这篇文章将介绍 Linux 中一个进程是如何诞生的,如何结束的。进程有哪些的不同状态,这些状态如何进行转换。
首先我们从进程的基本概念说起。
Linux 中,进程是由父进程创建的,每一个进程又可以作为父进程再创建子进程。每一个进程都有一个ID,叫做 pid,作为进程的唯一标志。Pid 在系统的同一时间不会重复,当分配 pid 的时候,kernel 会取当前系统中最大的 pid + 1,直到这个值超过 /proc/sys/kernel/pid_max ,所以 kernel 不保证 pid 在不同时间不会复用。在进程的结构体里面保存了 ppid,就是父进程的 id。根据 pid 和 ppid 我们可以找到每一个进程的父进程,这样,系统中所有的进程就像一个树一样可以串起来。
通过 pstree 这个工具,我们用一个树展示出所有的进程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
[root@trial1 vagrant]# pstree -p systemd(1)─┬─NetworkManager(2170)─┬─dhclient(2185) │ ├─{NetworkManager}(2171) │ └─{NetworkManager}(2173) ├─agetty(614) ├─auditd(18996)───{auditd}(18997) ├─chronyd(505) ├─dbus-daemon(482)───{dbus-daemon}(498) ├─firewalld(533)───{firewalld}(719) ├─haveged(488) ├─memcached(587)─┬─{memcached}(594) │ ├─{memcached}(595) │ ├─{memcached}(596) │ ├─{memcached}(597) │ ├─{memcached}(598) │ ├─{memcached}(599) │ ├─{memcached}(600) │ ├─{memcached}(601) │ └─{memcached}(602) ├─polkitd(483)─┬─{polkitd}(521) │ ├─{polkitd}(522) │ ├─{polkitd}(523) │ ├─{polkitd}(524) │ ├─{polkitd}(525) │ ├─{polkitd}(526) │ ├─{polkitd}(527) │ ├─{polkitd}(528) │ └─{polkitd}(530) ├─sshd(2210)───sshd(2221)───bash(2222)───sudo(2248)───bash(2250)───pstree(+ ├─sshd(18956)───sshd(6828)───sshd(6831)───bash(6832) ├─sssd(4248)─┬─sssd_be(4249) │ └─sssd_nss(4250) ├─systemd(2214)───(sd-pam)(2216) ├─systemd-journal(417) ├─systemd-logind(541) ├─systemd-udevd(438) └─tuned(19019)─┬─{tuned}(19023) ├─{tuned}(19025) └─{tuned}(19031) |
可以看到,最上层的进程的 pid 是 1,其他的进程要么是 pid 1 进程的子进程,要么是 pid 1 子进程的子进程,pid 1 的进程是所有进程的“祖先”。Pid 为 1 的进程,是在 kernel 启动的时候就创建的,所以实际 init 进程没有通常意义上的“父进程”,这里显示出它的父进程是进程0,只是一个标志。
|
|
[root@trial1 vagrant]# ps o pid,ppid,comm -p 1 PID PPID COMMAND 1 0 systemd |
Pid 为 1 的进程是可以指定的,我这个系统中是 systemd。如果不指定的话,Kernel 将尝试以下 4 个可执行文件:
- /sbin/init: The preferred and most likely location for the init process.
- /etc/init: Another likely location for the init process.
- /bin/init: A possible location for the init process.
- /bin/sh: The location of the Bourne shell, which the kernel tries to run if it fails to find an init process.
除了 pid 为 1 的进程外,其实还有一个 pid 为 2 的进程,父进程也是 0. 这个进程叫 kthreadd。
|
|
[root@trial1 vagrant]# ps o pid,ppid,comm -p 2 PID PPID COMMAND 2 0 kthreadd |
同理,这个进程也是在 Kernel 启动的时候就创建的。Linux 中有一些进程是跑在 Kernel 中的,但是为了统一调度,这些进程也同用户进程一样放在一起管理。kthreadd 就是这些 kernel 进程的父进程,等同于 init 进程(或者 systemd 进程)之于我们的用户进程。
Pid 0可以认为就是 kernel 本身。这个进程也是 idel process,当没有可以运行的进程的时候,kernel 就运行进程 0.
那么一个进程是如何产生自己的子进程的呢?
进程创建
在 Unix 中,创建进程和载入要执行的程序是分开的。创建一个进程一共2步,涉及2个 syscall。
第一个是 fork(),负责创建出来一个新的进程。那么新的进程也需要有可执行的代码、地址空间啥的呀,默认是啥呢?总不能是空的吧,如果是空的,那 kernel 执行到这个进程怎么办?
答案是 fork() 出来的进程,和父进程是一模一样的,除了:
- 子进程的 pid 被重新分配;
- 子进程的父进程被设置为原来的进程;
- 子进程资源的统计被初始化成0;
- 子进程中,未处理的 signal 全部清除;
- 父进程的 file lock 不会继承到子进程;
那两个进程是一模一样的,我执行了 fork() 之后,怎么让这两个进程做不一样的事情呢?答案是 fork() 的返回值不同,fork() 在父进程中返回子进程的 pid,在子进程中返回 0.这样我们就可以在调用 fork() 之后,通过一个 if 判断,让子进程和父进程做不一样的事情。一般是下面这种代码模板:
|
|
pid_t pid; pid=fork( ); if (pid > 0) printf ("I am the parent of pid=%d!\n", pid); else if (!pid) printf ("I am the baby!\n"); else if (pid == -1) perror ("fork"); |
新的进程创建好了,我们想让新的进程去执行另一部分任务,但是无法像上面这样都写在代码中,怎么办呢?举个很好理解的场景,我在终端的 bash 中执行了一个 top 命令,那么 bash 的代码肯定是和 top 没有关系的,怎么让 bash 新创建的子进程去执行 top 的代码吗?
这就是载入部分了。载入的 syscall 是一个函数族,这里用调用最简单的 execl() 举例:
|
|
int ret; ret = execl ("/bin/vi", "vi", NULL); if (ret == -1) perror ("execl"); |
有关 execl 具体的行为,可以参考下 manual. exec 是一个 syscall family,除了 execl() 这个之外,还有:execl, execlp, execle, execv, execvp, execvpe。本质上他们都一样,只是传入参数的格式、path、环境变量有些许不同。这些函数都是 glibc 提供的库函数(其他的 C 库提供的会有所不同,比如 libc 提供的函数族就是 execl, execle, execlp, execv, execvp, execvP ),底层他们调用的都是 execve(感谢 Nitroethane 指正)。
通常,打开的文件可以通过 exec 继承。比如父进程打开了一个文件,那么父进程的子进程是有 full access 的。如果不想这么做的话,可以在 exec 之前关闭这些文件。
Copy-on-write
在早期的 Unix 系统中,fork() 之后要复制很多东西到子进程,最耗时的是要一个 page 一个 page 地拷贝内存,这个操作非常耗时。
现代的 Unix 系统中,有一种叫做 copy-on-write 的机制。本质上是对这种资源复制的优化策略:如果多个消费者都需要一段内存的副本的话,先不去真正的做拷贝,而是让这些消费者都认为自己持有这段内存。如果进行读操作,那其实大家读到的还是同一段内存;如果要进行写操作,那这段内存(以 page 为单位)就会透明地被 kernel 拷贝出来。所以是一种懒加载的策略,只有用到的时候才去拷贝。
fork() 可以说是这个机制的最大受益者,因为 fork() 之后经常跟的是 exec ,也就是说子进程被 fork 出来之后都去干别的了,你复制一遍父进程的内存过来也没有意义。
这里我还想提一下,Redis 的 rdb 机制也是 copy-on-write 的一大受益者。Redis 的 rdb 就是定期将 Redis 内存中存储的数据转存到硬盘上,这个功能是基于 fork 实现的:当 Reids 要要 dump rdb 的时候,先 fork 出一个子进程,然后子进程开始从内存读出来数据,写到硬盘上,而原来的进程(父进程)继续提供服务。得益于 copy-on-write,子进程不需要完全复制一份父进程的内存来做写硬盘操作,即节省了时间和CPU,也节省了内存——它和父进程读的是同一段内存。
但是这里有个问题就是,假如 Reids 用在了一个写操作非常频繁的场景的话,那 copy-on-write 的意义就不大了。子进程 fork 出来之后,父进程因为写入很频繁,大部分内存都脏了,都需要被 kernel copy 出一份进行写操作。就可能导致在 dump rdb 的时候,内存占用提升了一倍(子进程和父进程分别有一份内存)。
进程销毁
一个进程要结束自己,非常简单。调用 exit() 这个 syscall,kernel 就会结束这个函数的调用者进程。我们也可以通过 atexit() 或 on_exit() 函数注册一些进程退出时的 hook。
除了显示的调用 exit() 之外,一个经典的退出方式是执行完整个程序。比如 main() 函数的代码最后,编译器会插入一个 _exit()。
进程收到 SIGTERM 或 SIGKILL 之后也会退出。具体的 signal 下面会介绍。
最后一种结束进程的方式是,惹的 kernel 不高兴了。比如出现 OOM 了(out-of-memory),或者 segment fault。kernel 会结束这个进程。
子进程退出之后,谁关心子进程是如何退出的呢?比如 daemon 进程退出了,systemd 如何实现“restart on failure”呢?所以这里还需要某种机制,来关心子进程的退出状态。
当子进程的状态改变之后,父进程会发生2件事情:
- 父进程会收到 SIGCHLD 信号;
- 父进程 block 调用
waitpid() 会返回(即这个系统调用会拿到子进程具体的事件);
也就是说父进程如果关心子进程的状态的话,一般是会设置 SIGCHLD 信号的 handler(进程如何处理信号,本文暂不涉及),收到这个信号之后去调用 wait() 系统调用,得到具体的事件。
这里有一个 Python 写的例子,展示了父进程如何得到子进程的状态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import os import sys import signal def waitpid(): (pid, status) = os.waitpid(-1, os.WUNTRACED | os.WCONTINUED) if os.WIFSTOPPED(status): s = "stopped sig=%i" % os.WSTOPSIG(status) elif os.WIFCONTINUED(status): s = "continued" elif os.WIFSIGNALED(status): s = "exited signal=%i" % os.WTERMSIG(status) elif os.WIFEXITED(status): s = "exited status=%i" % os.WEXITSTATUS(status) print "waitpid received: pid=%i %s" % (pid, s) childpid = os.fork() if childpid == 0: # Child os.kill(os.getpid(), signal.SIGSTOP) sys.exit() waitpid() os.kill(childpid, signal.SIGCONT) waitpid() waitpid() |
执行这段程序,输出如下:
|
|
$ python parent.py waitpid received: pid=16935 stopped sig=19 waitpid received: pid=16935 continued waitpid received: pid=16935 exited status=0 |
这段代码执行的流程如下:
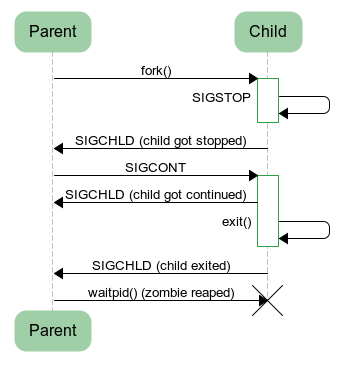
子进程在退出之后,保存进程状态的一些信息并不会立即销毁,因为这样的话,父进程就无法获得这些信息了。它们等待父进程调用 wait() 来读出来后,才会真正销毁。
这种已经退出,但是 state change 并没有被父进程读到的进程,叫做讲僵尸进程(Zombies)。父进程创建了子进程,就需要对子进程负责,在子进程退出之后,去调用 wait() 来 clear 这些子进程状态,即使父进程并不关心这些状态是什么。不然的话,这些子进程的状态将一直存在,占用资源(虽然很少),成为 ghosts,这些 ghosts 的 parent 也成为了不负责任的父母。
通常,我们可以安装一个 signal handler 来 wait() 这些子进程。需要注意的是,发给父进程的 SIGCHLD 可能被合并,比如有 3 个子进程退出了,但是父进程实际上只会收到一次 SIGCHLD。所以我们在 wait() 的时候要注意使用一个循环。
|
|
static void sigchld_handler(int sig) { int status; int pid; while ((pid = waitpid(-1, &status, WNOHANG)) > 0) { // `pid` exited with `status` } } |
如果一个进程创建了子进程,但是在子进程之前就退出了呢?这样子进程就没有父进程来调用 wait() 了。
当一个进程结束的时候,kernel 会遍历它的子进程,将这些父进程已经死掉的进程,分配给 init 进程(即 pid 是1的进程)作为它们的父进程。这就保证了系统中每一个进程,都有一个直接的父进程。init 进程会定期去 wait() 它所有的子进程。
进程的状态
上面我们已经提到了一些进程的状态:Zombies,Runing,Stopped。
这里重点解释一下几种状态:
- R – runnable,处于这个状态的进程是可以执行的,会被 kernel 放到一个待执行的 queue 中,分配时间片去执行。我们无法控制进程的运行,runnable 的进程由 kernel 的 scheduler 来决定什么时候运行,运行多长时间;
- D – 不可中断的 sleep(一般是IO);
- S – 可中断的 sleep;
- Z – 进程已死,或者失去响应,死透了;
- T – 进程以暂停(是可以恢复的,还没死透);
这里面其他状态都比较好理解,D 和 S 有点模糊。
代码在执行的时候,会在 user space 和 kernel space 之间切换。当执行 syscall 的时候,代码的执行从用户空间切换到内核空间。当在等待 system call 的时候,进程处于 S 状态或者 D 状态。S 状态比如 read() ,这时收到像 SIGTERM 这样的信号,进程就会提前结束 syscall,返回用户空间,执行 signal hanlder 的代码;如果是处于 D 状态,进程就是不可 kill 的。
T 状态是可以恢复的暂停。比如我们给进程发送 SIGSTOP 或者按 CTRL+Z,就可以将进程置为暂停状态,可以通过 bg/fg 命令,或者发送 SIGCONT 信号恢复。
下面开启了一个 sleep 命令,然后用 CTRL+Z 暂停它,再用 fg 重新开启。展示了 S -> T -> S 的状态转换:
|
|
[root@trial1 vagrant]# sleep 100 ^Z [1]+ Stopped sleep 100 [root@trial1 vagrant]# ps -o pid,state,command -p7144 PID S COMMAND 7144 T sleep 100 [root@trial1 vagrant]# fg %1 sleep 100 [vagrant@trial1 ~]$ ps -o pid,state,command -p7144 PID S COMMAND 7144 S sleep 100 |
将 sleep 命令替换成 yes > /dev/null ,上面实验的状态 S 会变成 R,其他一样。
综上,状态流转如下(再盗图一张):
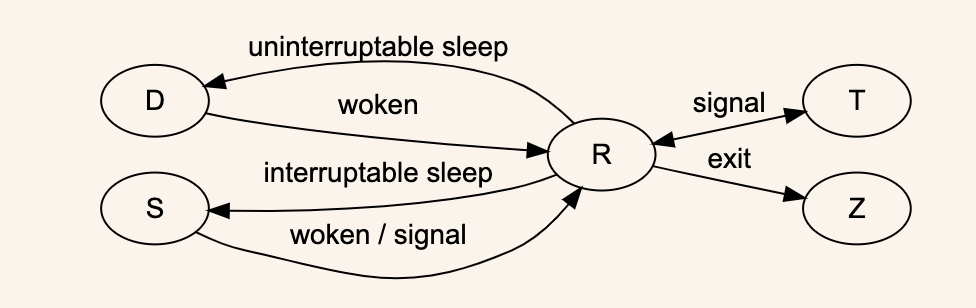
所有的进程状态,可以看下这个文档,介绍了源代码中定义的进程状态。
信号
上面介绍了一些信号,这里再列一些常用的:
- SIGCHLD:子进程状态改变;
- SIGCONT: 进程继续执行;
- SIGSTOP: 进程暂停,和上面的 SIGCONT 是一对;
- SIGTERM: 指示进程结束,这个信号可以被捕捉或者忽略,允许进程收到这个信号之后 gracefully exit;
- SIGKILL: 立即结束进程,收到这个信号的进程无法忽略这个信号,必须退出。但是 init 除外,init 不接受 SIGKILL;
- SIGINT: 从终端(用 CTRL+C)发出的终端信号。在一些 REPL 中会介绍当前的命令,也有些进程的表现是直接退出;
信号本质上是一中进程间通讯方式(IPC),Signal wiki。
以上就是基本的进程知识了,本文所有的参考资料已经在文中链接。这是我最近读 Linux System Programming 的笔记,如有理解错误,请指出。接下来还会分享一些有关 Linux 的文章。