自从认识了 CircleCI 之后,基本上都在用这个了。相比于之前用的 travis-ci,CircleCI 丑是丑了点,但是相比与 travis 有几点好处:
- CircleCI 基于 docker image 的,怎么做隔离的不太清楚,有可能是在虚拟机上面执行 docker 来做隔离的,而 travis 还是基于 VM。这样好的好处是,CircleCI 提供了很多 image,你可以组合出来很多服务。比如 Django 项目用到了 redis 和 MySQL,你只要在 yaml 里面加上这两个 image 就好了,而 travis 要在 VM 里面处理好服务依赖。不仅不方便,每次执行速度也慢很多。
- CircleCI 支持 private repo,travis 只支持开源 repo。
但要说缺点的话,CircleCI 用户体验实在不如 travis,配置比较复杂。每次用都会多少踩一些坑。这篇文章介绍一下一个 Django 项目接入的过程,和其中一些要注意的坑。
1. 设定好 Django 项目的测试和依赖
以前 Django 测试用的是 Django 自带的 manage.py 里面的 test. 后来发现还是 pytest 比较好:插件多、模板代码少些很多,fixture 的设计比较合理,测试中使用到 db 需要明确声明,否则无法 access db,这样更加 explicit,测试执行的速度也更快。
除了 pytest,其他的还有一些依赖,test-requirements.txt 文件的内容如下:
|
1 2 3 4 5 |
File: test-requirements.txt -r dev-requirements.txt factory_boy pytest-cov pytest-django |
其中 pytest-django 是 pytest 继承到 Django 中去了,pytest-cov 是追踪测试覆盖率的,factory_boy 是可以根据 Django 的 ORM 自动生产测试需要的 Model (这个强烈推荐,如果不用这个的话,需要写一推 json 来事先定义好测试用的 Model,后续维护也很费劲,如果改了一个不需要测试的 Model 的 Field,这些 json 也需要维护)。
然后运行 Django 测试,使用 pytest 命令就好了:
|
1 |
$ DJANGO_SETTINGS_MODULE = myproject.settings.testing pytest --reuse-db --cov-config=.coveragerc --cov=. --cov-report=html --junitxml=test-reports/junit.xml |
这个命令太长了,我们可以将环境变量和命令参数写到 pytest.ini 文件中去:
|
1 2 3 4 |
File: pytest.ini [pytest] DJANGO_SETTINGS_MODULE = easycron.settings.testing addopts = --reuse-db --cov-config=.coveragerc --cov=. --cov-report=html --junitxml=test-reports/junit.xml |
这样每次测试,使用 pytest 这个命令就可以了,参数和环境变量会自动设置。
解释一下每个参数是干嘛用的:
- 第一行是 Django 环境变量,用来区分测试使用的 django.conf.settings 和开发、生产用的;
- –resuse-db :pytest 测试复用DB,不必每次都创建然后执行 migrations,对测试执行速度的提升非常明显。但是在 CircleCI 上运行测试,由于每次 MySQL 都是一个新的镜像实例,所以还是要每次新建数据库,执行 migrations 的。这个参数只是在本地执行的时候有用;
- –cov-config / –cov :这个是追踪测试覆盖率的 coverage.py 使用的配置文件,和要追踪测试覆盖率的文件夹;
- –cov-report :生成测试覆盖率的格式,每次运行完测试之后,生成覆盖率测试的文件。在 CircleCI 上我们可以设置测试运行完之后将这些文件上传至 artifacts 上去,可以在浏览器看这些文件;
- –junitxml : 测试的 Summary,也可以在 CircleCI 上展示;
以上就是项目中测试的配置,现在运行 pytest 可以自动发现项目中的测试用例执行了,并且测试完成后会生成测试报告。
接下来介绍如何在 CircleCI 上配置,实现每次 git push 之后自动执行代码。
2. 在 CircleCI 开启 CI 和设置运行环境
接入的方式分两步,根据 CircleCI 的指引就可以:
- 用 Github 账户登陆 CircleCI,然后在 CircleCI 上导入 Github 的项目;
- 在项目中添加
.circleci/config.yml配置文件,git push,就会自动触发 CircleCI 的 build 了。
其中配置文件以我的这个项目为例,配置文件如下(基本上是拿 CircleCI 的配置模板修改了一下,保留了注释):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
# Python CircleCI 2.0 configuration file # # Check https://circleci.com/docs/2.0/language-python/ for more details # version: 2 jobs: build: docker: # specify the version you desire here # use `-browsers` prefix for selenium tests, e.g. `3.6.1-browsers` - image: circleci/python:3.7.1 # Specify service dependencies here if necessary # CircleCI maintains a library of pre-built images # documented at https://circleci.com/docs/2.0/circleci-images/ # - image: circleci/postgres:9.4 - image: circleci/redis:5.0.1 - image: circleci/mysql:8.0.12 environment: MYSQL_DATABASE: test_easycron_ MYSQL_ROOT_HOST: "%" MYSQL_USER: easycron MYSQL_PASSWORD: 123 command: [--default-authentication-plugin=mysql_native_password] working_directory: ~/repo steps: - checkout - run: name: install dockerize command: wget https://github.com/jwilder/dockerize/releases/download/$DOCKERIZE_VERSION/dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz && sudo tar -C /usr/local/bin -xzvf dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz && rm dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz environment: DOCKERIZE_VERSION: v0.3.0 - run: name: Wait for db command: dockerize -wait tcp://localhost:3306 -timeout 1m # Download and cache dependencies - restore_cache: keys: - v3-dependencies-{{ checksum "test-requirements.txt" }} # fallback to using the latest cache if no exact match is found - v3-dependencies- - run: name: install dependencies command: | python3 -m venv ~/venv . ~/venv/bin/activate pip install -r test-requirements.txt - save_cache: paths: - ~/venv key: v3-dependencies-{{ checksum "test-requirements.txt" }} # run tests! # this example uses Django's built-in test-runner # other common Python testing frameworks include pytest and nose # https://pytest.org # https://nose.readthedocs.io - run: name: run tests command: | . ~/venv/bin/activate pytest - store_test_results: path: test-reports - store_artifacts: path: htmlcov destination: htmlcov |
前面说过 CircleCI 是基于 Docker 的,它的一个好处就是:如果你需要 MySQL、Redis 之类的服务,只要在 docker 这里声明就好了,CircleCI 在启动测试的时候会帮你启动这些容器。
build:docker 这里的配置就是用到的服务,用到哪个配置就写上 CircleCI 的 image 就好了,常用的都有,比较丰富。后面的 steps 来定义 CI 的步骤,一些事先定义好的 steps 可以参考下文档, 比如 clone 代码之类的就不需要自己实现了。
但是这里有一些挺坑的地方,需要注意。
使用 CircleCI 官方 MySQL 这个 image 需要设置验证方式,不然的话会遇到以下这个错误:
|
1 |
E MySQLdb._exceptions.OperationalError: (2059, "Authentication plugin 'caching_sha2_password' cannot be loaded: /usr/lib/x86_64-linux-gnu/mariadb18/plugin/caching_sha2_password.so: cannot open shared object file: No such file or directory") |
MySQL,redis 等都不能通过 .sock 文件访问,访问的时候不要使用 localhost,使用 IP。因为本质上这不是在同一个 image 启动的,测试所在的容器并不会有这些服务的 sock 文件,实际上是启动了不同的 image 然后通过 docker 的 network 放在一组,实现了访问。
还有一个巨坑的地方是,有时候你依赖的服务还没准备好,测试就开始执行了。我用的时候发现有的时候访问 MySQL 端口不通,有的时候却是通的。解决的方式也很挫,就是 31-38 行,使用 dockerize block 住这个 step,不断检查端口是否接受连接了。端口通了才继续执行后面的步骤。
这里为了加快测试的执行速度,可以将创建的 venv 缓存起来,参考上面的 restore cache 和 save cache 那一步。需要注意的是 key 加上了 checksum,这样依赖文件更改的时候可以自动重新安装。有个小坑的地方是 CircleCI 竟然没提供删除 cache 的功能,所以我的 key 加上了 v3 ,如果想弃用之前的 cache 的话,只要升级到 v4 就好了,cache 找不到自动安装新的。
最后两步是上传测试 Summary 和覆盖率文件。效果如下:

test summary 展示
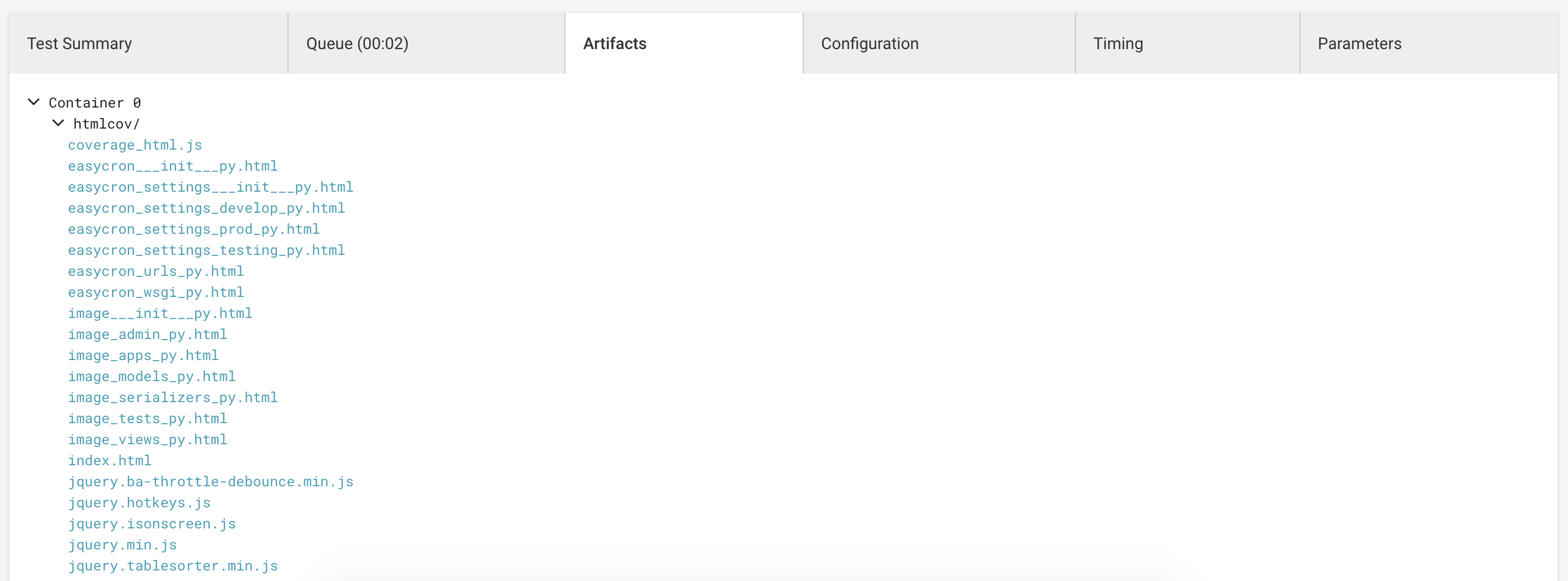
测试覆盖率文件
注意 venv 不要建立在 working_directory 下面,不然你的 venv 里面的库也会被追踪测试覆盖率。
最后再吐槽一下 Artifacts 没有自动打开 index.html 的按钮,每次都需要自己找到这个文件点开,有点反人类。