这篇文章介绍跟硬盘分区相关的知识和概念。我觉得和这相关的内容比较难理解,是因为一部分是硬件上的概念,一部分是软件的(文件系统),很多资料介绍的时候,没有放到一起对比,读者看到的时候就会对一些概念很模糊。比如硬盘的分区有分区类型,文件系统有类型,这两种类型有啥区别?硬盘有扇区大小,文件系统有 block 大小,这两者又有什么区别?这篇文章试图深入浅出,从基本的原理讲起,介绍一些概念,它们分别是做什么的,为什么要这么做。
认识硬盘
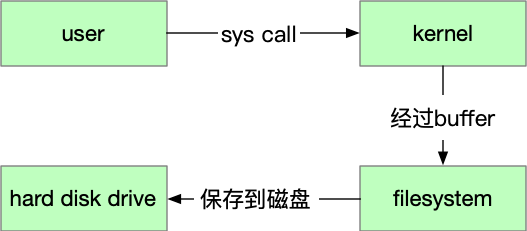
硬盘在 Linux 中,就是一个 block device,就是存储数据用的。你把数据输入到硬盘中,硬盘帮你存到一个位置。下次需要的时候,再从这个位置读出来。
那么给硬盘一个位置,它怎么去找这个位置的数据的呢?
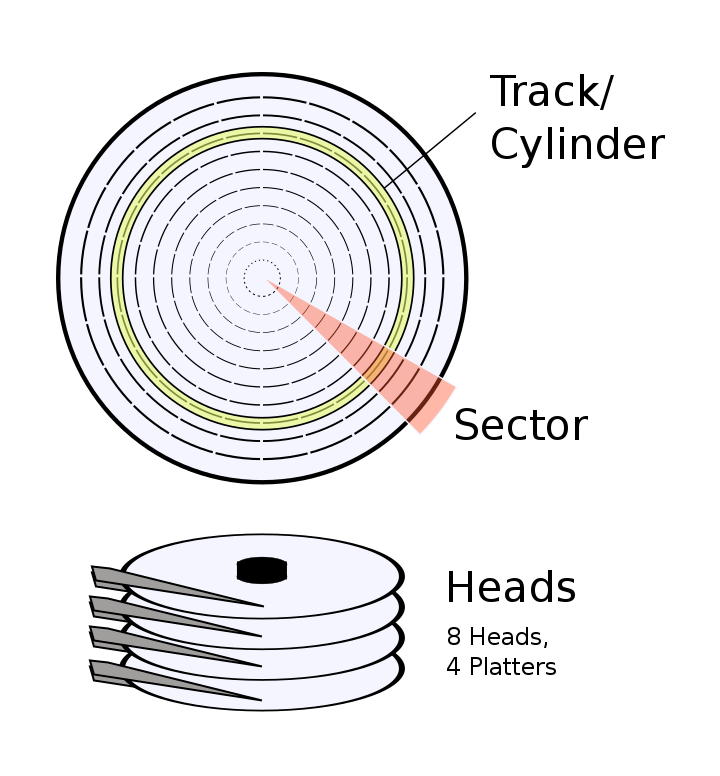
这要从硬盘的结构说起(虽然现在大部分的机器都使用 SSD 了,但是很多资料都是基于机械硬盘的,所以这里以机械硬盘为例,介绍一下 CHS 寻址的原理。)。硬盘是由几张碟片组成的,每张碟片的正反两面都可以保存数据。
所以这个问题就转换成了:在几个圆面中,如何确定一个位置。首先我们想,在一个圆面中,确定一个位置需要几个参数?很显然是2个,距离圆心的距离可以确定一个圆,再加上一个“角度”可以确定这个圆上的一个点。那么在硬盘的结构中,再加上一个参数确定是第几个圆面就可以了。
这几个参数我们分别叫它:
- Cylinder/Track:磁道,柱面,确定距离圆心的位置;
- Head: 磁头,这个是读写数据的物理装置,实际上硬盘在运行的时候,是盘片在转的,磁头负责移动,调整读取的柱面;
- Sector: 扇区。上面两个参数确定了一个圆形,Sector 就可以确定这个圆形中哪个扇区了。
这就是 CHS 寻址的方式。
从中可以也看出,硬盘存储的读写单位是“一个扇区”。实际上,在分区的时候,(分区软件)也会用“第几个到第几个扇区”来表示,不会让你涉及到 Track 和 Head 的,这是属于硬件自己用来寻址的东西。
使用 fdisk 我们可以看到硬盘有多少个扇区,一个扇区多大。实际上从 1980 年以来,几乎所有的硬盘扇区大小都是 512bytes。(@yiran 纠正:现在一些新磁盘的物理扇区是 4k 了,系统中看到的逻辑扇区是512字节)
|
|
$ fdisk -l Disk /dev/sda: 64 GiB, 68719476736 bytes, 134217728 sectors Disk model: VBOX HARDDISK Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x86ae6277 Device Boot Start End Sectors Size Id Type /dev/sda1 2048 4542463 4540416 2.2G 82 Linux swap / Solaris /dev/sda2 * 4542464 35999743 31457280 15G 83 Linux |
为什么要分区?
现在我们知道有了扇区的位置,硬盘就可以把数据写入或读出。那为什么要分区呢?原因以下几点:
- 隔离文件系统的腐烂(鸡蛋不放在一个篮子里)。我们要在设备上建立文件系统,操作系统才能使用文件系统来读写。文件系统是对存储设备的规划,记录着每一块都存了什么(inode, block)。万一文件系统的元数据错乱了,那么整个文件系统的数据可能都读不到了;
- 提高存储的利用率。参考之前的博文:Linux 文件系统 inode 介绍,一个文件最小将占用一个 block,如果 block 太大的话,将会浪费很多空间。比如 block size 是 4k,而存储的都是 1k 的文件,那么有 3/4 的空间是浪费的。如果 block 太小,那性能就很低,因为 kernel 是以 block 为单位拷贝的;我们可以分一个区,建一个 block size 为 512bytes 的文件系统来专门存储这些小文件;
- 限制文件增长。crontab 写日志太多了导致所有的进程都挂了,这肯定是不合理的。但是文件的增长不会越过文件系统,跑到另一个分区上,所以我们可以通过分区,来给特定的进程分配写空间。
基于此,我们可以在系统中为不同的存储内容划分区。比如为用户程序 /usr 单独分区,/home 单独分区。
分区的本质是什么?
不同的分区还是在一块硬盘上,相当于是对不同的扇区分组管理罢了。那么这个分组信息保存在哪里呢?
答案是第一个硬盘的第一个扇区上。硬盘的第一个扇区也是系统启动的时候第一个读的地方(基于 BIOS 的启动流程)。前面说到,一个扇区的大小是 512bytes,这 512bytes 都有什么呢?
在 Linux 中一切都是文件,硬盘也是一个文件,用 /dev/sda 表示(这是 SCSI 接口,IDE 接口会是 /dev/hda ,具体命名方式和编号见此)。这样,我们就可以将这个“文件”的前 512bytes 拷贝出来。
|
|
$ dd if=/dev/sda of=mbr.bin bs=512 count=1 1+0 records in 1+0 records out 512 bytes copied, 0.000308004 s, 1.7 MB/s |
然后可以用 Vim 带的 xxd 命令看一下这个文件的内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
$ xxd mbr.bin 00000000: eb63 9010 8ed0 bc00 b0b8 0000 8ed8 8ec0 .c.............. 00000010: fbbe 007c bf00 06b9 0002 f3a4 ea21 0600 ...|.........!.. 00000020: 00be be07 3804 750b 83c6 1081 fefe 0775 ....8.u........u 00000030: f3eb 16b4 02b0 01bb 007c b280 8a74 018b .........|...t.. 00000040: 4c02 cd13 ea00 7c00 00eb fe00 0000 0000 L.....|......... 00000050: 0000 0000 0000 0000 0000 0080 0100 0000 ................ 00000060: 0000 0000 fffa 9090 f6c2 8074 05f6 c270 ...........t...p 00000070: 7402 b280 ea79 7c00 0031 c08e d88e d0bc t....y|..1...... 00000080: 0020 fba0 647c 3cff 7402 88c2 52be 057c . ..d|<.t...R..| 00000090: b441 bbaa 55cd 135a 5272 3d81 fb55 aa75 .A..U..ZRr=..U.u 000000a0: 3783 e101 7432 31c0 8944 0440 8844 ff89 7...t21..D.@.D.. 000000b0: 4402 c704 1000 668b 1e5c 7c66 895c 0866 D.....f..\|f.\.f 000000c0: 8b1e 607c 6689 5c0c c744 0600 70b4 42cd ..`|f.\..D..p.B. 000000d0: 1372 05bb 0070 eb76 b408 cd13 730d 5a84 .r...p.v....s.Z. 000000e0: d20f 83de 00be 857d e982 0066 0fb6 c688 .......}...f.... 000000f0: 64ff 4066 8944 040f b6d1 c1e2 0288 e888 d.@f.D.......... 00000100: f440 8944 080f b6c2 c0e8 0266 8904 66a1 .@.D.......f..f. 00000110: 607c 6609 c075 4e66 a15c 7c66 31d2 66f7 `|f..uNf.\|f1.f. 00000120: 3488 d131 d266 f774 043b 4408 7d37 fec1 4..1.f.t.;D.}7.. 00000130: 88c5 30c0 c1e8 0208 c188 d05a 88c6 bb00 ..0........Z.... 00000140: 708e c331 dbb8 0102 cd13 721e 8cc3 601e p..1......r...`. 00000150: b900 018e db31 f6bf 0080 8ec6 fcf3 a51f .....1.......... 00000160: 61ff 265a 7cbe 807d eb03 be8f 7de8 3400 a.&Z|..}....}.4. 00000170: be94 7de8 2e00 cd18 ebfe 4752 5542 2000 ..}.......GRUB . 00000180: 4765 6f6d 0048 6172 6420 4469 736b 0052 Geom.Hard Disk.R 00000190: 6561 6400 2045 7272 6f72 0d0a 00bb 0100 ead. Error...... 000001a0: b40e cd10 ac3c 0075 f4c3 0000 0000 0000 .....<.u........ 000001b0: 0000 0000 0000 0000 7762 ae86 0000 0004 ........wb...... 000001c0: 0104 82fe c2ff 0008 0000 0048 4500 80fe ...........HE... 000001d0: c2ff 83bb c1bb 0050 4500 0000 e001 0000 .......PE....... 000001e0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000001f0: 0000 0000 0000 0000 0000 0000 0000 55aa ..............U. |
这里面的内容可以分成4部分:
- 001-440bytes(一共 440bytes):给 BIOS 执行的代码; 这个其实很有意思,感兴趣的朋友可以将这段 dump 成机器码看一下。启动系统需要将代码加载到内存,但是我们需要系统启动才能加载代码。所以这个过程又叫做 boot,即 “pull oneself over a fence by one’s bootstraps”。
- 441-446bytes(一共 6bytes):MBR Disk 签名;
- 447-510(一共 64bytes):分区表,一共 4 部分,每部分16 bytes;
- 最后的 511 和 512(一共2bytes):固定为 0x55AA,表示硬盘可以用于启动;
从 00001be 到最后 00001fd 之间,记录的都是分区表的信息。
|
|
000001b0: .... .... .... .... .... .... .... 0004 ........wb...... 000001c0: 0104 82fe c2ff 0008 0000 0048 4500 80fe ...........HE... 000001d0: c2ff 83bb c1bb 0050 4500 0000 e001 0000 .......PE....... 000001e0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000001f0: 0000 0000 0000 0000 0000 0000 0000 .... ................ |
- 分区1:
0004 0104 82fe c2ff 0008 0000 0048 4500
- 分区2:
80fe c2ff 83bb c1bb 0050 4500 0000 e001
- 分区3:
0000 0000 0000 0000 0000 0000 0000 0000
- 分区4:
0000 0000 0000 0000 0000 0000 0000 0000
根据上面 fdisk -l 显示,我这个机器只有两个分区,所以分区3和4是空的。这 16bytes 里面都记录的什么呢?我们拿其中一个分区来说明,这里就用第2个分区说吧:
80fe c2ff 83fe c1bb 0050 4500 0000 e001
0字节,80,是一个标志:
80 此分区可以用于系统启动;00 此分区不能用于系统启动;
1-3字节,fe c2ff 这就是用我们上面说的 CHS 地址表示,以及后面的 5-7 字节,分别表示此分区开始的位置是:
fe Cylinder位置是 fe;c2 Head 开始位置是 c2;ff Sector 开始位置是 ff;
相应的,这个分区的结束位置是 bb c1 bb。
开始和结束中间的第4字节,是分区类型。在这里是 83 ,表示 type 是 Linux.
在 fdisk 中可以通过 l 命令列出所有的 type:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
Command (m for help): l 0 Empty 24 NEC DOS 81 Minix / old Lin bf Solaris 1 FAT12 27 Hidden NTFS Win 82 Linux swap / So c1 DRDOS/sec (FAT- 2 XENIX root 39 Plan 9 83 Linux c4 DRDOS/sec (FAT- 3 XENIX usr 3c PartitionMagic 84 OS/2 hidden or c6 DRDOS/sec (FAT- 4 FAT16 <32M 40 Venix 80286 85 Linux extended c7 Syrinx 5 Extended 41 PPC PReP Boot 86 NTFS volume set da Non-FS data 6 FAT16 42 SFS 87 NTFS volume set db CP/M / CTOS / . 7 HPFS/NTFS/exFAT 4d QNX4.x 88 Linux plaintext de Dell Utility 8 AIX 4e QNX4.x 2nd part 8e Linux LVM df BootIt 9 AIX bootable 4f QNX4.x 3rd part 93 Amoeba e1 DOS access a OS/2 Boot Manag 50 OnTrack DM 94 Amoeba BBT e3 DOS R/O b W95 FAT32 51 OnTrack DM6 Aux 9f BSD/OS e4 SpeedStor c W95 FAT32 (LBA) 52 CP/M a0 IBM Thinkpad hi ea Rufus alignment e W95 FAT16 (LBA) 53 OnTrack DM6 Aux a5 FreeBSD eb BeOS fs f W95 Ext'd (LBA) 54 OnTrackDM6 a6 OpenBSD ee GPT 10 OPUS 55 EZ-Drive a7 NeXTSTEP ef EFI (FAT-12/16/ 11 Hidden FAT12 56 Golden Bow a8 Darwin UFS f0 Linux/PA-RISC b 12 Compaq diagnost 5c Priam Edisk a9 NetBSD f1 SpeedStor 14 Hidden FAT16 <3 61 SpeedStor ab Darwin boot f4 SpeedStor 16 Hidden FAT16 63 GNU HURD or Sys af HFS / HFS+ f2 DOS secondary 17 Hidden HPFS/NTF 64 Novell Netware b7 BSDI fs fb VMware VMFS 18 AST SmartSleep 65 Novell Netware b8 BSDI swap fc VMware VMKCORE 1b Hidden W95 FAT3 70 DiskSecure Mult bb Boot Wizard hid fd Linux raid auto 1c Hidden W95 FAT3 75 PC/IX bc Acronis FAT32 L fe LANstep 1e Hidden W95 FAT1 80 Old Minix be Solaris boot ff BBT |
但其实,这个分区类型在 Linux 中用处并不大,无论是 ext2 还是 ext3 还是其他 Linux 分区,都是 83。这个标志位不同的操作系统有不同的解释方法,比如 Windows,会用这个标志来区分不同的分区类型,所以你看到在这个表中,FAT32 和 NTFS 这些常见的 Windows 分区都分别占用了一种标志位。说到底,这个标志位其实就是个普通的标志,怎么解释归操作系统的,甚至不同的操作系统安装在同一个硬盘上也是可行的,比如 0x07 ,OS/2 认为这个标志位是 HPFS 类型的分区,Windows 认为是 NTFS 类型的分区。
要注意的是,这个标志位和文件系统并没有本质的关系。既然 Linux 不关心这个标志位,那么无论这个分区的类型是什么,我都可以在这上面建一个文件系统。甚至我可以在系统运行的时候覆盖写入这个标志位。比如我把当前的这个分区改成 FAT12,也是一点问题都没有的。
|
|
Device Boot Start End Sectors Size Id Type /dev/sda1 2048 4542463 4540416 2.2G 82 Linux swap / Solaris /dev/sda2 * 4542464 35999743 31457280 15G 1 FAT12 /dev/sda3 35999744 38096895 2097152 1G 83 Linux |
8-11字节:0050 4500 逻辑 block 地址的第一个扇区的绝对地址。
11-15字节:0000 e001 此分区一共有多少个扇区。
MBR 分区的限制:从这里可以看出,4个字节表示第一扇区的绝对地址,4个字节表示此分区有多少个扇区,那么 MBR 分区表最多可以支持的硬盘大小是:
|
|
512Bytes * 0xff ff ff ff + 512Bytes * 0xff ff ff ff 扇区大小 最大能表示的第一个扇区位置 扇区大小 最后一个分区的最大扇区数 |
即 512 * (2^32 -1 ) * 2 ,是 4TiB -1Kb。
然而,这样分区的话,必须要最后一个分区是 2TiB,这样才能利用起 4Tib。如果一个用户有一个 4TiB 的硬盘,想要平均分成4区,每个分区 1TiB,是不行的。这会对很多用户造成困惑,所以在商业宣传的时候,就直接说 MBR 支持 2TiB。参考1 参考2 yiran补充
主分区和扩展分区
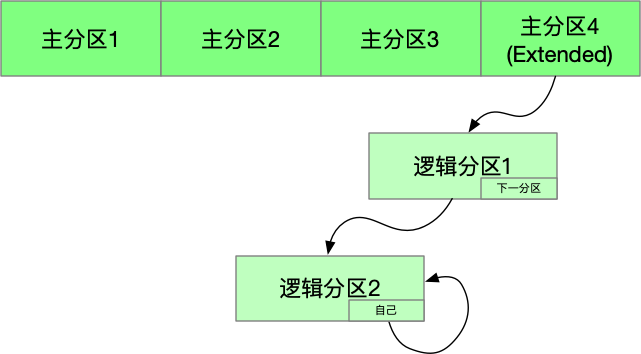
从这里也可以看出,分区数据一共 64bytes,每个分区表需要 16bytes 的信息。那么一共可以有 4 个分区。我第一次用电脑的时候,是 Windows,一直不明白“本地磁盘 CDEF”是什么意思。其实就是分区软件的快速分区模式默认平均将硬盘分了4个区而已。
分区表决定了我们只能创建 4 个分区,如果我们想要更多的分区怎么办?
还记得在文件系统中 block 寻址的时候如果超过 inode 能存放的 block 怎么办吗?答案是:inode 存放的 block,实际的内容是指向真正的 block 的地址。这里也用了同样的原理,我们可以创建一个类型为 Extended 类型(标志位是 5)的主分区,然后这个分区中每个分区的最后都保存着指向下一个分区的地址。
逻辑分区必须是连续的(显而易见),但是主分区可以不连续。除此之外逻辑分区和主分区在使用上并没有差别。逻辑分区也可以启动系统。
介绍到这里,应该能解决读者大部分的问题了(至少这些内容回答了我的很多疑问)。更加深入的问题,可能就要读者基于这些内容,自行搜索更详细的资料了。
扇区大小和Block大小
看文本文你应该对这个问题有所了解,扇区是一个硬盘的概念,几乎所有的硬盘扇区都是 512Bytes,如果不是,可能会出问题的。而 Block 指的是一个逻辑上的概念。但是可能在一些情景下依然对它们有些困惑。我研究了一番相关的内容,所以在这里多少一些,以便将来跟我有同样疑问的朋友,能找到这里,节省一些时间。
扇区大小的概念,出入很小。但是 Block 在不同的情景下是有不同的含义的。
首先是文件系统的 block,这里的 block 会影响存储文件使用的 block 大小。道理很简单,文件系统以 block 为单位寻址,如果 block 大小为 4k,那么即使文件写入 1k,也需要占用 4k。
创建文件系统,会自动分配 inode 和 block:
|
|
$ mkfs -t ext2 /dev/sda5 mke2fs 1.45.3 (14-Jul-2019) Creating filesystem with 131072 1k blocks and 32768 inodes Filesystem UUID: eac2bf41-3564-4f66-8740-e574593247fa Superblock backups stored on blocks: 8193, 24577, 40961, 57345, 73729 Allocating group tables: done Writing inode tables: done Writing superblocks and filesystem accounting information: done |
IO 中的 block:IO 是以 block 为单位的,这个 block 不一定是文件系统的 block 大小,也不一定是扇区的大小,可以比扇区更小,但是这是一种浪费,因为硬盘每次写会写 512bytes,如果 IO 的 block 是 256bytes,那么相当于写入相同一个扇区的内容,用了两次物理写入操作。此外,我们写入磁盘必须经过 syscall,在用户空间和 kernel 空间之间拷贝数据,也是以 block 为单位。我们可以用 madvice 这个系统调用向 Kernel 建议 IO block size。
以下是我用 dd 从硬盘拷贝相同的数据,使用不同的 block size,可以见期速度的影响。
|
|
$ dd if=/dev/sda of=dump.bin bs=200 count=1000 1000+0 records in 1000+0 records out 200000 bytes (200 kB, 195 KiB) copied, 0.0111036 s, 18.0 MB/s $ dd if=/dev/sda of=dump.bin bs=512 count=1000 1000+0 records in 1000+0 records out 512000 bytes (512 kB, 500 KiB) copied, 0.00905283 s, 56.6 MB/s $ dd if=/dev/sda of=dump.bin bs=1024 count=1000 1000+0 records in 1000+0 records out 1024000 bytes (1.0 MB, 1000 KiB) copied, 0.0061073 s, 168 MB/s |
但是 IO 其实是一个很复杂的问题,三言两语是说不清楚的,推荐一本书 Linux System Programming,里面用了四章介绍 IO 相关的话题。
除此之外,在看到 block 的时候,你还要注意它说的是什么语境。比如 ls -s 命令展示的 block,是以每个 block=1024bytes 展示的,而 stat 里面的 block 是 512bytes。
|
|
$ ls -s a.txt 4 a.txt $ stat a.txt File: a.txt Size: 6 Blocks: 8 IO Block: 4096 regular file Device: 802h/2050d Inode: 656578 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Context: unconfined_u:object_r:user_home_t:s0 Access: 2019-12-01 09:49:27.651029032 +0000 Modify: 2019-12-01 09:51:26.508134896 +0000 Change: 2019-12-01 09:51:26.508134896 +0000 Birth: 2019-12-01 09:49:27.651029032 +0000 |
建议用相关工具实践一下分区,建议在虚拟机里面操作,不用担心搞坏宿主机。玩一下这些命令:
- xxd (vim提供)
- fdisk
- mount
- grub
- ss
- dd
这篇文章参考的资料:
- Linux Partition HOWTO
- 分区标志
- Parition Types
- Linux System Administrators Guide: Chapter 5. Using Disks and Other Storage Media
- Linux 是如何启动的?
- Linux MBR
- 分区类型和文件系统类型的区别
- 如何确定 block size