在前面的系列文章中,二层交换技术已经讨论的差不多了。我们现在知道了一个包经过交换机去往同子网下的其他主机都有哪些高可用技术。接下来,我们讨论下跨越子网的情况。
如果目标地址和自己不在同一个子网下,那么这个包就无法只经过二层网络到达目的地。必须经过三层路由。那么主机应该把这个包交给谁呢?回顾本系列开始的基础知识——如何在 IP 网络中将包送达到目的地,依赖的是所有参与三层路由的设备的路由表。在三层网络的视角下,我们的 Linux 服务器也是一个三层协议的参与者,服务器上也有一个路由表,只不过这个路由表很小,最核心的就是一条默认路由——如果不知道应该转发到哪里去,就转发给默认路由。
|
1 2 3 |
root@ubuntu-1:/$ip route default via 192.168.1.1 dev eth0 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.5 |
默认路由可以通过 ip route 命令来配置。
|
1 |
ip route add default via 192.1.1.1 dev eth0 |
那么问题就出现了,这个 IP 只能配置一个,这不就成了一个单点故障了吗?
如何解决这个单点故障呢?既然静态的配置只能配置一个 IP,那么自然就想到我们可以使用动态配置。即这个默认网关 IP 是动态生成的。
动态路由协议
一种方法就是让我们的服务器去运行动态路由协议(比如 OSPF,BGP),这种方法我们在四层负载均衡技术中见到过。这样,服务器就变成了一个动态路由协议的参与者,它不会在协议中参与数据转发,只参与控制面,只为了获取默认网关 IP。
这种方式缺点是配置复杂,带来了额外的计算成本,也给网络拓扑增加复杂度。当被作为默认网关的路由器故障时,需要的故障收敛时间也比较长。
ICMP Router Discovery Messages (动态路由发现)
RFC 1256 定义了一种基于 ICMP 的动态路由发现协议方法。简单来说,就是路由器会在 LAN 中不断广播自己的地址。这样,就可以配置多个路由器来一起广播自己的地址,每一个路由器的广播中会带有 preference level,这样,主机选择 preference level 最高的来作为自己的默认网关。新的主机在上线的时候,可以立即通过广播请求来询问路由器的地址。如果在使用的默认网关不再进行广播,就认为它挂了,去使用 preference level 下一级的路由器作为网关。
这种方法相比之下复杂度小一些,但是故障收敛时间也不小。
使用「动态」网关,每一个主机要独立判断当前网关的地址,所以收敛时间就不可避免地比较长。要想快速恢复,最好的方法还是静态配置,但是我们把静态配置的 IP 做成高可用的。
这里讨论一下 DHCP,很容易搞混。DHCP 不是一种动态生成网关地址的方式,在我们这篇文章讨论的上下文下,DHCP 也相当于是「静态配置」,只不过不需要在服务器主机上配置,而是在路由器上静态配置,主机通过询问路由器来获得这个静态配置。
DHCP 这种可以动态获取 IP 的方式,放在数据中心可太吓人了。数据中心网络的特点是,网络结构是确定的,主机数也是确定的,每一个服务器都应该有一个固定的 IP,而不是变来变去。所以,在数据中心网络基本上看不到 DHCP 协议。DHCP 用在园区网,办公网,家庭网络中,用于用户上网接入。
「高可用的网关」
我们现在需要设计一个高可用的默认网关。高可用最简单直观的方式是什么呢?active-backup. 所以我们使用两台路由器,一个作 Master,一台作 Backup。接下来我们只需要一种方式,能让 Master 在挂掉的时候快速切换到 Backup 就可以了。
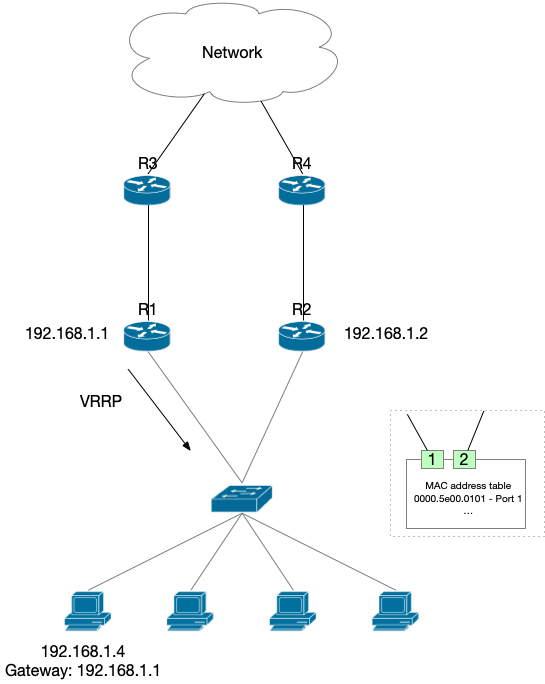
怎么做到切换呢?网关和服务器在同一个子网,子网内的寻址方式是 MAC 地址。所以可以切换网关 IP 对应的 MAC 地址。但是这样太慢了,子网内所有的服务器都需要通过 ARP 发现 Backup 路由器的 MAC 地址才行。
怎么能更快呢?对咯,又是 Gratuitous ARP. 我们给两个路由器配置相同的 IP 地址、相同的 MAC 地址,正常情况下,询问网关 IP 对应的 MAC 地址的 ARP request 只有 Master 会响应,服务器感受不到 Backup 路由器的存在。一旦 Master 路由器挂了,Backup 路由器直接发一个 GARP 让交换机更新 MAC 地址对应的交换机端口,这样,发往网关 MAC 地址的流量就被交换机全部转发到了 Backup 路由器。服务器感知不到这个切换过程,切换是在路由器和交换机之间完成的。
设计好了切换过程,我们只剩下一个问题需要解决——何时切换。
切换其实是 Backup 路由器完成的,因为何时切换取决于 Backup 路由器何时发送出来这个 GARP 包。为了决定要不要切换,Backup 路由器需要知道 Master 路由器的状态。我们就需要一个协议能让路由器之间协商谁来做 Master,谁来做 Backup。
这个协议就是 VRRP(The Virtual Router Redundancy Protocol) 协议。
VRRP
VRRP 是 IETF 定义的一个开放协议,标准化于 RFC 2338,发布于 1998 年。
2004 年,发布了 RFC 3768,VRRP v2, 主要添加了对 IPv6 的支持。
2010 年,发布了 RFC 5798,VRRP v3,主要添加了抢占模式,object tracking(追踪链路状态),sub-second timers.
VRRP 不是解决这个问题的唯一协议。这类协议的统称叫做 FSRP(First-hop redundancy protocol, 第一跳冗余协议)。比如:
- Hot Standby Router Protocol (HSRP),思科专有协议。VRRP 大部分都是借鉴了 HSRP。
- Common Address Redundancy Protocol (CARP),patent-free(VRRP 和 HSRP 都不是)。
VRRP 核心工作方式
VRRP 协议是路由器和路由器之间的协议,多个路由器合作来提供一个 Virtual IP 和一个 Virtual MAC,来给其他的 Host 作为默认网关。Host 不需要知道 VRRP 的存在,只需要静态配置默认网关地址即可。
VRRP 的核心工作方式就是,多个路由器选举出来一个 Master,其他的成为 Backup。Master 每秒广播自己的信息,表示自己健康。如果 Backup 3s (准确地说是 3s + Skew time) 没有收到来自 Master 广播包,就重新选举出来一个 Master。新 Master 发 GARP 指示交换机切换,并且开始承担转发流量的工作。
VRRP 协议只有一种包,结构如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |Version| Type | Virtual Rtr ID| Priority | Count IP Addrs| +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Auth Type | Adver Int | Checksum | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | IP Address (1) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | . | | . | | . | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | IP Address (n) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Authentication Data (1) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Authentication Data (2) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
VRRP 基于 IP Multicast 协议,广播的目标地址是 224.0.0.18,Master 路由器要定时广播上面这个结构的包,Src IP 设置为自己,IP 层的 TTL 设置为 255,如果不是 255,会被其他的路由器丢弃,但是这个 TTL 没有含义的,因为这个广播包不会被转发,其他的人收到这个包要么自己内部处理,要么丢弃。
VRRP 协议的参与者有三种状态:Initial, Master, Backup.
Initial 状态是刚启动的时候进入的,启动后如果 Priority(VRRP 配置项,可以在路由器上配置)是 255,直接成为 Master,否则成为 Backup。
Master 状态下,要负责以下几件事:
- 回应对网关 IP 的 ARP request (一定要回应 Virtual MAC 地址,不要回应 Master 自己的物理 MAC 地址,不然的话正常情况下网络能通,但是发生选举切换之后,客户端还是用物理 MAC 地址访问,就挂了,相当于埋雷);
- 目标地址是网关虚拟 MAC 地址的,进行三层转发;
- 定时广播 VRRP 包;
- 如果收到别人广播的 VRRP 包:
- 如果对方的 Priority 更高(如果 Priority 相同,比较 IP 地址谁高),转入 Backup 状态;
- 如果自己的 Priority 更高,丢弃(让他看看谁才是老大);
- 如果收到 shutdown 信号,广播 VRRP 包并且把自己的 Priority 设置为
0,意思是本 Master 不再继续当 Master 了,请立即开始选举。这样,能让预期的维护降低 downtime;
Backup 状态下,要负责以下几件事情:
- 如果收到了发给 Virtual IP 或者 Virtual MAC 的包,直接忽略;
- 设置定时器,如果收到来自 Master 的广播包,重置定时器;如果定时器达到倒计时时间,成为 Master,开始广播 VRRP 包。
选举过程非常简单,基本上就是比 Priority,默认是 100,如果 Priority 相同,就比 IP 地址。
这里可能有一个问题,假设我们有 4 个路由器在子网内组成一个虚拟网关,现在 Master 挂了,那么 3 个 Backup 同时成为 Master 开始广播,虽然最终只会有一个 Master 存在,但是会短暂地造成 MAC flapping 问题。这个问题在协议中是通过加入 Skew_time 开解决的:
- Backup 倒计时的时间是
(3 * Advertisement_Interval) + Skew_time; - 其中
Skew_time的计算方式是:( (256 - Priority) / 256 );
这样,谁的优先级高,谁就会先发送。
部署结构
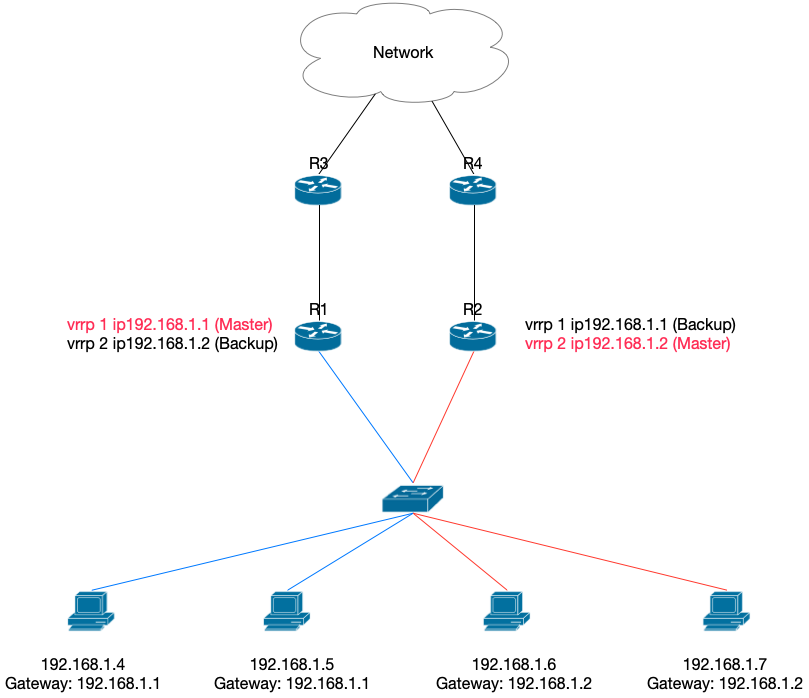
VRRP 本质上是一个主备方案,我们在这个系列开头就讨论过主备方案的坏处:备份意味着浪费资源。
有什么办法把资源都利用起来呢?其实到了三层上,我们可以看作是「客户端-服务器」架构了,Host 是客户端,默认网关是 Gateway。那么就可以用使用「负载均衡」的思想。
对于两个路由器 A 和 B,我们可以设置两组 VRRP,第一组 A 为 Master,第二组 B 为 Master。在子网所有的 Host 中,一半的 Host 使用第一组的 Virtual IP 作为 Default Gateway,另一半的 Host 使用第二组 VRRP 的 Virtual IP 作为 Default Gateway。这样,就可以实现「负载均衡」了,并且在任何一个路由器挂的情况下,另一个路由器会承担起两组 VRRP 的转发责任。
实验
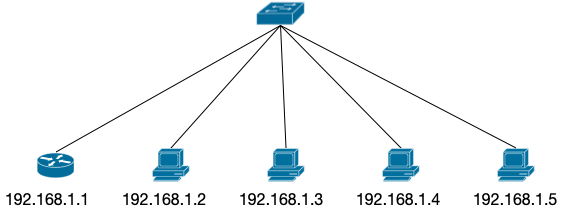
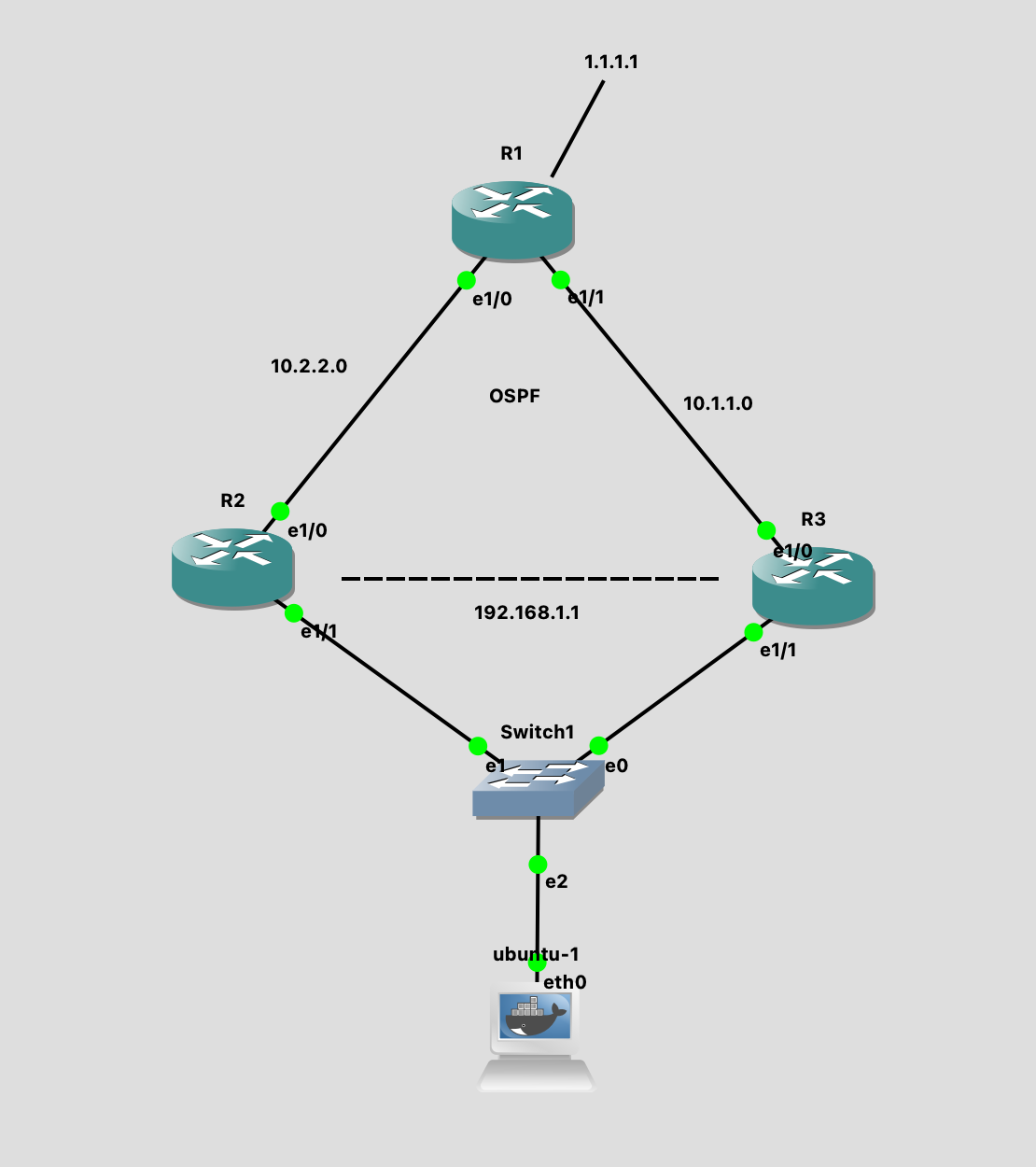
实验使用的拓扑图如下:
三个路由器运行 OSPF 路由,在 R1 上有一个 1.1.1.1 主机,R2 和 R3 都可以提供去往 1.1.1.1 的路由,并且 R2 和 R3 组成一个 VRRP,提供的虚拟默认网关地址是 192.168.1.1。我们在 ubuntu-1 上配置好静态默认网关,以达到在 R2 和 R3 之间任意一路由器挂掉都不影响从 ubuntu-1 到 1.1.1.1 的路线。
路由器的配置如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
hostname R1 ! interface Loopback0 ip address 1.1.1.1 255.255.255.0 ! interface Ethernet1/0 ip address 10.2.2.1 255.255.255.0 duplex half ! interface Ethernet1/1 ip address 10.1.1.1 255.255.255.0 duplex half ! router ospf 110 router-id 1.1.1.1 log-adjacency-changes network 1.1.1.0 0.0.0.255 area 0 network 10.1.1.0 0.0.0.255 area 0 network 10.2.2.0 0.0.0.255 area 0 ! |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
hostname R2 ! interface Ethernet1/0 ip address 10.2.2.2 255.255.255.0 duplex half ! interface Ethernet1/1 ip address 192.168.1.1 255.255.255.0 duplex half vrrp 1 ip 192.168.1.1 ! router ospf 110 router-id 2.2.2.2 log-adjacency-changes network 10.2.2.0 0.0.0.255 area 0 network 192.168.1.0 0.0.0.255 area 0 ! |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
hostname R3 ! interface Ethernet1/0 ip address 10.1.1.3 255.255.255.0 duplex half ! interface Ethernet1/1 ip address 192.168.1.2 255.255.255.0 duplex half vrrp 1 ip 192.168.1.1 ! router ospf 110 router-id 3.3.3.3 log-adjacency-changes network 10.1.1.0 0.0.0.255 area 0 network 192.168.1.0 0.0.0.255 area 0 ! |
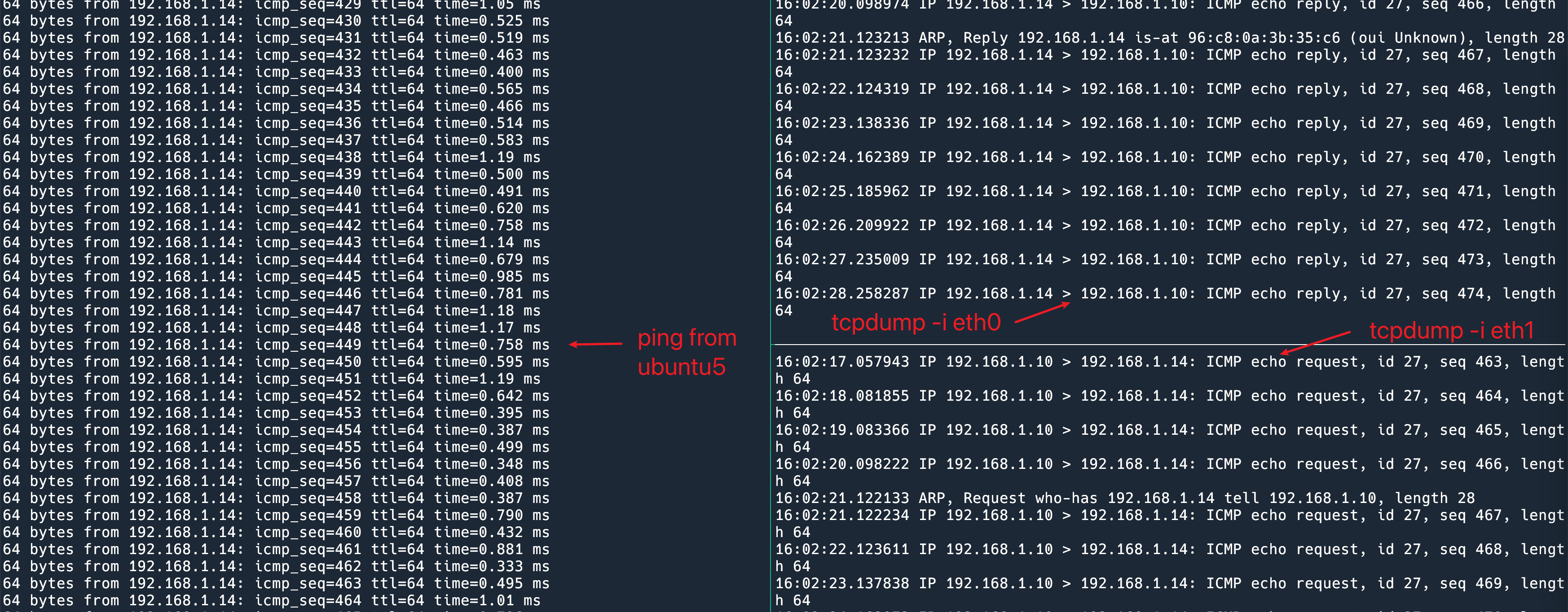
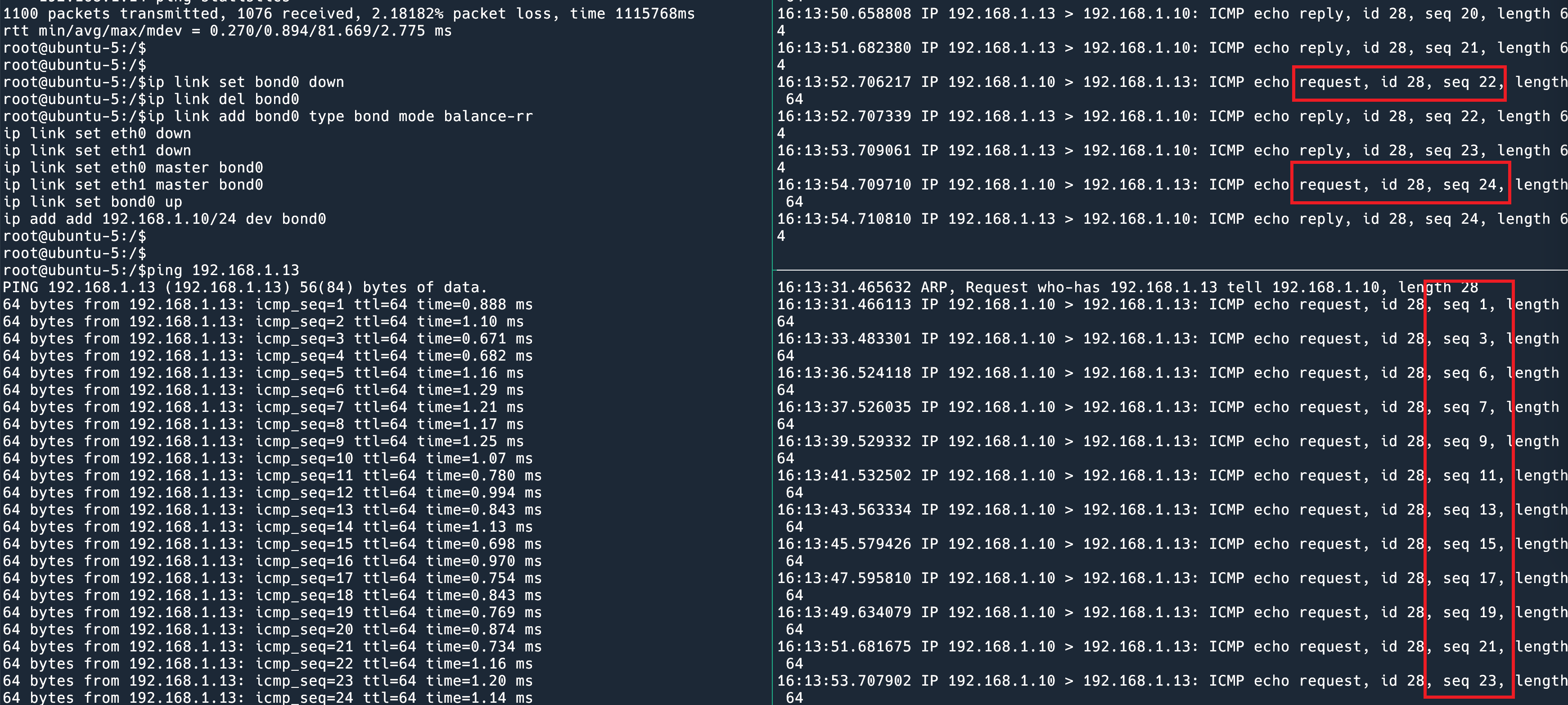
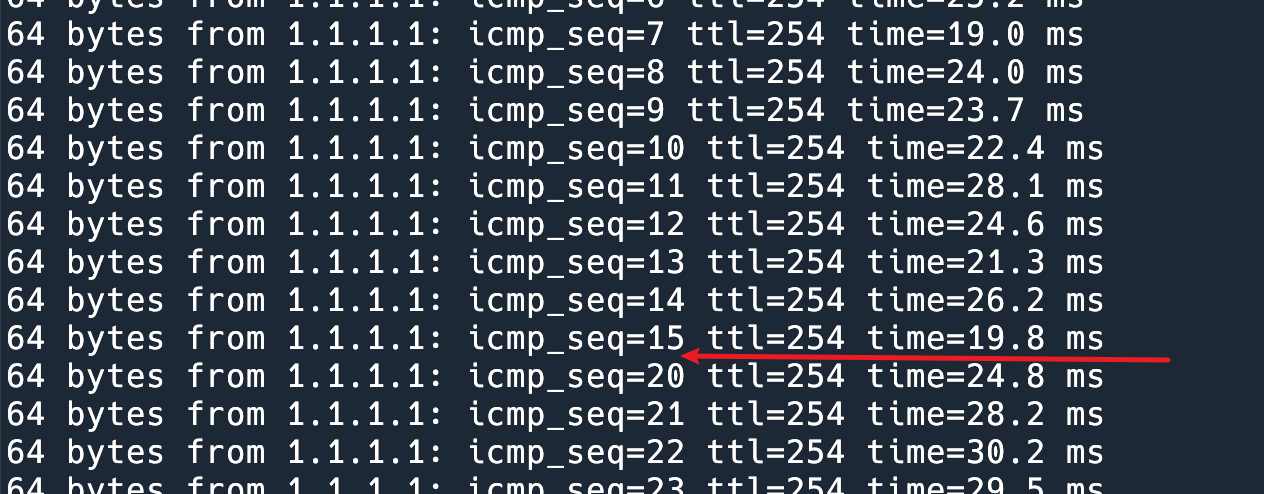
在 ubuntu-1 主机上 ping 1.1.1.1,然后挂掉当前的 Master R2 可以看到一共丢了 4 个包。
R3 显示从 Backup 成为 Master:
|
1 2 |
R3# *Aug 11 12:42:53.867: %VRRP-6-STATECHANGE: Et1/1 Grp 1 state Backup -> Master |
|
1 2 3 4 5 6 7 8 9 10 11 |
R3#show vrrp Ethernet1/1 - Group 1 State is Master Virtual IP address is 192.168.1.1 Virtual MAC address is 0000.5e00.0101 Advertisement interval is 1.000 sec Preemption enabled Priority is 100 Master Router is 192.168.1.2 (local), priority is 100 Master Advertisement interval is 1.000 sec Master Down interval is 3.609 sec |
Until next time!