今天看 antirez 写了一篇有关客户端缓存设计的想法:《Client side caching in Redis 6》(文章比较难懂,如果先看 Ben 演讲,理解起来 antirez 这篇博客会轻松一些)。antirez 认为,redis 接下来的一个重点是配合客户端,因为客户端缓存显而易见的可以减轻 redis 的压力,速度也快很多。大公司或多或少都有实现这种应用端缓存的机制,antirez 想通过 server 端的一些设计来减少客户端缓存实现的复杂度和成本,甚至不惜在 redis 协议上做修改。
antirez 的博客对细节介绍的比较清楚,我这篇文章算是拾人牙慧了,一来理清一下自己的思路,二来我认为除了缓存,这个机制还可以用在实时控制应用程序的某些配置上面。跟大家分享一下。
一、缓存的数据一致性问题
通常我们谈论缓存一致性的时候,一般在谈的都是这种架构:应用有一个数据库和缓存,数据库中的常用数据会被放到缓存中,在这种场景下如何保证数据库的数据和缓存中的数据是一致的?这种其实比较好解决,Cache-aside 模式已经是比较成熟和通用的了,实现上也比较简单和可靠。
Remember kids: you either have a single source of truth, or multiple sources of lies.
但 Redis 这种缓存从某种意义上还是一种远程的缓存,每次缓存读取会增加一次 TCP RTT(这个影响个人认为随着技术发展会逐渐减少),数据的序列化和反序列化也需要资源。如果对效率有更高的要求,就要考虑进程内缓存了。
进程内缓存的数据一致性比分布式的缓存面临更大的挑战。一个进程更新的时候,如何通知其他进程也更新自己的缓存呢?如果按照分布式缓存的思路,我们可以缩短缓存过期时间,进程内缓存如果过期了就去分布式缓存获取数据。这样不必实现复杂的通知机制,但是不同进程内的数据依然会面临不一致的问题,并且不同进程缓存过期时间不统一,用户体验也不好,同一个请求到了不同的进程,可能出现反复幻读的情况。另外也会对分布式进行大量不必要的更新,浪费网络资源。
进程内缓存面临2个主要的问题是:
- 保证数据的一致性,包括各个进程缓存的数据要是一致的,进程缓存和 Redis 缓存要是一致的;
- 尽可能减小网络压力;
为了实现所有进程的缓存的一致性,显而易见的实现是,当一个 key value 被修改了,广播被修改的键值对。所有客户端收到广播的时候更新自己的 kv。这种实现的缺点是1)有可能一个进程收到两个冲突的广播,无法解决。2)广播键值对,这样修改缓存的代价太大了。基于这两点,可以想到优化方案是我们只广播更新的 key,Redis 的缓存最为 Source of Truth,客户端收到了 key 更新的消息,就去 Redis 获得最新的键值对。这样就解决了冲突的问题,对资源的消耗也少了。
这里还可能存在的问题是:业务为了避免 key 冲突,通常会把 key 的名字写的很长:project:app:username:lastlogin 。这样 debug 起来也很简单。Redis 的 Key 长度限制是 512M,“如果一个问题有可能发生,那么它就一定会发生”。另一个问题是即使其他进程缓存了 key 但是用不到,也要立即去 Redis 获取最新的 value,也浪费了资源,当然这里可以用类似 Cache-aside 的策略,收到 key 即删除,下次用到的时候再取,这个问题不大。
所以 Ben 视频中提出了一个很有创意的实现。这里是借鉴了 Redis Cluster,所以我们先跑个题:Redis Cluster 是将 key Hash 到不同的 slots,每个 Node 都保存一个范围的 Slots(Shared nothing),当读请求过来的时候,对这个请求的 key Hash 计算 Slot,然后根据 Slot 去对应的 Node 寻找这个 Key。
基于这个 idea,为了节省空间(同时节省广播 Key 的网络资源和处理 Key 更新的资源),每一个 key 都属于一个 slot,在 key 更新的时候,我们只广播更新了这个 key 所在的 slot:“嘿,这个 slot 更新了,你不用管 slot 里面哪一个 key 更新了,只要你的 key 在这个 slot 里面,那就去读 Redis 里面的数据吧,进程内缓存的数据已经脏了!” Slot 是 2bytes,比 key 小多了,可以节省很多网络资源。
空间是节省了,随之而来的问题是更新逻辑变得复杂。如果广播 key,那客户端收到 key 即删除,下次从 Redis 取就好了。收到的是一个 slot 呢?Slot 是单向的(因为 hash 是单向的),有 key 可以计算出 slot,有了 slot 可不知道这个 slot 能包含哪些 key。
计算遍历所有的 key 吗?命中脏 slots 的话,就删除这个key?但是这样的话相当于对每一个缓存更新操作,客户端都要遍历计算一遍自己所有 key 的 slot,显然是不可接受的。
这里也是采用惰性计算的思想:客户端收到了 slot 更新的广播,只把 slot 存起来,当真正用到在此 slot 中的 key 的时候才去 Redis 更新。那么就会有这样一种情况,slot 中部分 key 更新了,部分 key 没有更新,如何区分开哪些 key 已经在 slot 更新之后更新过了呢?这里只要记一下 slot 更新的 timestamp 就可以,每一个 key-value 也带有一个 timestamp 属性。如果 key 的 timestamp 早于 slot 的 timestamp,那 key 就是需要更新的;更新之后 key 的 timestamp 就晚于 slot 的 timestamp 了。下次可以直接用。
客户端内缓存需要保存的内容,增加了 slot 和租后修改时间,kv 也增加了 timestamp 保存从 Redis 获得缓存的时间,用来判断这个 key 是否脏了。
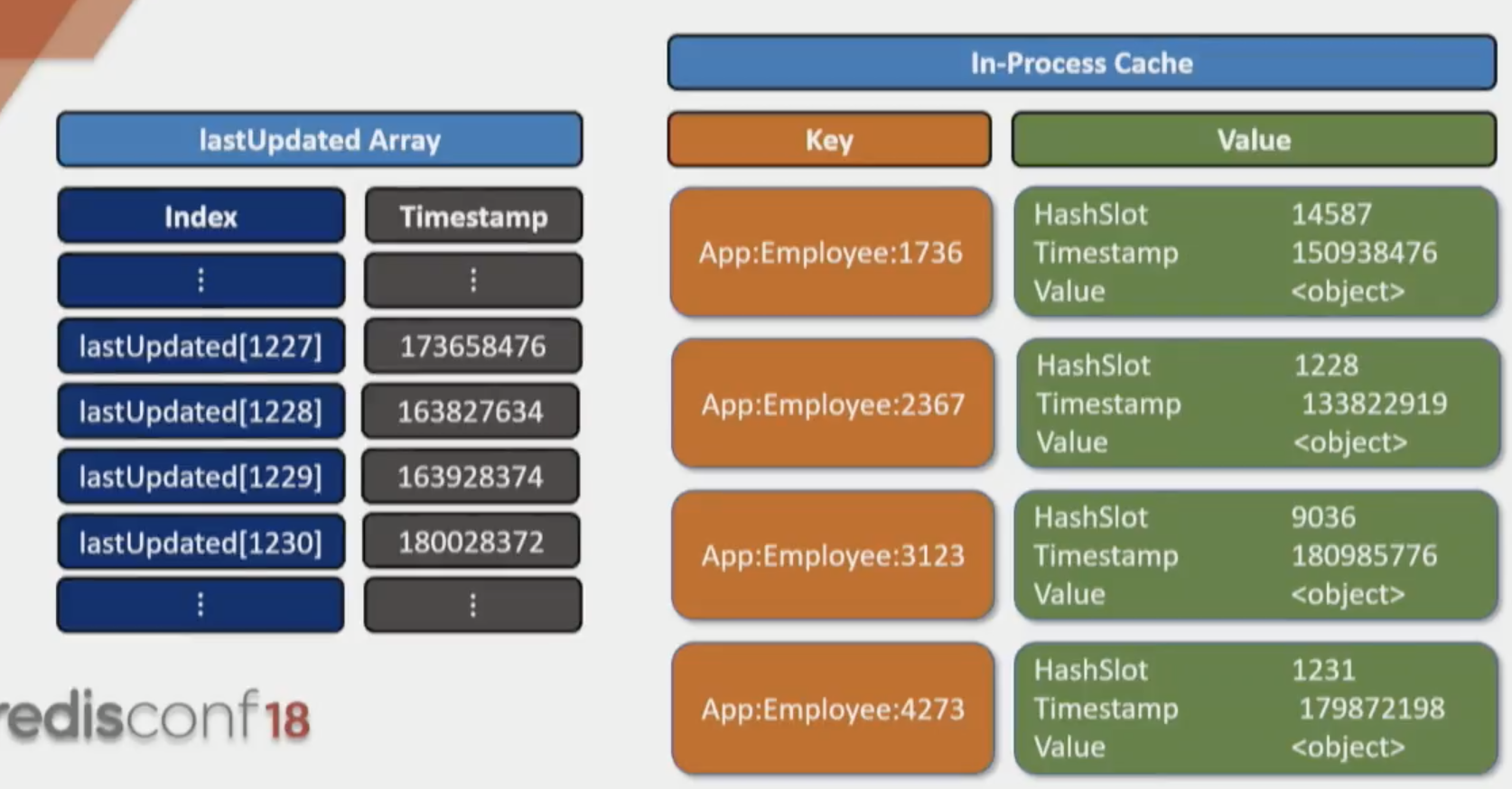
读缓存的流程:先将 kv 的 timestamp 和 slot 的 timestamp 对比,看 key 是否已脏。
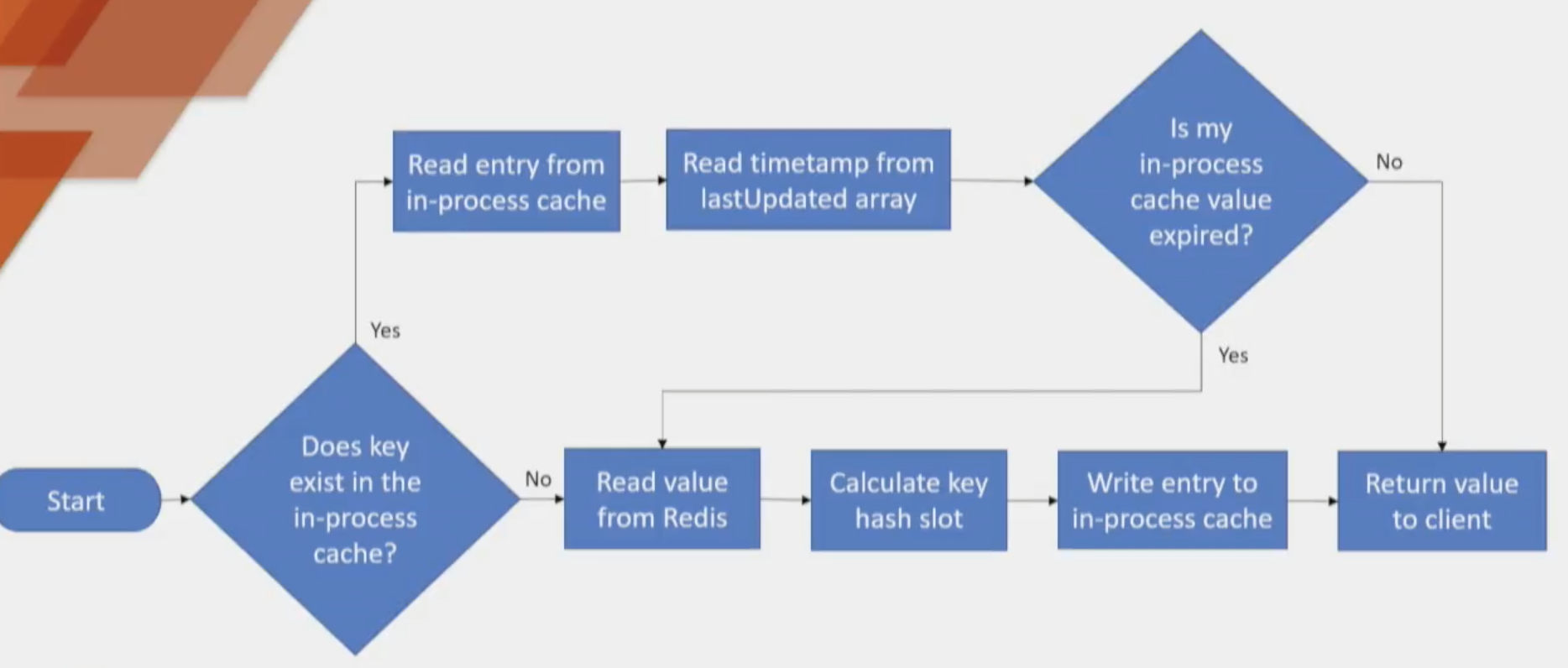
写操作比较直观,先写到 Redis,再写到 in-process cache,两个都洗完之后返回客户端缓存更新成功。

这里还有一些 tricky 的情况:我更新了一个 key,刷新了这个 key 的 timestamp,同时又收到了这个 key 所在的 slot 更新的消息。这时客户端如何处理这种情况呢?以自己更新的为准还是收到的 slot 信息为准?这个问题可以用 Master clock 时钟同步或 RedLock 来解决,但是从并发性和系统复杂度方面讲,两个都不是最好的办法。
这里有一种无锁的实现,通过操作的顺序来保证数据一致,非常巧妙,实现的几个要点如下:
- 所有的 timestamp 都是 server local timestamp:获得了 slot 更新的消息,将 slot 的更新时间设定为当前 local timestamp;进程更新 key 了,进程将 key 的更新时间设定为 local timestamp。实际上,timestamp 已经当成一个相对于本地 server 的偏移量来用了,无论是不同进程之间的时间如何偏移不准,都没有影响;
- 必须先更新 Redis,Redis 更新完成之后再发布更新消息(再次强调,Redis 作为 Source of the Truth);
- 在更新 Redis、in-process cache 之前就获取 timestamp,这一步很关键。这里解释一下为什么要先获取 current timestamp 再进行更新:其根本目的是 slot、key 的 timestamp 就尽量提前。如果在 Get current timestamp 之前收到了 slot update message,那么我们的更新操作一定发生在其他进程的更新操作之后,没有毛病;如果在 Get current timestamp 之后收到了 slot update message,那么不管如何,我们的 key timestamp 会落后收到的 slot timestamp,会去 redis 获取,也没有毛病。假设这里先更新完再获取 timestamp,会有这么一种情况:我们更新好了 in-process cache,这时候来了一条 slot update message,我们更新了这个 slot 的 timestamp,然后我们自己的更新操作到了获取 timestamp 这一步,我们记录了自己的 key timestamp 和 slot timestamp。就造成了我们的 key 更新时间实际上晚于真正的 key 更新时间,我们保存了一个过时的 key 却不知道。
以上说的有点啰嗦,总结一下:我们总是更新完 redis 缓存在发送同步消息,这样其他进程收到消息的时候,Redis 总是保存了最新的缓存;通过提前获取时间来保证了本地更新缓存和收到缓存更新时的冲突(倾向于认为自己的数据过时),并且没有锁、没有时间同步要求、不会保存了一个过时的 key 却认为是最新的。
最后其实还有一种非常极端的情况,但是有出现的可能,我觉得作者这个解决方法很牛,所以也说一下。
这个情况就是在一个 timestamp 分辨率下,我更新缓存,但同时收到了 slot 更新的消息。即我的 key 的 timestamp 是 a,但是在 a 这个 timestamp 的同时其他进程更新了缓存,这个时候 timestamp a 依然是正确的,但其实缓存住的是一个过时的 key。其实这个发生的概率太小了,timestamp 的精度是 300ns 的话,必须在 300ns 内更新完 redis 缓存和 in-process 缓存,收到 sync 消息,才有可能发生——但是依然有概率发生的。
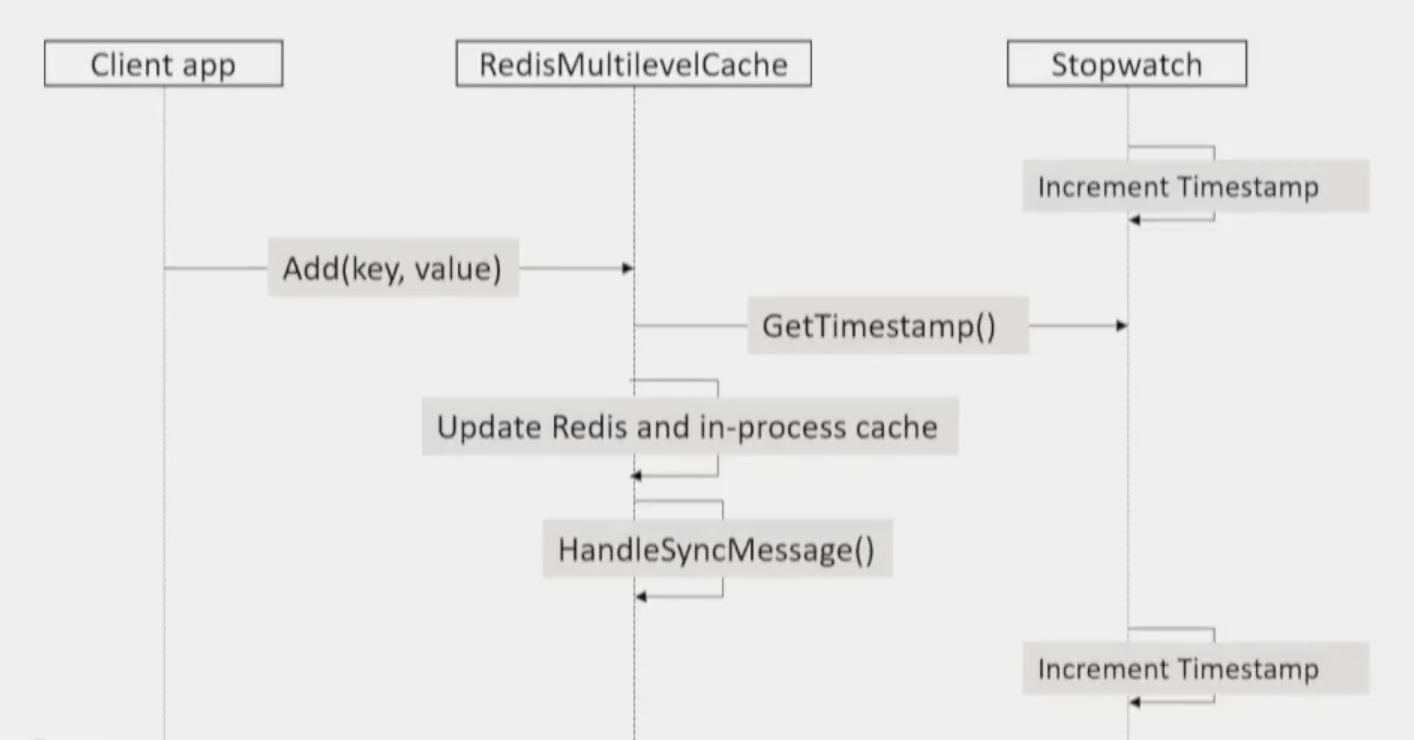
解决的方法很聪明:GetTimestamp() 之后总是 -1(其实不必-1,减一个 timestamp 精度就可以).这样就保证收到 sync message 我总是倾向于缓存脏了,去 redis 获取。如果发生一个 timestamp 进度内出现缓存更新和收到 sync 消息,那么我实际缓存更新的时间肯定晚于其他进程更新缓存的时间,因为我把我的表调快了嘛,所以我保存的 key 是新的。
最后的方案还有一些小问题:如果 pub/sub 出现了网络问题,那么情况就退化成等待缓存过期的情况了。Pub/Sub 本身在 redis 中就不是可靠的,可以通过 Stream 或其他可靠的机制来替代。
Well well,以上就是在现有的 Redis 实现客户端缓存的一些设计,这个设计源自 Redis Conf 的演讲。Antirez 认为这个方法非常好,所以想在 Redis Server 端做一些支持。
二、Redis 6 客户端缓存加强
注意上面讲的都是 Client 端所做的实现,对 Redis Server 并没有任何改动,这意味着,使用当前的 Redis 完全是可以实现的。这个实现存在的问题有:
- pub/sub 不可靠,如果 sub 掉线,pub 端和 Server 并不做任何承诺,这个上面说过的;
- 广播的是 slot 信息,slot 中如果有一个 key 更新了,那么整个 slot 都认为脏了。一共有 16384 个 slot,这意味着如果我们有百万级别的 key 数量的话,将平均几百个 key 共享 slot,这样的话变脏的几率是很高的。这是一种 Trade off 吧,一个 slot 占用 16bit,16384 个 slots 一共占用 64Kib 的数据。毕竟客户端的的目的是最大程度的利用缓存;
- 一个 slot 更新的消息,Server 要广播给所有的客户端,及时那些客户端并没有缓存这个 slot。这是因为服务端无法知道哪些客户端缓存了哪些 slots;
以上的问题,只有在 Server 端参与的情况下才可以更好地解决。所以 Redis 6 会实现 “Server-assisted client side caching”。
关于问题2和问题3:Redis 的 Command Table 里面会标记出来 Read Only 的命令,当客户端发送了 Read Only 的命令,比如 MGET,Server 除了返回响应之外,还会记住这个客户端读取了这个数据(数据所在的 slots)。这样 Server 会保持追踪哪个客户端缓存了哪些 slots,在 slot 变脏之后,只通知缓存这个 slot 的客户端。
实现的方式是保持一个很大的指针数组,每一个指针指向一个 Linked List,代表缓存了一个 Slot 的客户端列表。
|
1 2 3 4 5 6 |
slot1 -> client1 -> client2 -> client5 slot2 -> client2 slot3 -> null slot4 -> client9 -> client1 -> client2 ... slot16777216 -> client23 -> client24 |
每一个 client 都有一个 unique ID,第四行就表示,client 9,1,2 读取了 slot4 中的数据。client假设 slot4 中的 key 更新了,那么 Server 将会把 Slot 更新的信息发送给这三个客户端。这样就解决了问题3,无意义的消息推送问题。
这个指针数据有多大呢?首先这里的 slots 数量比 Ben 的方法多很多,这里使用的是 CRC64 的 24bit 输出,那就是 2^24 个 slots。指针是 64bit 指针,即 64bit ** 2^^24 = ~130Megabyte。Antirez 认为服务端这些内容是是值的,这解决了很多 key 共享 slots 的问题,就算有千万级别的 key,也只有两三个 key 共享 slots,散列度很高。
有2点需要注意:客户端可以重新 match 这些 slots,服务端是 16million 个,客户端可以使用更少,收到 slots 信息自己做 mapping;这个 feature 可以选择开关,通过 CLIENT TRACKING on 来打开。
关于问题1:Antirez 建议客户端感知连接的断开,处理好重连的情况;建议有一个 Thead 来 ping connection 确保连接存活。Redis Server 为了尽量减少影响,以及方便客户端的实现,还会通知其他客户端:请转发此消息(slot invalidation)给掉线客户端。
另外这样的实现在 Redis 协议里面有些冲突,客户端调用 block 命令收到的回复和收到的 slot push message 回复如何区分?Antirez 直接没有提复杂的实现(比如从 Response 中添加额外的信息标志这个是正常回复,还是 Invalidation message?),而是建议另开一个 Connection,专门处理 Invalidation messages,不和接收正常回复的 Connection 共享一个 Connection Pool。客户端可以通过发送命令 CLIENT TRACKING on REDIRECT 1234 来告诉服务器有一个专门的客户端是接收 Invalidation messages 的。
以上已经合并到 unstable。其实我倒觉得,现在同 datacenter 内的网速已经很快了(),增加这样的复杂度来换取客户端缓存的优势好像并不值得,实际我也没有接触过客户端缓存,也不知道会带来多少的性能提升。但是我看到这个实现我马上想到了一个非常实用的使用场景。
三、客户端缓存的应用场景:动态配置数据
复杂系统中我们肯定有动态修改配置的需求:比如如果 condition-1 就这样处理,如果 condition-2 就那样处理。每一个请求都需要判断这个 condition,这个 condition 又经常变。
如果放到数据库里面,通过数据库来修改,显然对数据库的压力就太大了。一般我们会实现某种形式的通知系统。类似下面的这种结构。
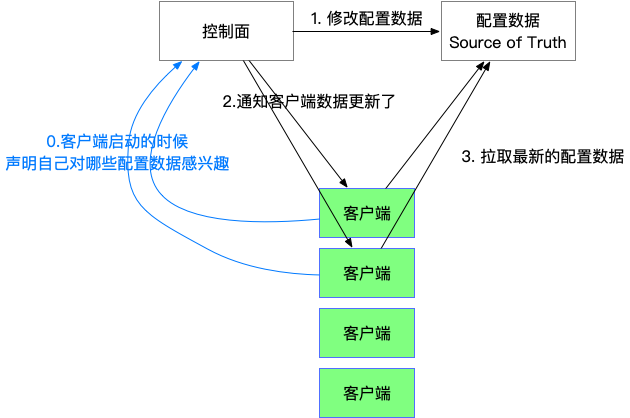
对支付宝中间件熟悉的同学,可以发现这就是 DRM(动态配置中心,Dynamic Resource Management)。现在有了 Redis 这种机制的话,我们可以很轻松的实现一个可靠的动态配置系统。
下面这张图很直白的表示了什么样的数据,适合什么样的缓存。
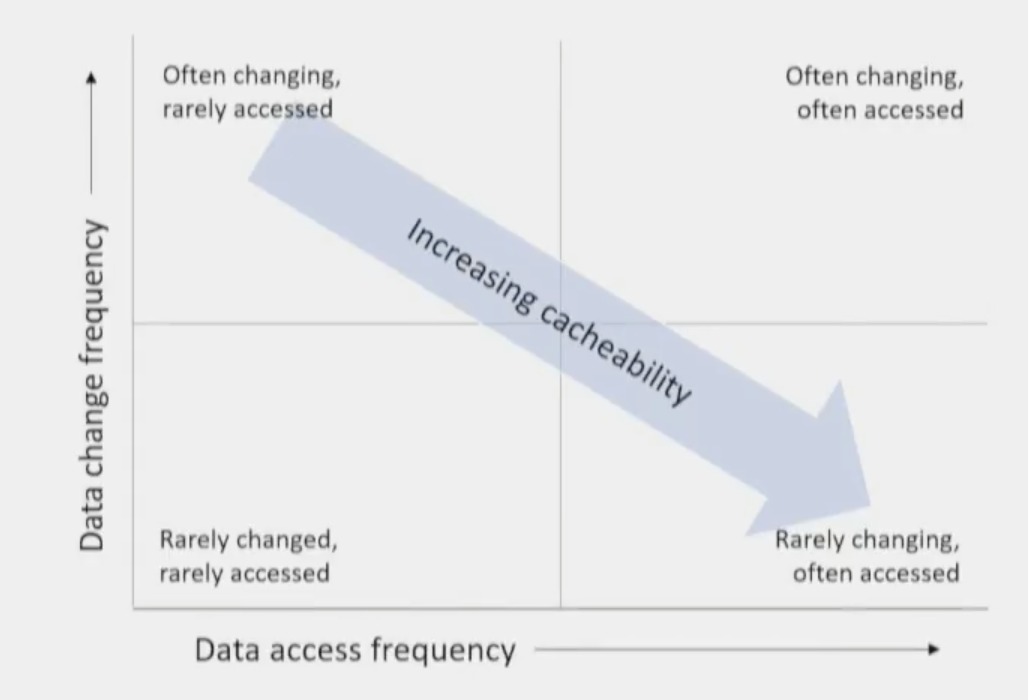
Source: https://www.youtube.com/watch?v=kliQLwSikO4
在这张图中,配置类型的数据几乎是属于最右下角的了,可能每一个请求都需要读取配置数据,访问频率非常高,但是改动很小。除此之外,像是对于每次请求都要通过 cookie 判断用户登陆状态的情况,对 session 的读取压力也是非常大的,这种场景其实做到客户端缓存中也比较合适。
综上,Client-caching 我认为意义是很大的。如果你有 Redis,那么你不需要引入其他依赖,不需要 Message Queue,不需要同步时钟,不需要锁,就可以得到一个近乎强一致的客户端缓存机制。
最后,在这篇博客中有这么一句话让我感动:
Yet I was among the streets of New York thinking about this idea.
像 Antirez 这种程序员是一种英雄主义,也是我的榜样。
参考资料: