周末收到邮件通知,说博客的流量马上要用完了。发现博客的访问量变高了许多,另外我将博客首页展示了最近的 5 篇文章,有时候贴的图片比较多,就比较耗费流量一些。
之前这个博客一直是跑在一个共享的“空间”上,这是在 Docker 出来之前比较流行的一种共享资源的方式。本质上就是我的博客会和其他的一些网站共用一个虚拟机,通过反向代理和 php 等的配置来隔离资源。但是用户没有权限控制 Nginx,php 等进程,也不能 ssh 登录到主机上做一些操作。只能使用服务提供商提供的文件管理页面,编辑特定位置的反向代理文件等。现在看来颇有一些 SaaS 的意味,呵呵。
由于只能使用一些有限的配置,不方便用脚本自动化一些操作,以及流量、存储空间也不高,所以一直想迁移到一个 VPS 上去部署,最近流量用的越来越高了,正好趁这个机会迁移一下吧。
之前的部署形式非常简单,就是使用“空间提供商”给的反向代理,上传我自己的 wordpress 程序,使用空间提供商提供的数据库,然后 CDN 之类的,空间提供商会自己处理。现在打算迁移到的目标结构是:

VPS 部署
在 VPS 上重新部署博客这一步是最麻烦的,本以为很快就可以搞定,但实际上却花了我一天的时间。
由于之前只能使用空间里面的东西,所以很多东西都是很旧的,比如 MySQL, PHP 等,PHP 太旧就导致 WordPress 不能使用最新版。然后就直接导致直接使用 PHP 7.4 无法部署起来我的博客。需要升级 WordPress.
这里有一个很坑的地方是,Wordpress 其实可以自己更新自己,打开后台界面,点击升级,就可以自动下载软件,升级到最新的版本。能通过后台来管理软件,对很多小白用户来说很友好,估计这也是 WordPress 如此流行的一个原因吧。但是其实对运维来说非常不友好,因为这样就没有隔离用户自己的代码和 WordPress 官方的代码,都是混在一起的。如果不通过后台来升级,我就需要自己下载代码,然后看要复制哪一些到我的博客里面;而通过后台升级,又可能会覆盖一些我自己的修改……
按照官方最新版的 Changelog 复制好文件之后,又陆续与到一些其他的坑,比如:
- 最新版的依赖已经改变了,网上安装 WordPress 的教程有很多,但是大多数都跑不起来,最好自己去 debug,看看缺少什么就安装什么(才发现 WordPress 的古登堡编辑器已经上线了,我打开之后直摇头,这是什么魔幻编辑器……果断用 Classic Editor 切换回默认的编辑器!);
- 最新版有一些新的数据库表,需要去检查有哪些 DDL 需要手动执行下;
- 我之前安装了一个 SSL 插件来将 HTTP 请求重定向到 HTTPS, 但是在部署的时候会导致本地也打不开 HTTP, 需要手动将这个插件删除……
- 之前安装的一些类似于 cache, 评论插件,代码高亮插件,在最新版的 WordPress 下已经无法工作了,需要挨个去检查有什么替代品;
- ……
挨个处理好之后,总算是跑起来了。还好按照错误日志的信息一步一步来,没有什么特别复杂的坑。
评论通知方案
之前的博客,在访客的评论得到回复之后,会自动向访客发送一封邮件。我觉得这样可以增加一些有意义的讨论。但是自己维护评论系统其实是个大坑。之前的邮件回复系统已经挂了很久了,我竟然不知道…… 不过这次迁到 VPS 去部署,也需要切换到一个国外的服务商来帮我发送邮件,所以是不可避免地要重新折腾一下了吧。
发送邮件总体来说有三个方案:
- 直接从 VPS 主机发。基本行不通,VPS 厂商一般会禁用主机直接发邮件,一般的邮件服务都会把 VPS 的 IP 段给屏蔽掉,来阻止垃圾邮件。所以就算你能从 VPS 上发出去,用户一般也收不到;
- 通过 Gmail 这样的域名来发送:这个方案比较可行,但是非常复杂,这个其实就通过 API 调用 Gamil,用 [email protected] 的发件人发送。我尝试过使用 Gamil, SendGrid, mailgun, mailchimp 等等,有一些尝试到一半发现只能发 newsletter 这种,不能发送通知;有一些发现到一般需要人工审核;有一些发现必须要付费。其中 Gmail 这个最烦人,就发送邮件的接口,我要去 Google Cloud Platform 申请一个账号,然后申请一个 OAuth, 然后创建一个 Application, 然后为这个 Application 创建一个 Scope, 有一堆让人看不懂是什么的概念,最后也没搞成,Gmail 说我的应用发邮件是敏感的权限,需要人工审核应用;
- 通过一些 Email 服务来发送,但是发件使用自己的 mx 记录。最后是通过 sendinblue 发送的。配置还不算特别复杂,只要添加 4 个 txt 的 DNS 记录来验证你拥有这个域名,然后通过 WordPress 插件 WP Mail SMTP 来集成一下就好了。
最后我修改了一下评论框,默认勾选邮件通知,但是用户也可以取消。

博客的评论框选项,欢迎留言~
实际自己测试了一下,发现提交一条评论大约要花 1s 左右,我怀疑这个发送邮件是同步的,也就是说通过 POST 留下一条评论之后,后台要在邮件要发出去之后再通知用户评论成功了。不过对于评论系统来说也可以接受吧……
备份方案
最麻烦的还是来了,得想个办法,能在下一次轻松在新机器上部署好博客。这里的难点是 WordPress 的代码会自己更新,比如在后台点一下就可以更新插件,Wordpress 版本等。要保证下次我部署的时候还是一模一样的版本和代码,不会因为某些地方下载不到了这种事情导致部署不起来……
最后决定是直接用 git 来管理博客的代码,将整个博客的代码放到一个 repo 中,这个 repo 放到 Github 上,然后把机器的 ssh key 加入到我的账号中,给这个机器此 repo 的写权限。这样就相当于我的博客是一个 WordPress 的 fork, 每次在后台更新了博客代码,就使用 git diff 检查一下 diff, commit 到 git 中。
其中,wp-content/uploads 这个目录是我上传的文件,这部分不是代码,不需要用 git 来 track. 为了方便部署又最小化修改,我直接将这个目录软连接到 /var/www/uploads,因为软连接并不需要目标位置一定存在,所以可以将这个软连接也追踪到 git 中。
这样代码的问题就解决了,我可以使用 git 的记录追踪在后台做的更新,可以保证运行所需要的代码都是有备份的。
然后剩下了两部分比较简单的备份:静态文件和 SQL 文件。每天备份即可。
Cloudflare CDN 设置
VPS 能访问通了之后,再部署 Cloudflare, 这样用户的请求永远到达 Cloudflare, 不会直接去访问我的主机,速度更快一些,也更安全。
这里按照 Cloudflare 的教程,将域名的 DNS 交给 Cloudflare 解析即可。但是中间遇到一个问题搞了好久:在设置成 Cloudflare 代理之后,访问域名总是出现 Error 521 Web Sever Is Down. 直接访问又是能访问通的。由于看不到日志,只能通过 Cloudflare 的界面来配置,所以没什么好的方法 debug. 我就直接在主机上 tcpdump 80 端口。发现 80 端口根本没有请求,这就意味这 Cloudflare 没有把用户的请求转发到 80 端口。
反复确认 DNS 的设置没问题之后,我有点怀疑人生了。
最后把 Cloudflare 的面板一个一个挨着看了一遍,发现一个这样的配置:
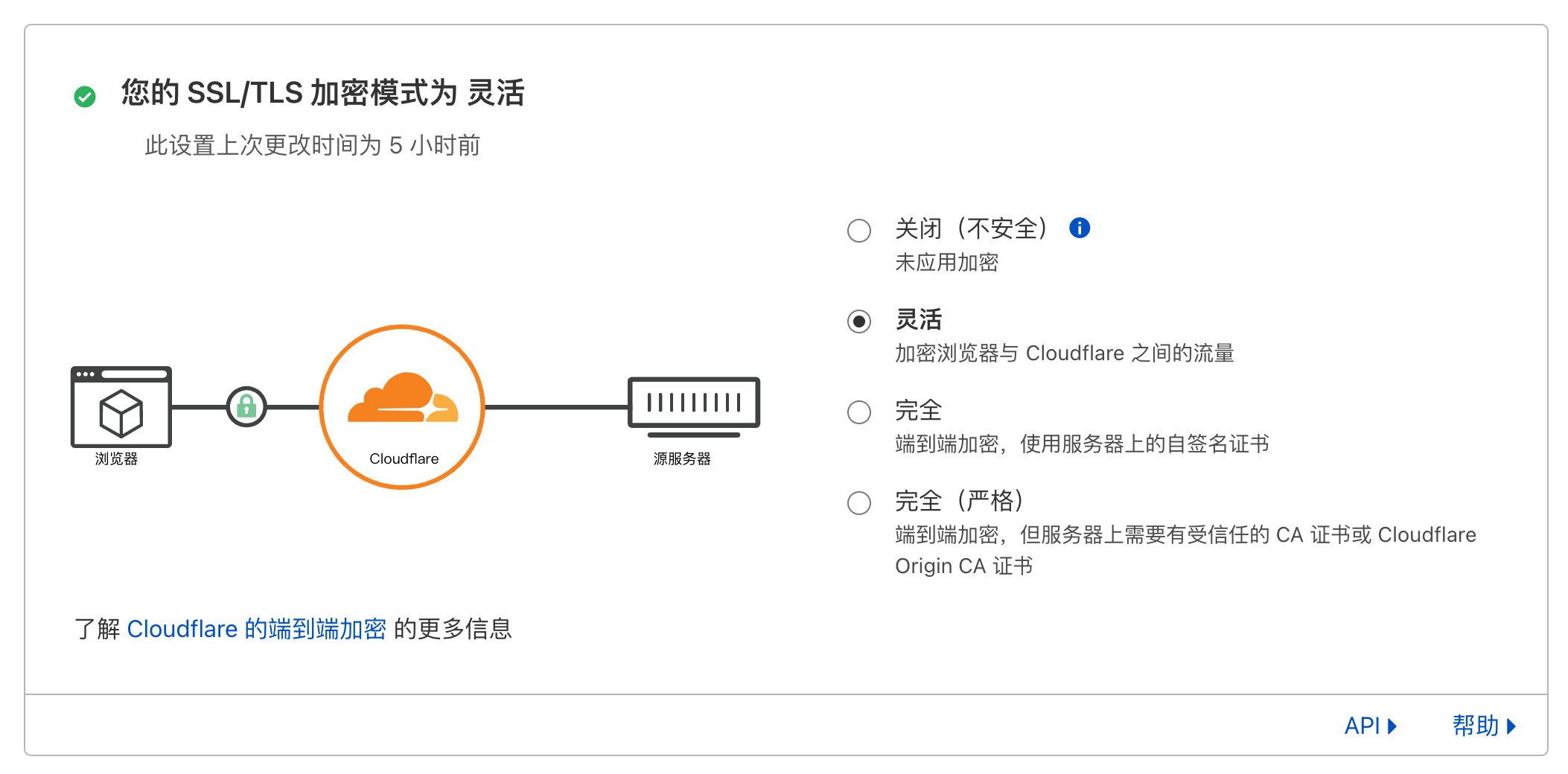
SSL/TLS 加密模式 配置
默认选择的是“完全”,也就是说,Cloudflare 请求我的网站去的是 443 端口,期望我是有证书的。而我用 CDN 有一个原因就是我懒得管理证书,直接让 Cloudflare 帮我把认证做好就可以了。至于 Cloudflare 访问我的源站,我觉得这里被劫持的概率不高吧……毕竟只是个博客,也不需要这么高的安全性。
改成“灵活”,果然就可以访问了。
Cloudflare 的 IP 设置
由于用了反向代理,实际到达我的主机的 IP 全部都是 Cloudflare 的 IP,如果看不到访客的真实 IP,那么对评论反垃圾的质量也有影响。
所以这里我自己写一个插件,来从 Cloudflare 发来的请求中获取访客的真实 IP(不要害怕,这年头谁上网没有个代理呢是吧),而不是代理的 IP.
- 首先在
wp-content里面创建一个mu-plugins,mu-plugins里面的 Plugins 是 Must Use Plugins, 会自动启用; - 然后在
mu-plugins创建 cloudflare-realip.php; - 在这个文件中输入以下代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<?php /* Plugin Name: Cloudflare Real IP Description: Get Cloudflare Real IP for comment Version: 1.0.0 Author: laixintao Author URI: kawabangga.com */ if ( isset( $_SERVER["HTTP_CF_CONNECTING_IP"] ) ) { $_SERVER['REMOTE_ADDR'] = $_SERVER["HTTP_CF_CONNECTING_IP"]; } |
这段代码的作用就是拿 Cloudflare 发来的真实 IP 字段,来放到 WordPress 要读取的字段中。
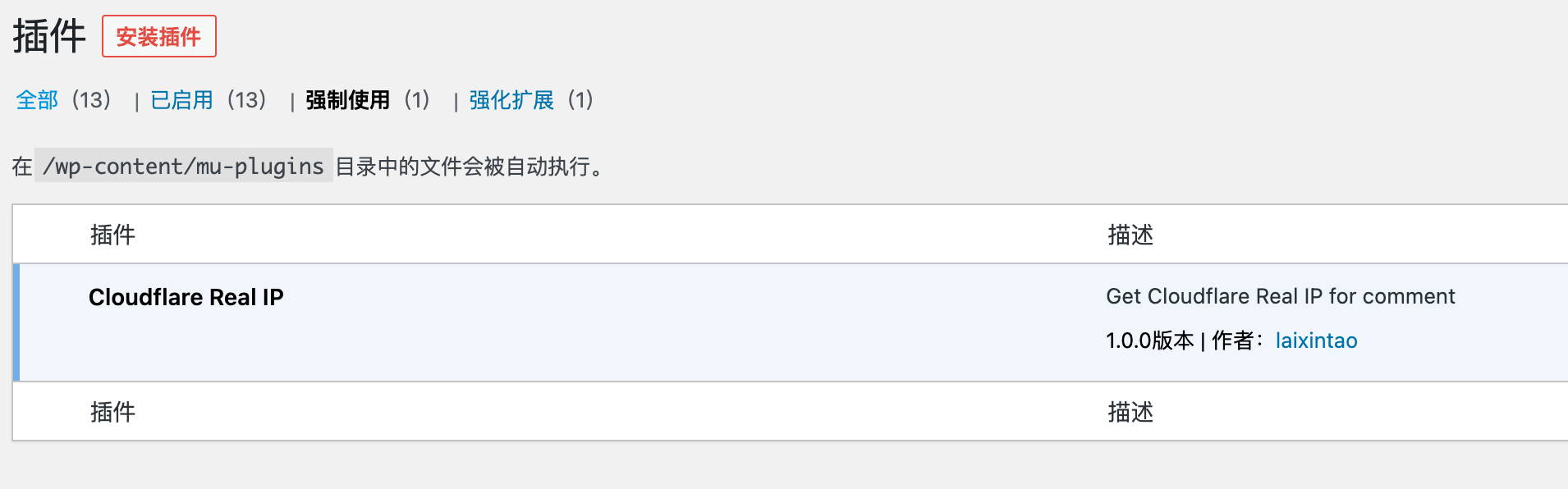
打开网站后台,可以看到插件已经启用了。留言测试,现在显示的就不是 Cloudflare 代理的 IP 了。
将缓存直接上传 CDN
有一个插件叫做 WP Cloudflare Super Page Cache, 可以将页面的缓存直接上传到 CDN 上面,这样用户在访问的时候都不会回源,相当于直接访问 Cloudflare 完成了请求。
但是实际测试下来发现区别不是很大,本地 Cache + CDN 已经比较快了。所以就没有用,因为毕竟 “WP-Super-Cache” 是官网的插件,质量要好一些。WP Cloudflare Super Page Cache 测试下来发现有评论之后不能立即看到评论的问题。
DNS 迁出
到这里,基本上所有的配置都好了。但是改 DNS 的时候,竟然丧心病狂地让我人脸识别。实在受不了了,多年以前不懂事,申请域名找了个国内的厂商,后来麻烦事一堆一堆的,又是实名认证又是人脸识别的。这次索性直接将域名转移到 namecheap 来管理了。
转移不算麻烦,只要在原来的注册商那里拿到密码然后去 namecheap 办理转入就行了。
在这个空间上跑了5年,终于要说再见了,哈哈。没想到部署一个博客花了一整个周末……
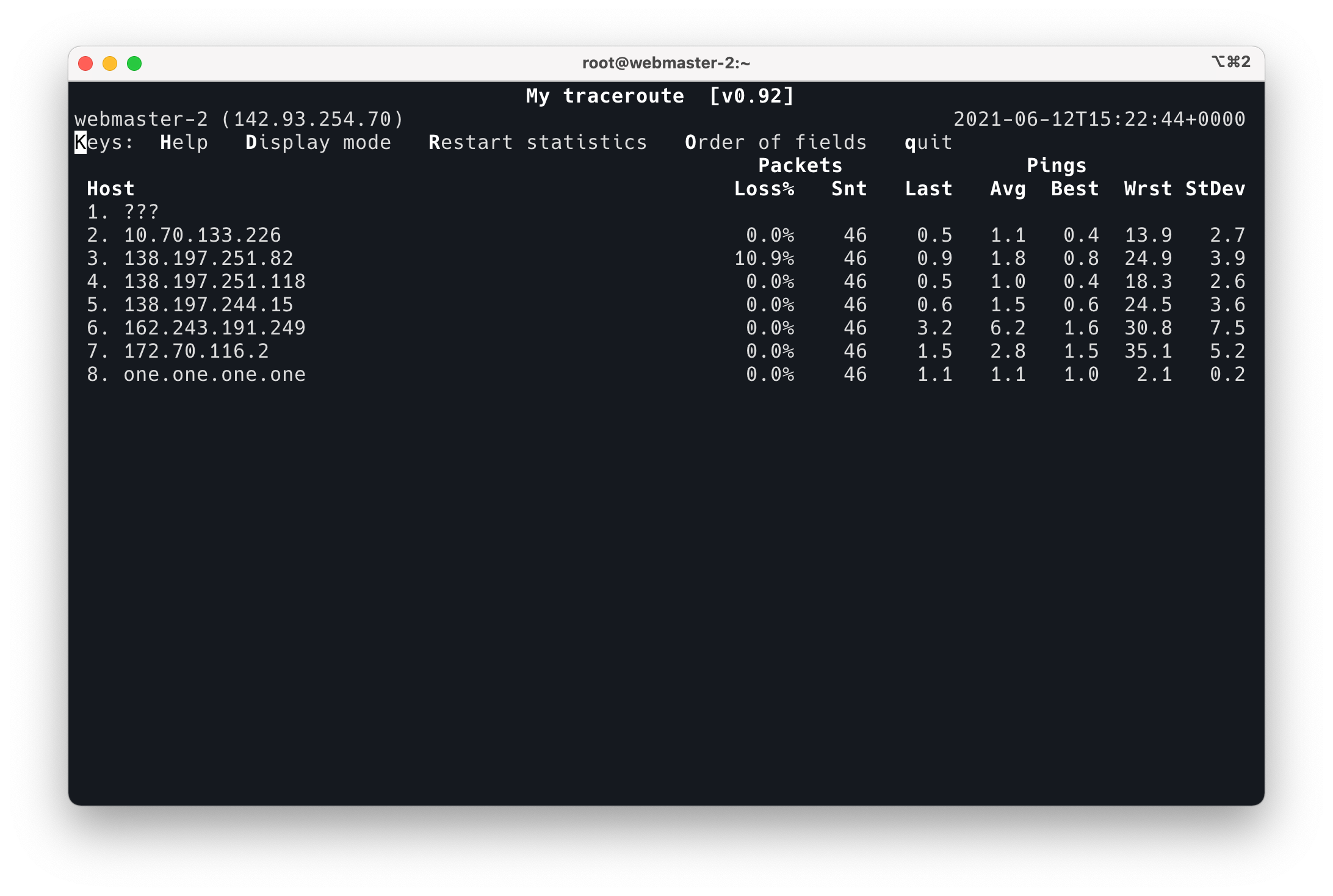
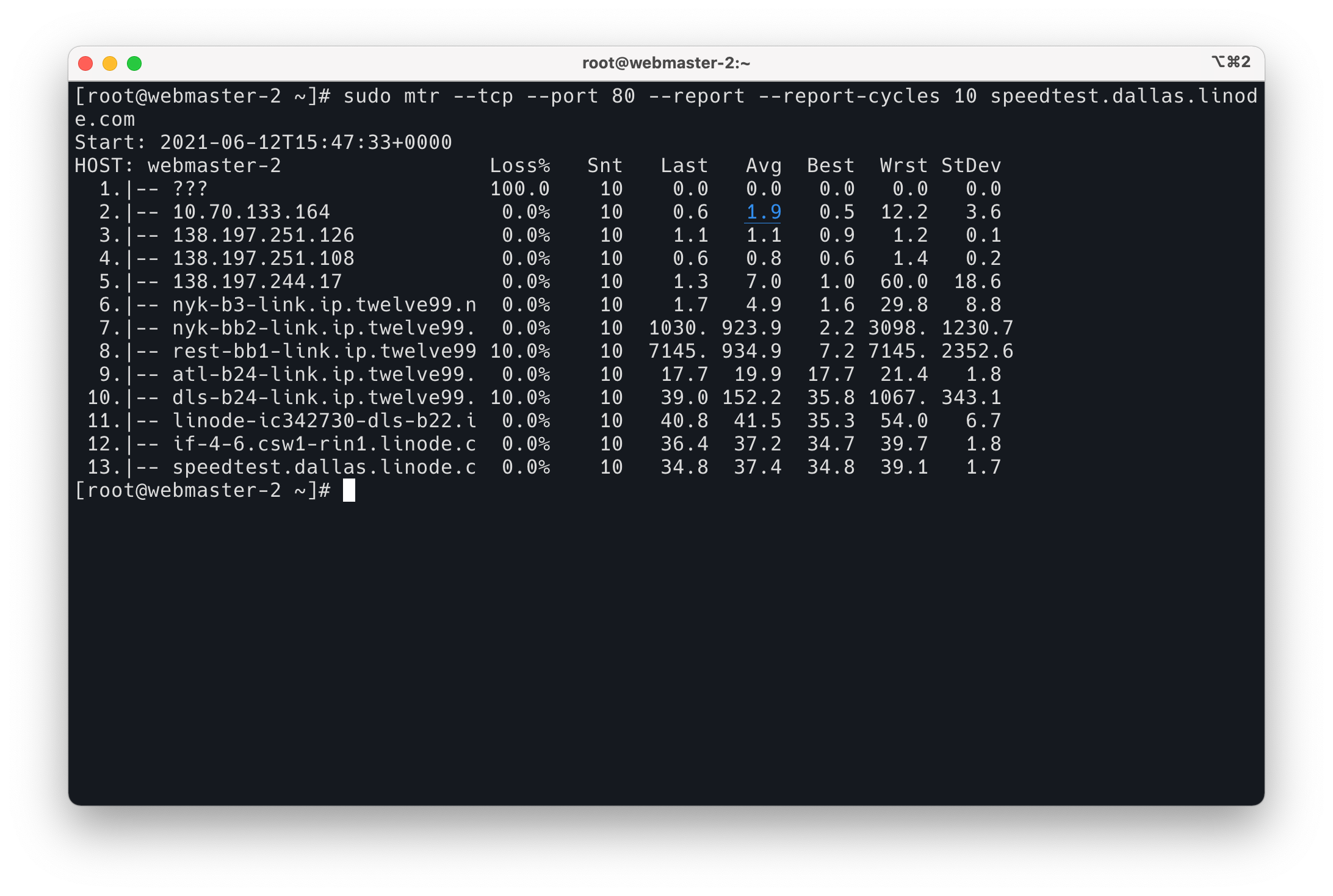
之前打开页面至少需要四五秒,CDN + 缓存一套搞下来,现在打开速度只要 2s 了,我在新加坡打开只需要不到 300ms, 这个速度也太爽了。真不知道我之前用那个“空间”那么慢是怎么忍受的……
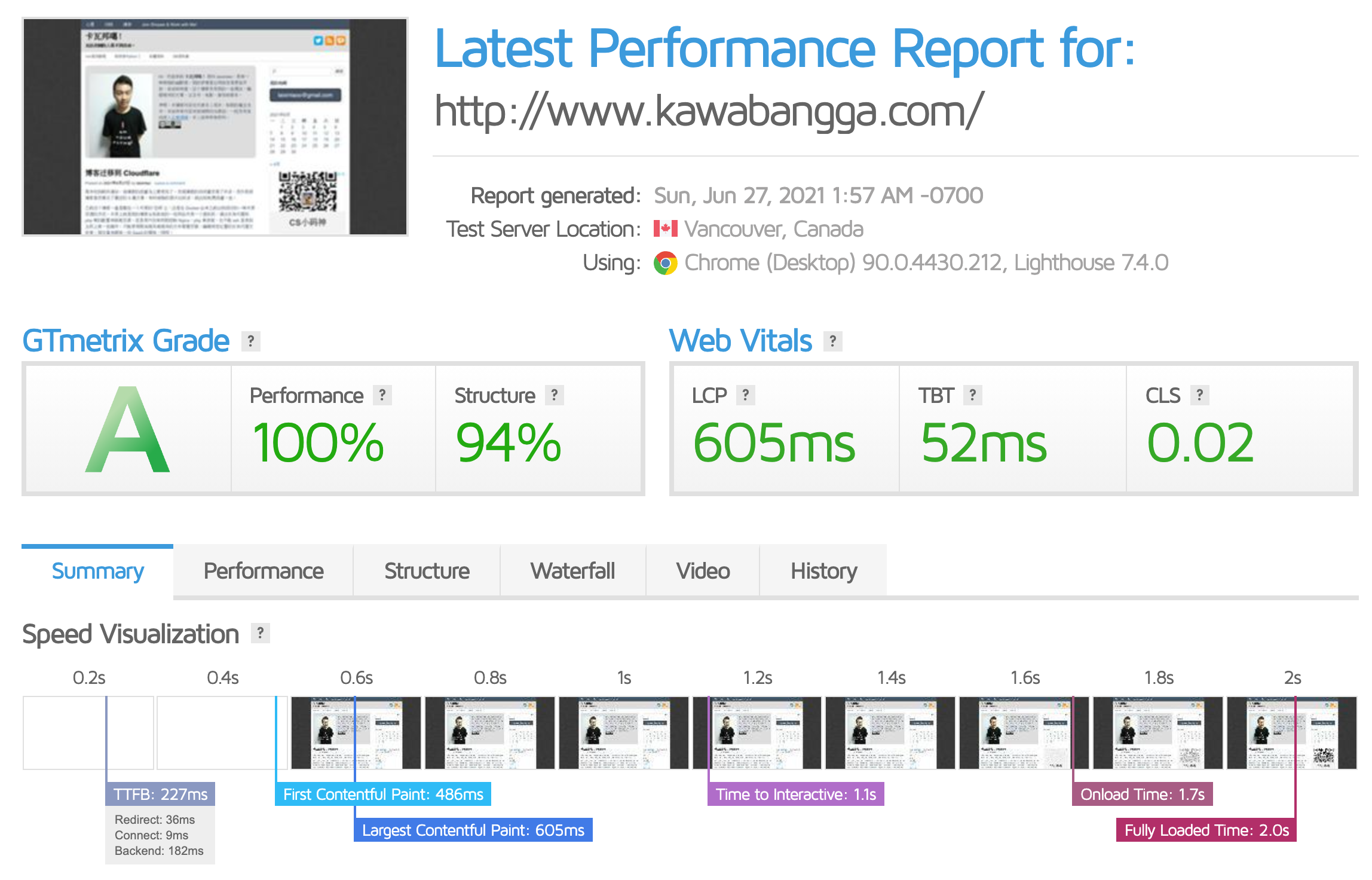
加拿大节点的速度测试

我在新加坡访问速度
还不太清楚 Cloudflare 在国内访问的质量怎么样,如果你发现现在打开这个博客速度有些问题,可以通过评论告诉我一下,谢谢。