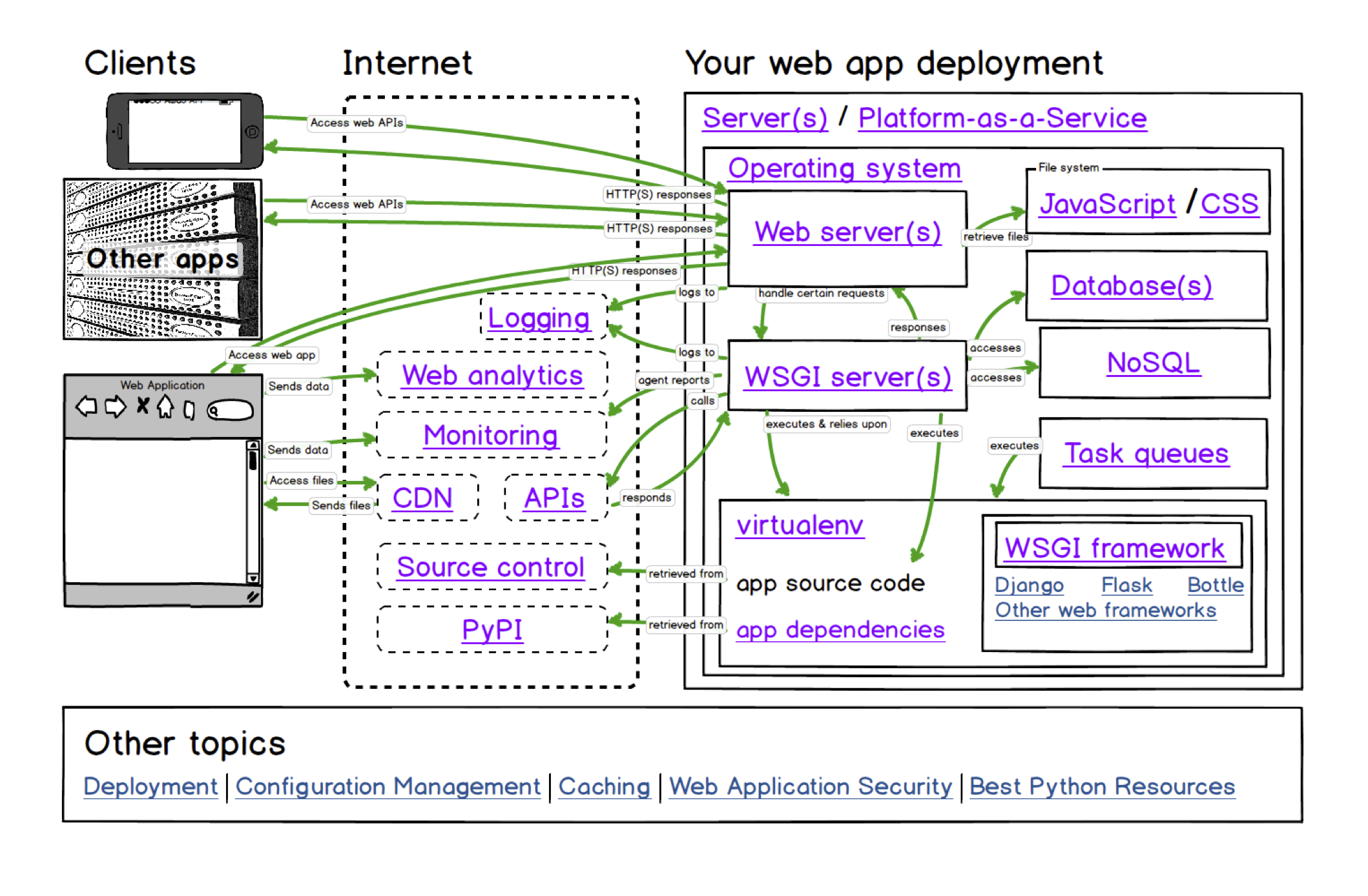
去年去参加了 WEPLAY 游戏展,会展上《寂静岭》的音乐制作人山冈晃先生接受采访的时候说,《寂静岭》音乐的灵感来自于一本俄罗斯小说《罪与罚》,所以我决定去读一下这本书。
花了半年时间才读完这本书,读完之后发现,这个情节和游戏中的剧情有很微妙的关系。《罪与罚》中主线讲述的是大学生罗佳迫于生活的穷困,内心又有着伟大的思想,认为杀死一个蝼蚁一般的老太婆,获得短期内的钱来供自己这段时间的发展,对人类社会来说是有益的,就像拿破仑一样。然而,内心是有这样的想法,但是实践起来却畏手畏脚,最终鬼使神差践行了自己的计划,良心却备受谴责。经历了很长时间的煎熬,最后去警察局自首。我认为罗佳的悲剧来自于年纪轻轻却不甘于平庸,急切地想有非常舒适的环境去发展自己的矛盾。现实中的自己无法满足自己对自己的期望,从而对自己产生了恨,表现地对自己的妹妹和妈妈冷漠,对自己的处境也漠不关心。
除了主人公罗佳,书中还描述了很多人的悲剧。无法自制经常跑去饮酒的小官吏,硬生生断送的自己的前程,还有原本幸福的家庭;命途多舛的官吏妻子,被逼卖淫的女儿;被世俗嘲笑,被富婆包养的斯维德里盖洛夫,即使放弃了一切也换不到杜尼娅的芳心,最终自杀;对儿子百般溺爱,精神失常的罗佳的妈妈。
这本书所描述的悲剧如此突出,我觉得很大部分原因是作者陀思妥耶夫斯基喜欢让人物的感情剧烈变化,文章有打断的独白和对话,用了很多语气词,惊叹词,使得这些人物的台词感染力非常强,很容易代入。
读完这本书,也没有什么很特别的想法,就是感受到了这么多悲剧。生者还是好好活着,多考虑一下别人,小心翼翼的,生活太容易破碎了。
以下是我在 Kindle 上划出的一些摘录。
这种理论把芸芸众生人为地分为“非凡的人”和“平凡的人”两类:“一类是低级的人(平凡的人),也就是说,可以称之为仅仅是繁殖同类的材料;另一类是真正意义上的人,也就是具有天赋和才干,能在自己所处的社会提出新见解的人。”
个人究竟该以何种方式与途径发展自己的个性呢?
但他犯罪后良心不安,被他蔑视的道德规范暗暗地惩罚着他的灵魂,他噩梦连连,疑神疑鬼,惶惶不可终日,几次打算到警察分局去投案自首。这样,这部小说所写的真正惩罚就是道德与良心的惩罚,它所描绘的是发生在主人公内心深处的道德和心理斗争。
“那是由于没有别的人可找,也没有别的路可走啊!不是吗,任何人总得至少有一条路可走啊。因为有时候一个人必须有条路可走!
此外,要了解任何一个人,都必须一步一步地细心观察,才不致产生错误和偏见,否则,以后纠正错误和消除成见就十分困难了。
啊。当然,即使只吃黑面包只喝白开水,她也不会出卖自己的灵魂,也不会因为耽于舒适而放弃精神方面的自由;
啊,必要时我们会压制我们的道德情感,并且把自由、宁静,甚至良心,所有的一切,都拿到旧货市场上去拍卖。连生命也毫不顾惜!只要我们热爱的人能够幸福。
一种新的、无法克服的感觉以每分钟逐渐增强之势控制了他:这就是对劈面相逢的、环绕四周的一切都怀着某种无比强烈的、几乎是生理性的反感,一种持续不断的、怒气冲冲的、恨之入骨的反感。他憎恶劈面相逢的一切人,——憎恶他们的面孔、步伐、举止。假如有谁来与他攀谈,他简直要啐他一脸唾沫,可能还会咬他一口……
科学却告诉我们:首先你应该只爱自己,因为世界上的一切都以个人利益为基础。你只爱你自己,那么你就会把自己的事情办妥,你的长上衣也就会完整如一。经济学的真理进一步告诉我们,社会上办得好的私人事业越多,也就是说完整如一的长上衣越多,社会的基础就越牢固,公共事业也就会办得越发兴旺。
“您的那个讲师在莫斯科受审时被问到为何伪造有奖债券时,答道:‘大家都千方百计致富,所以我也想快速发财。’原话我记不太清了,但意思就是不劳而获,尽快地大发横财!大家都习惯于坐享其成,以别人的思想为思想,吃别人的现成饭。哈,伟大的时刻来临了,每个人都露出了自己的本性,都在看用什么法子发财……”
他只知道一点:“这一切必须就在今天结束,一次性地结束,立即结束;否则他决不回家,因为他不愿意如此活着。”如何结束?用什么法子结束?对此他毫不知晓,甚至不愿加以考虑。他驱走了这个念头,因为这个念头让他苦恼不已。他只是感觉到并且知道,一切总归都必须改变,这样变或者那样变,“不管怎样变都行”,他怀着天不怕地不怕、无可动摇的自信和决心反复喃喃着这句话。
“没什么可锁的人是幸福的,对吗?”他笑盈盈地对索尼娅说。
比方说,哪怕是人类的立法者和规章制度的创立者,从远古时代,直至后来的莱喀古士[17]、梭伦[18]、穆罕默德[19]、拿破仑等等,无一例外,都是罪犯,唯一的原因在于,他们在制定新法规的同时,也就破坏了世所公认的、神圣不可侵犯的、代代相传的古老法规,而且,当然啰,他们也不会面对流血而停步不前,只要流血(有时流的完全是无辜的、为维护古代的法规而英勇献身者的鲜血)能帮助他们成功。尤其令人注目的是,这些人类的恩人和规章制度的创立者,大多数都是血流成河的特别可怕的屠夫。
第一类人永远是现在的主人,第二类人则是未来的主人。第一类人保存这世界,增殖人口;第二类人则推动世界向前发展,并引导它奔向目的地。无论是第一类人还是第二类人,都有完全相同的生存权利。
“有良心的人一旦意识到自己的错误,就会深感痛苦。这也是对他的一种苦役之外的惩罚。”
追求进步,并跻身于“我们的年轻的一代”的行列——完全是出于一时的青春激情。他是那些数不胜数、各式各样的言行庸俗、思想幼稚、志大才疏而又刚愎自用者之一,这类人对于最流行的时髦思想必定是顷刻间便趋之若鹜,紧紧依附,为的是立即把它庸俗化,并在一瞬间把他们有时竭诚效劳的一切漫画化。
也许,在这件事上起决定作用的是那种特殊的穷人的自尊心。就是因为这种自尊心,千千万万的穷人每逢日常生活中人人必须遵守的某些社会习俗时,都会倾箱倒箧地把自己节衣缩食积攒起来的一点点钱全都花光,只是为了证明自己“毫不逊色于别人”,以及不让那些人对他们横加“指责”。
你们还不知道,还不知道,这是怎样的一颗心灵,这是怎样的一个姑娘!她竟会偷钱,她!如果你们需要的话,她为了济人之难会脱下自己身上的最后一件衣服,光着脚去把它卖掉,再把钱送给你们,瞧啊她就是这样一个姑娘!因为我的孩子啼饥号寒,她甚至去领了黄色执照,她完全是为了我们才去出卖自己的呀!……哎哟,死鬼,死鬼呀!哎哟,死鬼,死鬼呀!你看见了吗?你看见了吗?这就是为你办的丧后酬客宴!上帝啊!你们倒是保护保护她呀,究竟为什么光是站着呢!罗季昂·罗曼诺维奇!您为什么不出来主持正义啊?难道连您都不相信她?你们连她的一个小指头都抵不上,你们所有的人,所有的人,所有的人,所有的人!上帝啊!最后只好请您保护她了!”
你瞧:你已经知道,我母亲几乎是一无所有。妹妹侥幸受了些教育,也注定只能东奔西跑当家庭教师。她们把一切希望都寄托在我的身上。我已经上了大学,但在大学里我无法维持自己的生活,迫不得已只好暂时退学。假如我就这样勉强拖下去,那么十年二十年之后(如果天从人愿,情况好转),我仍然有希望当上一名教师,或者成为一个官吏,可以拿到一千卢布的年薪……(他似乎是倒背如流)然而到那个时候,母亲早已因为操劳和愁苦而憔悴不堪了,我还是不能使她感到安慰,而妹妹……唉,妹妹的情况也许更糟!……难道竟然可以一辈子对这一切都漠不关心,置若罔闻,把母亲忘记到九霄云外,让妹妹低首下心地,譬如说吧,任人侮辱?为了什么?是不是为了在埋葬她们以后,挣钱去养活其他的人——妻子和孩子,而以后又一文不名地让他们活在世上餐风饮露?唔……唔,于是我下定决心要占有老太婆的钱,把它们用做我最近几年的费用,不再使母亲担忧受苦,用这些钱维持我大学的生活,实现我大学毕业后最初的一些计划——大刀阔斧、不遗余力地彻底改变这一切,为自己开创一个崭新的前程,踏上一条独立自主的新路……唔……唔,我要说的就全在这里了……唔,当然喽,我杀死了这个老太婆,——我做了一件坏事……唉,不说了!”
一百只兔子永远拼不成一匹马,一百个疑点永远拼不成一个证据,有句英国谚语不是这样说的吗?不过这仅仅是一种理智的说法,可是一时冲动起来的感情是难以控制的。
其实,要对某些人做出公正的评判,就必须预先放弃一些先入的偏见,改变那种对待我们周围的人和事的习惯态度。
最后,我采取了一个征服女人的心的最高明、最有效的绝招,这个绝招永远都不会使人失望,对任何人都绝对管用,无一例外。这个绝招是众所周知的,它就是阿谀奉承。世界上最难的事是开诚相见,而最容易的事是阿谀奉承。开诚相见,只要有百分之一的虚假,那么马上就会出现不和谐,而麻烦就会随之而来。至于阿谀奉承,哪怕从头至尾都是虚假,但还是令人感到高兴,听起来不会不舒服;哪怕觉得肉麻,但还是觉得舒服。不管阿谀奉承是如何肉麻,其中肯定至少有一半使人觉得真实。
“罪行?什么罪行?”他突然出人意外地狂叫,“我杀死的是一只可恶的、有害的虱子,一个对任何人都没有益处的放高利贷的老太婆,一个穷人的吸血鬼,杀了她可以赎四十桩罪行,这也算是犯罪吗?我可不认为这是罪行,也没有想去赎罪。为什么大家都指着我说:‘犯罪,犯罪!’直到现在我才明白,我的胆怯是非常愚蠢的,现在我已决定去受这种不应该受到的耻辱!我这样做,只是由于自己的卑鄙和无能,也许还由于这个……波尔菲里建议的好处!……”
但是他对自己进行了严格的审判,他那变得冷酷无情的良心,在他以往的行为中没有发现任何特别严重的罪过,除了人人都免不了的一般的失误以外。