最近项目上线,遇到了比较烦的问题,我们无法在线上环境使用 redis。原因貌似是 redis 对集群不太友好,高可用比较难做。所以公司没有现有的可以申请用的 redis 集群(但是有类似的替代品)。
在之前解决分布式定时任务的时候,我引入了 celery,但是很可惜,celery 目前支持的几个 Broker 在我们这里都没有。想了很多方案之后,还是决定不再用 celery + redis 的组合了。寻找一个不依赖外部 Broker 的异步队列。
其实需求主要是两部分:1 需要支持定时任务功能,并且多个节点不能重复执行,这就需要一个全局的 Lock 之类的东西。 2 能够执行一些异步的任务,比如用户发请求,直接返回 Response,表示请求成功,然后再慢慢处理任务。
找了一圈之后,发现 uWSGI 自带的 spooler 功能基本可以满足异步任务的需求。定时任务可以使用 django-cron 。这篇文章分享下 spooler,下一次再分享下 django-cron 这个项目吧。
spooler 解决的主要是这样一种场景:收到用户请求的时候要执行一个耗时比较长的任务,比如发送邮件,通过网络请求更新数据库的一些数据(我们就是这种),而用户可以不必关心任务执行的结果,只要知道任务成功开始执行了就行了。
spooler 的原理
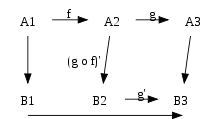
异步任务队列的生产者可以是任何能产生 spool file 的程序,是可以跨语言的。任务用用一个文件夹下面的文件来表示的。指定一个文件夹,一个文件就是一个任务。
后端应用 app 可以往 spool 中放任务(调用 spooler 的 API 生成一个文件),然后uWSGI 启动的时候会将 spawn 出来 spooler 进程,就是 worker,处理这些异步的任务,任务处理成功就将文件删掉。如下图。

尝试 spooler 第一步
首先我们新建一个 django 项目来演示 spooler,方便读者阅读。依赖只有 django 和 uwsgi ,通过 pip 安装即可。然后用 django-admin 开启一个新的项目。需要执行的命令如下:
|
|
➜ [python37] pip install django ➜ [python37] pip install uwsgi ➜ [python37] django-admin startproject demo ➜ [python37] cd demo |
然后我们可以使用 uwsgi 来启动项目了。
|
|
➜ uwsgi --http :9090 --wsgi-file demo/wsgi.py |
可以访问下 localhost:9090 端口看是否启动成功。
将任务放入队列
将任务放入队列我们只要调用 uWSGI 的 spool 函数就可以了。可以接受一个 dict 或者直接是 keyword args。我们在上一步生成的 demo django 项目中写一个向任务队列添加任务的函数如下,直接写在 urls.py 里面了。
|
|
from django.contrib import admin from django.urls import path import uwsgi from django.http import HttpResponse def write_task(request): uwsgi.spool({b'body': b'hello world'}) return HttpResponse('done!') urlpatterns = [ path('admin/', admin.site.urls), path('add_task', write_task), ] |
代码比较好懂,访问 URL add_task 的时候就会调用 write_task 往队列里面 spool 一个任务。其中要注意的是 spool 的内容在 Python3 中必须是 bytes 的。
我们使用下面的命令执行,执行之前,需要先建立 task 文件夹,我们用这个文件夹来存储任务。
|
|
➜ uwsgi --http :9090 --wsgi-file demo/wsgi.py --spooler tasks |
如果你仔细看的话,会发现最后的输出信息如下。
|
|
*** uWSGI is running in multiple interpreter mode *** spawned uWSGI master process (pid: 33651) spawned the uWSGI spooler on dir /Users/laixintao/Program/demo/tasks with pid 33652 spawned uWSGI worker 1 (pid: 33653, cores: 1) spawned uWSGI http 1 (pid: 33654) [spooler /Users/laixintao/Program/demo/tasks pid: 33652] managing request uwsgi_spoolfile_on_Kowalski.local_32914_1_496006739_1536043751_393482 ... unable to find the spooler function, have you loaded it into the spooler process ? [spooler /Users/laixintao/Program/demo/tasks pid: 33652] managing request uwsgi_spoolfile_on_Kowalski.local_33136_1_861157818_1536044162_805038 ... unable to find the spooler function, have you loaded it into the spooler process ? |
确实有了 spooler 的 worker ,而不加 --spooler 参数的话是没有的。
最后的提示是说没有找到 spooler function ,这是因为我们没有写消费者,所以目前任务会被成功放进去,但是不会被执行。可以试一下,访问我们事先定义好的 localhost:9090/add_task。可以看到每访问一次,task 文件夹就会多一个文件。
|
|
➜ [python37] demo curl http://localhost:9090/add_task done!% ➜ [python37] demo ls tasks uwsgi_spoolfile_on_Kowalski.local_33698_6_2054991181_1536044759_292732 ➜ [python37] demo curl http://localhost:9090/add_task done!% ➜ [python37] demo ls tasks uwsgi_spoolfile_on_Kowalski.local_33698_6_2054991181_1536044759_292732 uwsgi_spoolfile_on_Kowalski.local_33698_7_257284366_1536044765_789078 |
其中,spool 函数还有以下特殊的参数,可以满足更多对任务定制的需求。
- ‘spooler’ => specify the ABSOLUTE path of the spooler that has to manage this task
- ‘at’ => unix time at which the task must be executed (read: the task will not be run until the ‘at’ time is passed)
- ‘priority’ => this will be the subdirectory in the spooler directory in which the task will be placed, you can use that trick to give a good-enough prioritization to tasks (for better approach use multiple spoolers)
- ‘body’ => use this key for objects bigger than 64k, the blob will be appended to the serialzed uwsgi packet and passed back to the spooler function as the ‘body’ argument
编写 spooler 函数(消费者)
spooler 相当于是 celery 的 worker,是真正将任务取出来进行处理的部分,实际就是从 uWSGI 设置的 spooler 文件夹处理每一个文件。如果你 spooler 写的不对,或者文件夹配置不对的话,这个文件夹会越来越大,相当于任务积压没有被处理。
uWSGI 是跨语言的,perl,ruby,python 都可以写 spooler。下面是一个 Python 的 spooler 的例子。
|
|
import time import uwsgi def my_spooler(args): time.sleep(5) print(args) return uwsgi.SPOOL_OK uwsgi.spooler = my_spooler |
这里要注意的是,返回的值必须是以下 uWSGI 内置的 int 值:
- -2 (SPOOL_OK) – 任务成功,spool 文件将会被删除
- -1 (SPOOL_RETRY) – 任务失败,将会被重试
- 0 (SPOOL_IGNORE) – 忽略任务,在多语言环境可能导致竞争,使用此返回值可以让某些语言的实例跳过此任务
我们可以将这部分代码保存在项目下面的 worker.py 中。由于这段代码在 uWSGI 启动的时候不会被执行,所以启动命令加一个 --import 参数。
|
|
➜ uwsgi --http :9090 --wsgi-file demo/wsgi.py --spooler tasks --import worker.py *** uWSGI is running in multiple interpreter mode *** spawned uWSGI master process (pid: 34108) spawned the uWSGI spooler on dir /Users/laixintao/Program/demo/tasks with pid 34109 spawned uWSGI worker 1 (pid: 34110, cores: 1) spawned uWSGI http 1 (pid: 34111) [spooler /Users/laixintao/Program/demo/tasks pid: 34109] managing request uwsgi_spoolfile_on_Kowalski.local_33698_6_2054991181_1536044759_292732 ... {'spooler_task_name': b'uwsgi_spoolfile_on_Kowalski.local_33698_6_2054991181_1536044759_292732', 'body': b'hello world'} [spooler /Users/laixintao/Program/demo/tasks pid: 34109] done with task uwsgi_spoolfile_on_Kowalski.local_33698_6_2054991181_1536044759_292732 after 5 seconds [spooler /Users/laixintao/Program/demo/tasks pid: 34109] managing request uwsgi_spoolfile_on_Kowalski.local_33698_7_257284366_1536044765_789078 ... {'spooler_task_name': b'uwsgi_spoolfile_on_Kowalski.local_33698_7_257284366_1536044765_789078', 'body': b'hello world'} [spooler /Users/laixintao/Program/demo/tasks pid: 34109] done with task uwsgi_spoolfile_on_Kowalski.local_33698_7_257284366_1536044765_789078 after 5 seconds |
启动之后可以看到 tasks 文件夹中的文件逐渐消失了,每5s 少一个,同时 uWSGI 打印出了执行记录。
另外,通过 spooler-process 参数可以控制并发量。比如下面这个命令开启 4 个 spooler 进程。
|
|
➜ uwsgi --http :9090 --wsgi-file demo/wsgi.py --spooler tasks --import worker.py --spooler-processes 4 *** uWSGI is running in multiple interpreter mode *** spawned uWSGI master process (pid: 34314) spawned the uWSGI spooler on dir /Users/laixintao/Program/demo/tasks with pid 34316 spawned the uWSGI spooler on dir /Users/laixintao/Program/demo/tasks with pid 34317 spawned the uWSGI spooler on dir /Users/laixintao/Program/demo/tasks with pid 34318 spawned the uWSGI spooler on dir /Users/laixintao/Program/demo/tasks with pid 34319 spawned uWSGI worker 1 (pid: 34320, cores: 1) spawned uWSGI http 1 (pid: 34321) |
一些高级的特性
如果单机有多个 uWSGI 的实例,但是只想启动一个干活的,其他的都只负责 spool 任务。那么可以使用 External spool。
另外放任务的过程,其实就是 uWSGI 打包好一个任务写到一个文件里面,所以如果我们向网络中其他 uWSGI 实例,通过 socket 写入,也是可以的,这样就可以使用 Networked spoolers。
任务权重。在上面的内容中,已经介绍过 spool 函数有一个 priority 参数,可以控制任务的权重。实际上 spooler 在运行的时候,会扫面文件夹,如果扫描到数字,就会优先深度执行数字文件夹里面的内容。但是 uWSGI 执行的时候要加 --spooler-ordered 参数。
比如下面这个 spooler 文件夹的内容:
|
|
/spool /spool/ztask /spool/xtask /spool/1/task1 /spool/1/task0 /spool/2/foo |
实际执行的结果会是:
|
|
/spool/1/task0 /spool/1/task1 /spool/2/foo /spool/xtask /spool/ztask |
其他还支持一些 Options 参数,可以参考文档。
非常重要的 Tips
我是照着 uWSGI 的文档学习的,可以说这个文档很不友好…… 不是按照初学者的路线组织的,纯粹是解释项目组织的,跟一个 wiki 一样,可能是不同的人一直加 feature 然后更新文档导致的吧…… 总之原来的文档最后一段是比较重要的,本文也是。如果你看到一半就关掉这篇文章,那么你惨了……
第一点,如果要在实例之间共享内存,可以使用 uWSGI 的 cache 或者 sharedarea。
第二点,也是比较重要的一点:Python 有 uwsgidecorators.py ,Ruby 有 uwsgidsl.rb 。不要直接用本文介绍的低级 API。
使用优美的装饰器
如果你使用本文介绍的这些函数的话,可能已经发现,只能写一个延时任务,因为你修改的是全局的 uwsgi.spooler 的值。如果要支持多个任务,就要自己写 dispatcher,像参考资料1中做的那样。
uwsgidecorators.py 里面提供了 3 个很有用的函数。
uwsgidecorators.spool 可以帮你自动分发多个任务,用起来非常像 Celery。还可以自动帮你设置返回值(默认是 uwsgi.SPOOL_OK)。
|
|
@spool def a_long_long_task(arguments): print(arguments) for i in xrange(0, 10000000): time.sleep(0.1) @spool def a_longer_task(args): print(args) for i in xrange(0, 10000000): time.sleep(0.5) # enqueue the tasks a_long_long_task.spool(foo='bar',hello='world') a_longer_task.spool({'pippo':'pluto'}) |
uwsgidecorators.spoolforever 功能同上,不同的是此装饰器永远返回 uwsgi.SPOOL_RETRY ,也就意味着这个任务会永远被重试,永远被执行。
uwsgidecorators.spoolraw 这个函数需要用户自己写返回值。
有兴趣的也推荐看一下这些装饰器的源代码。可以看到它会帮你处理很多事情,所以千万不要用原始的 API 啊,装饰器就够了。
参考资料:
- 使用uwsgi实现异步任务 手把手的教程,不错
- uWSGI文档
- uwsgi_tasks 这个项目对 spooler 不太友好的 API 进行了封装