上一篇笔记中降到了排序相关的索引技巧。排序经常和“取部分结果”这种用法结合。比如分页,我们只需要取 1 页数据来展示,如果需要读完所有的 row 然后取出来前 20 条作为 1 页展示的话,未免也太浪费资源了。在排好序的情况下,显然我们可以只读 20 rows 就直接返回,而不必读完整张表的数据。索引可以帮我们做到这一点。
- Use the Index, Luke! 笔记1
- Use the Index, Luke! 笔记2 性能、Join操作
- Use the Index, Luke! 笔记3:避免回表
- Use the Index, Luke! 笔记4:sorting 和 grouping
- Use the Index, Luke! 笔记5:查询部分结果
- Use the Index, Luke! 笔记6:增删改的索引
Top N查询
我们需要某种 SQL 语法来告诉数据库只取前 N 条数据。SQL 对此并没有一个明确的标准。一方面是因为这并不是一个核心的 Feature,另一方面因为每个数据库对此都有了自己的实现。比如 MySQL 是 LIMIT N, pg 是 FETCH FIRST 10 ROWS ONLY, 也可以用 LIMIT.
Oracle 12c 之前,并没有 fetch first 的语法,但是我们可以用 rownum 来 work around.
|
1 2 3 4 5 6 7 |
SELECT * FROM ( SELECT * FROM sales ORDER BY sale_date DESC ) WHERE rownum <= 10 |
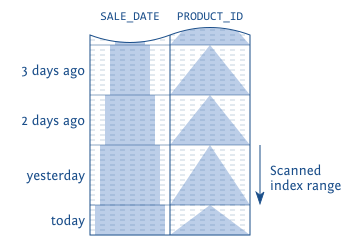
我们知道,即使在有索引的情况下,优化器仍可能选择扫全表的方案。因为在要取出的 ROW 很多的时候,索引回表查数据比直接 SCAN 全表要慢。但是如果我们告诉优化器,只需要前10条,那么优化器就知道,即使是需要从索引回表,但只需要10条数据,回表也是要比不走索引扫表快很多的。
Oracle 对上面的查询计划如下。COUNT STOPKEY 会在达到需要的数量之后停止查询,立即返回结果。
|
1 2 3 4 5 6 7 8 9 |
------------------------------------------------------------- | Operation | Name | Rows | Cost | ------------------------------------------------------------- | SELECT STATEMENT | | 10 | 9 | | COUNT STOPKEY | | | | | VIEW | | 10 | 9 | | TABLE ACCESS BY INDEX ROWID| SALES | 1004K| 9 | | INDEX FULL SCAN DESCENDING| SALES_DT_PR | 10 | 3 | ------------------------------------------------------------- |
这是在有合适的 order by 索引的情况下。假如没有 SALE_DATE 索引的话,就意义着这些记录是没有事先排好序的。即使我们取 Top 1 条记录,数据库也必须将此表全部排序,只有读完全表并排完序,才能将第一条结果返回。
Pipelined top N query 带来的不仅仅是性能的提升,还有水平扩展性。如果没有索引的话,我们每次取 Top N 都要读完全表排序,查 Top N 的速度是和表的大小成正比的,表越大,查询的速度越慢。而如果有索引的话,随着表不断增大,查询速度一直是 O(1) 的,会有很好的扩展性。
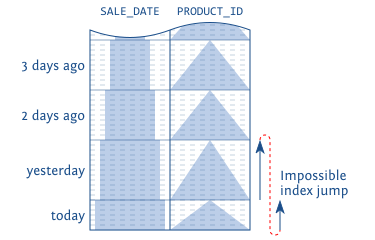
但实际上,即使有索引,查询 Top N 的效率是和要取的 N 正比的。查 Top 100 条数据比 Top 10 条要慢很多。
paging 的时候,这个问题尤为显著。比如我们要取第 5 页的数据,也要将前 5 页都读出来,然后丢弃前 4 页的数据,返回第 5 页的数据。
有一种分页的方法可以避免这种依次读 Top N 带来的性能问题;
分页技术
分页技术一般有两种。最常用的一种是需要从头读到第 N 页的数据,然后丢掉前几页的数据。
这种方法非常容易实现,甚至很多数据库都有一个专门的 keyword 来处理这种情况:offset. 在 Postgres 中,可以用下列的 SQL 取第二页的数据(每页有10条记录,跳过前10条记录)。
|
1 2 3 4 5 |
SELECT * FROM sales ORDER BY sale_date DESC OFFSET 10 FETCH NEXT 10 ROWS ONLY |
这种分页只需要 offset 就可以取回任意一页的数据,但是有两个显而易见的缺点:
- 分页会漂移。以为每次 offset 都是从头开始数的,假设从第一页跳到第二页的时候,恰好在第一页插入了一条数据,那么第一页的最后一条数据就会出现在第二页上。一个现实的例子是豆瓣,豆瓣是按照时间倒序分页的,我经常翻页到第二页的时候看到在第一页看到过的帖子;
- 第二个缺点就是性能问题。可以想象,每次都要从头开始读,那页数越大,那么要读的 Top N 就越多,效率也就越慢;
第二种分页技术可以完美地解决这两个问题:基于 seek 的分页。解释一下这个方法,这里没有第几页的概念了,而是用一个 where 条件来分页。从这个条件往后继续查 10 条记录。
举个例子,假设现在每一天只有一条销售记录,那么你可以用下面这条 SQL 查出来一页(10条)的销售记录(在 SALE_DATE 有索引的情况下):
|
1 2 3 4 5 |
SELECT * FROM sales WHERE sale_date < ? ORDER BY sale_date DESC FETCH FIRST 10 ROWS ONLY |
这里的 ? 上一页最后一条记录的时间。然后要查下一页的数据的话,继续将 ? 替换成这一页最后一条记录的时间即可。
这种方法的实现有几个要点需要注意:
- 必须要保证每次查询的结果是固定的顺序。显而易见,如果顺序不固定的话那么这个 Top N 是不可靠的。有一个陷阱是,可能你自己查了几次顺序都是固定的,但是上了生产顺序就不固定了,这是因为你看到的有序可能只是巧合,恰好是因为你本地的数据库每次用一样的 plan 来执行这个查询,到了服务器可能因为并行计算就出现乱序的情况。解决这个情况很简单,就是在排序的索引上添加固定的 column,比如 id;
- 基于此,查询下一页的时候要从上一页结束的地方开始,这也是比较 tricky 的地方。
接着上面的例子,假如不是一天只有一条销售记录了,那么我们可以创建这样的索引。
|
1 |
CREATE INDEX sl_dtid ON sales (sale_date, sale_id) |
然后使用的查询语句如下:
|
1 2 3 4 5 |
SELECT * FROM sales WHERE (sale_date, sale_id) < (?, ?) ORDER BY sale_date DESC, sale_id DESC FETCH FIRST 10 ROWS ONLY |
当然,这个方法也不是没有缺点的。虽然可以解决第一种方法两个问题,但是 seek 方法本身的问题也很大:它只能按照一页一页的顺序查找,无法直接跳到某一页。但是对于现在很多应用(比如 Twitter)采用了无限滚动的方法,是比较实用的。
Window Function 也可以用来分页
Window Function 也可以基于索引分页。下面的查询:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM ( SELECT sales.* , ROW_NUMBER() OVER (ORDER BY sale_date DESC , sale_id DESC) rn FROM sales ) tmp WHERE rn between 11 and 20 ORDER BY sale_date DESC, sale_id DESC |
这里按照排好序之后,按顺序分 ROW_NUMBER,然后限制 ROW_NUMBER 在 11 和 20 之间,同样可以使用索引。
查询计划如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
--------------------------------------------------------------- |Id | Operation | Name | Rows | Cost | --------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1004K| 36877 | |*1 | VIEW | | 1004K| 36877 | |*2 | WINDOW NOSORT STOPKEY | | 1004K| 36877 | | 3 | TABLE ACCESS BY INDEX ROWID | SALES | 1004K| 36877 | | 4 | INDEX FULL SCAN DESCENDING | SL_DTID | 1004K| 2955 | --------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("RN">=11 AND "RN"<=20) 2 - filter(ROW_NUMBER() OVER ( ORDER BY "SALE_DATE" DESC, "SALE_ID" DESC )<=20) |
但是生产中 Window Function 很少用,它真正的威力是在离线分析上。Window Function 功能很强大,值得好好读一读相关的文档。