今年在 PyCon 做了一个分享,本次演讲 PPT 可以在这里找到:https://speakerdeck.com/laixintao/python-wen-hua-zhong-de-jie-kou-he-xie-yi
在 github 的这个 repo 也有备份.
有问题的同学可以在这篇文章回复。
对加入我们组有兴趣的同学可以通过邮件联系我 :)
今年在 PyCon 做了一个分享,本次演讲 PPT 可以在这里找到:https://speakerdeck.com/laixintao/python-wen-hua-zhong-de-jie-kou-he-xie-yi
在 github 的这个 repo 也有备份.
有问题的同学可以在这篇文章回复。
对加入我们组有兴趣的同学可以通过邮件联系我 :)
大学时候读《松本行弘的程序世界》的时候,粗略的了解了一下垃圾回收算法,写过一篇介绍三种最基本的垃圾回收算法的文章。最近在看《垃圾回收的算法与实现》,接触到了这些垃圾回收算法的实现细节。粗略了解的话,基本的原理就是之前这篇博客介绍的内容,这样说出来很简单,也容易理解。但是实现起来就有很多细节了,首先要用到很多指针,所有的对象和引用的基础都是指针。然后会用到链表来保存一些可用内存,用堆来分配对象等。
其实在学校的时候学了很多数据结构,工作了发现一只在 CURD,但是研究 GC 这个话题会用上那些复杂的数据结构和算法,优化的空间也很大,非常有意思。
从这些算法细节也可以看出这些不同的算法其实都有一些强大的地方和弱点。好在评价一个垃圾回收算法的好坏有比较明确的标准,这篇文章就参考《垃圾回收的算法与实现》这本书谈一下评价标准。
垃圾回收算法(6 个字太长了,以下简称 GC)算是对程序完成它想做的事情的一种辅助,并不是程序的主要目的(废话)。所以 GC 占用的时间越少越好,程序花在正事上面的时间越多越好。
这个标准严格定义应该是 需要处理的堆大小 ÷ GC 占用时间。书中称为“吞吐量”。
这个指标其实很好理解。举个例子吧,标记清除算法要遍历两次,第一次遍历所有活跃的对象,将它们标记为“不是垃圾”。第二次遍历所有的对象,将没有被标记的垃圾回收掉。复制收集算法只需要遍历一次,将活跃的对象从内存的一般复制到另一半。所以从这个指标的角度讲,复制收集算法完爆标记清除。
但实际上,这个指标是不能“静态衡量”的。依然是上面两种算法,标记清除遍历的时候速度很快,只要写一个标记就可以了。而复制收集算法要有 copy 操作。虽然堆中活动对象的增加,甚至会出现复制收集吞吐量小于标记清除的情况。
这个指标也比较好理解,GC 算法需要一些标记,但是如果算法本身所使用的内存占得很多,就得不偿失了。这个算法本身的目的就是回收内存,本身却占用了很多内存,听起来就不合理。
其实,从算法的角度讲,内存是空间,吞吐量是时间。算法上有“用空间换时间”的策略,自然 GC 也会有。这是一种 Trade off,很多情况不可兼得。
拿引用计数来说,用几个位来表示引用计数是门学问。简单的话,占用 8 个位表示,那每个对象 1byte 就没有了。假设是占用 2 个字节的对象,那么内存占用就扩大了整整 1.5 倍。 而大多数对象仅仅会被引用 1 次而已。所以引用计数方法就发展出一些优化措施,减少引用计数占用的内存,配合其他算法来处理计数器溢出的问题。有一种极端的方式是只使用 1 位来计数(倒不如说这是一种标记了)。叫做 1位引用计数。具体的原理,这篇文章就不展开说了。
复制清除算法每次只能使用一半的空间,所以这个算法的内存使用率也是很低的。
这个指标和“吞吐量”看起来有些像,GC 算法速度越快,时间就越小。但是吞吐量指的是总体的速度,最大暂停时间指的是 GC 算法执行的时候,程序在等待 GC 完成的最大时间。这段时间由于 GC 的运行程序无法做其他的事情。
为什么这个指标会重要呢?有些程序可能可以忍受吞吐量不高,但是实时性要求很强的。比如说,A 算法每分钟暂停 1 次,一次暂停 1 秒,一小时一共暂停 60s。另一个 B 算法每小时暂停 1 次,一次暂停 30s。可想而知,如果是用户程序暂停时间长是体验很糟糕的,另外比如机器人控制程序,迈开一只腿这时候到了暂停时间,机器人就摔倒了。
引用计数的最大暂停时间是最好的,因为对象的引用到 0 的时候立即会回收,这个过程不需要暂停程序。而复制算法和标记清除算法需要在无法申请出更多内存的时候,暂停程序,开始清除阶段/复制阶段。
我们知道,越快的存储价格就越高。CPU 寄存器速度最快,但是只有几个寄存器。高速缓存非常快,但是极其昂贵。然后是内存、硬盘等。
如果程序在执行的时候缓存命中率高,那么运行效率就会高。
在这篇文章中,我们可以将程序粗略的分成两部分:GC 运行的部分和程序运行的部分。如果 GC 运行的时候需要频繁寻找对象,然后对象的引用又在很远的地方,那么缓存命中率就会很低;另一方面说,如果 GC 算法将程序的对象变得很离散,那么程序在运行的时候,互相引用的对象离得很远,效率就会很低。
标记清除算法会造成内存的碎片,对缓存不友好。复制收集算法由于是拷贝不是垃圾的对象,所以在一次拷贝操作之后,垃圾对象被释放,非垃圾对象都在一起了,所以命中率会高。另外上面提到的 1 位引用计数算法由于只拷贝指针,而不需要去找到对象,所以缓存命令率也会高。
Copy-on-write 在现代计算机技术中是比较常用的。简单来说,如果你 fork 出 4 个进程,而这 4 个进程都只是在读同一片内存,系统将会将这一片内存共享给 4 个进程,如果有其中一个进程想要写入的时候,系统才会复制出来这部分内存给这个进程写入。
这里特别要“批评”的是引用计数,因为引用计数的原理是每一个对象记住有多少个对象指向了自己。这就意味着,即使我们没有更改这个对象,只是读(应用)了这个对象,相关的内存就有了写入操作,这部分内存就会被复制。
2017 年 Instagram 发表的这篇关闭 Python 的 GC 来提高性能的文章,原理就是这样。
以上内容现学现卖,如有错误欢迎指出。
国庆之后第一天,同事在 uWSGI 的日志发现这样的东西:
|
1 2 3 4 5 6 7 8 9 |
Mon Oct 1 07:23:00 2018 - *** uWSGI listen queue of socket "127.0.0.1:3031" (fd: 4) full !!! (101/100) *** Mon Oct 1 07:23:01 2018 - *** uWSGI listen queue of socket "127.0.0.1:3031" (fd: 4) full !!! (101/100) *** Mon Oct 1 07:23:02 2018 - *** uWSGI listen queue of socket "127.0.0.1:3031" (fd: 4) full !!! (101/100) *** Mon Oct 1 07:23:03 2018 - *** uWSGI listen queue of socket "127.0.0.1:3031" (fd: 4) full !!! (101/100) *** Mon Oct 1 07:23:04 2018 - *** uWSGI listen queue of socket "127.0.0.1:3031" (fd: 4) full !!! (101/100) *** Mon Oct 1 07:23:05 2018 - *** uWSGI listen queue of socket "127.0.0.1:3031" (fd: 4) full !!! (101/100) *** Mon Oct 1 07:23:06 2018 - *** uWSGI listen queue of socket "127.0.0.1:3031" (fd: 4) full !!! (101/100) *** Mon Oct 1 07:23:07 2018 - *** uWSGI listen queue of socket "127.0.0.1:3031" (fd: 4) full !!! (101/100) *** Mon Oct 1 07:23:08 2018 - *** uWSGI listen queue of socket "127.0.0.1:3031" (fd: 4) full !!! (101/100) *** |
真有意思,看日志的表面意思是 socket 的队列被占满了。
介绍一下我们的业务场景吧,这个 uWSGI 服务负责处理的 HTTP 请求大多数一个前端的应用发过来的,请求耗时会很长,最长可能到 2 分钟,最短 ms 级别。处理请求的耗时不稳定,请求的频率也不稳定,比如可能突然发过来很多耗时长的请求。
我们的 uWSGI 基本没有配置,大多都是默认的参数,所以出现这种日志几乎是必然的。在网上搜索了一下,看到几篇 CSDN “互相参考” 风格的解决方案:加大 socket queue 的 size。主要操作分成两步:
uWSGI 有一个 stat server,因为我们使用的默认的参数,查看 uWSGI 的 stats 可以看到 socket 的队列最大为 100:
|
1 2 3 4 5 6 7 8 9 10 |
sockets: [ { name: "127.0.0.1:3031", proto: "uwsgi", queue: 0, max_queue: 100, shared: 0, can_offload: 0 } ], |
开始修改,首先使用 sysctl 加大 kernel 的 socket queue. 执行 sudo echo "net.core.somaxconn = 1024" >> /etc/sysctl.conf; sysctl -p。然后在 uWSGI 启动参数添加 listen = 2014。
要注意的是,如果只修改了 uWSGI 的 listen 参数但是不修改系统参数,将会碰到下面这个错误。
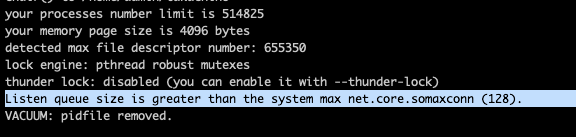
修改之后可以重新看 stats 发现确实修改成了 1024:
|
1 2 3 4 5 6 7 8 9 10 |
sockets: [ { name: "127.0.0.1:3031", proto: "uwsgi", queue: 0, max_queue: 1024, shared: 0, can_offload: 0 } ], |
看起来大功告成了,但是突然,我眉头一皱,发现事情并没有这么简单。如果 uWSGI 并发能力不够,那么加大队列并没有什么意义啊,早晚是会满的,无论改成多大,占满队列只是时间问题。所以同样的 warning 不加思索的照抄网上的方法是不可取的,要思考根本原因。根本原因就是有些请求处理时间太长了,而且都是 IO 耗时,这个时候最合理的方案是加大线程数量,增加并发能力。
uWSGI 默认是单进程单线程启动的,并发能力当然低了。一般来说进程数与 CPU 数相等。但是我们这个应用处理请求是高 IO 的,所以我每个进程又开了 32 个线程。在 uWSGI 中添加的配置如下:
|
1 2 |
processes = 8 threads = 32 |
推荐一个 debug 的工具,简直是神器:uwsgitop。uWSGI 自身提供一个 stats 服务器,可以是 socket 的,也可以是 http 的。这个工具可以自动帮你刷新 uWSGI 的实时状态,像 top 那样展示出来。关键是代码竟然只有 300 行左右,惊为天人。
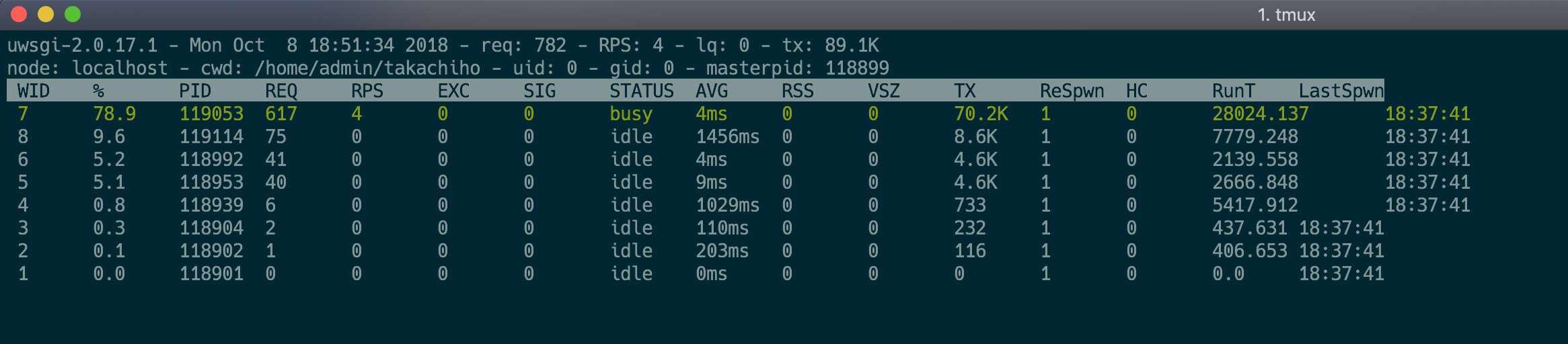
uwsgitop 显示效果
Small Sur 的《Berlin》,第一次看见这首歌是一年之前了。看到这首歌的名字的时候刚回国,就被这个名字吸引了。第一次听被惊艳到了,歌曲听起来特别安静,像冬天的街头,你可以感受到清冷的空气,明亮的阳光。
这是一个三个人组成的美国民谣乐队。《Berlin》这首歌在网易云音乐的好评比较多,其余的歌都不怎么受关注。毕竟这个乐队一共也才出了三张专辑。
但是我最喜欢的是那首《Labor》,整首歌基本上没有重复的旋律,歌词也很美,像是配合着节奏在下定一个决心一下,很鼓舞人。
《Labor 歌词》
Oh,I swear I’ll find
even more light in this coming year.
And the darkness will subside
or bring focus unto the light.
I will build a shrine
and within
place my present mind.
Shaped from water,
auburn earth,
I will favor my lover over others.
I will be inspired
by my friends,
by all questions.
And in the meantime
I will work.
I will labor for my lover,
for my mother.
Small Sur 一共发布了三十几首歌,不算多,一点儿也不同质化,都很好听。心情不好的时候可以挨着听听,想想事情。
最近一直在用 dot 来画图,如果你不知道 dot 这个东西,那么 graphviz 应该听说过吧,graphviz 是 dot 语言的一个实现。dot 是一个绘图语言,可以表达有向图和无向图,用 dot 语言描述的图可以 render 成 png、jpeg、pdf、svg 等等各种格式,非常方便。
比如下面这个 dot 文件:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
digraph G { subgraph cluster_0 { style=filled; color=lightgrey; node [style=filled,color=white]; a0 -> a1 -> a2 -> a3; label = "process #1"; } subgraph cluster_1 { node [style=filled]; b0 -> b1 -> b2 -> b3; label = "process #2"; color=blue } start -> a0; start -> b0; a1 -> b3; b2 -> a3; a3 -> a0; a3 -> end; b3 -> end; start [shape=Mdiamond]; end [shape=Msquare]; } |
可以渲染成下面这个文件:
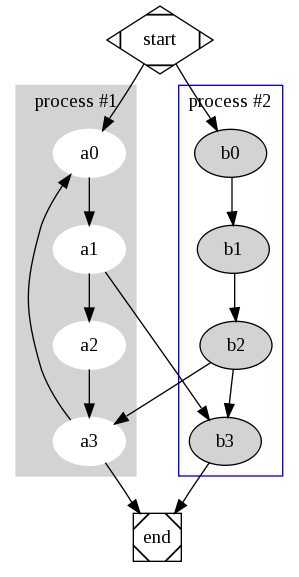
dot-example
Mac 的 graphviz 提供了命令行的工具可以渲染 dot 文件。可以通过 brew 来安装: brew install graphviz 。
但是每次编辑然后切换到命令行渲染,再用 Preview 打开浏览,非常繁琐,这种文件修修改改是比较频繁的,预览体验很不好,比较合适的方法是用 jupyter 这样的 notebook 来实时渲染。Graphviz 目前没有可以直接在 jupyter 里面跑的 kernel,不过 Python 的封装是支持在 jupyter 看到结果的。这个缺点是你要写 Python 语言,调用 Python 的函数和方法,show 函数等等。不能写原生的 dot 语言。
我在这上面包了一层,调用这个包可以直接在 jupyter 的 cell 里面写 dot 了,项目的地址如下:
https://github.com/laixintao/jupyter-dot-kernel
这个 kernel 其实挺好写的,去看了一下文档,基本复用一下 IPython 的 kernel 就可以了。但是发送二进制数据回前端的 Response 结构很妖娆,文档也看不怎么明白,网上的资料也比较少…… 算是一个小坑吧,在这上面花了不少时间。最后是一拍脑袋,去找了其他 kernel 的代码看了一下才弄清楚的。贴在下面让大家感受下……
|
1 2 3 4 5 6 |
stream_content = { "metadata": {"image/png": {"width": width, "height": height}}, "data": {"image/png": data}, } self.send_response(self.iopub_socket, "display_data", stream_content) |
然后我还在 jupyter 里面写了一个教程(WIP),目前写了基础的教程, 看完之后基本都知道怎么样了。后面打算继续完善一些一些更高级的用法。教程的地址如下:
https://github.com/laixintao/learn-dot
我参考的主要是一些手册和文档,其实目前找到的也不是很多。那个 dot 文档竟然没有一个目录,有必要整理一下。
man dot