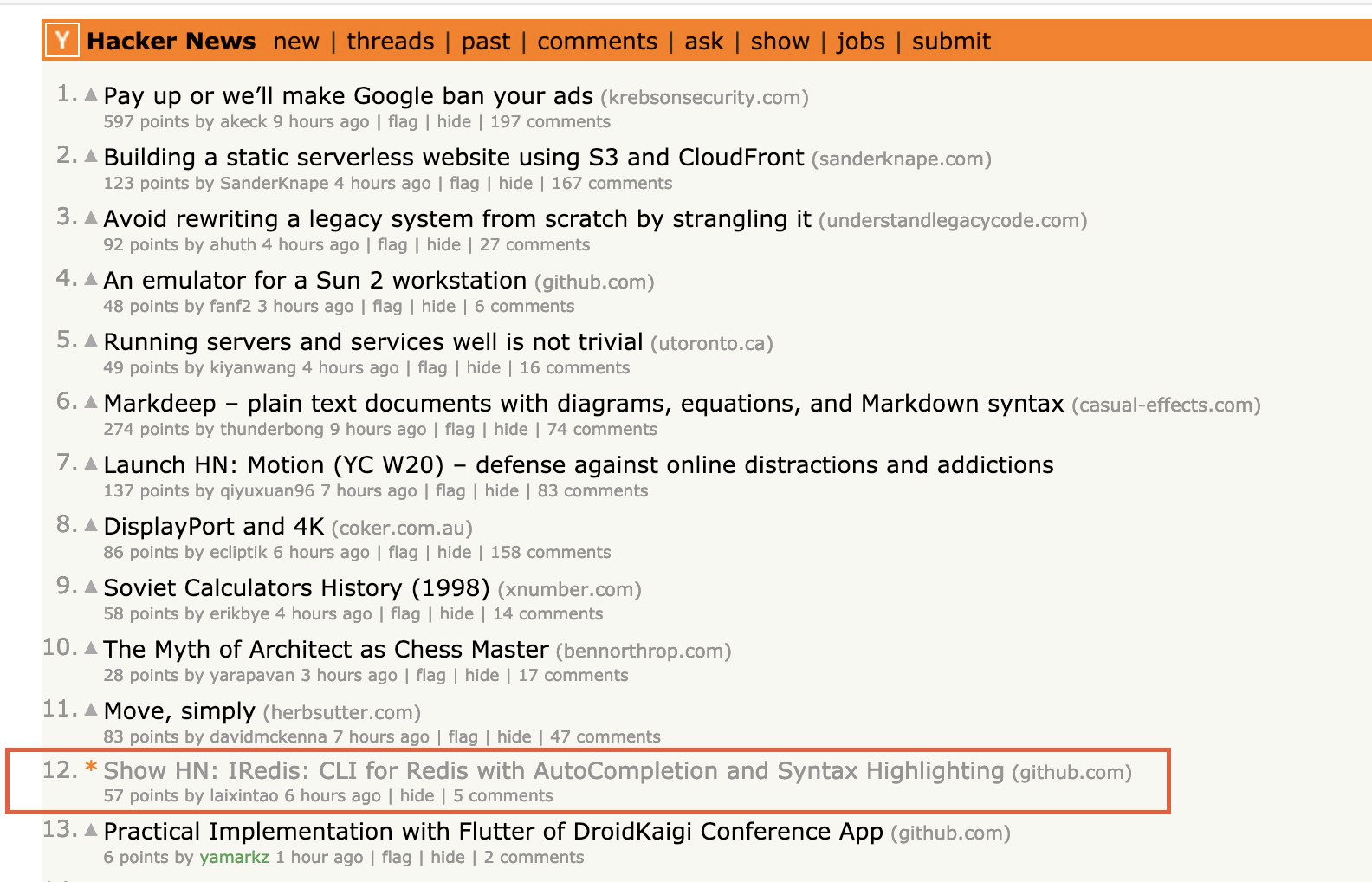
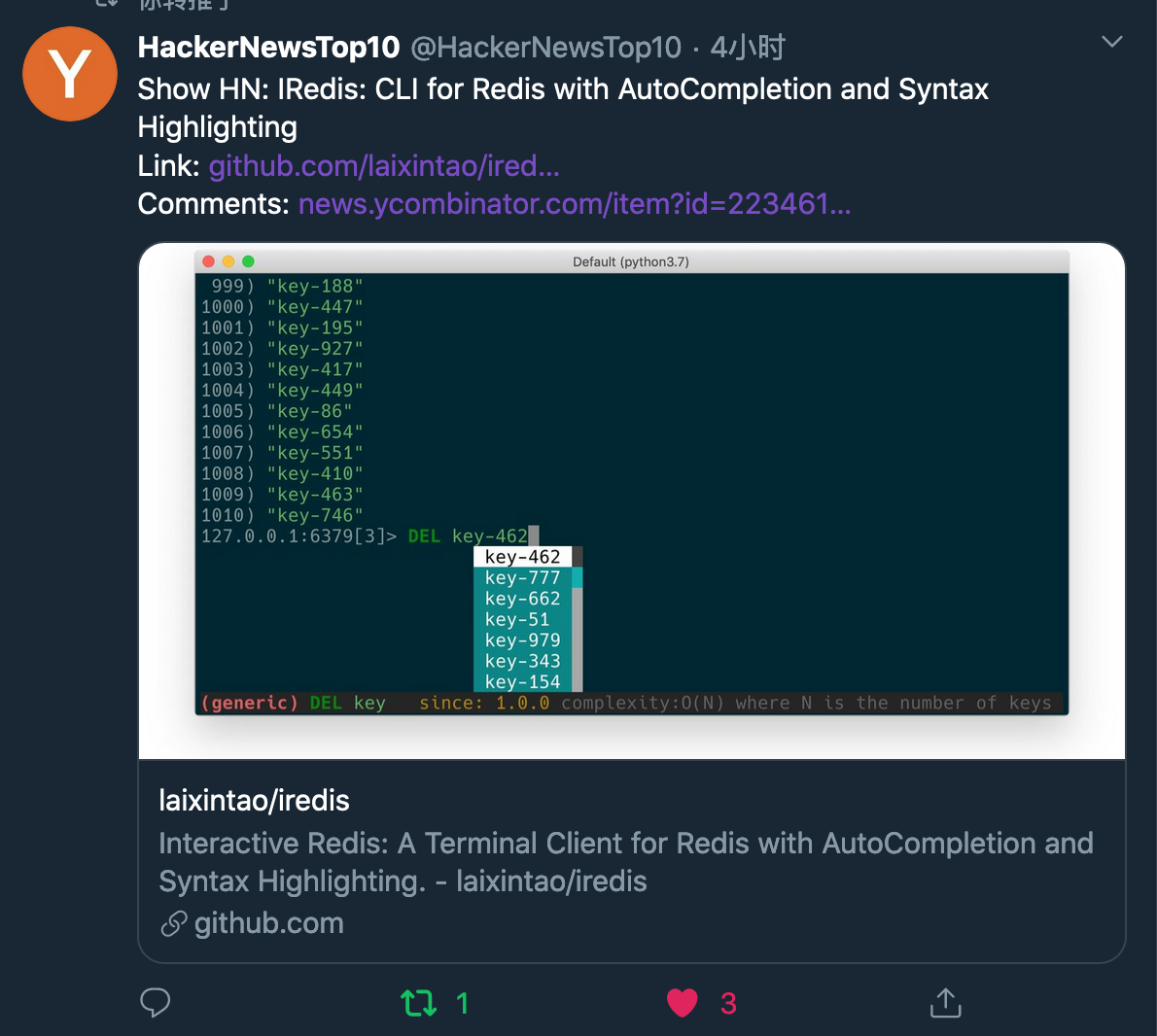
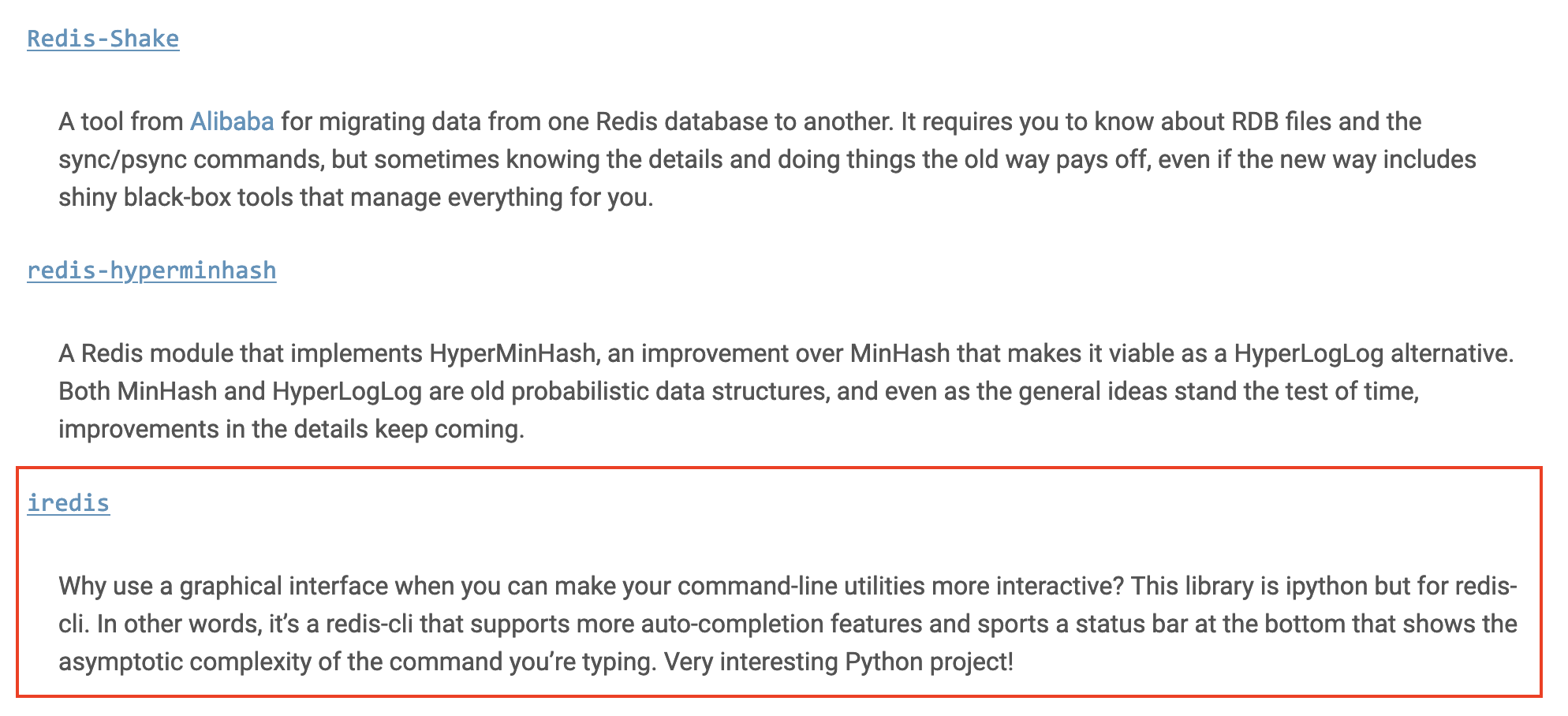
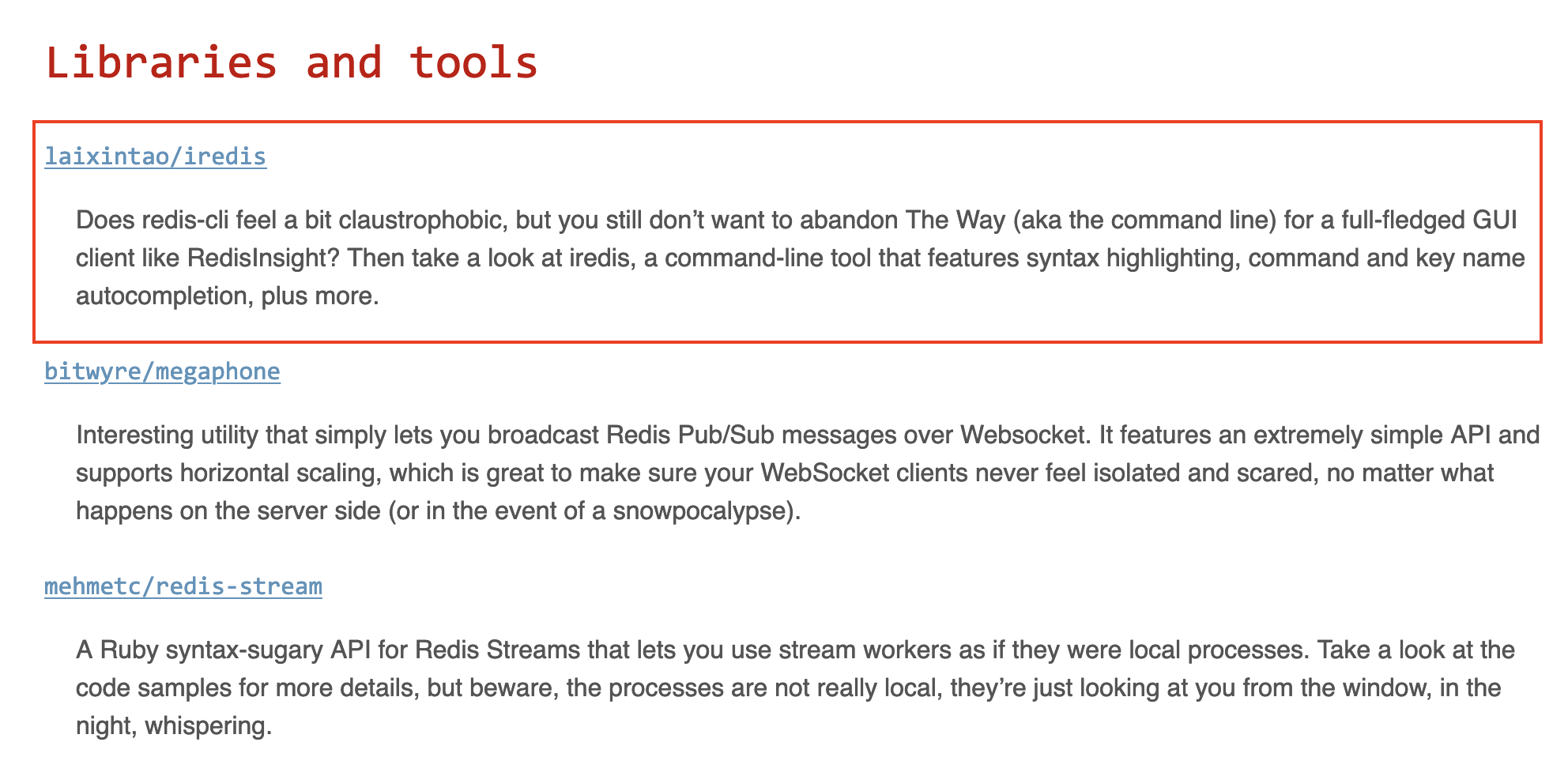
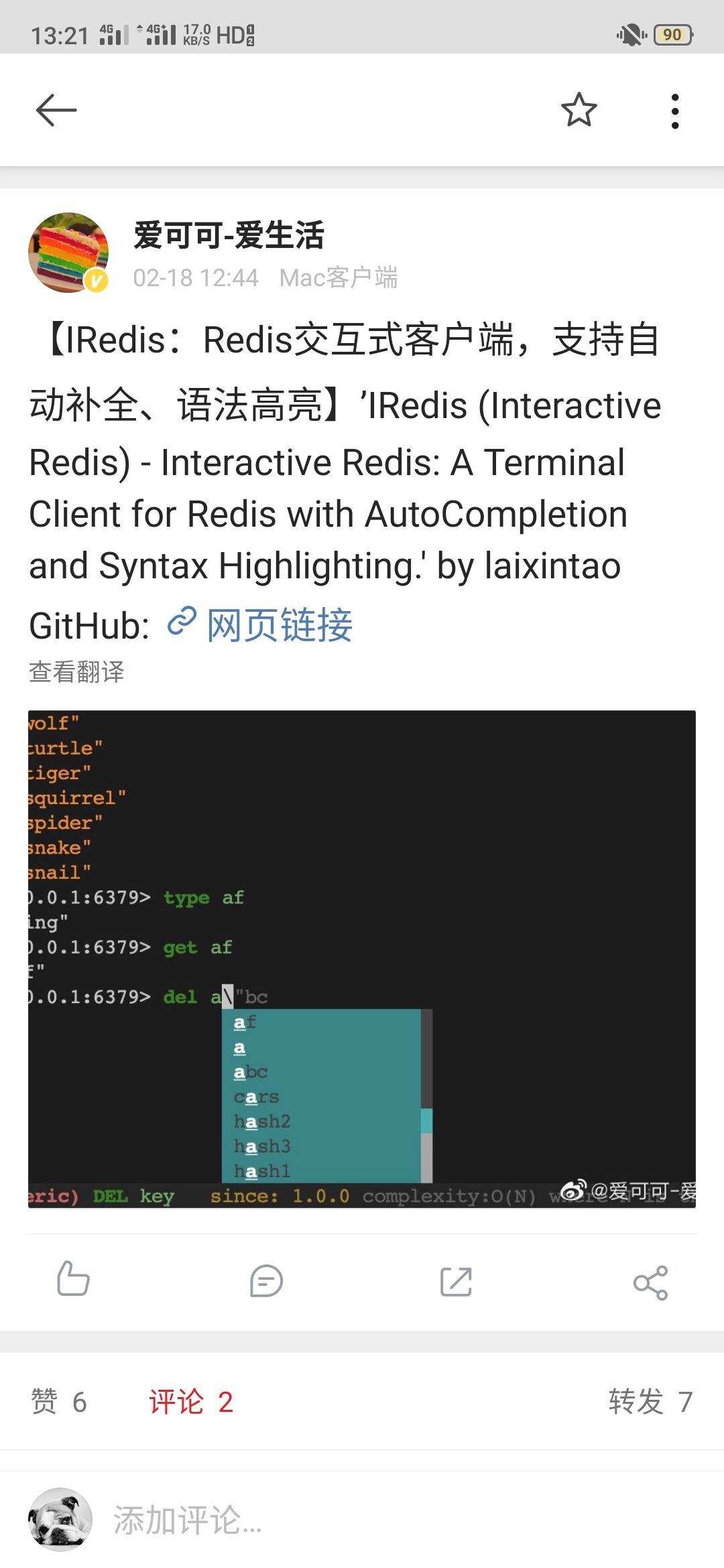
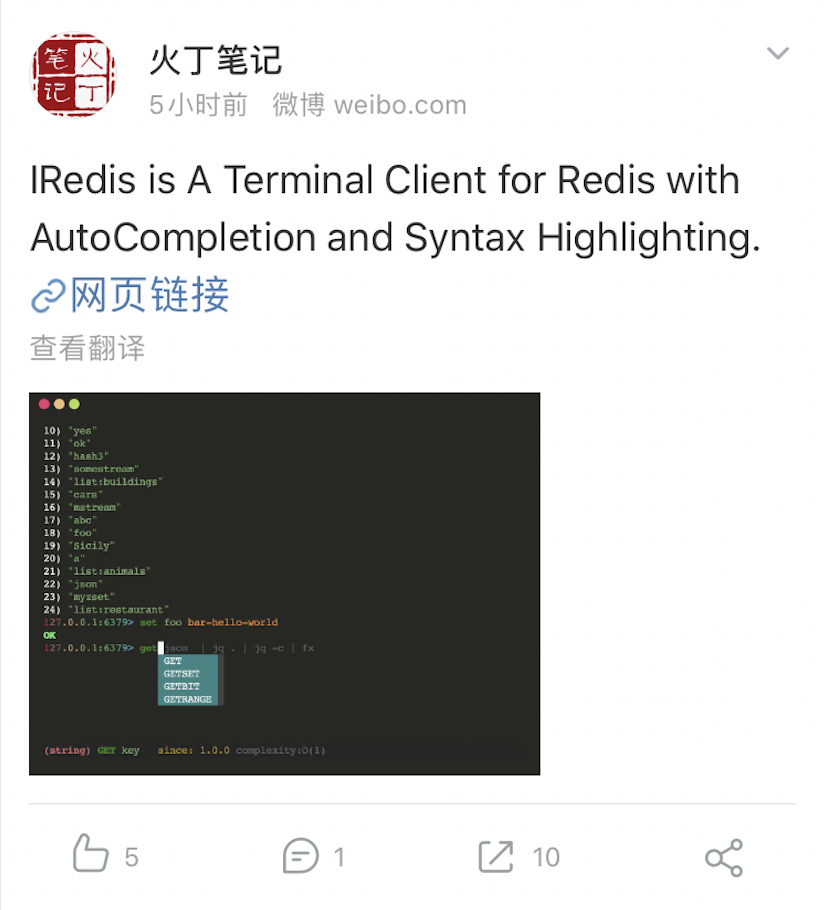
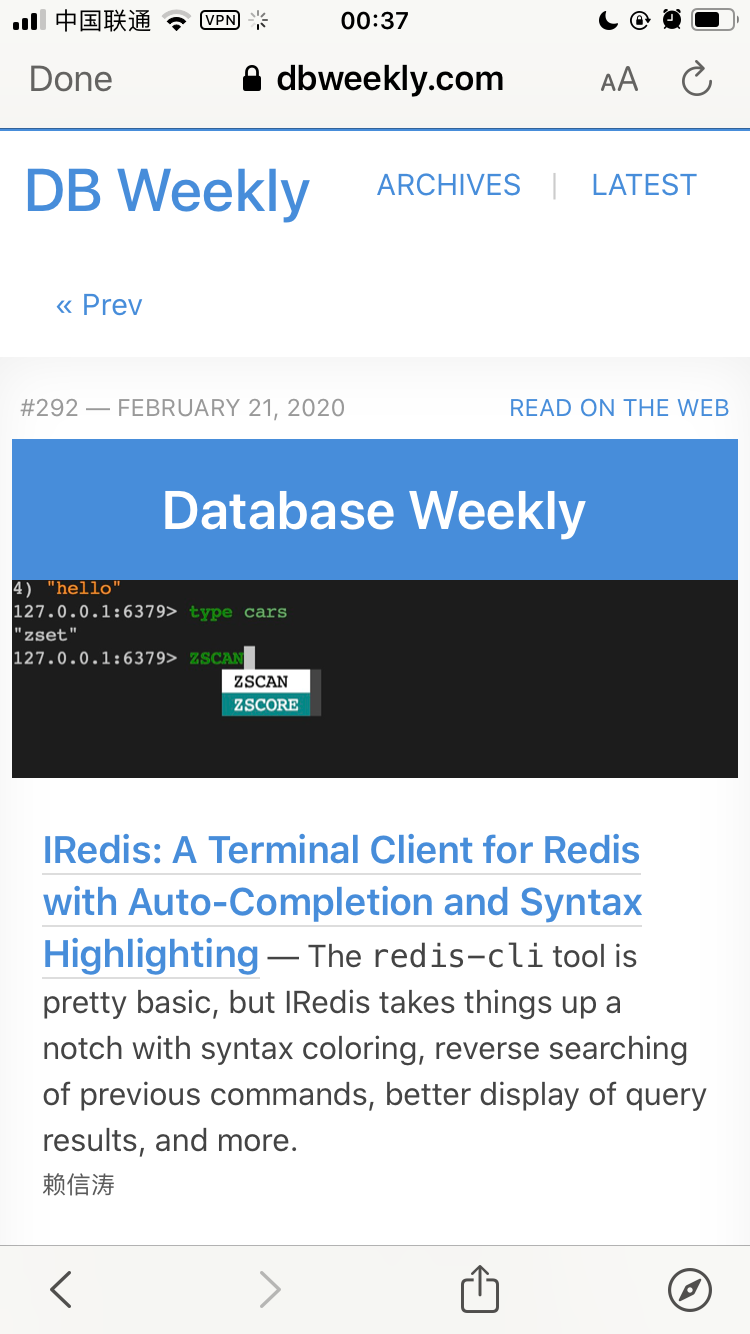
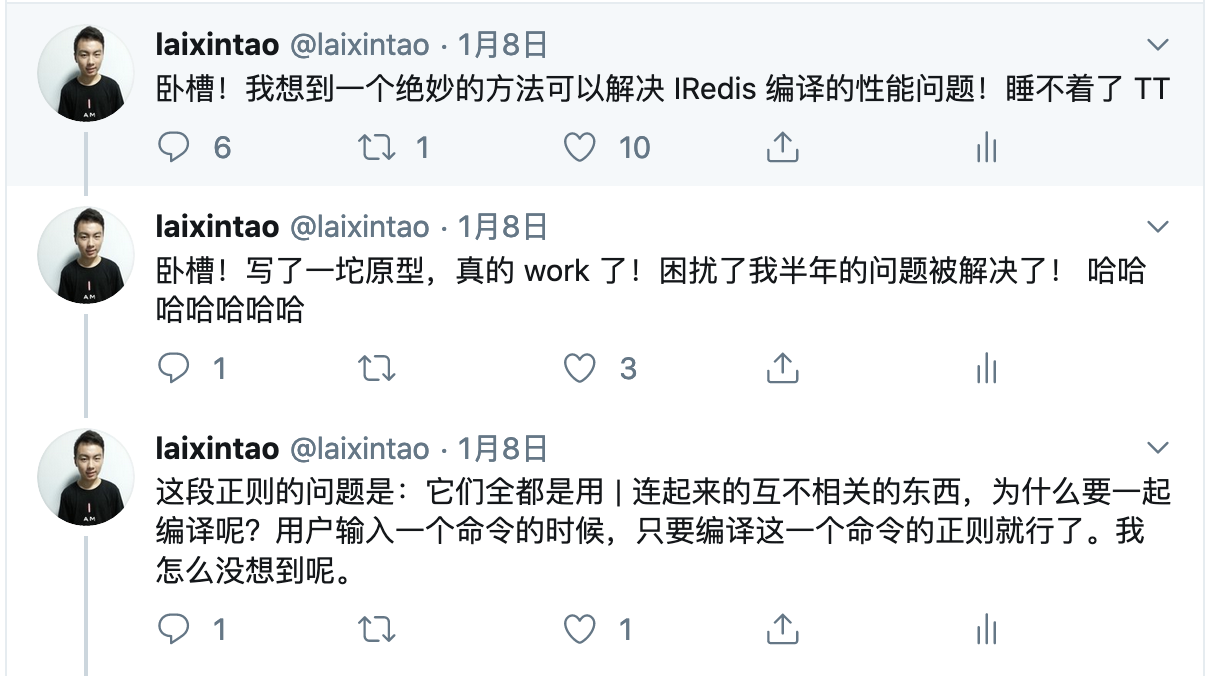
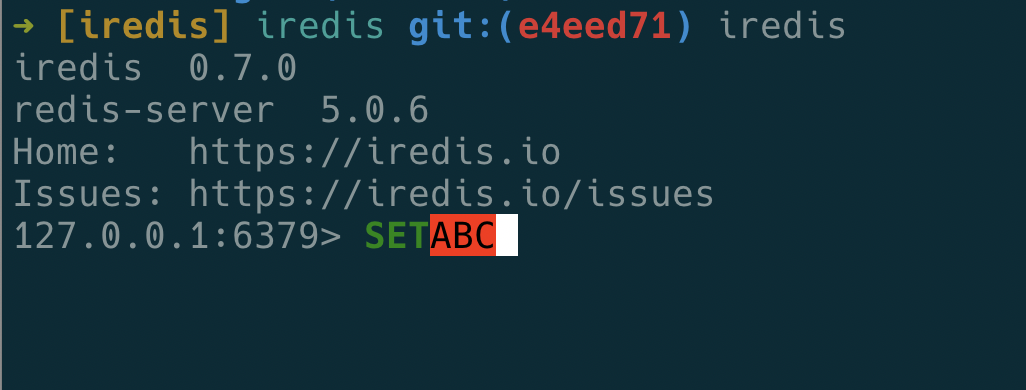
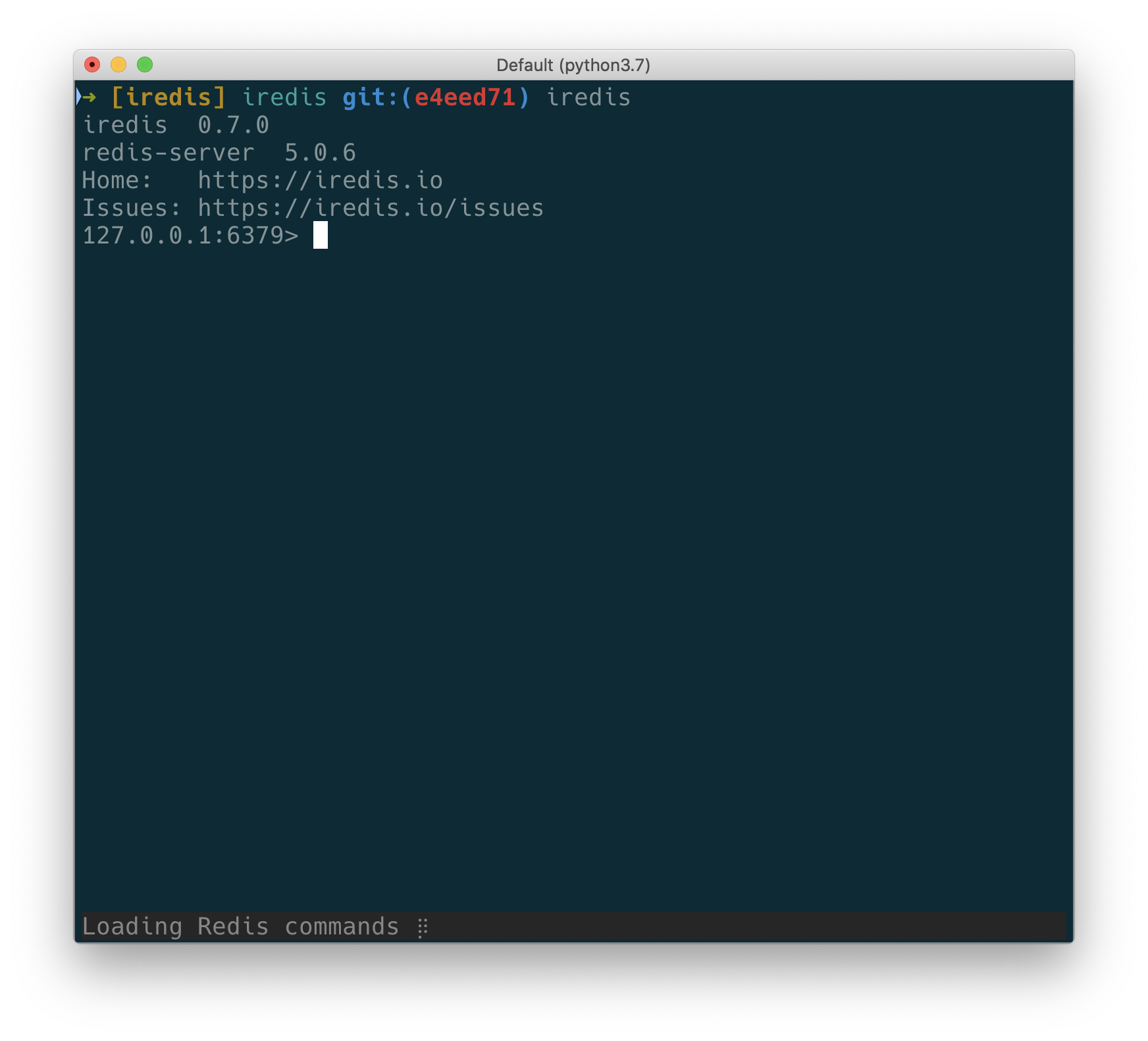
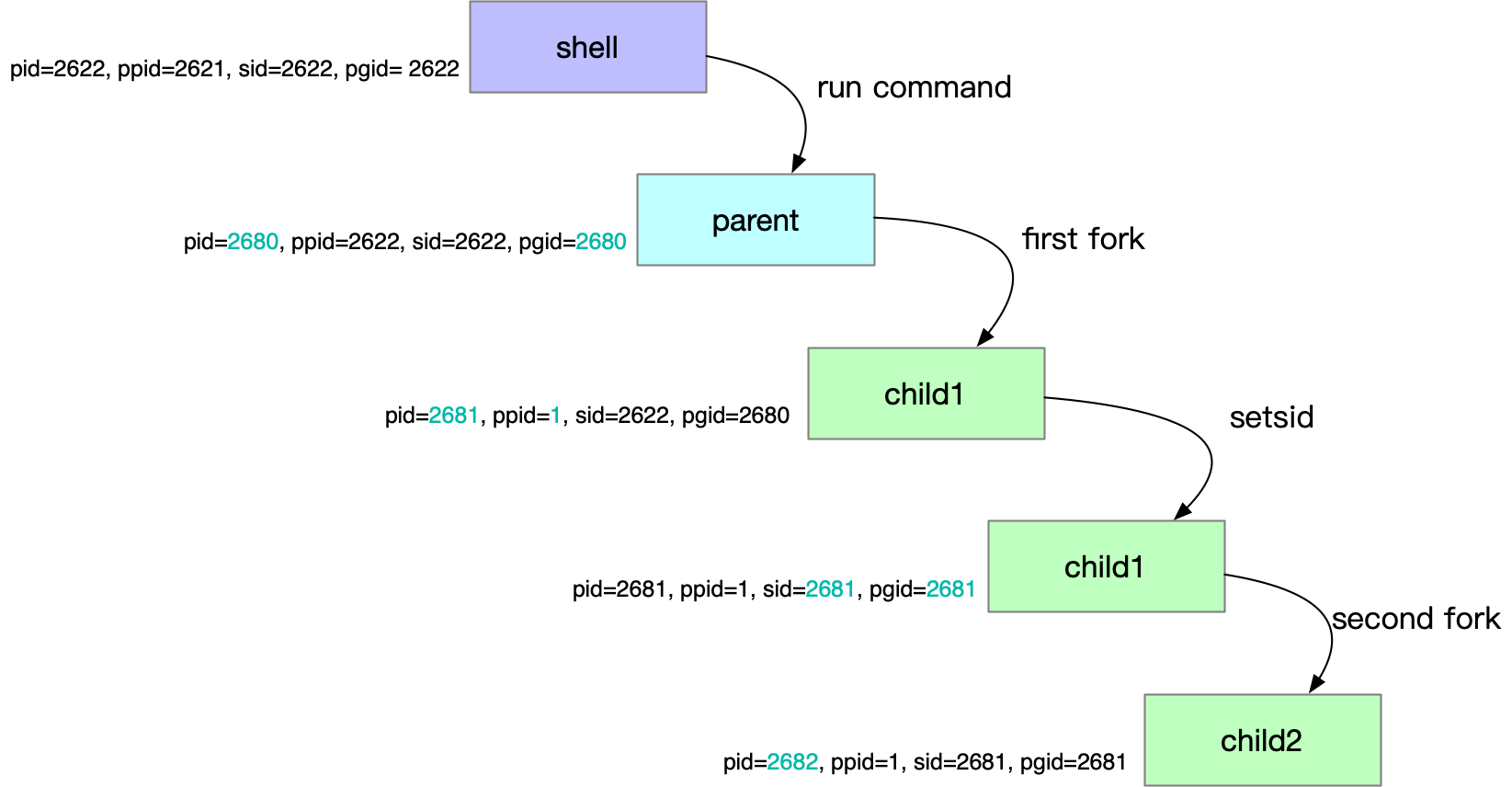
^(?:(?:(?:\s){0,}(?P<n5>(?:(?:(?:C)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n6>(?:(?:C(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n7>(?:(?:CL(?:U)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n8>(?:(?:CLU(?:S)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n9>(?:(?:CLUS(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n10>(?:(?:CLUST(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n11>(?:(?:CLUSTE(?:R)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n12>(?:(?:CLUSTER(?:\s)*(?:(?:\s)?)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n13>(?:(?:CLUSTER(?:\s){1,}(?:K)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n14>(?:(?:CLUSTER(?:\s){1,}K(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n15>(?:(?:CLUSTER(?:\s){1,}KE(?:Y)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n16>(?:(?:CLUSTER(?:\s){1,}KEY(?:S)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n17>(?:(?:CLUSTER(?:\s){1,}KEYS(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n18>(?:(?:CLUSTER(?:\s){1,}KEYSL(?:O)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n19>(?:(?:CLUSTER(?:\s){1,}KEYSLO(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n20>(?:(?:(?:D)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n21>(?:(?:D(?:U)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n22>(?:(?:DU(?:M)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n23>(?:(?:DUM(?:P)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n24>(?:(?:(?:P)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n25>(?:(?:P(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n26>(?:(?:PE(?:R)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n27>(?:(?:PER(?:S)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n28>(?:(?:PERS(?:I)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n29>(?:(?:PERSI(?:S)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n30>(?:(?:PERSIS(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n31>(?:(?:(?:P)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n32>(?:(?:P(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n33>(?:(?:PT(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n34>(?:(?:PTT(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n35>(?:(?:(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n36>(?:(?:T(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n37>(?:(?:TT(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n38>(?:(?:(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n39>(?:(?:T(?:Y)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n40>(?:(?:TY(?:P)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n41>(?:(?:TYP(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n42>(?:(?:(?:H)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n43>(?:(?:H(?:G)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n44>(?:(?:HG(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n45>(?:(?:HGE(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n46>(?:(?:HGET(?:A)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n47>(?:(?:HGETA(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n48>(?:(?:HGETAL(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n49>(?:(?:(?:H)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n50>(?:(?:H(?:K)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n51>(?:(?:HK(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n52>(?:(?:HKE(?:Y)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n53>(?:(?:HKEY(?:S)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n54>(?:(?:(?:H)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n55>(?:(?:H(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n56>(?:(?:HL(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n57>(?:(?:HLE(?:N)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n58>(?:(?:(?:H)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n59>(?:(?:H(?:V)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n60>(?:(?:HV(?:A)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n61>(?:(?:HVA(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n62>(?:(?:HVAL(?:S)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n63>(?:(?:(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n64>(?:(?:L(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n65>(?:(?:LL(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n66>(?:(?:LLE(?:N)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n67>(?:(?:(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n68>(?:(?:L(?:P)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n69>(?:(?:LP(?:O)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n70>(?:(?:LPO(?:P)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n71>(?:(?:(?:R)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n72>(?:(?:R(?:P)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n73>(?:(?:RP(?:O)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n74>(?:(?:RPO(?:P)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n75>(?:(?:(?:D)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n76>(?:(?:D(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n77>(?:(?:DE(?:B)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n78>(?:(?:DEB(?:U)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n79>(?:(?:DEBU(?:G)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n80>(?:(?:DEBUG(?:\s)*(?:(?:\s)?)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n81>(?:(?:DEBUG(?:\s){1,}(?:O)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n82>(?:(?:DEBUG(?:\s){1,}O(?:B)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n83>(?:(?:DEBUG(?:\s){1,}OB(?:J)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n84>(?:(?:DEBUG(?:\s){1,}OBJ(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n85>(?:(?:DEBUG(?:\s){1,}OBJE(?:C)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n86>(?:(?:DEBUG(?:\s){1,}OBJEC(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n87>(?:(?:(?:S)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n88>(?:(?:S(?:C)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n89>(?:(?:SC(?:A)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n90>(?:(?:SCA(?:R)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n91>(?:(?:SCAR(?:D)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n92>(?:(?:(?:S)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n93>(?:(?:S(?:M)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n94>(?:(?:SM(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n95>(?:(?:SME(?:M)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n96>(?:(?:SMEM(?:B)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n97>(?:(?:SMEMB(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n98>(?:(?:SMEMBE(?:R)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n99>(?:(?:SMEMBER(?:S)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n100>(?:(?:(?:Z)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n101>(?:(?:Z(?:C)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n102>(?:(?:ZC(?:A)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n103>(?:(?:ZCA(?:R)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n104>(?:(?:ZCAR(?:D)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n105>(?:(?:(?:D)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n106>(?:(?:D(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n107>(?:(?:DE(?:C)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n108>(?:(?:DEC(?:R)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n109>(?:(?:(?:G)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n110>(?:(?:G(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n111>(?:(?:GE(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n112>(?:(?:(?:I)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n113>(?:(?:I(?:N)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n114>(?:(?:IN(?:C)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n115>(?:(?:INC(?:R)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n116>(?:(?:(?:S)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n117>(?:(?:S(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n118>(?:(?:ST(?:R)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n119>(?:(?:STR(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n120>(?:(?:STRL(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n121>(?:(?:STRLE(?:N)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n122>(?:(?:(?:c)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n123>(?:(?:c(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n124>(?:(?:cl(?:u)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n125>(?:(?:clu(?:s)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n126>(?:(?:clus(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n127>(?:(?:clust(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n128>(?:(?:cluste(?:r)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n129>(?:(?:cluster(?:\s)*(?:(?:\s)?)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n130>(?:(?:cluster(?:\s){1,}(?:k)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n131>(?:(?:cluster(?:\s){1,}k(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n132>(?:(?:cluster(?:\s){1,}ke(?:y)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n133>(?:(?:cluster(?:\s){1,}key(?:s)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n134>(?:(?:cluster(?:\s){1,}keys(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n135>(?:(?:cluster(?:\s){1,}keysl(?:o)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n136>(?:(?:cluster(?:\s){1,}keyslo(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n137>(?:(?:(?:d)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n138>(?:(?:d(?:u)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n139>(?:(?:du(?:m)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n140>(?:(?:dum(?:p)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n141>(?:(?:(?:p)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n142>(?:(?:p(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n143>(?:(?:pe(?:r)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n144>(?:(?:per(?:s)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n145>(?:(?:pers(?:i)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n146>(?:(?:persi(?:s)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n147>(?:(?:persis(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n148>(?:(?:(?:p)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n149>(?:(?:p(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n150>(?:(?:pt(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n151>(?:(?:ptt(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n152>(?:(?:(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n153>(?:(?:t(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n154>(?:(?:tt(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n155>(?:(?:(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n156>(?:(?:t(?:y)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n157>(?:(?:ty(?:p)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n158>(?:(?:typ(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n159>(?:(?:(?:h)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n160>(?:(?:h(?:g)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n161>(?:(?:hg(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n162>(?:(?:hge(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n163>(?:(?:hget(?:a)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n164>(?:(?:hgeta(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n165>(?:(?:hgetal(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n166>(?:(?:(?:h)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n167>(?:(?:h(?:k)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n168>(?:(?:hk(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n169>(?:(?:hke(?:y)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n170>(?:(?:hkey(?:s)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n171>(?:(?:(?:h)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n172>(?:(?:h(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n173>(?:(?:hl(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n174>(?:(?:hle(?:n)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n175>(?:(?:(?:h)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n176>(?:(?:h(?:v)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n177>(?:(?:hv(?:a)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n178>(?:(?:hva(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n179>(?:(?:hval(?:s)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n180>(?:(?:(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n181>(?:(?:l(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n182>(?:(?:ll(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n183>(?:(?:lle(?:n)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n184>(?:(?:(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n185>(?:(?:l(?:p)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n186>(?:(?:lp(?:o)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n187>(?:(?:lpo(?:p)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n188>(?:(?:(?:r)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n189>(?:(?:r(?:p)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n190>(?:(?:rp(?:o)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n191>(?:(?:rpo(?:p)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n192>(?:(?:(?:d)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n193>(?:(?:d(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n194>(?:(?:de(?:b)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n195>(?:(?:deb(?:u)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n196>(?:(?:debu(?:g)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n197>(?:(?:debug(?:\s)*(?:(?:\s)?)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n198>(?:(?:debug(?:\s){1,}(?:o)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n199>(?:(?:debug(?:\s){1,}o(?:b)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n200>(?:(?:debug(?:\s){1,}ob(?:j)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n201>(?:(?:debug(?:\s){1,}obj(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n202>(?:(?:debug(?:\s){1,}obje(?:c)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n203>(?:(?:debug(?:\s){1,}objec(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n204>(?:(?:(?:s)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n205>(?:(?:s(?:c)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n206>(?:(?:sc(?:a)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n207>(?:(?:sca(?:r)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n208>(?:(?:scar(?:d)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n209>(?:(?:(?:s)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n210>(?:(?:s(?:m)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n211>(?:(?:sm(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n212>(?:(?:sme(?:m)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n213>(?:(?:smem(?:b)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n214>(?:(?:smemb(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n215>(?:(?:smembe(?:r)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n216>(?:(?:smember(?:s)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n217>(?:(?:(?:z)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n218>(?:(?:z(?:c)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n219>(?:(?:zc(?:a)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n220>(?:(?:zca(?:r)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n221>(?:(?:zcar(?:d)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n222>(?:(?:(?:d)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n223>(?:(?:d(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n224>(?:(?:de(?:c)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n225>(?:(?:dec(?:r)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n226>(?:(?:(?:g)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n227>(?:(?:g(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n228>(?:(?:ge(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n229>(?:(?:(?:i)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n230>(?:(?:i(?:n)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n231>(?:(?:in(?:c)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n232>(?:(?:inc(?:r)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n233>(?:(?:(?:s)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n234>(?:(?:s(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n235>(?:(?:st(?:r)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n236>(?:(?:str(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n237>(?:(?:strl(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n238>(?:(?:strle(?:n)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n239>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s)*(?:(?:\s)?)?))?$
^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n241>(?:(?:(?:")?))?)))?$
^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n242>(?:(?:"(?:(?:[^"]|\\"))*?(?:(?:(?:[^"])?)?)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n243>(?:(?:"(?:(?:[^"]|\\"))*?(?:(?:(?:(?:\\)?))?)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n244>(?:(?:"(?:(?:[^"]|\\"))*?(?:(?:(?:\\(?:")?))?)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n245>(?:(?:"(?:(?:[^"]|\\")){0,}?(?:")?))?)))?$
^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n246>(?:(?:(?:')?))?)))?$
^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n247>(?:(?:'(?:(?:[^']|\\'))*?(?:(?:(?:[^'])?)?)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n248>(?:(?:'(?:(?:[^']|\\'))*?(?:(?:(?:(?:\\)?))?)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n249>(?:(?:'(?:(?:[^']|\\'))*?(?:(?:(?:\\(?:')?))?)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n250>(?:(?:'(?:(?:[^']|\\')){0,}?(?:')?))?)))?$
^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n251>(?:(?:[^\s"])*(?:(?:[^\s"])?)?)?)))?$
^(?:(?:(?:\s){0,}(?P<n252>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n253>(?:"(?:(?:[^"]|\\")){0,}?"|'(?:(?:[^']|\\')){0,}?'|(?:[^\s"]){1,}))(?:\s)*(?:(?:\s)?)?))?$
^(?:(?:(?:\s)*(?:(?:\s)?)?))?$
^(?:(?:(?:\s){0,}(?P<n254>(?:(?:(?:C)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n255>(?:(?:C(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n256>(?:(?:CL(?:I)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n257>(?:(?:CLI(?:E)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n258>(?:(?:CLIE(?:N)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n259>(?:(?:CLIEN(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n260>(?:(?:CLIENT(?:\s)*(?:(?:\s)?)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n261>(?:(?:CLIENT(?:\s){1,}(?:L)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n262>(?:(?:CLIENT(?:\s){1,}L(?:I)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n263>(?:(?:CLIENT(?:\s){1,}LI(?:S)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n264>(?:(?:CLIENT(?:\s){1,}LIS(?:T)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n265>(?:(?:(?:c)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n266>(?:(?:c(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n267>(?:(?:cl(?:i)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n268>(?:(?:cli(?:e)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n269>(?:(?:clie(?:n)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n270>(?:(?:clien(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n271>(?:(?:client(?:\s)*(?:(?:\s)?)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n272>(?:(?:client(?:\s){1,}(?:l)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n273>(?:(?:client(?:\s){1,}l(?:i)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n274>(?:(?:client(?:\s){1,}li(?:s)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n275>(?:(?:client(?:\s){1,}lis(?:t)?))?)))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s)*(?:(?:\s)?)?))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n279>(?:(?:(?:T)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n280>(?:(?:T(?:Y)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n281>(?:(?:TY(?:P)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n282>(?:(?:TYP(?:E)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n283>(?:(?:(?:t)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n284>(?:(?:t(?:y)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n285>(?:(?:ty(?:p)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n286>(?:(?:typ(?:e)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n287>(?:TYPE|type))(?:\s)*(?:(?:\s)?)?))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n289>(?:(?:(?:N)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n290>(?:(?:N(?:O)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n291>(?:(?:NO(?:R)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n292>(?:(?:NOR(?:M)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n293>(?:(?:NORM(?:A)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n294>(?:(?:NORMA(?:L)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n295>(?:(?:(?:M)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n296>(?:(?:M(?:A)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n297>(?:(?:MA(?:S)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n298>(?:(?:MAS(?:T)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n299>(?:(?:MAST(?:E)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n300>(?:(?:MASTE(?:R)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n301>(?:(?:(?:R)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n302>(?:(?:R(?:E)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n303>(?:(?:RE(?:P)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n304>(?:(?:REP(?:L)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n305>(?:(?:REPL(?:I)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n306>(?:(?:REPLI(?:C)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n307>(?:(?:REPLIC(?:A)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n308>(?:(?:(?:P)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n309>(?:(?:P(?:U)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n310>(?:(?:PU(?:B)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n311>(?:(?:PUB(?:S)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n312>(?:(?:PUBS(?:U)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n313>(?:(?:PUBSU(?:B)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n314>(?:(?:(?:n)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n315>(?:(?:n(?:o)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n316>(?:(?:no(?:r)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n317>(?:(?:nor(?:m)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n318>(?:(?:norm(?:a)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n319>(?:(?:norma(?:l)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n320>(?:(?:(?:m)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n321>(?:(?:m(?:a)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n322>(?:(?:ma(?:s)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n323>(?:(?:mas(?:t)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n324>(?:(?:mast(?:e)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n325>(?:(?:maste(?:r)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n326>(?:(?:(?:r)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n327>(?:(?:r(?:e)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n328>(?:(?:re(?:p)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n329>(?:(?:rep(?:l)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n330>(?:(?:repl(?:i)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n331>(?:(?:repli(?:c)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n332>(?:(?:replic(?:a)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n333>(?:(?:(?:p)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n334>(?:(?:p(?:u)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n335>(?:(?:pu(?:b)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n336>(?:(?:pub(?:s)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n337>(?:(?:pubs(?:u)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n338>(?:(?:pubsu(?:b)?))?)))?))?$
^(?:(?:(?:\s){0,}(?P<n339>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n340>(?:TYPE|type))(?:\s){1,}(?P<n341>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){0,1}(?:\s)*(?:(?:\s)?)?))?$