来新加坡四年整了,记录一下。
数据中心网络高可用技术:ECMP
在之前的文章中,已经介绍过很多次 ECMP1 了,它的原理非常简单:在路由协议中,如果下一跳有多个路径可以选择,并且多个路径的 cost metric 相等,那么路由器就会根据包的 header,计算一个 hash 值,然后根据这个 hash 值对这个 flow 选择一条固定的路径,作为下一跳。
这里的要点是:
- 路径的 cost metric 要相等。需要注意,Administrative Distance 决定协议的优先级,而 ECMP 只适用于同一协议内部的路径选择,例如 OSPF 使用 Cost 值,BGP 使用 AS-Path 长度;
- 如我们前面讨论过的 bonding 技术2,ECMP 选路的时候,也是基于 hash 的,这样可以对一个 flow 尽量保证包到达的顺序一致;
- ECMP 只影响在某一跳选择下一跳,不影响全局。即,它在每一跳之间做均衡,而不是全局做均衡。
我们拿实际的问题来分析。
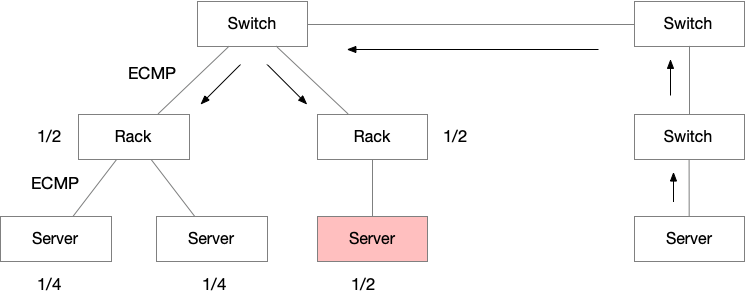
如果如图所示部署,一共有三台服务器,部署在两个 rack,这样会造成右边的服务器承担的流量是其他服务器的两倍,流量是不均衡的。因为第一层 ECMP 是发生在两个 Rack 之间,每一个 Rack 的交换机都是拿到 1/2 的流量。然后再进行服务器和 Rack Switch 之间的 ECMP,服务器之间均分 Rack 分得的流量。
所以 ECMP 对部署结构是有要求的,要保证每一个 Rack 的服务器数量大致相当。
ECMP 环境排错要点:理解 flow hash
因为环境中有多条 path,所以在排查问题的时候,要考虑到这一点。
多条 path 之间是通过 flow 的 hash 结果来选路的。ICMP 包主要通过 Src IP, Dst IP, Type, Code, Identifier 来确定一个 flow,如果使用 mtr3,那么一次 mtr 的链路是固定的,因为 mtr 使用固定的 Identifier 来发送 ICMP,在 ECMP 链路中,总会 hash 到一条特定的路线。有的时候,网络存在问题,但是 ping 和 mtr 可能显示没有问题,原因就是恰好 ICMP 被 hash 到了好的线路上去。
如果使用 mtr --tcp --port 80,就可以看到链路中所有的线路。因为 mtr 使用 tcp 的时候,每次使用的 src port 是不固定的,这样就导致每次发出来的 TCP 包都 hash 到不同的线路上。
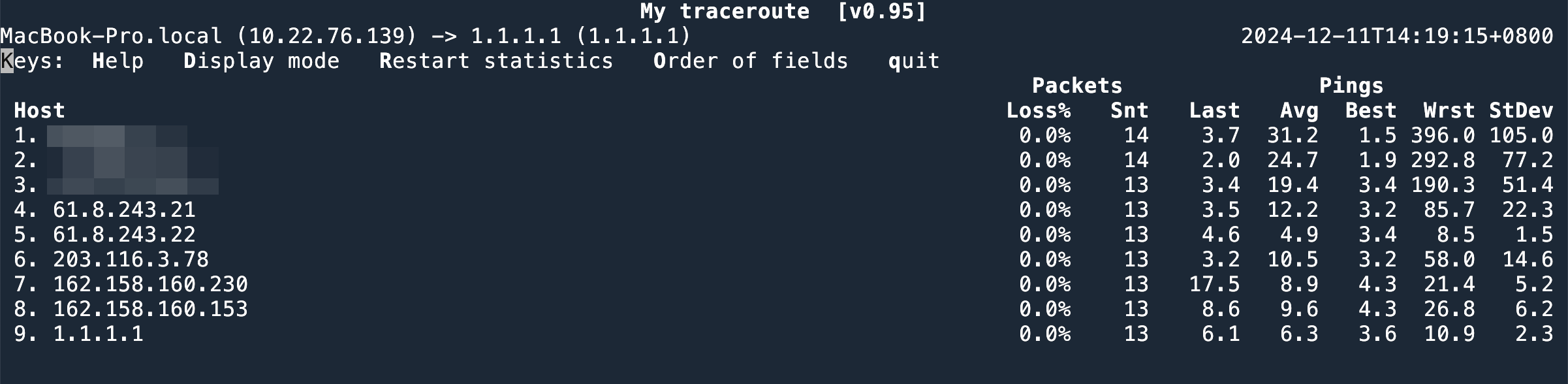
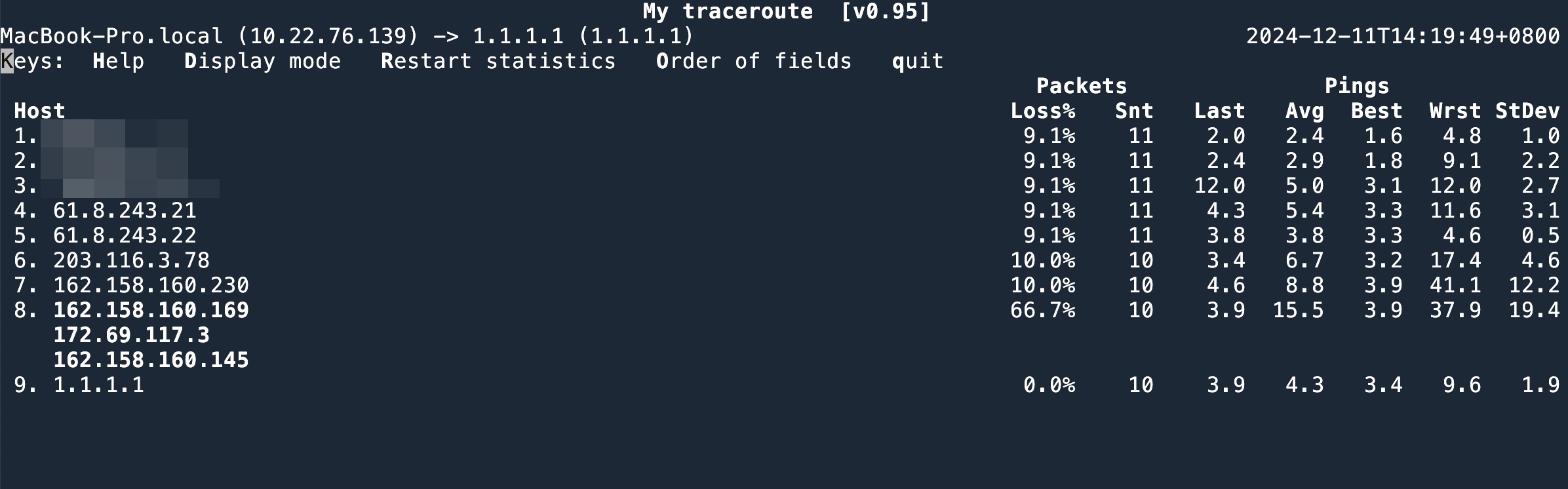
--tcp,会显示出来(第8跳)所有的路线假设就是想测试和客户端一样的固定线路,可以使用 tcptraceroute4,这个工具可以指定 src port,这样 TCP 四元组就固定了。在 ECMP 环境中就会走一样的路线。
另外一点排错经验,如果是 25% 丢包,50% 丢包,通常和某条线路丢包有关。
连接池问题
我们常用的很多 SDK,比如 redis,和 db 的 SDK,都会老道的创建一个连接池来复用连接,减少 tcp 创建的 overhead。还有一个细节,就是这些 SDK 一般会给连接加上最大存活时间,如果超过之后,就会关闭这个连接并删除。
这样做是有好处的,我们自己写的代码中访问 HTTP 服务也会用连接池,但是很少会注意要重建连接。就导致一个连接建立起来,会存在数天。有一些交换机有 Sticky ECMP 的功能,假设多路网络中有一个设备下线,流量就会分散到剩余的设备中。当这个设备回来的时候, Sticky ECMP 会保证这期间创建的连接都依然走一样的路线(不会考虑重新加入的设备)。
这样就会造成连接的带宽使用不均衡。如果连接一直不关闭,就会一直不均衡。在总带宽利用远小于 100% 的时候,就会出现丢包的情况。
所以我们在写代码的时候,也要注意定时重建连接。
- 四层负载均衡漫谈 ↩︎
- 数据中心网络高可用技术之从服务器到交换机:802.3 ad ↩︎
- 使用 mtr 检查网络问题,以及注意事项 ↩︎
- https://linux.die.net/man/1/tcptraceroute ↩︎
数据中心网络高可用技术系列
iptables 拦截 bridge 包的问题排查
最近排查的一个网络问题,两个 IP 之间的网络不通,经过在 Linux 上一个一个 interface 上抓包,发现包丢在了本地的 bridge 上。
Bridge 就是一个简单的二层设备,虽然是虚拟的,但是应该逻辑也很简单,怎么会丢包呢?
经过一通乱查,发现 Bridge 的包跑到了 iptables 里面去,被 iptables 的 FORWARD chain DROP 了。

说到这里跑个题,我有一个排查 iptables 是哪一条 rule 丢包的妙计,就是 watch -d "iptables -nvL | grep DROP,watch 会监控引号中的脚本,脚本会过滤出来所有会丢包的 rule,-d 参数很关键,它可以让 watch 每次对比和上一次命令的不通,然后高亮出来。一眼定位到问题。
话说回来,bridge 一个二层的设备怎么会跑到 iptables 里面去?iptables 可是 IP tables,这是三层呀。
在 Linux 中有一个机制,可以让 layer 2 的 bridge 代码调用 iptables, arptables, ip6tables 等。这样能做的事情就比 BROUTING chain (Bridge Routing1) 更多。可以在 bridge 上通过 iptables 做 dnat, stateful firewall, conntrack 等2。
如果不需要 bridge 上的包跑到 iptables 上过一遍,可以通过 kernel 参数关闭:
sysctl -w net.bridge.bridge-nf-call-iptables=0
0 的意思是 bridge 的包不会去 iptables,1 就是会去 iptables,默认是 1. 也是执行完这行命令,网络果然就通了。
Bridge call iptables, 之前是在 kernel 实现的一个功能,但是显然这样会有性能问题。后来就独立出来作为一个独立的 kernel module 了 (br_netfilter3)。(如果使用 physdev 4就会自动启用这个 module)。
另外,nftables 和 iptables-nft 也会受到影响,layer violation 会有很多复杂的问题。新的 kernel module – nf_conntrack_bridge5 可以做到直接在 bridge layer 实现 connection track. nftables6 是下一代的 iptables。
前面说过这个功能是一个 kernel module,所以在关闭的时候有一个小小的问题。即我们关闭的时候,可能还没有这个 module load,所以会告诉我们无法设置这个参数:error: "net.bridge.bridge-nf-call-iptables" is an unknown key。如果后来创建一个 bridge,那么这个 module 会自动 load,那么包就又会跑到 iptables 里面去。
libvert 给出的解决方案7是,通过 udev 来创建一个事件,每次创建 bridge 就执行 sysctl 来 disable net.bridge.bridge-nf-call-iptables.
- ebtables https://linux.die.net/man/8/ebtables ↩︎
- ebtables/iptables interaction on a Linux-based bridge:https://ebtables.netfilter.org/br_fw_ia/br_fw_ia.html ↩︎
- https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/commit/?h=linux-3.18.y&id=34666d467cbf1e2e3c7bb15a63eccfb582cdd71f ↩︎
physdev: https://manpages.debian.org/bookworm/iptables/iptables-extensions.8.en.html#physdev ↩︎- nf_conntrack_bridge: https://www.kernelconfig.io/config_nf_conntrack_bridge ↩︎
- nftables wiki: https://wiki.nftables.org/wiki-nftables/index.php/Main_Page ↩︎
- https://wiki.libvirt.org/Net.bridge.bridge-nf-call_and_sysctl.conf.html ↩︎
Docker 命令行小技巧:runlike
事情要从上周的一次事故说起,我们用 docker 部署的程序有一点问题,要马上回滚到上一个版本。
这个 docker 是一个比较复杂的和 BPF 有关的程序,启动时候需要设置很多 mount 和 environments,docker run 的命令特别长。所以我用 Ansible 来配置好这些变量,然后启动 docker,一个实例要花费 3~5 分钟才能启动。
同事突然说,某实例他手动启动了,当时我就震惊了,怎么手速这么快?!
请教了一下,原来是用的 runlike 工具,项目地址是:https://github.com/lavie/runlike。
这个工具的原理是,docker inspect <container-name> | runlike --stdin ,就会生成这个容器的 docker run 命令。这个思路简直太棒了。就和 Chrome 的 copy as cURL 功能一样好用!
ARP Flux 问题和解决方法
我们写程序不需要写 ARP request 和 response 相关的逻辑,因为这部分是操作系统帮我们做的。
Linux 处理 ARP 请求的逻辑是:
如果操作系统收到了一个 ARP reuqest,并且本机中某一个接口配置了 ARP request 中请求的 IP,那就回复这个 ARP request,回复的 ARP response 中,使用收到此 ARP request 的 interface 的 MAC 地址作为答案。
这个逻辑看起来没有问题:从 Linux 的视角,既然我能从一个 interface 收到 ARP 请求,那么对方向这个 interface 发送数据包,我也可以从这个 interface 收到,所以,回复 interface 的 MAC 地址即可。
但是,在下面这种情况就会出问题:
- Linux 有两个 interface 接入到了同一个交换机上;
- 这两个 interface 配置的 IP 地址在同一个广播域;
满足这两个条件的话,当有 LAN 中有主机发送 ARP request 广播包,交换机会转发到自己的所有端口,Linux 会从这两个端口都收到此 ARP request 广播包。按照以上处理逻辑,Linux 会回复 2 个 ARP reply,因为收到了两个 request,两个 interface 各回复一次,并且这两个 ARP reply 分别是两个 interface 的 MAC 地址。
实验环境如下图所示:
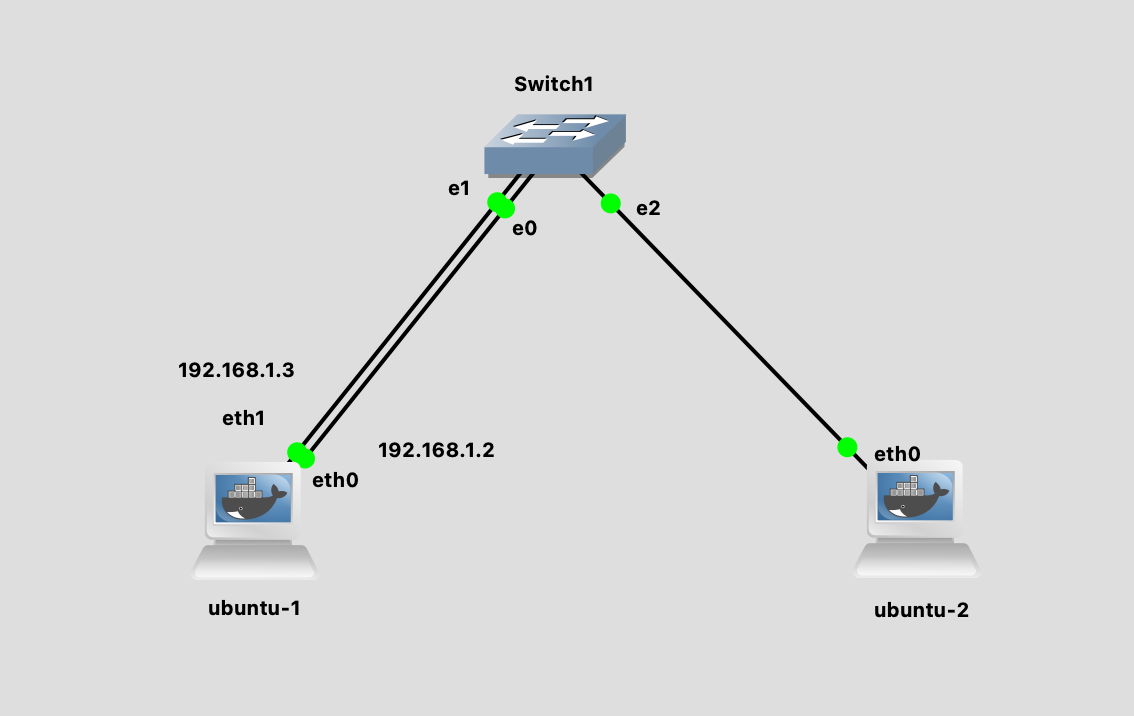
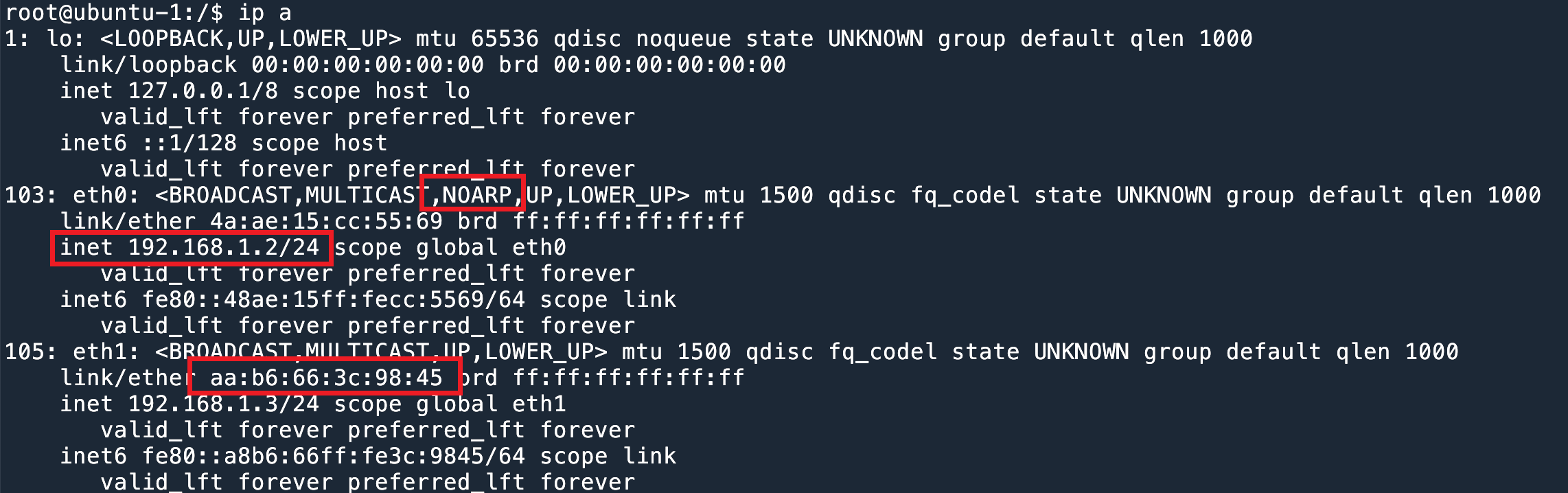
配置好 IP 之后,我们在 ubuntu-2 主机发送 ARP request。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
root@ubuntu-2:/$ arping 192.168.1.2 -c 3 ARPING 192.168.1.2 42 bytes from aa:b6:66:3c:98:45 (192.168.1.2): index=0 time=1.017 msec 42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=1 time=1.032 msec 42 bytes from aa:b6:66:3c:98:45 (192.168.1.2): index=2 time=300.636 usec 42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=3 time=557.981 usec 42 bytes from aa:b6:66:3c:98:45 (192.168.1.2): index=4 time=308.836 usec 42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=5 time=546.011 usec --- 192.168.1.2 statistics --- 3 packets transmitted, 6 packets received, 0% unanswered (3 extra) rtt min/avg/max/std-dev = 0.301/0.627/1.032/0.299 ms |
一共发送了 3 个 request,却收到了 6 个 ARP reply。并且有两种 MAC 地址。
这个就是 ARP Flux 问题。
解决方法0: 配置不同的 IP subnet
因为 ARP 是在 LAN 内的,如果两个 interface 分别配置在不同的 subnet,就不会有这个问题了。
但是有时候我们的软件守交换机网段的限制,只能配置在一个网段。并且有些场景需要两个线路和两个 IP,比如管理和数据面分开(带外管理),就又会遇到这个问题。
解决方法1: 隐藏其中一个接口
使用 ip link set dev eth0 arp off 可以禁用 interface 的 ARP 恢复,这样,在 LAN 上就相当于把这个 interface 隐藏了,因为没有人可以发现它的 MAC 地址了。在四层负载均衡中,如果使用 DSR 的模式并且不加隧道的话,就需要对 RS 的 VIP 禁用 ARP 回复1。
这里有一个有意思的现象:假设 192.168.1.2 配置在 eth0 上,但是我们把 eth0 的 ARP 禁用了。
192.168.1.2 所在的 eth0 ARP禁用这时候如果请求 192.168.1.2 的地址,会拿到 eth1 的 MAC 地址。参考上文讨论过的 Linux ARP 工作原理。
|
1 2 3 4 5 6 7 8 9 |
root@ubuntu-2:/$ arping 192.168.1.2 -c 3 ARPING 192.168.1.2 42 bytes from aa:b6:66:3c:98:45 (192.168.1.2): index=0 time=313.417 usec 42 bytes from aa:b6:66:3c:98:45 (192.168.1.2): index=1 time=240.823 usec 42 bytes from aa:b6:66:3c:98:45 (192.168.1.2): index=2 time=294.223 usec --- 192.168.1.2 statistics --- 3 packets transmitted, 3 packets received, 0% unanswered (0 extra) rtt min/avg/max/std-dev = 0.241/0.283/0.313/0.031 ms |
这个方法只能通过 interface 级别来设置,如果一个 interface 上有多个 IP 地址,那么只能全部禁用或者开启。
如果要 by IP 来禁用 ARP,可以使用 arptables(8)2 3.
解决方法 2: arp_ignore
直接禁用 ARP 差不多等于把这个 interface 关闭了,大部分情况下不是我们想要的结果。
我们希望的效果是对于 ARP request 只回复一次,并且只有 IP 在自己的 interface 上才回复,不要代替其他 interface 回复。
通过 arp_ignore4 可以改变 Linux 的 ARP 行为:
0– 默认,只要本地有的 IP 就会回复,无论是哪一个 interface;1– 只有当 ARP request 询问的 IP 配置在收到 ARP 的接口上时,才会回复;- 2 – 同
1,并且 sender 的 IP 在本地 IP 的相同 subnet 内,才会回复; 3–scope host不会回复,只有scope link和scope global才会回复 (可以通过ip address命令查看配置的 IP scope);4–7– 保留字段;8– 所有 local address 都不回复;
配置方法:通过 sysctl -w 可以修改配置。arp_ignore 是 per interface 的配置。
|
1 2 3 4 5 6 7 8 |
root@ubuntu-1:/$ sysctl -a | grep arp_ignore net.ipv4.conf.all.arp_ignore = 0 net.ipv4.conf.default.arp_ignore = 0 net.ipv4.conf.eth0.arp_ignore = 0 net.ipv4.conf.eth1.arp_ignore = 0 net.ipv4.conf.eth2.arp_ignore = 0 net.ipv4.conf.eth3.arp_ignore = 0 net.ipv4.conf.lo.arp_ignore = 0 |
其中 all 是一个全局变量,最终在 interface 上生效的值是 max(all, eth0)。以最大的为准。
default 是模板变量,在新建一个 interface 的时候,会自动使用这个值。
我们可以给所有的 interface 都设置为 1.
|
1 2 |
root@ubuntu-1:/$ sysctl -w net.ipv4.conf.all.arp_ignore=1 net.ipv4.conf.all.arp_ignore = 1 |
然后再发送 arp 请求,就会发现回复之后一个了,并且是正确的那个。
|
1 2 3 4 5 6 7 8 9 |
root@ubuntu-2:/$ arping 192.168.1.2 -c 3 ARPING 192.168.1.2 42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=0 time=602.926 usec 42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=1 time=312.438 usec 42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=2 time=236.994 usec --- 192.168.1.2 statistics --- 3 packets transmitted, 3 packets received, 0% unanswered (0 extra) rtt min/avg/max/std-dev = 0.237/0.384/0.603/0.158 ms |
解决方法3: arp_filter
另一个方法是使用 arp_filter 参数,这个参数是一个 bool,默认是 0 ,如果开启为 1,就意味着,如果收到 ARP request,ARP 请求的 IP 为 A,收到 ARP 的 interface 为 X 和 Y,那么 kernel 就测试路由,假设要发出去 source IP 为 A 的包,从 X 发出去还是从 Y 发出去。如果从 X 发出去,那么只有 X 会回复。(source based rotuing).
举例来说,我们现在有两个接口和两个 IP,回复 192.168.1.10 的 ARP 时,可以测试当前的路由情况:
|
1 2 3 4 5 6 |
root@ubuntu-1:/$ ip route get 192.168.1.10 from 192.168.1.2 192.168.1.10 from 192.168.1.2 dev eth0 uid 0 cache root@ubuntu-1:/$ ip route get 192.168.1.10 from 192.168.1.3 192.168.1.10 from 192.168.1.3 dev eth0 uid 0 cache |
可以看到无论 source IP 是哪一个,都会从 eth0 口出。
这是因为我们的 ip route 配置:
|
1 2 3 |
root@ubuntu-1:/$ ip route show table all 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.2 192.168.1.0/24 dev eth1 proto kernel scope link src 192.168.1.3 |
会永远走第一条路由。
所以我们如果发送 ARP request,对 .2 和 .3 两个地址,得到的结果会是一样的,因为都是 eth0 在回复。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
root@ubuntu-2:/$ arping 192.168.1.2 -c 3 ARPING 192.168.1.2 42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=0 time=165.606 usec 42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=1 time=161.927 usec 42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=2 time=179.383 usec --- 192.168.1.2 statistics --- 3 packets transmitted, 3 packets received, 0% unanswered (0 extra) rtt min/avg/max/std-dev = 0.162/0.169/0.179/0.008 ms root@ubuntu-2:/$ arping 192.168.1.3 -c 3 ARPING 192.168.1.3 42 bytes from 4a:ae:15:cc:55:69 (192.168.1.3): index=0 time=230.590 usec 42 bytes from 4a:ae:15:cc:55:69 (192.168.1.3): index=1 time=182.955 usec 42 bytes from 4a:ae:15:cc:55:69 (192.168.1.3): index=2 time=149.800 usec --- 192.168.1.3 statistics --- 3 packets transmitted, 3 packets received, 0% unanswered (0 extra) rtt min/avg/max/std-dev = 0.150/0.188/0.231/0.033 ms |
如果我们把第一条路由删了,那么现在就都走 eth1 了,这时候 ARP 结果就都是 eth1 了。
|
1 2 3 4 5 6 7 |
root@ubuntu-1:/$ ip route del 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.2 root@ubuntu-1:/$ ip route get 192.168.1.10 from 192.168.1.3 192.168.1.10 from 192.168.1.3 dev eth1 uid 0 cache root@ubuntu-1:/$ ip route get 192.168.1.10 from 192.168.1.2 192.168.1.10 from 192.168.1.2 dev eth1 uid 0 cache |
Lookback 接口是否会回复 ARP?
答案是是的(虽然听起来很没道理)。这个主要是跟路由有关。
当我们在给 lo 绑定一个地址的时候,kernel 会默认添加 2 条路由,lo 所在网段和 lo 的地址会被标记成 dev lo 的本地路由。
|
1 2 3 4 5 6 7 |
root@ubuntu-1:/$ ip route show table local local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1 local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1 broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1 local 192.168.1.0/24 dev lo proto kernel scope host src 192.168.1.2 local 192.168.1.2 dev lo proto kernel scope host src 192.168.1.2 broadcast 192.168.1.255 dev lo proto kernel scope link src 192.168.1.2 |
其实,当我们给 lo 地址添加 192.168.1.2/24 的时候,由于自动添加的 192.168.1.0/24 的 route (第5行),导致我们其他的接口也不会回复这个网段的 ARP 请求了。这个时候从 ubuntu-2 上 arping 192.168.1.10 和 192.168.1.11 都会 timeout。
这个是默认的行为。但是如果我们改一下,删除这两条路由,添加另一条从 eth0 口出的路由的话,就会发现,arping lo 接口的 IP,也会收到 ARP response 了。
|
1 2 3 |
root@ubuntu-1:/$ ip route del local 192.168.1.0/24 dev lo proto kernel scope host src 192.168.1.2 root@ubuntu-1:/$ route del local 192.168.1.2 dev lo table local proto kernel scope host src 192.168.1.2 root@ubuntu-1:/$ ip route add local 192.168.1.2 dev eth0 proto kernel scope host src 192.168.1.2 |
|
1 2 3 4 5 6 7 8 9 |
root@ubuntu-1:/$ ip address show dev lo 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet 192.168.1.2/24 scope global lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever |
在 ubuntu-2 可以 ping 通。
|
1 2 3 4 5 6 7 8 9 |
root@ubuntu-2:/$ arping 192.168.1.2 -c 3 ARPING 192.168.1.2 42 bytes from 56:6b:38:20:7e:56 (192.168.1.2): index=0 time=274.702 usec 42 bytes from 56:6b:38:20:7e:56 (192.168.1.2): index=1 time=299.748 usec 42 bytes from 56:6b:38:20:7e:56 (192.168.1.2): index=2 time=296.380 usec --- 192.168.1.2 statistics --- 3 packets transmitted, 3 packets received, 0% unanswered (0 extra) rtt min/avg/max/std-dev = 0.275/0.290/0.300/0.011 ms |
所以说 lo 接口是否回复 ARP request,主要和 ip route 的设置有关。