很多人对“速度”没有什么概念,同机房内 RTT (Round Trip Time)大约是多少?如果将一个应用内的函数的调用拆成两个应用 RPC 调用,将增加多少延迟?打印日志有多快,打印日志的多少会增加多少延迟?
之前看过 Jeff Dan(忘记在哪里看到的了)写一个叫 Latency Numbers Every Programmer Should Know 的东西,我费了半天劲,终于找到了。决定把它贴在这里,传播一下。原文如下,这是从这个 gist 看到的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
Latency Comparison Numbers (~2012) ---------------------------------- L1 cache reference 0.5 ns Branch mispredict 5 ns L2 cache reference 7 ns 14x L1 cache Mutex lock/unlock 25 ns Main memory reference 100 ns 20x L2 cache, 200x L1 cache Compress 1K bytes with Zippy 3,000 ns 3 us Send 1K bytes over 1 Gbps network 10,000 ns 10 us Read 4K randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD Read 1 MB sequentially from memory 250,000 ns 250 us Round trip within same datacenter 500,000 ns 500 us Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory Disk seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip Read 1 MB sequentially from disk 20,000,000 ns 20,000 us 20 ms 80x memory, 20X SSD Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms Notes ----- 1 ns = 10^-9 seconds 1 us = 10^-6 seconds = 1,000 ns 1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns Credit ------ By Jeff Dean: http://research.google.com/people/jeff/ Originally by Peter Norvig: http://norvig.com/21-days.html#answers |
有意思的事实是,CPU 的 Cache 到内存的操作都是纳秒级别的,同机房的 RTT 和 SSD 的读写速度在一个量级,机械硬盘比 SSD 慢20倍,比内存慢80倍。
以上的数据是2012年的,技术在发展,这个网页也可以拖动滚动条对不同年代的时间做可视化。2005年之前,CPU和内存的速度在飞速发展,但是2005年之后基本停滞了,之后是网络带宽、硬盘(SSD)快速发展。

https://people.eecs.berkeley.edu/~rcs/research/interactive_latency.html
这个网站可以看各个城市的延迟:https://wondernetwork.com/pings/
哦对了,说到 ping,我清明节的时候写了一个小工具 pingtop,可以同时 ping 多个 server 并在终端展示出来,喜欢的同学请点个赞❤️。
最后贴一张有人画的形象化的版本。
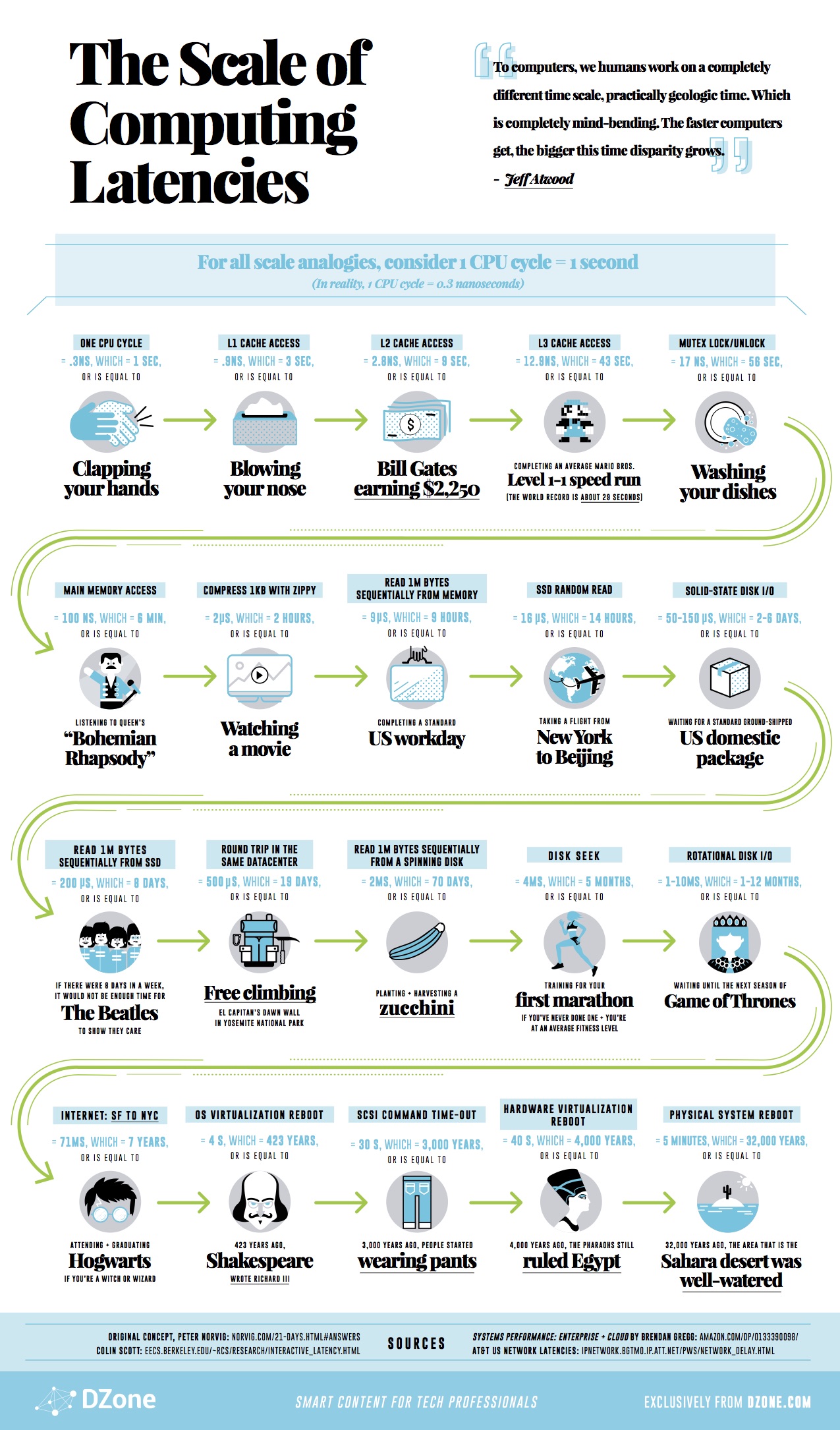
其他相关的阅读:
- Jeff Dan 的一个分享 http://videolectures.net/wsdm09_dean_cblirs/
- Teach Yourself Programming in Ten Years (我搜这个时间表的时候搜到的,这篇文章值得一看 ——为什么大家都这么着急呢?)