以前整理自己的东西都是用印象笔记,槽点太多了,比如只支持1级目录,列表页不友好等,整理起来很不方便。最近发现了 Vimwiki 这个好东西,于是想出另一种策略:
- 用 Vim 撰写个人 wiki (Vim 是我最喜欢的编辑器,第二喜欢的是 WordPress 后台编辑器)
- 用 git 追踪变更记录,每次写入的时候自动追加 commit 信息 (这样自己完全可以不用关心备份了)
- 用 Github pages 来托管 html (静态网站托管无比简单,写 wiki 就是为了方便查阅,如果再耗费很多精力去运维就得不偿失了)
1.新的 Github 账户
我的 Github 账号的 Pages 已经托管了一些小玩意,所以另申请了一个账号,专门用来记录 wiki。用新账号新建一个 Pages 并将主账号加入到合作者,这样 key、邮箱都不用再另外配置了。
自己邀请自己还有点奇怪
然后新账号就可以丢掉了,以后全部用自己的主账号操作。
接下来配置 Vim 和 Vimwiki。
2.安装和配置
毕竟是一个很老的项目,提供了各种 Vim 包管理工具的安装方式。可以通过 Readme 的信息选择你喜欢的方式安装。
然后 clone 下来我的 Pages 仓库,创建 wiki 文件夹存放源文件,创建 html 文件夹来保存生成的 html 文件。
在 .vimrc 中加入如下配置,设置 Vimwiki 的路径:
|
1 2 3 4 |
let g:vimwiki_list = [{ \'path': '/Users/laixintao/Program/laixintao-wikibot.github.io/wiki', \'path_html': '/Users/laixintao/Program/laixintao-wikibot.github.io/html', \}] |
然后在 Vim 中按下 <leader>ww 就可以看到一个新创建好的 index.wiki Buffer 了。
随便写点什么保存,然后在 Vim 中执行 :Vimwiki2HTML 就可以将 wiki 文件编译成 html。然后将其 push 到 Github 上,就可以在线上看到这个页面了。
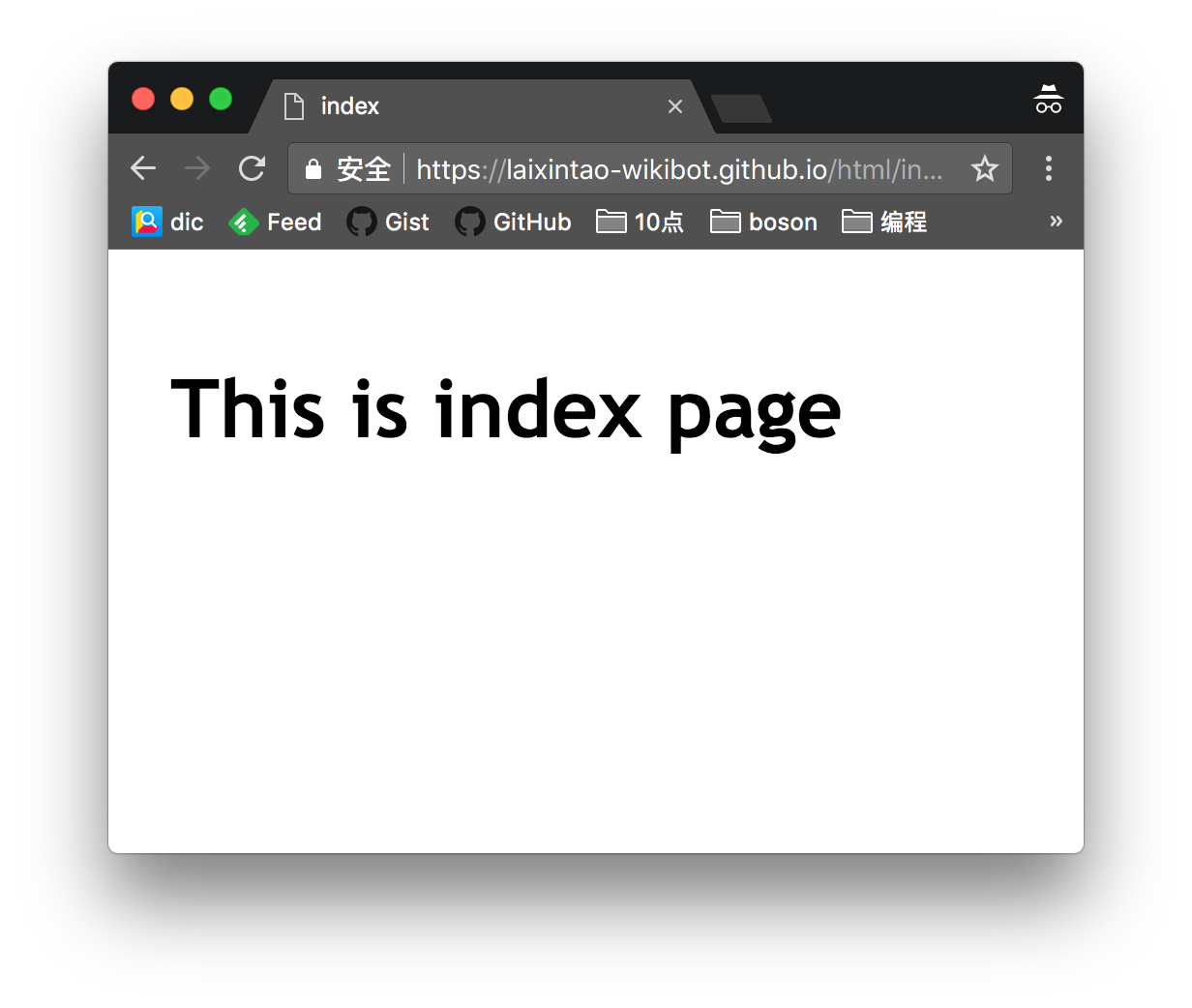
可以写一个 Makefile 自动化发布的过程。
|
1 2 3 4 5 6 7 8 9 10 11 |
publish: clean git add -A git commit -m "Auto commit wiki files." vim -m +VimwikiIndex +VimwikiAll2HTML +qa git add -A git commit -m "Compile to html" git pull --rebase git push clean: rm -rf html/* |
这样只要运行 make publish 命令,就会自动构建最新的 Wiki 并发布到 Pages 上。
3.自定义域名
静态托管简直太爽,我相信 Pages 在我有生之年不会倒闭,但是为了以防万一,还是使用自己的域名,这样将来万一要切换,也会很方便,直接改下 DNS 解析位置就好了。首先添加一个 CNAME 文件让 Pages 跳转到我自己的域名: echo "wiki.kawabangga.com" > CNAME 然后 PUSH 上去就可以了。然后再到自己的域名服务商那里添加一个 CNAME 指向 laixintao-wikibot.github.io 。等解析生效就可以通过 wiki.kawabangga.com 访问了。
到这里就差不多搭建起来了,接下来就是熟悉一下 WIKI 的语法、学下 Vimwiki 的快捷键使用。另外默认的 template 太丑了,就是一个基本的 html,有时间的话还要在网上找找有没有漂亮点的 theme。
参考资料:
- 使用 Vimwiki + git 做知识管理
- http://kwiki.github.io/tips/vim/vimwiki-guide.html
