经不是官方的了,而是自己维护的一个版本,也加大了阅读的难度。所以我将启动流程梳理了这篇博客,希望能理清它的逻辑。
在开始分析源代码之前,读者需要具备的准备工作是:
- Golang 的基本语法,但是我发现 Golang 很简单,看完 https://gobyexample.com/ 足矣;
- 知道 DNS 的基本工作原理,知道 DNS Resolver, DNS Root Server, DNS TLS Server 的区别,能区分 Cloudflare 1.1.1.1 服务和 AWS 的 Route53 分别是什么角色,知道 Coredns 是哪一种 Server(其实 Coredns 哪一个都能做);
- 需要先看完 Coredns 的使用文档,知道它怎么配置;
在完成了这些之后,就基本可以知道 Coredns 是怎么工作的了。在开始进入源码之前,可以通过已知的文档来思考一下:如果 Coredns 需要完成已知的这些功能,需要做哪些事情呢?
猜想的实现模块
因为在之前的博客中已经介绍过,Coredns 其实是基于一个 caddy 的 server,所以我们可以猜想 Coredns 必须要完成以下事情:
- 需要能够解析 Corefile,这是 Coredns 的配置文件;
- 需要维护一个 Plugin Chain,因为 Coredns 工作方式的本质是一个一个的 Plugin 调用;
- Plugin 需要初始化;
- Coredns 是基于 caddy 的,那么 Coredns 必须有地方告诉 caddy 自己处理请求的逻辑,监听的端口等等;
你可能还想到了其他的功能,这样,在接下来的源码阅读中,就可以尝试在源代码中找到这些逻辑,看看 Coredns 是怎么实现的。
Coredns 的入口程序是 coredns.go,里面只有两部分,第一部分是 import,第二部分是 main。
|
|
import ( _ "github.com/coredns/coredns/core/plugin" // Plug in CoreDNS. "github.com/coredns/coredns/coremain" ) func main() { coremain.Run() } |
Golang 的 import 并不是简单地引入了 package 的名字,如果 package 里面有 init() 的话,会执行这个 init()。所以这里的 import 其实做了很多事情。
注册
import package 的时候,imported package 还会 import 其他的 package,最终,这些 package 的 init() 都会被执行。
import 的链路和最终执行过的 init 如下,其中一些不重要的,比如 caddy.init() 在图中忽略了。
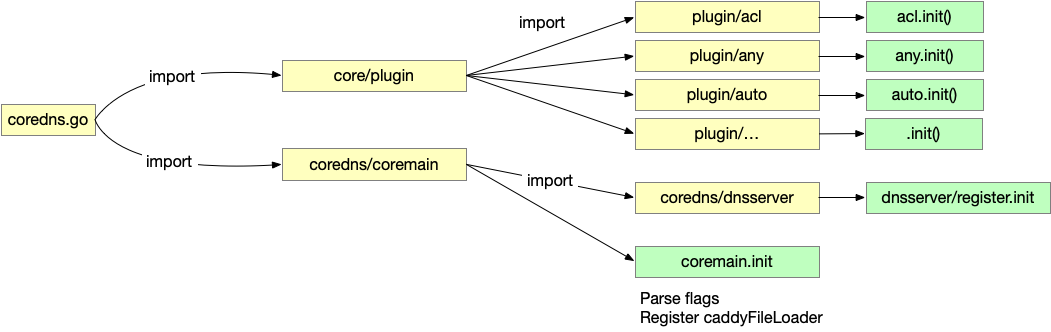
重要的注册主要有两部分,第一部分是将所有的 Plugins 都 import 了一遍,并且执行了这些 Plugin 里面的 init()。这个 Plugin 的 import 列表其实是生成的,在之前的博客中提到过。
因为 Golang 是静态编译的语言,所以要修改支持的 Plugin 列表,必须要重新编译 Coredns:
- 修改
plugin.cfg 文件
- 使用仓库中的
directives_generate.go 生成 zplugin.go 源代码中文,这时 import 列表更新
- 重新编译 Coredns
Plugin 中的 init() 做的事情很简单,就是调用 coredns.plugin.Register 函数,将 Plugin 注册到 caddy 中去,告诉 caddy 两个事情:
- 这个 Plugin 所支持的 ServerType 是 DNS
- Plugin 的
Action,即初始化函数。这里只是注册,并没有运行过。
第二部分是 register 中的 init 函数,主要的动作是使用 caddy 的接口 caddy.RegisterServerType 注册上了一个新的 Server 类型。
注册的时候,要按照 caddy 的接口告诉 caddy:
- Directives: 新的 ServerType 支持的 Directives 是什么;
- DefaultInput: 在没有配置文件输入的时候,默认的配置文件是什么,这个选项其实不重要;
- NewContext: 这个是最重要的,如何生成对应这个 ServerType 的 Context,Context 是后面管理 Config 实例的主要入口;
coremain 里面也有一个 init() 主要是处理了 Coredns 启动时候的命令行参数,然后注册了 caddyFileLoader,即读取(注意还没有解析)配置文件的函数。
到这里,import 阶段就结束了,目前为止所做的工作大部分都是将函数注册到 caddy,告诉 caddy 应该做什么,函数并没有运行。
然后回到 coredns.go 文件的第二部分:coremain.Run()。
启动
数据结构
启动的大致流程是,初始化好各种 Instance, Context, 和 Config, 然后启动 Server. 不同的阶段所初始化的数据结构不同,要理解这个过程,最好先明白这些数据结构之间的关系。主要的数据结构以及它们之间的互相应用如下图。黄色的表示 caddy 中的数据结构,绿色的表示 Coredns 中的数据结构。
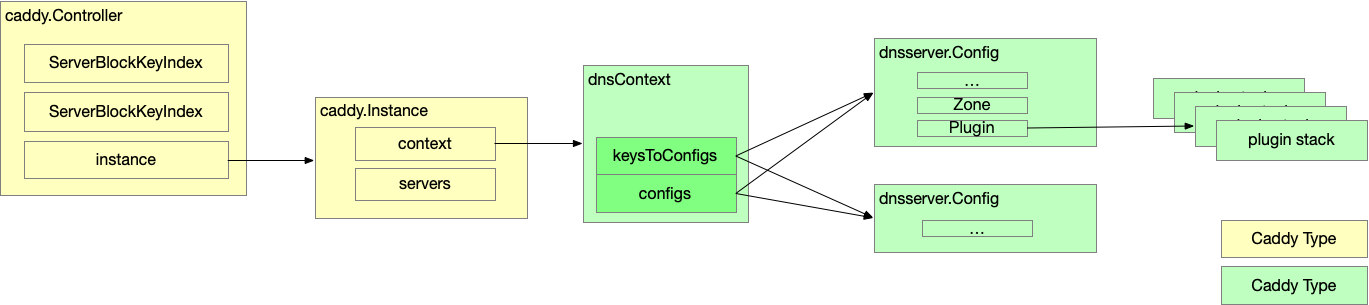
其中,caddy.Controller 和 caddy.Instance 是 caddy 中定义的结构,主要是 caddy server 在使用,Coredns 中并没有看到很多用到的地方。
dnsContext 是实现了 caddy.context,内部保存了和 Config 之间的关系,实现了 caddy 中定义的 InspectServerBlocks 和 MakeServers 接口,是一个主要的数据结构。对应 caddy.Instanse 全局只有一个,由 caddy 创建。
Config 就完全是 Coredns 内部的结构了,是最重要的一个结构,里面保存了 Plugin 列表,在处理 DNS 请求的时候,主要通过 Config 去调用 Plugin. 对于每一个 Corefile 配置文件中的 ServerBlock 和 Zone 都会有一个 Config 实例。
启动流程
Coredns 的启动流程之所以复杂,一个原因是真正的流程在 caddy 中而不是在 Coredns 中,另一个原因是随之而来的各种逻辑,本质上是 Coredns 定义的,然后注册到 caddy 中,caddy 执行的代码实际上是 Coredns 写的。
所以为了说明白这个启动的流程,我先画了一个图。启动流程的本职是初始化好上文中描述的各种数据结构。下图中,上面是数据结构,下面是代码的执行流程。在下图中,实线表示实际调用关系,虚线表示这段代码初始化了数据机构实例。
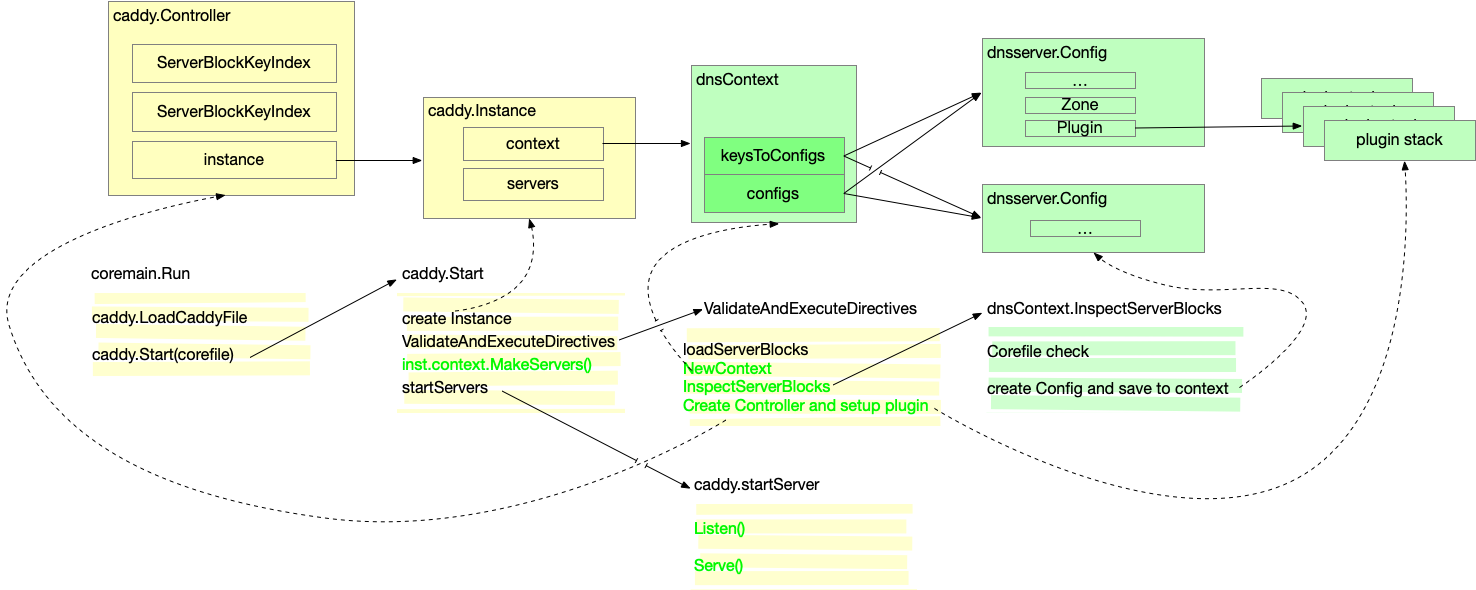
从 coremain.Run 开始,这里逻辑很简单,先是执行了上文提到过的注册的 caddyFileLoader 。然后调用了 caddy.Start,由 caddy 负责主要的启动流程。
下面我们找深度优先描述这个启动过程。
Caddy 先创建了一个 Instnace ,然后调用 ValidateAndExecuteDirectives。
ValidateAndExecuteDirectives 中,根据我们之前 load 出来的 caddy file 中的 ServerType string,拿到 DNS Server Type,就是上文提到的我们在 init 的过程中注册进去的。
然后执行 loadServerBlocks,这是 caddy 内置的函数,根据我们之前注册的 ServerType.Directives 返回的 Directives 去解析 caddy file,这时候是作为一个普通的 caddy 文件解析的,没有 coredns 的解析逻辑。这时候原来的 caddy file 被解析成 Tokens。由此也可以看出,Coredns 的配置文件和 Corefile 和 caddy 的格式必须是一样的,遵循一样的语法规范,因为解析器都是用的 caddy 中的(如果 Coredns fork 的版本没有修改的话)。
下一步是调用 ServerType 注册的第二个重要方法:NewContext 创建出来一个 context,实质的类型是 dnsContext。
然后调用 context.InspectServerBlocks,这个逻辑也是 Coredns 中实现的,是 dnsContext 实现的接口。主要做了两件事,一是检查 Corefile 是否合法,有无重复定义等。然后是创建 dnsserver.Config,Config 主要是和 dnsContext 关联,我们后面拿到这个 Config 主要也是通过 Context。比如在 config.go 中通过 Controller 拿到对应 Config 的方法实现:
|
|
// GetConfig gets the Config that corresponds to c. // If none exist nil is returned. func GetConfig(c *caddy.Controller) *Config { ctx := c.Context().(*dnsContext) key := keyForConfig(c.ServerBlockIndex, c.ServerBlockKeyIndex) if cfg, ok := ctx.keysToConfigs[key]; ok { return cfg } // we should only get here during tests because directive // actions typically skip the server blocks where we make // the configs. ctx.saveConfig(key, &Config{ListenHosts: []string{""}}) return GetConfig(c) } |
实际上是通过 Controller 找到 Instance, 然后找到 Instance 上的 Context (c.Context() 逻辑)。然后通过一个 Utils 去从 Context 上找到对应的 Config。这个实现和上图也是完全符合的。
上文提到过,每一个 Server Block 中的每一个 Key 都会有一个对应的 Config,那么这么多的 Config,我们怎么找到对应的呢?
其实就是 keyForConfig 的逻辑,context 中记录了 Server Block Index + Server Block Key Index 组合,和 Config 的一一对应关系。
回到 ValidateAndExecuteDirectives 的逻辑,调用完 InspectServerBlocks 之后,就是针对每一个 Directive 去拿到 Action 然后去执行。即,初始化每一个 Plugin。
完成之后,逻辑回到 caddy.Start中,会调用 dnsContext 中实现的第二个重要的接口:MakeServers. 初始化好 Coredns 中的 Server.
最后一步,就是 startServers 了,这里实际的逻辑又回到了 Coredns 实现的接口上。感觉比较清晰,没有什么难以理解的地方。主要是实现了两个接口,一个是 Listen, 一个是 Serve。
然后就可以开始处理请求了。
开始处理请求
最后 Server 实现了 caddy.Server 的 Serve 方法, 里面做的事情主要就是根据 DNS 查询请求里面的 zone 匹配到对应的 Config,然后 PluginChain 保存在 Config 里面,通过调用 h.pluginChain.ServeDNS 来完成请求的处理。
本文的代码解析就到这里,至此启动流程就完成了。本文尽量少贴代码,试图缕清启动的流程,具体的代码如果对照本文的图片和解释应该都找到的,并且剩下的部分应该不难看懂。如果发现错误或者有疑问,欢迎在评论区交流。
本文基于 Coredns 源码 Commit:3288b111b24fbe01094d5e380bbd2214427e00a4
对应最近的 tag 是:v1.8.6-35-gf35ab931