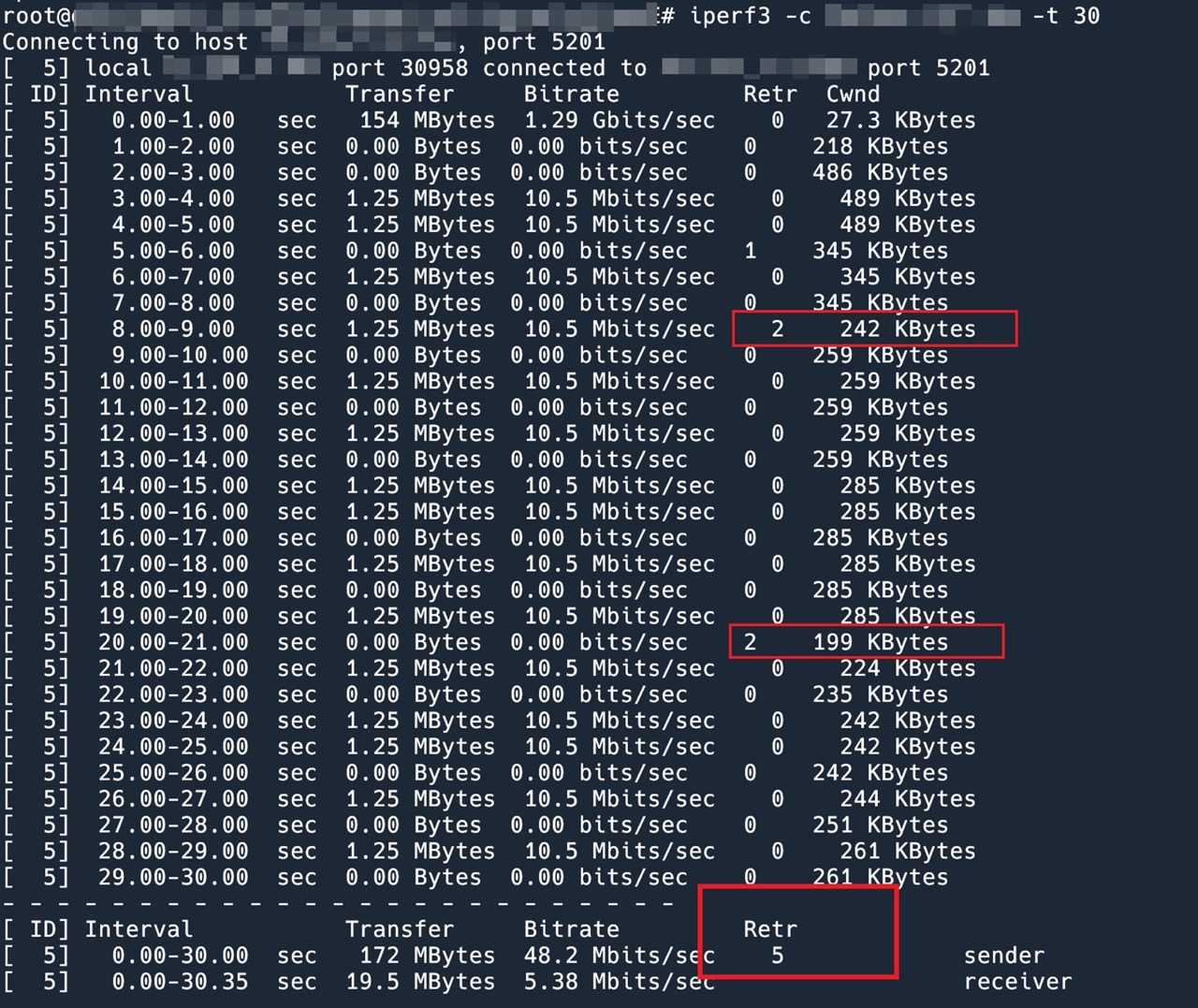
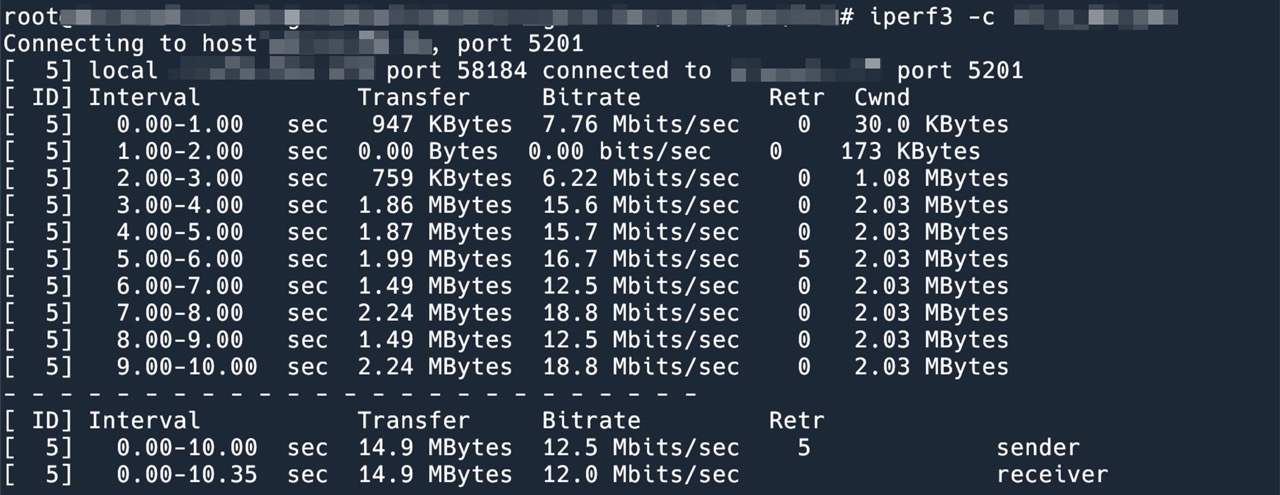
最近和 Luke 录制了一期播客。本来我们是买了一个话筒寄给嘉宾的,但是这个话筒不知为啥有电流声。所以就临时改成用手机录音了,出了点状况,导致最终出来的音质不是很好,Luke 的音轨底噪有一些强。放弃这一期不发布实在可惜,一筹莫展之际,我把剪辑好的 Mp3 文件发给最近一直在催更我的朋友听了,他说他用 iMovie 降噪之后听着还可以。这让我重新看到了希望,我去找了一些 Reaper 的降噪教程,想尝试对 Luke 的音轨进行降噪。最后的效果还不错,所以这里将我学到的降噪技巧分享一下,方便制作播客的兄弟们参考。
降噪的原理
如果你用过降噪耳机,你应该听说过「主动降噪」 这个词。它的原理就是,耳机会采集周围的环境声音,然后播放音乐的时候,播放一个和环境声音相反的声波。到你耳朵里的时候,因为耳机的反向噪音和环境噪音抵消了,就只剩下播放音乐的声音了。
剪辑技术中的降噪也是一样。先采样环境噪音,然后对整个音轨播放一个反向的声波,这样噪音就被抵消了。
上手操作
ReaFir 是 Reaper 自带的一个插件,可以完成降噪这项工作。Reaper 是一款非常优秀的音频处理软件,配合 UltraSchall4 插件,简直就是我一直在寻找的那个完美的播客剪辑软件!建议剪辑播客的朋友都尝试一下,UltraSchall4 专门为剪辑播客设计,里面的像 Normalize,切分,删除口头禅这样的常用剪辑操作都设计地非常方便。可以大大节省我们的剪辑时间。
话说回来,ReaFir 是 Reaper 自带的一个插件,不需要安装就可以使用。像一次典型的降噪处理,流程主要如下。
下面是我的剪辑界面,如果你没有安装 UltraSchall4 的话,看起来可能会稍微有些不一样。不过没关系,你只需要参考我的这张截图看如何找到对应的按钮就好了。
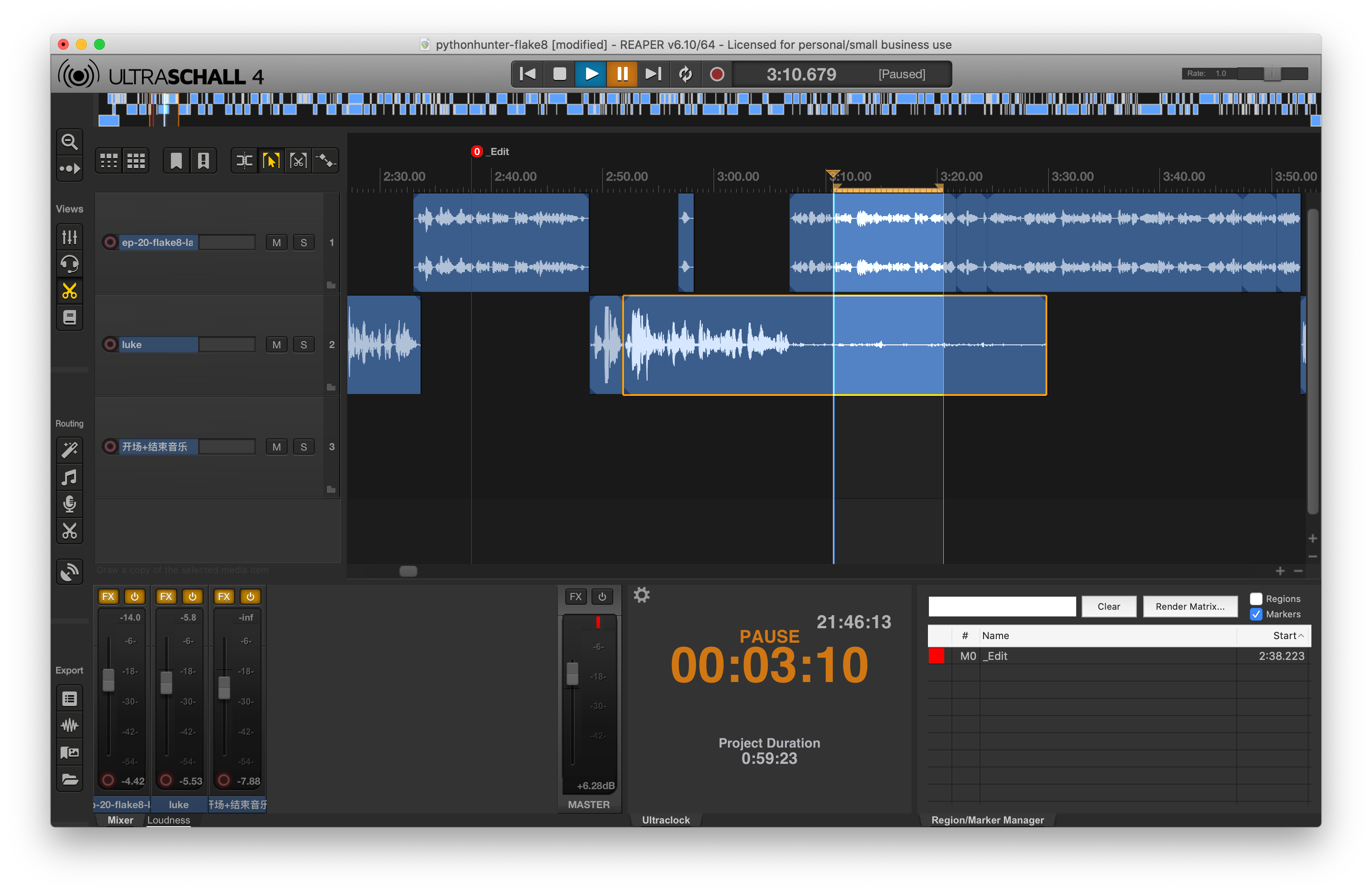
假设在这个剪辑界面中,我们的第二条音轨——Luke 的音轨底噪比较强。我们要对这条音轨进行降噪。首先在左下角用 FX 按钮打开音效插件界面。第一次打开可能没有我这里的 ReaFir 的,这时候点击 Add,先添加这个 ReaFir 插件。
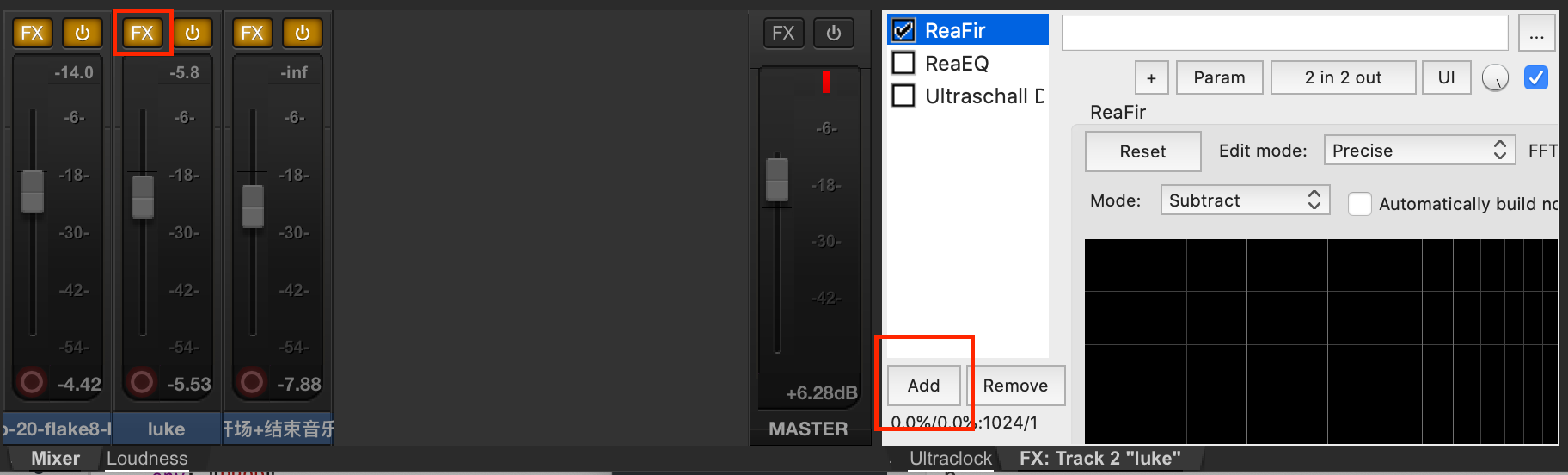
图2 – 添加 ReaFir 插件
在弹出的窗口中,选择 Cockos(Reaper的公司名字),然后选择 ReaFir。
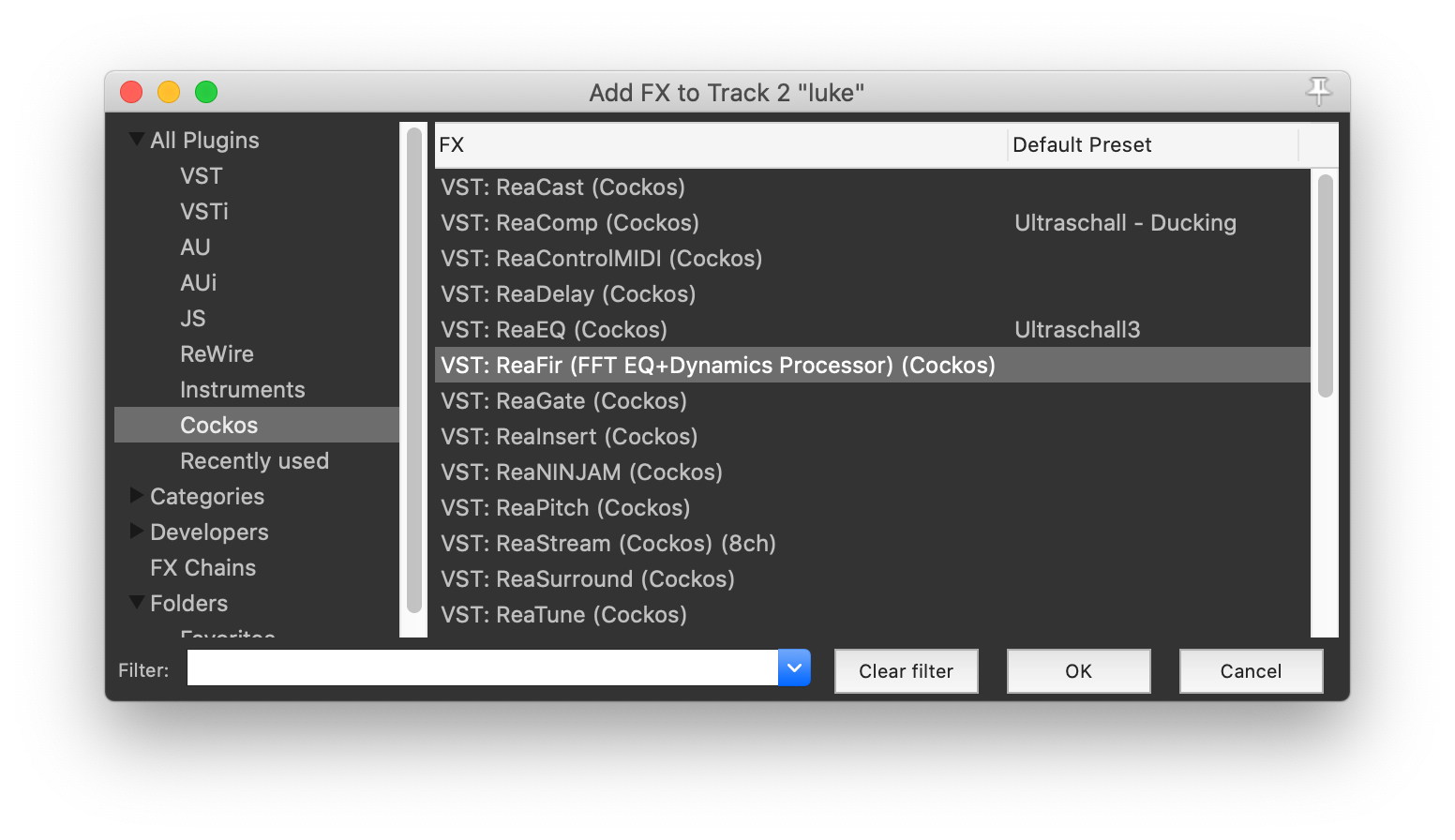
点击OK,你就会在上面图2中看到 ReaFir,一般会出现在已有插件的下方,需要用鼠标拖动到最上面去,排在其他的效果器前面。至于为什么要挂在最前面,K酱解释的很好:
任何降噪插件,都建议挂在干声轨的第一个位置,ReaFir 也不例外。
为什么呢?比如你在降噪插件之前挂了个EQ,你采样过的噪声特征是经过EQ处理了的,后来你又重新调了一下EQ,然后新的噪声特征就跟采样到的特征不一样了,降噪效果就下降了。再比如你在降噪之前挂了个压缩,底噪部分电平比较低,达不到压缩器的 threshold,采样到的噪声特征是未经压缩处理的,人声的部分被压缩了,噪声的电平也变小了,这样再用采样到的特征去降噪,可能会降噪太多导致失真。总之,请把 ReaFir 放在效果链的第一位。另外,如果你在采样完之后,需要调整干声的音量大小(拖动干声对象上边缘,不是音轨上的推子),那么你需要在调整完之后重新采样。
然后双击 ReaFir,可以打开主界面。降噪这个功能需要设置 Mode 为 Substract,其他参数按照下图调整,经验上是效果比较好的。
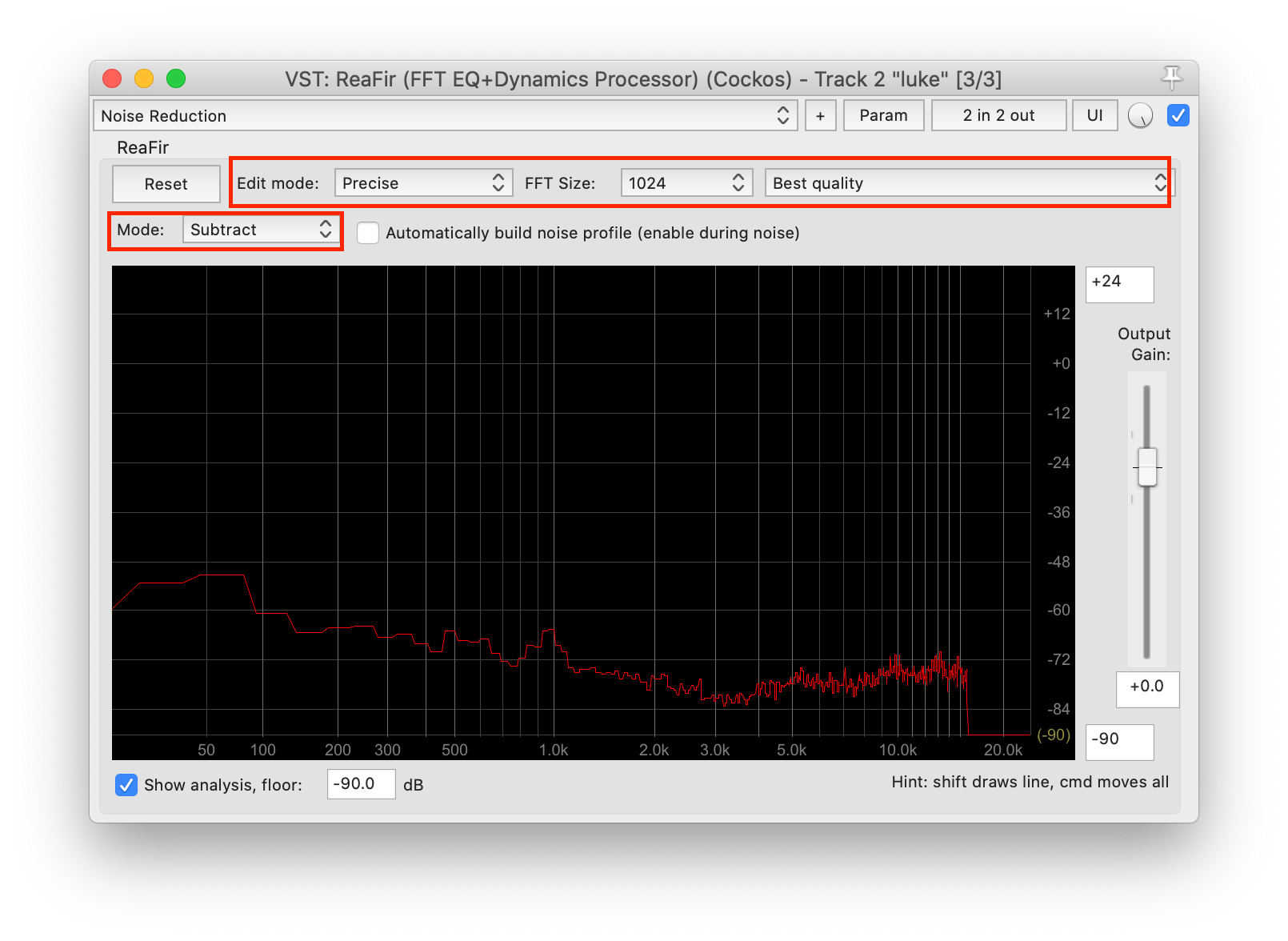
接下来就是采样的步骤。首先在上图选中 Automatically build nosie profile,再选中一段嘉宾没有说话的部分,因为我们要对噪音采样。我们是每个人录制一段音轨,后期合成的播客制作方式,所以找一段没有说话的部分是非常简单的。最后点击循环和播放(下图最上的按钮),其实只播放一遍的话也足够啦。
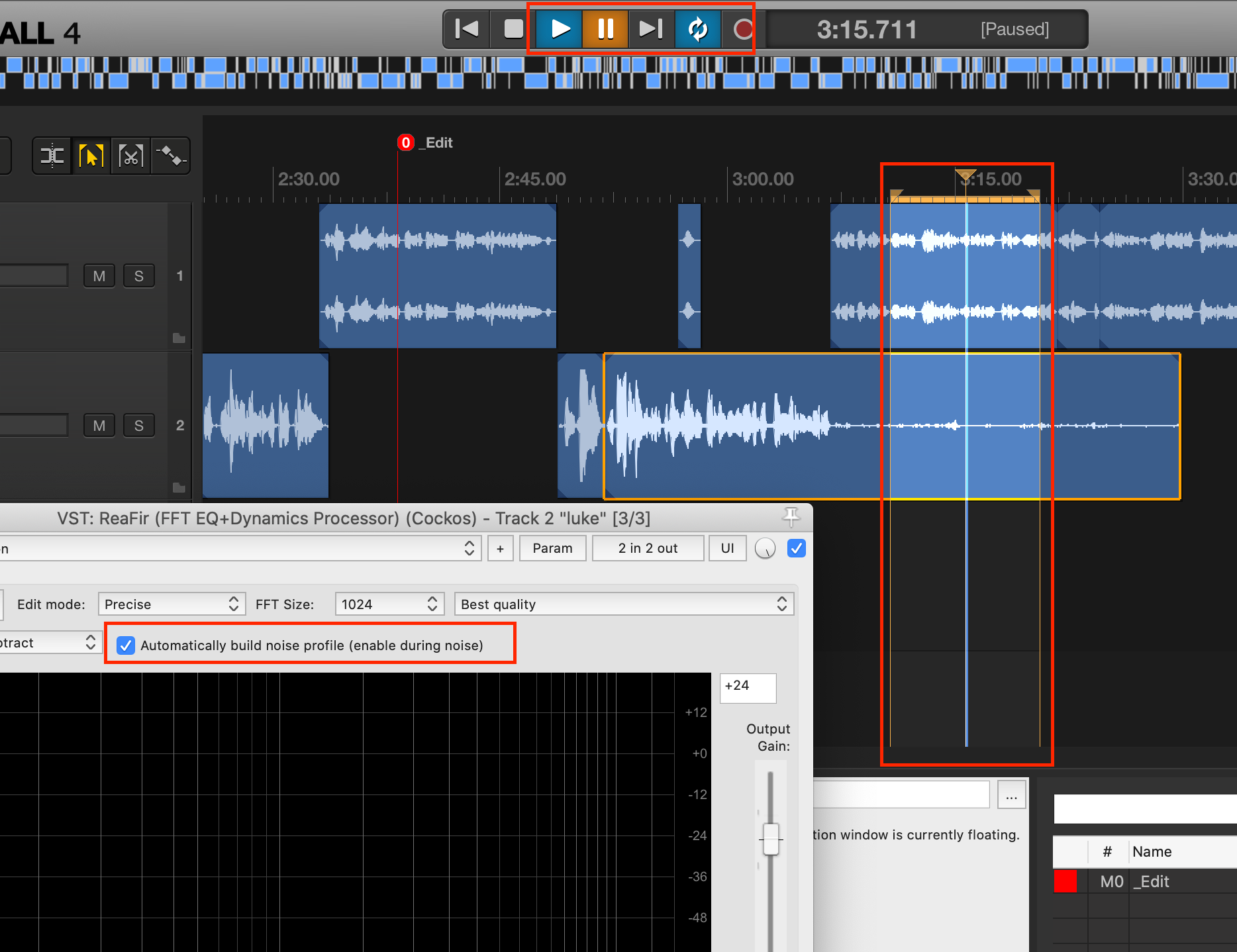
播放之后,你就会看见这里的红色曲线会变化,最终稳定。这就是对噪音的采样啦。
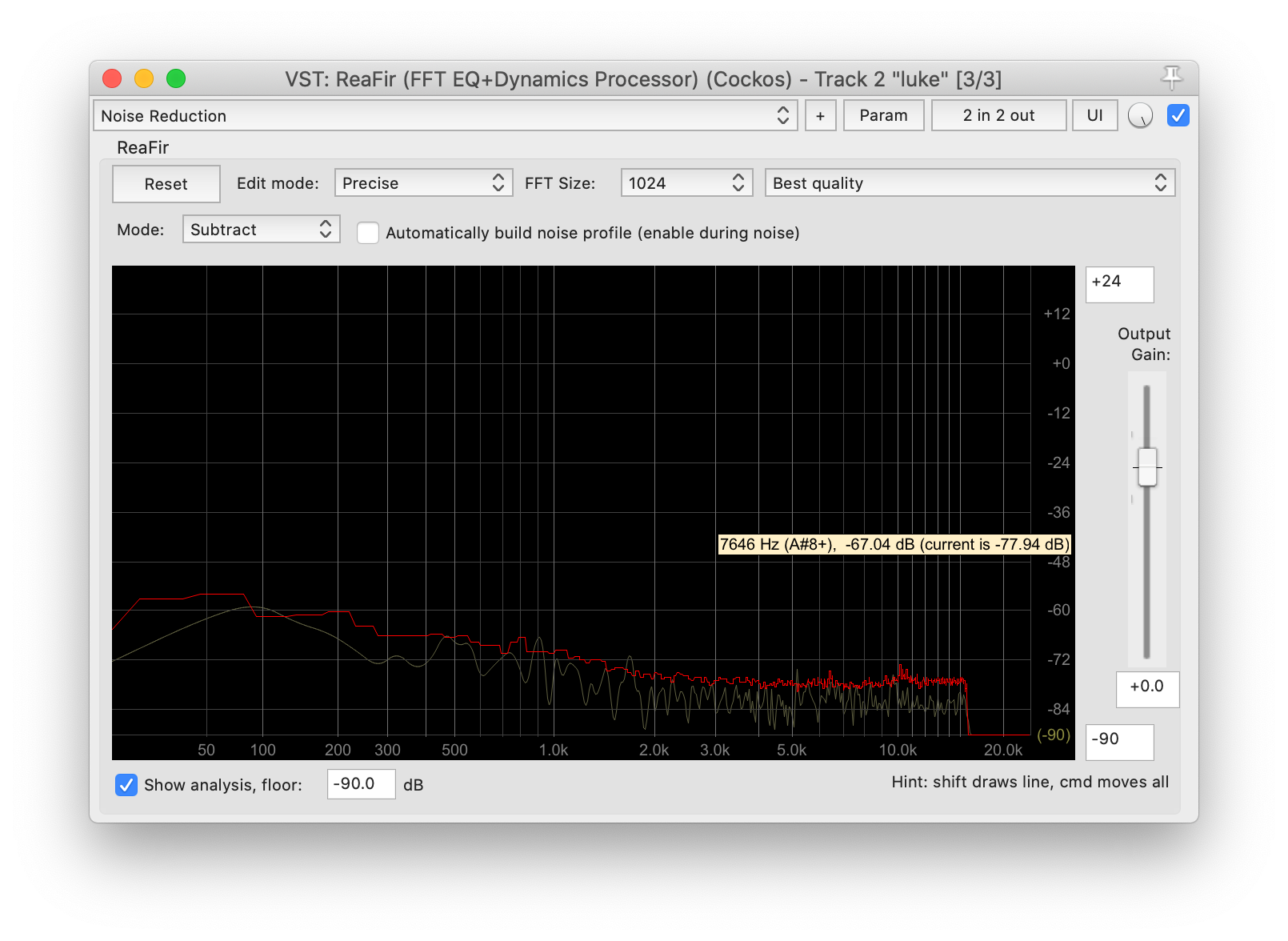
最后一步,就是生成反向声波进行降噪。其实就是将嘉宾的声轨减去这段噪音的 profile。做法其实很简单,就是取消 Automatically build nosie profile 就可以啦。Done!选取一段嘉宾说话的声音,对比一下和之前的区别吧,底噪应该好很多了的。
底噪降的太强,会减去人声,造成音质损失;底噪降的太弱,会降噪不够。所以在上图中,降噪的强度是可以调节的。在这个界面中,按住 Command 键(Windows系统是 Ctrl 键),用鼠标拖动红色线可以调节降噪的强度。可以循环播放一段嘉宾说话的音频,一边播放一边调整,找一个合适的位置。
如果还看不懂的话可以看下这个视频教程:https://www.youtube.com/watch?v=31phzT7pxkk 我就是看这个视频学会的。
广告时间~
这里的(傻瓜)降噪教程就结束啦,如果有问题可以留言问我。我和 Luke 录制的这一期应该就会在最近发布啦,我们聊的是 CI,flake8,lint 等话题。大家在我们的网站关注我们 http://pythonhunter.org/ ,可以通过泛用型客户端订阅我们的播客。
如果喜欢我们的节目,可以给我们捐赠一些钱,我们会用来购买话筒,邮寄给嘉宾,嘉宾用完之后给嘉宾报销邮费收回话筒,购买剪辑软件,制作周边回馈听众等用途,我们会尽最大努力保证节目的质量和音频质量~
捐赠在爱发电:https://afdian.net/@pythonhunter 支付宝和微信可以直接扫码付款。