这篇文章介绍什么是 kernel space 和 user space,以及系统调用(System call,以下会用 syscall表示)。
为什么要分成 kernel space 和 user space 呢?
这要对系统对进程的抽象说起,每一个进程看到的内存空间都从固定的位置开始,main() 总是从 0x4005db 开始,stack 也总是从特定的位置开始。那么不同进程使用的内存都是重叠的吗?
当然不是。这就是系统对进程的抽象。每个进程只能看到自己的内存,MMU(内存管理单元)将解决每个进程看到的虚拟内存和实际物理内存的对应(内存管理是一个很大的话题,这里只是简单的描述,有关内存管理有很多资料可以参考,这里提供一个有趣的文章:Virtual Memory With 256 Bytes of RAM – Interactive Demo)。不仅仅是内存,每个进程只能使用有限的资源,而 kernel 可以使用所有的资源。当 user space 需要使用硬件资源时,user space 通过 syscall 告诉 kernel space,kernel space 来完成调用。
这样做的目的是将资源隔离开,确保 user space 崩溃不会影响 kernel space;以及限制 user space 所能做的事情,不能让程序可以随意进入 kernel space 进行任意的操作。怎么做到的呢?当计算机启动的时候,CPU 会进入 ring0,即特权状态,在一个地址设置好 syscall 的对应关系(这个对应关系可以在这里查),比如 1 对应的就是 write() syscall,然后 CPU 退出到 ring3,即 user space。再次进入 ring0 的唯一方法就是通过 syscall。syscall 要求传入一个 int 表示要调用哪一个 syscall,这样,kernel 就可以控制所能执行的动作,即只能执行事先定义好的 syscall mapping。
Syscall 和一般的函数调用是不一样的,这一点读者应该已经明白了。因为在程序内部,可以使用 stack 或内存在调用之间传值,但是 user space 和 kernel space 是隔离的(当然也可以通过共享的内存传值),stack 不是共用的。如果写一个简单的 write() 程序反编译,可以看到 syscall 的汇编代码是 mov exa, 1 syscall ,其中1就是前面我们说的 syscall mapping,即 write(),然后 syscall 是 user space 向 kernel space 发出的软中断,进入 kernel space,kernel 会检查 exa 寄存器的值,找到对应的函数执行。(不同的架构实现会有所不同)
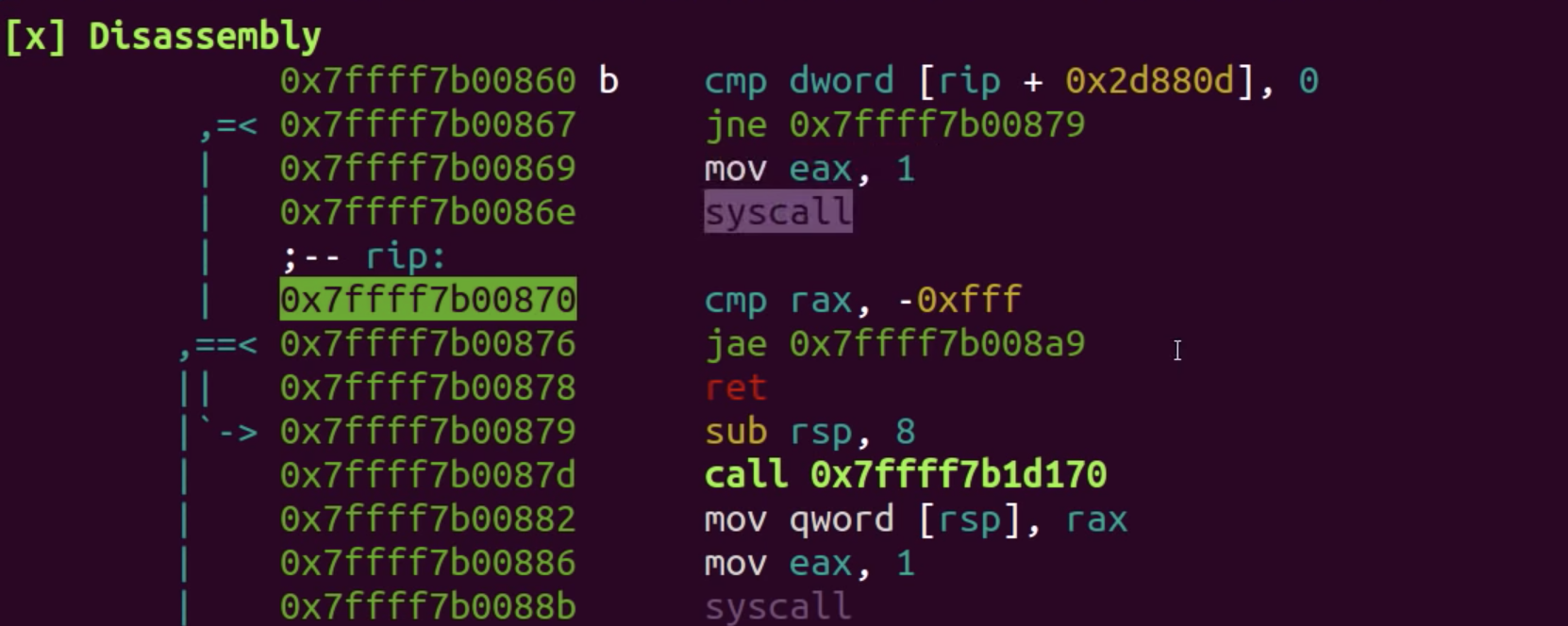
简单来说,kernel space 和 user space 是两个世界,syscall 就是连接这两个世界的桥梁。虽然这个桥梁我们一般不会直接使用,而是通过 glibc,glibc 是 syscall 的一个 wrapper,让我们 call 起来更加简单方便。比如说 printf 函数,其实就是 write() 的一个 wrapper。
通过 man 2 write 可以看到 write() 的原型如下:
|
1 2 3 |
#include <unistd.h> ssize_t write(int fd, const void *buf, size_t count); |
所以我们可以这么调用,向屏幕打印字符:
|
1 2 3 4 |
void main(){ // 1是stdout write(1, "hello syscall!", 20); } |
有关 syscall 大体就是这样。以上是我的理解,如果有错误欢迎交流。下面再介绍一些相关的工具。
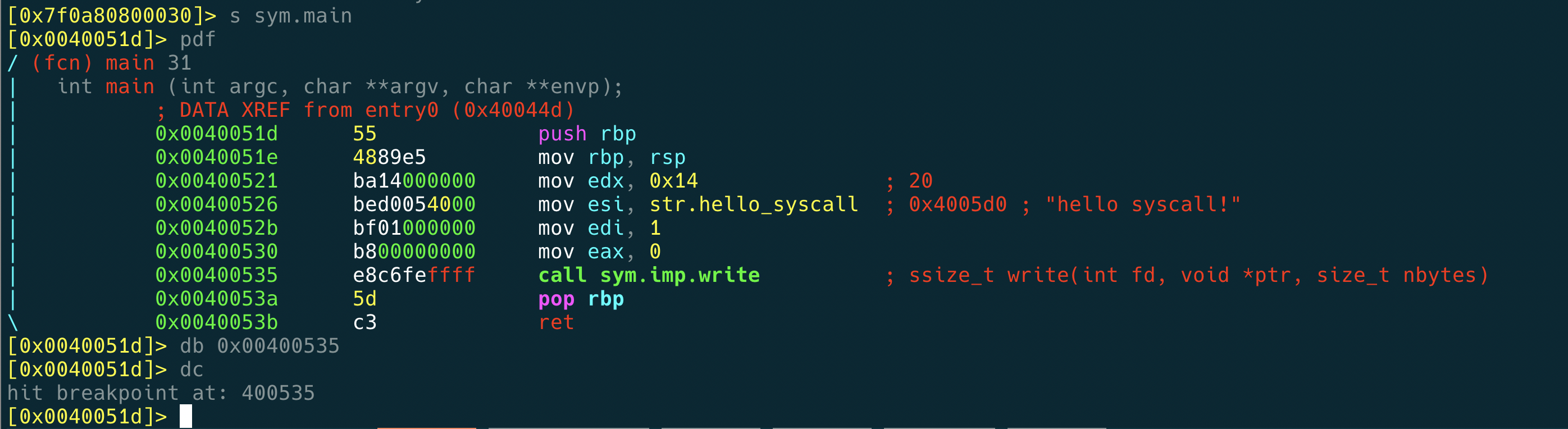
上面那张截图 radare2 的界面,一个反编译工具。使用方式是 radare2 -d ./a.out ,然后在s sym.main ,设置断点,可以看到 syscall 是如何执行的。
通过 man syscalls 可以查看系统提供的 syscalls. strace 工具可以将一个进程使用的 syscall 输出到 stderr,包括调用的参数,和返回值。比如查看 ls 使用的系统调用:
|
1 2 3 4 5 6 7 8 |
[vagrant@centos7 ~]$ strace ls execve("/usr/bin/ls", ["ls"], [/* 25 vars */]) = 0 brk(NULL) = 0x1574000 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fde7d373000 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3 fstat(3, {st_mode=S_IFREG|0644, st_size=25207, ...}) = 0 mmap(NULL, 25207, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7fde7d36c000 close(3) = 0 # 以下省略 |
-c 参数很有用,可以显示每次 call 花费的时间,call 的次数,占用的总时间等,是一个 perf 的好工具。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
[vagrant@centos7 /]$ strace -c ls bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 24.29 0.000034 17 2 statfs 9.29 0.000013 7 2 munmap 7.86 0.000011 1 13 close 6.43 0.000009 9 1 write 6.43 0.000009 0 27 mmap 5.71 0.000008 4 2 getdents 5.00 0.000007 1 10 open 5.00 0.000007 4 2 ioctl 4.29 0.000006 6 1 stat 3.57 0.000005 0 11 fstat 3.57 0.000005 0 18 mprotect 3.57 0.000005 2 3 brk 3.57 0.000005 3 2 1 access 2.86 0.000004 2 2 rt_sigaction 2.86 0.000004 4 1 openat 1.43 0.000002 2 1 rt_sigprocmask 1.43 0.000002 2 1 getrlimit 1.43 0.000002 2 1 set_tid_address 1.43 0.000002 2 1 set_robust_list 0.00 0.000000 0 8 read 0.00 0.000000 0 1 execve 0.00 0.000000 0 1 arch_prctl ------ ----------- ----------- --------- --------- ---------------- 100.00 0.000140 111 1 total |
参考资料:
- Linux System Programming
- Youtube: Syscalls, Kernel vs. User Mode and Linux Kernel Source Code – bin 0x09
- jvns 的这篇漫画:https://drawings.jvns.ca/userspace/