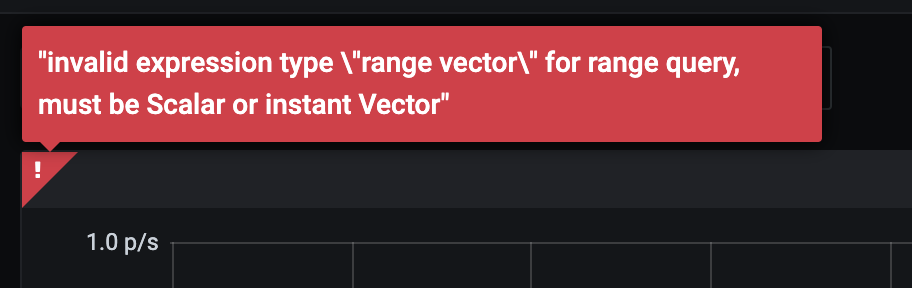
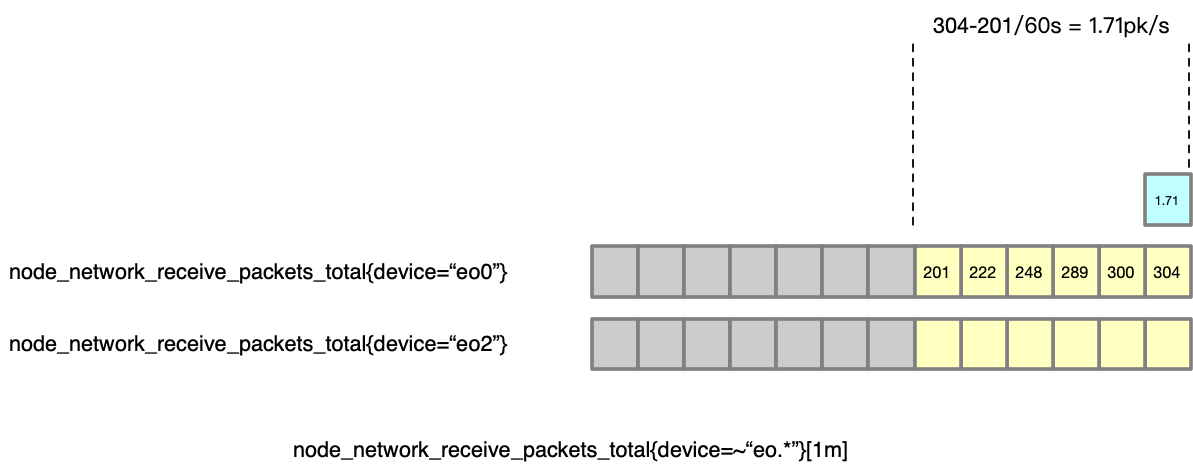
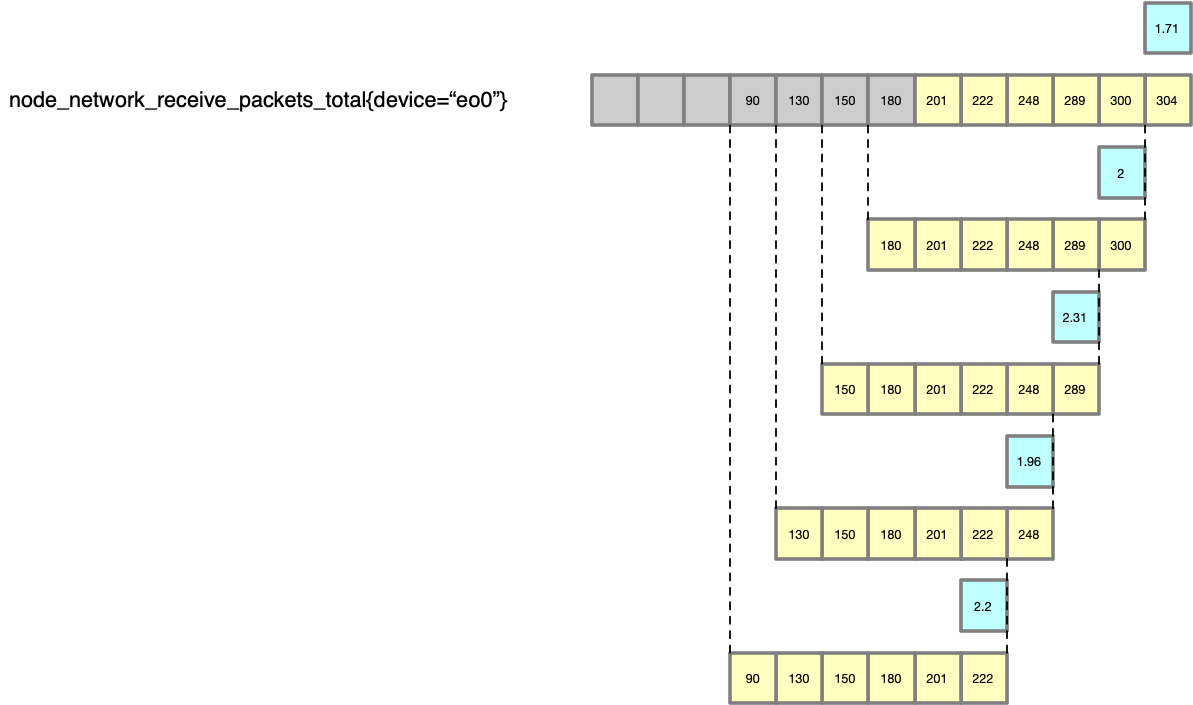
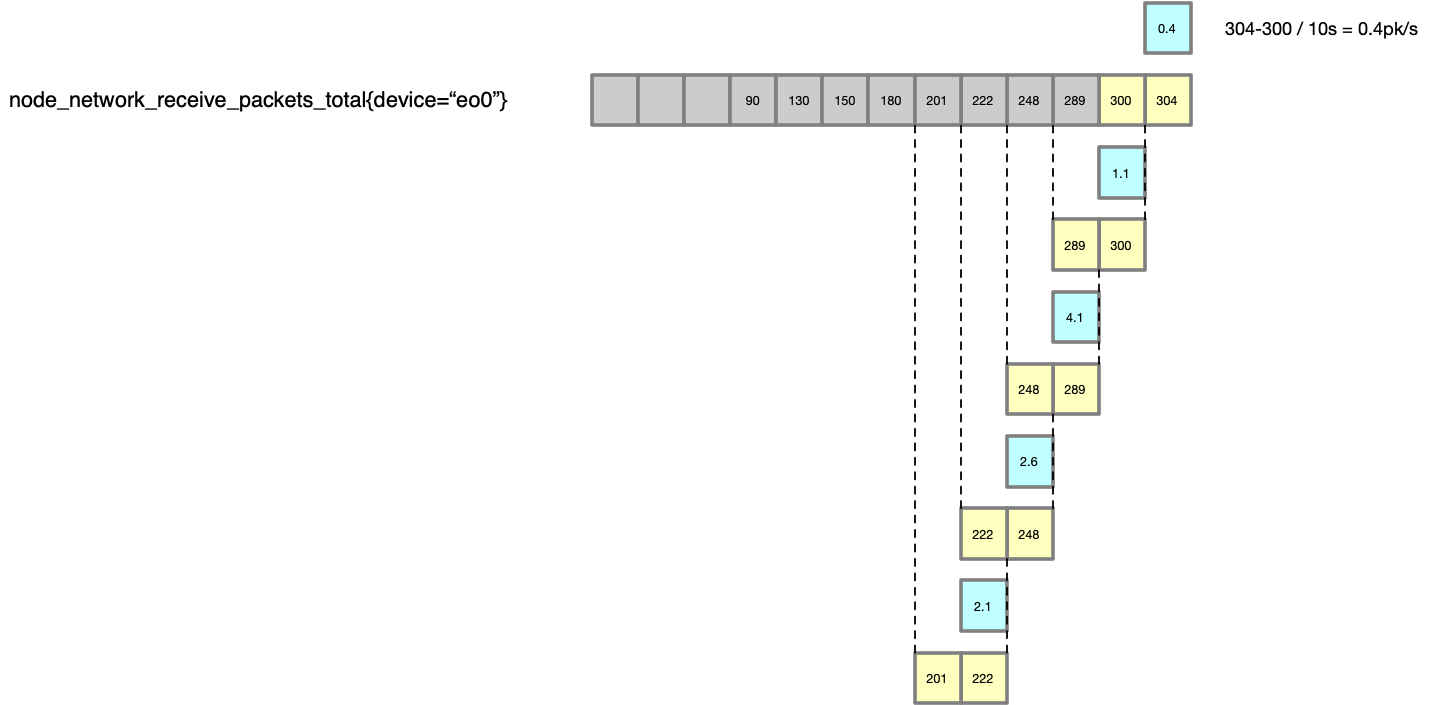
irate()
irate(v range-vector) calculates the per-second instant rate of increase of the time series in the range vector. This is based on the last two data points.
changes()
For each input time series, changes(v range-vector) returns the number of times its value has changed within the provided time range as an instant vector.
[nix-shell:~]$docker run nix-redis-minimal:latest redis-server
1:C19Jul202116:37:09.847# oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1:C19Jul202116:37:09.847# Redis version=5.0.7, bits=64, commit=00000000, modified=0, pid=1, just started
1:C19Jul202116:37:09.847# Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
1:M19Jul202116:37:09.848# WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
1:M19Jul202116:37:09.848# WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
为什么说这种复用是虚假的复用呢?Ansible 的逻辑里面,是可以支持复用的,但它的复用一般是将公共的部分封装,比如使用一个 role 来安装 Docker. 里面也有各种 if 来判断是什么 Linux 发行版,但是这种 if 是符合语义的:使用这个 role 可以帮你安装好 Docker,我在里面判断如果是 CentOS 就要这么安装,如果是 Ubuntu 就需要执行这些,等等。这是在“将复杂留给自己,将方便给用户”。当我使用他这个 role 的时候,我只要 include 进来,然后设置几个变量就好了。但是回到我们现在这个情况,此项目的复用没有带来任何简单。如果来了一个新的服务需要部署,我不可能直接使用原来的代码,必须要修改主流程,并且在原来的代码中添加 if。
我感觉这种味道的代码非常常见,在业务的代码中经常见到不同的函数复用了一个公共的函数,这个公共函数里面又充满了各种 if 去判断调用者是谁,然后根据不同的调用者去执行不同的逻辑(等等,这不会就是 Java 常说的控制反转吧!)。怎么能知道什么是合理的复用,什么是不合理的呢?其实你看到就知道了,从代码中你能看到作者在“绞尽脑汁”想着怎么搞点抽象出来。
Programmer A extracts duplication and gives it a name.This creates a new abstraction. It could be a new method, or perhaps even a new class.
Programmer A replaces the duplication with the new abstraction.Ah, the code is perfect. Programmer A trots happily away.
Time passes.
A new requirement appears for which the current abstraction is almost perfect.
Programmer B gets tasked to implement this requirement.
Programmer B feels honor-bound to retain the existing abstraction, but since isn’t exactly the same for every case, they alter the code to take a parameter, and then add logic to conditionally do the right thing based on the value of that parameter.
What was once a universal abstraction now behaves differently for different cases.
Another new requirement arrives. Programmer X.
Another additional parameter.
Another new conditional.
Loop until code becomes incomprehensible.
You appear in the story about here, and your life takes a dramatic turn for the worse.