最近在 HN 有一篇《Cli improved》比较火,讲的是一些命令行工具的增强版,我觉得比较好,替换掉了我之前用的一些工具,在这里分享一下。内容基本上是从原文中意译过来的。
首先本文要介绍的工具基本都是原来工具的增强版,也就是说原来工具有的,增强版也都有。因为习惯很难改变,所以完全可以用 alias 替换掉。但是如果某些情况下想用原版的程序的话,可以使用下面的命令:
|
1 2 |
\cat # ignore aliases named "cat" - explanation: https://stackoverflow.com/a/16506263/22617 command cat # ignore functions and aliases |
安装方法我就不说了,Mac 所有的软件都可以通过 brew 来安装,Linux 参考项目主页吧。
bat 替换 cat
cat 做的事情就是把文件内容打印出来,但是没有颜色高亮,很不方便(没有颜色我基本看不懂代码 > <)。ccat (Go语言写的)是有颜色的 cat。但是 bcat 不仅有颜色,还有行号、分页、git 加加减减的整合、类似 less 那样的搜索。下图是我自己的展示,最后两行带 + 的是新增的行,非常酷炫。
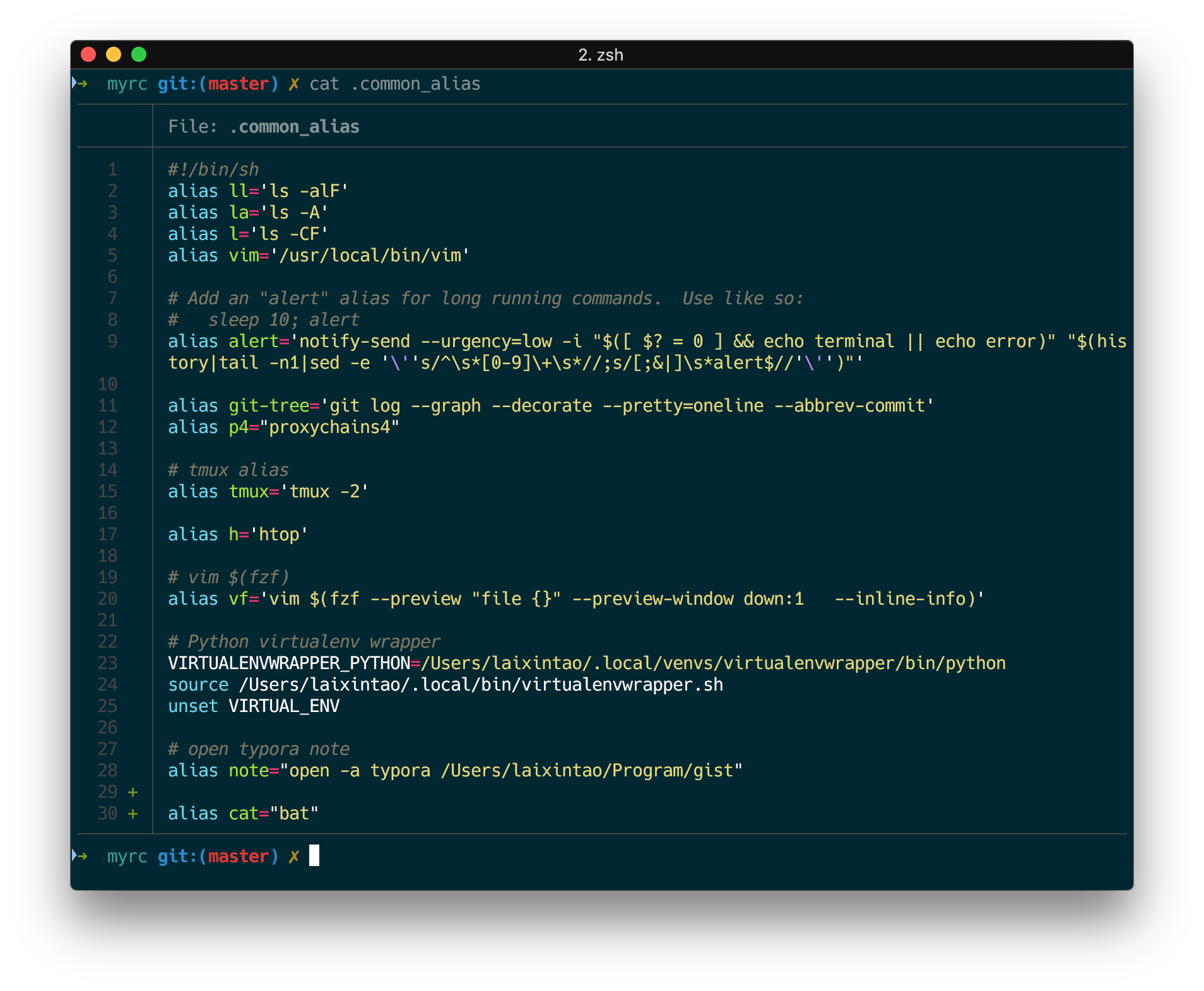
建议 alias cat=bat 。
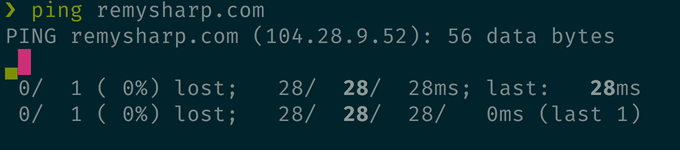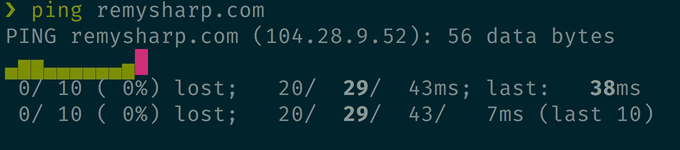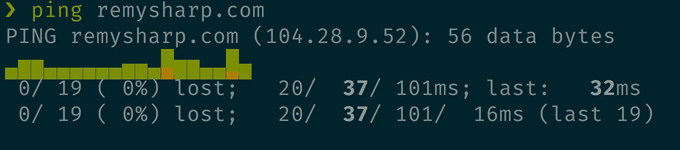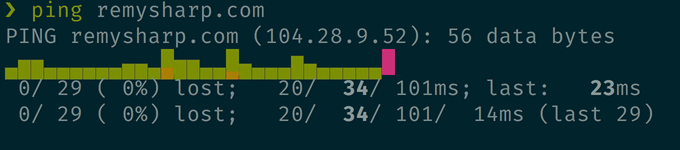
prettyping 替代 ping
这个不用多介绍了,直接看下效果吧。
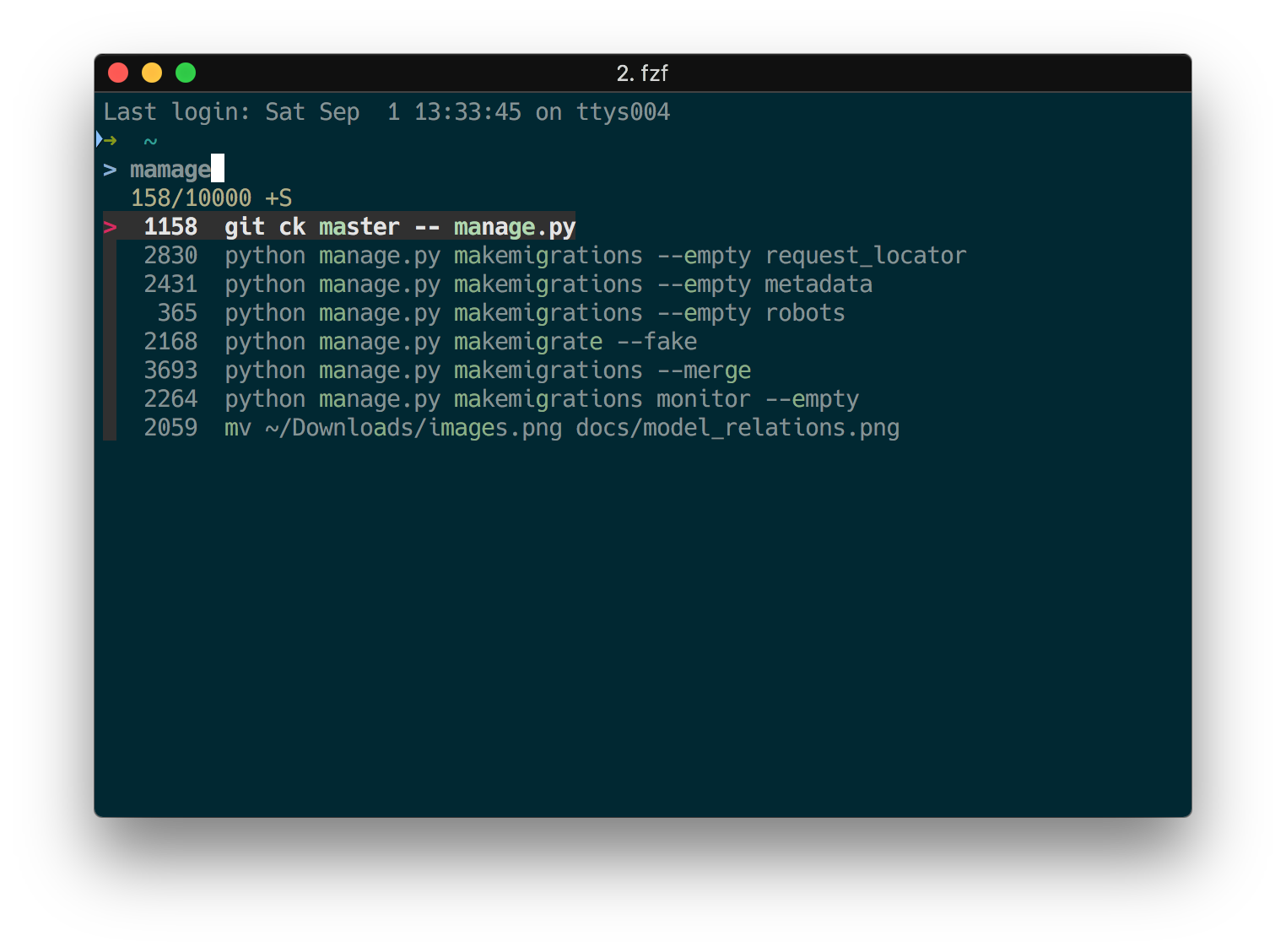
fzf 替换 Ctrl+R
Ctrl+R 可以在 history 搜索命令,不过用起来很反人类。fzf 使用效果如下,非常方便,从此再也不用畏惧长命令了。
除了查找历史命令,fzf 可以用来模糊查找文件,也很好用,直接设置一个命令,fzf 查找的结果调用 vim 编辑,效率很高。
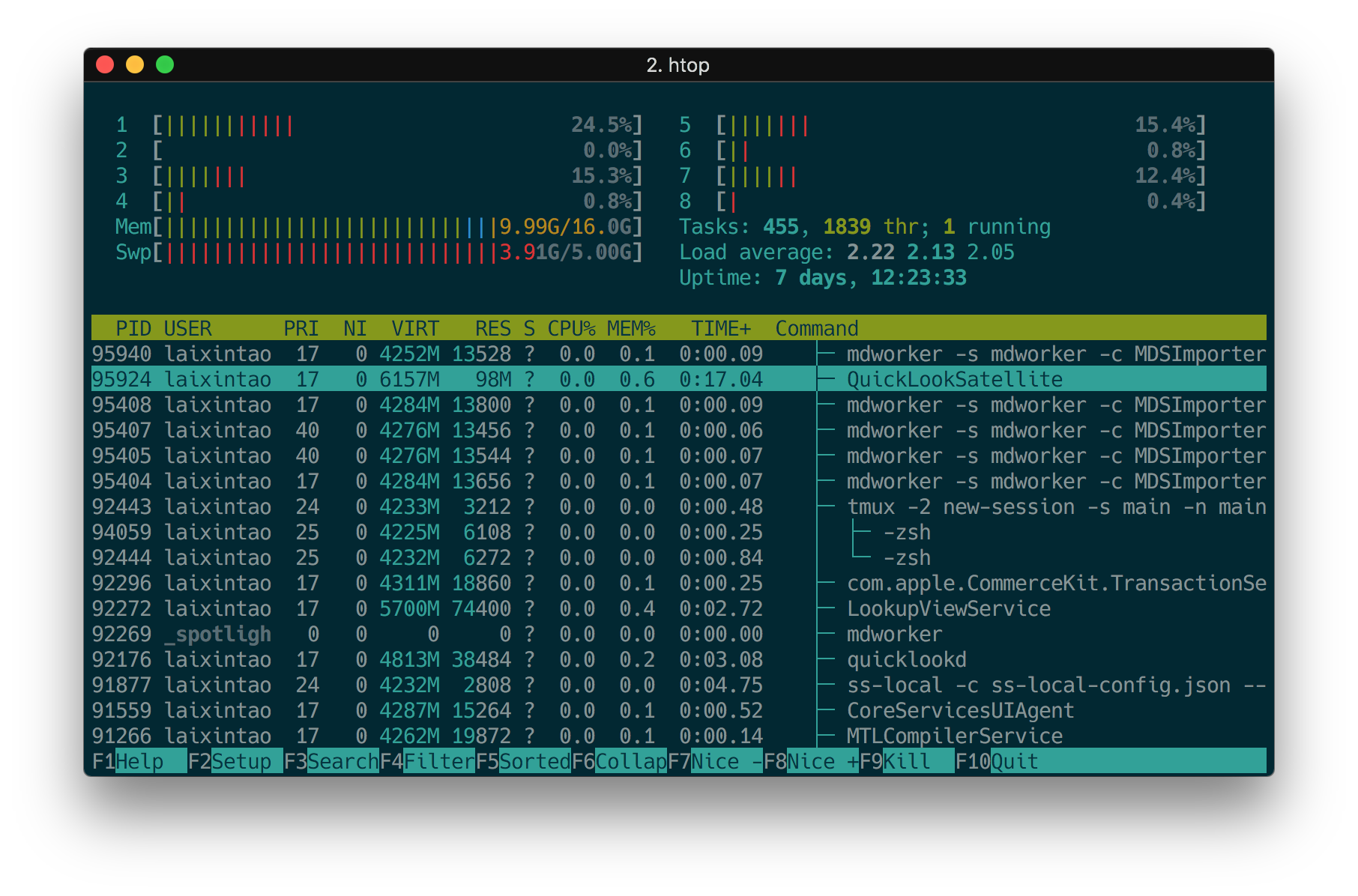
htop 替换 top
这个应该很多人都知道,htop 提供的信息更明确,熟悉了快捷键效率很高,比如按 P 按照 CPU 排序,t 展示树形,k 来 kill 选中的进程等等。
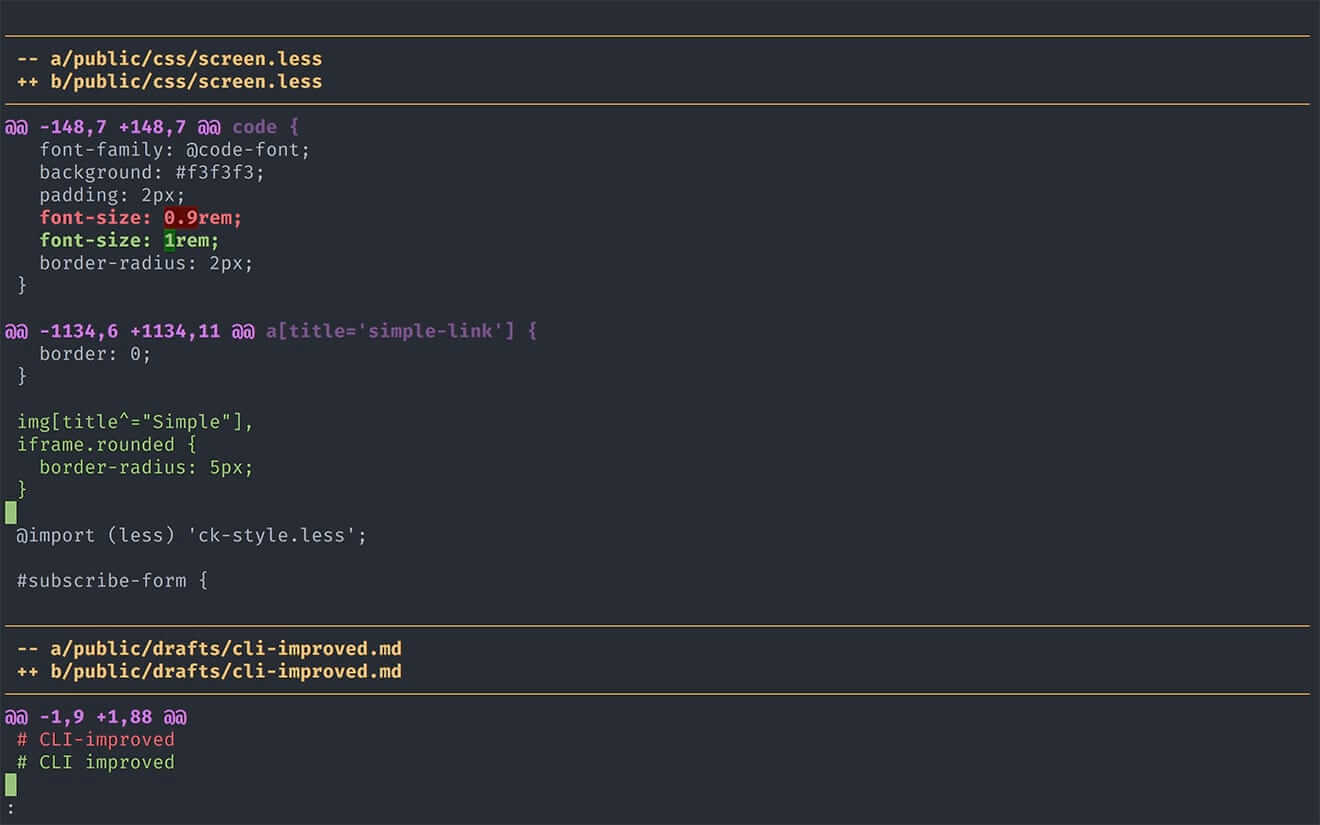
diff-so-fancy 替换 diff
diff-so-fancy 带有高亮,代码的变更等,配合 git 使用可以让你的 git diff 显示效果和 github 上面的 diff 页面一样。
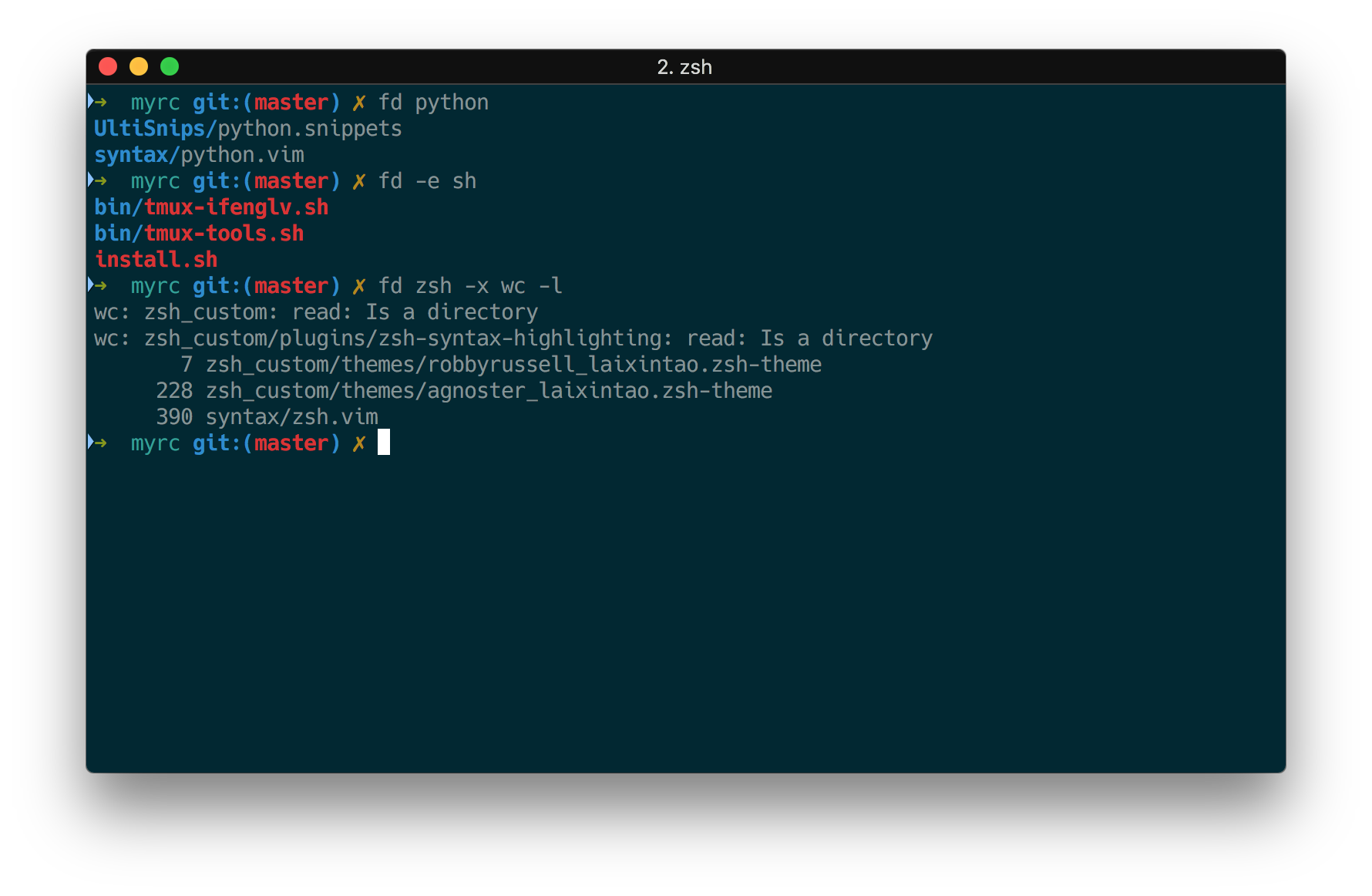
fd 替换 find
又一个 Rust 写出来的好东西:fd。find 的语法太难记了,fd 好用很多,显示还带高亮。效果如图。
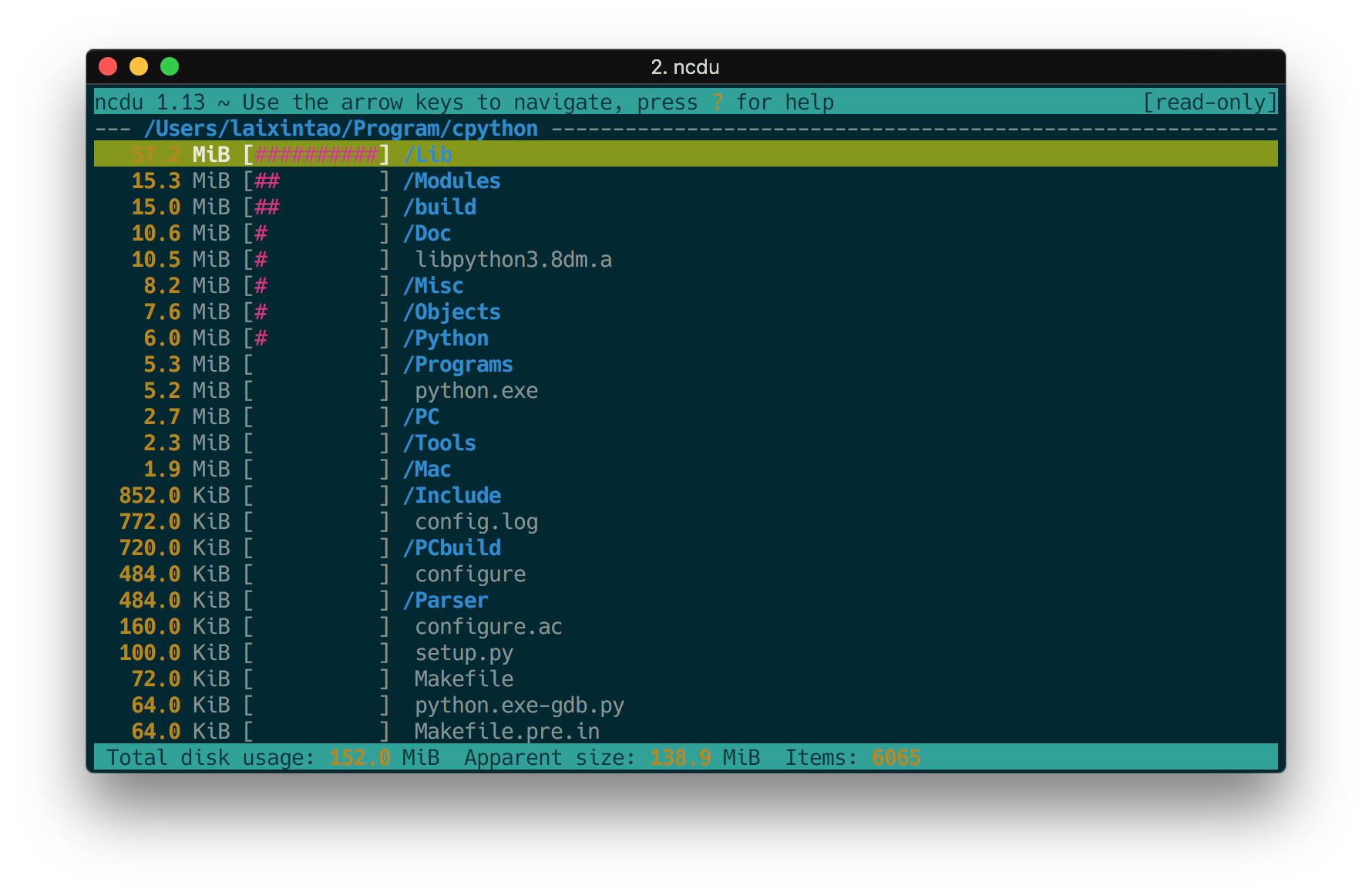
ncdu 替换 du
ncdu 将参数配置好,显示的效果如下。我用的是原作者的的 alias,文件夹是 CPython 的源代码。
|
1 |
alias du="ncdu --color dark -rr -x --exclude .git --exclude node_modules" |
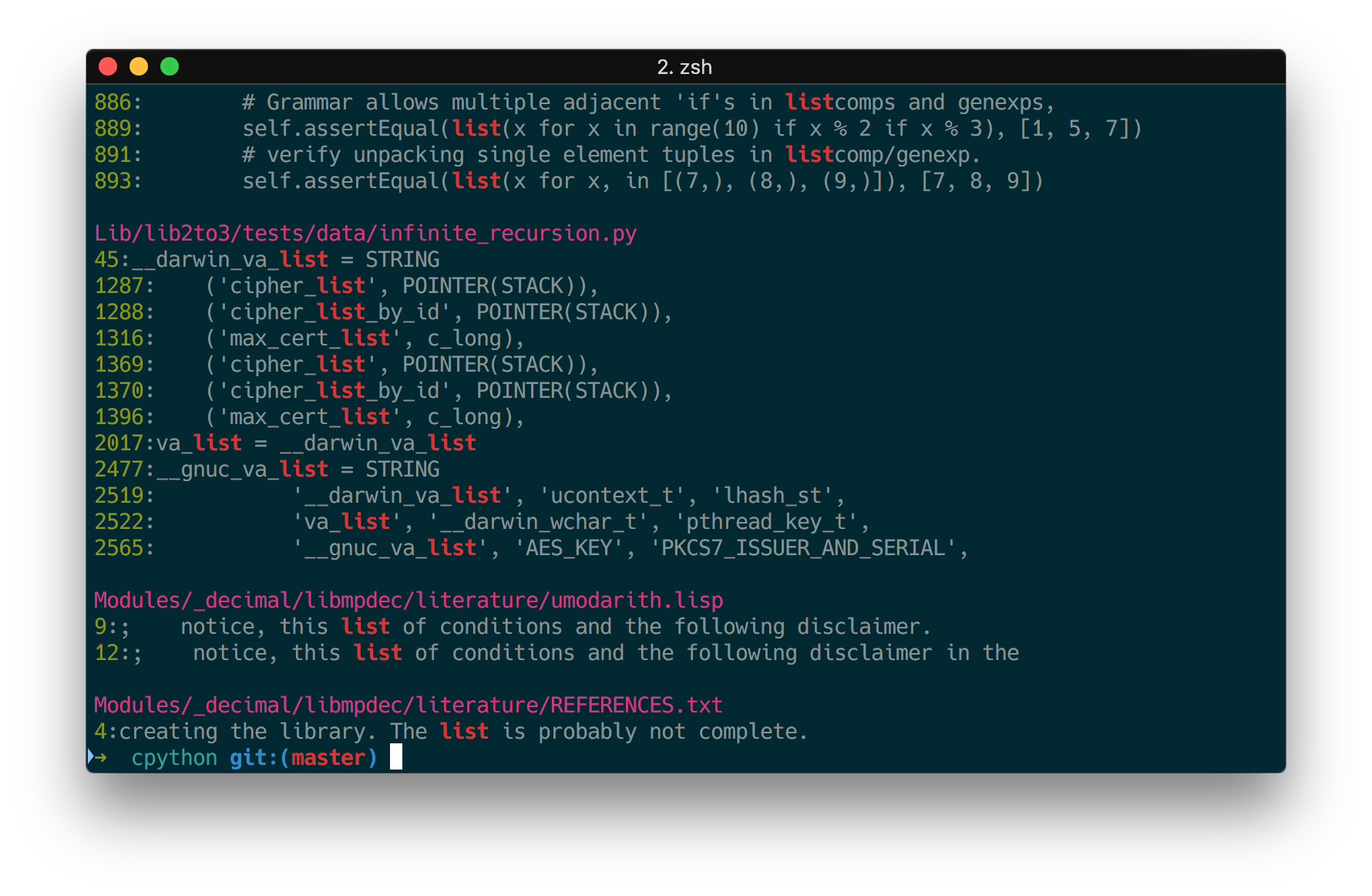
Ack 或 ag 替换 grep
这俩我都没用过,介绍一个我用的 rg 吧,主要是速度快。效果如下:
jq
操作 json 的一个命令行工具。再也不用组合复杂的 sed,awk,grep 来处理 json 了,我不确定是不是 jmespath 的语法。教程可以看下官方的,很好学。
类似的 for csv 的有一个叫 csvkit。
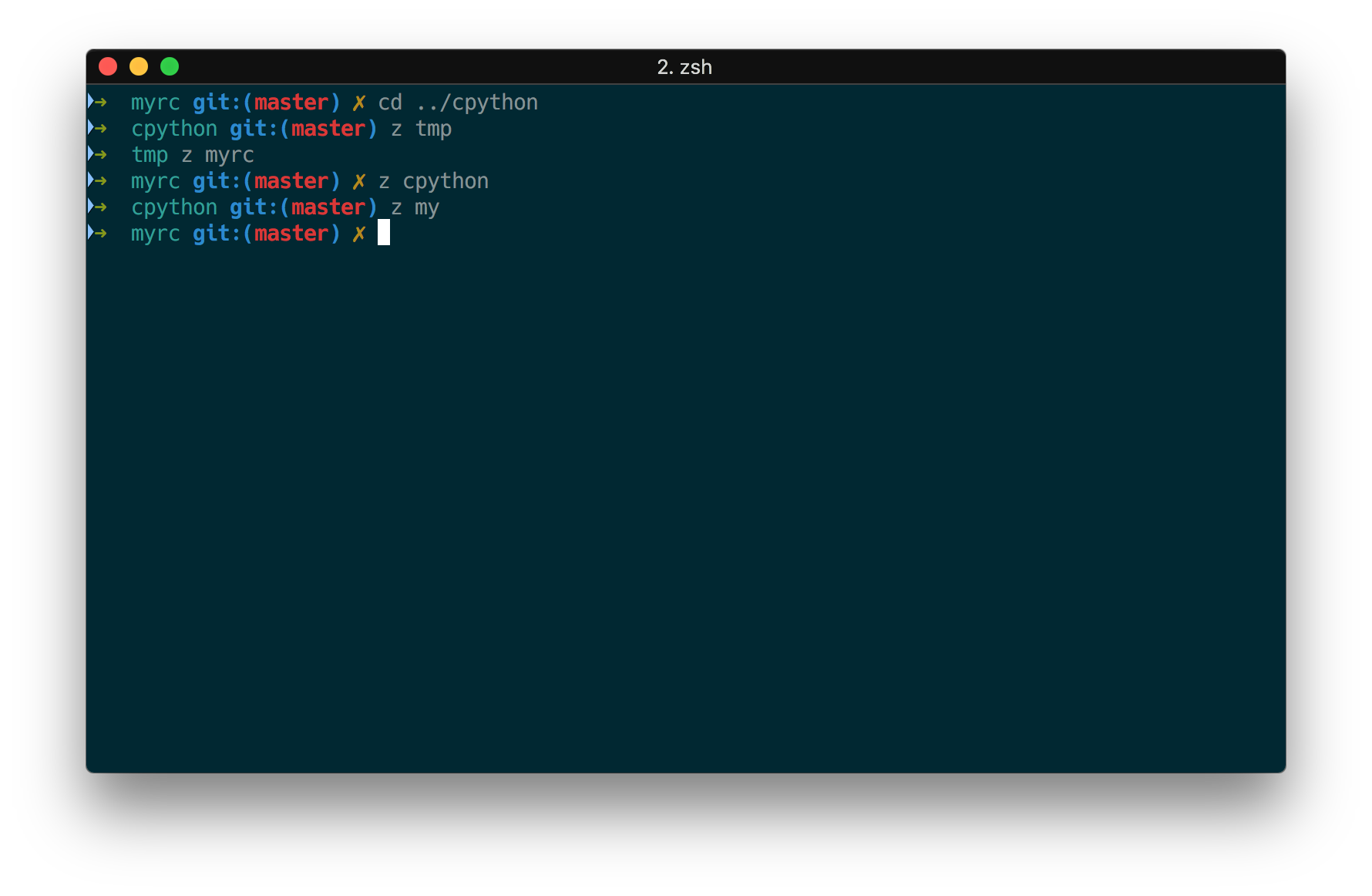
z
一个根据你的路径历史来 fuzzy 跳转的东西,有一个竞品叫 autojump。不过我习惯了用 z 了,用了很久没有什么痛点。使用效果如图。
fpp
根据前一个命令的输入,自动识别输入中的文件名,然后可以使用快捷键打开。
比如 git status | fpp 的效果如下:
lnav
lnav 是一个日志查看工具,是一个 TUI 工具。
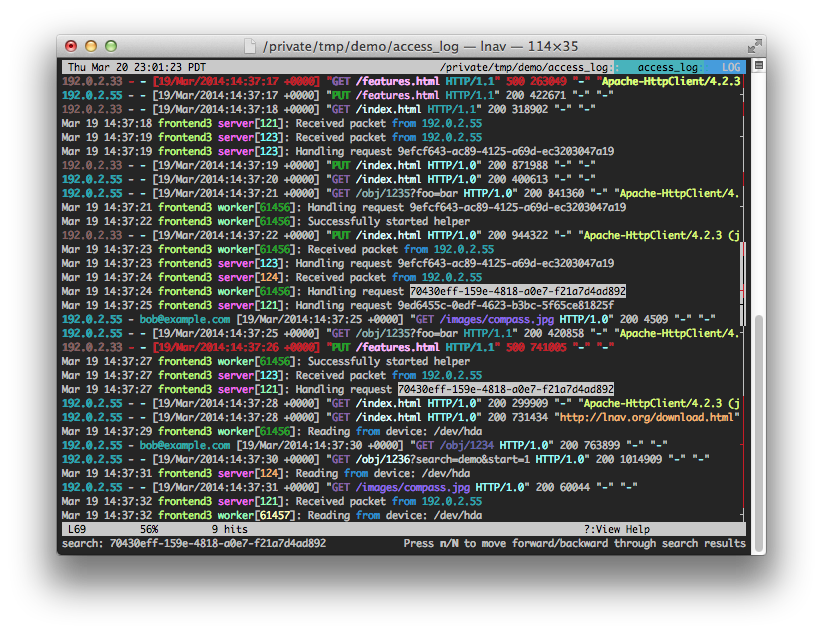
如上图所示,它的好处是处理了折行,对于长行的日志看起来是非常友好的。而且自动高亮了不同的内容,我们看日志的时候就可以方便地忽略每一行相同的部分,快速发现日志中的异常点。相比于 Vim,Vim 打开日志的话会有很多问题,是很危险的操作,因为 Vim 会将整个文件加载到内存,而 lnav 是用了 lseek 不会一下子占用很多内存。
未完待续…… 不定期更新,欢迎补充。