人们经常说TCP建立连接需要三次握手,断开连接需要四次挥手。有次我抓包发现,断开连接只抓到了三个包。
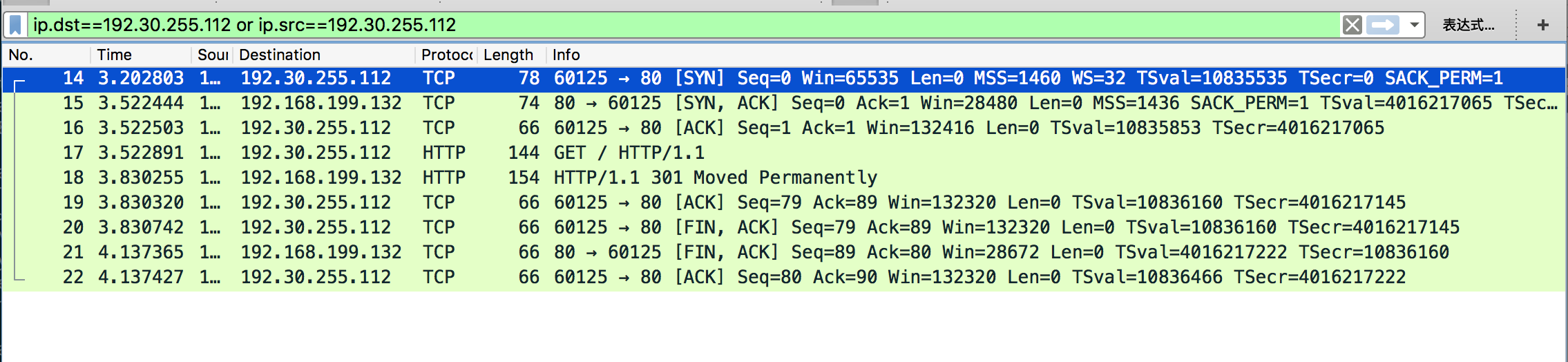
上图中可以看到,20号是一方发送的TCP包,FIN 表示“我这边没有数据要传输了”,然后经过20、21、22三个包,双方断开连接。回顾一下教科书上的断开连接过程:
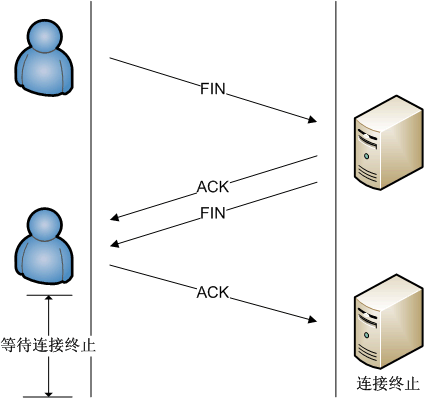
于是可以看到,上图中抓的包实际上是将ACK和FIN组合成一个包发送了,所以三个包就可以断开连接。维基百科的资料表示三个包断开连接也是可以的。
也可以通过测三次握手关闭连接。主机A发出FIN,主机B回复FIN & ACK,然后主机A回复ACK。
TCP要求,每一个发出去的包必须收到确认(ACK)。但实际上,并不会对每一个包发回一个单独的ACK,因为ACK和ACK标志位和数据段在不同的位置,所以数据和ACK是可以一同发的。Stack Overflow有一个很好看的ASCII图,我也贴一下。
TCP要求包收到ACK确认:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
+-------------------------------------------------------+ | client network server | +-----------------+ +--------------------| | (connect) | ---- SYN ----> | | | | <-- SYN,ACK -- | (accepted) | | (connected) | ---- ACK ----> | | \_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/ when client sends... \_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/ | | | | | (send) | ---- data ---> | | | | <---- ACK ---- | (data received) | \_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/ when server sends... \_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/ | | | | | | <--- data ---- | (send) | | (data received) | ---- ACK ----> | | \_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/ ...and so on, til the connection is shut down or reset |
但实际上:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/ | | | | | | <--- data ---- | (send) | | (data received) | | | | (send) | -- data,ACK -> | | | | | (data received) | | | <- data,ACK -- | (send) | | (data received) | | | | (wait a bit) | <--- data ---- | (send) | | (data received) | | | | (send) | -- data,ACK -> | | | | | (data received) | | (send) | ---- data ---> | (wait a bit) | | | | (data received) | | | <- data,ACK -- | (send) | | (data received) | | | | (wait a bit) | (dead air) | | | | ---- ACK ----> | | \_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/\_/ |
但实际ACK的情况还要复杂……我就不跑题了。
于是我就有了一个疑问,就是能否将第三次ACK的传递省略,等下一次有数据传送的时候再带上ACK传过去,不可以吗?
首先回顾一下TCP握手的原理,建立连接的目的是:1.表达一方企图建立连接的意图(SYN)2.表达知道对方的意图(ACK)。其实就是A发送SYN表示自己想要建立连接,B发送ACK表示知道了。然后B发送SYN表示想建立连接,A发送ACK表示自己知道了。向我们上面断开连接的三个包一样,B可以同时发送SYN+ACK,这样就是我们现在看到的三个包。
那么如果不发送第三个包,等下一次传输数据的时候带上ACK呢?
网上的解释基本都是这样的:
“已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。”
但并没有彻底解决我的疑问。比如A和B想建立连接,上述的解释只是意图保护B的资源,如果我是A,那么我这边是的实现是否可以做成不发送ACK而是带数据一同发送过去?
这里我们可以考虑一下如果有第三次包,但是第三次包ACK丢失的情况:
A发完ACK,单方面认为TCP为 Established状态,而B显然认为TCP为Active状态:
- 假定此时双方都没有数据发送,B会周期性超时重传,直到收到A的确认,收到之后B的TCP 连接也为 Established状态,双向可以发包。
- 假定此时A有数据发送,B收到A的 Data + ACK,自然会切换为established 状态,并接受A的 Data。
- 假定B有数据发送,数据发送不了,会一直周期性超时重传SYN + ACK,直到收到A的确认才可以发送数据。
(摘自知乎)
所以从这里看来,如果发起连接放有意不发送ACK,而是等下一次带上数据发送,也是能够成功建立连接的。我自己认为这里面没有逻辑问题,在网上搜索了一些资料,想得到确认。
果然,有人在wireshark论坛贴了一个问题,说自己抓到的包在TCP三次握手中,第三次ACK带着数据。有人回复说:如果在收到对方的第二次包SYN+ACK之后很快要发送数据,那么第三次包ACK可以带着数据一起发回去。这在Windows和Linux中都是比较流行的一种实现。但是数据的大小在不同实现中有区别。
而在TCP fast open中,是明确说最后的ACK是可以带有数据的:
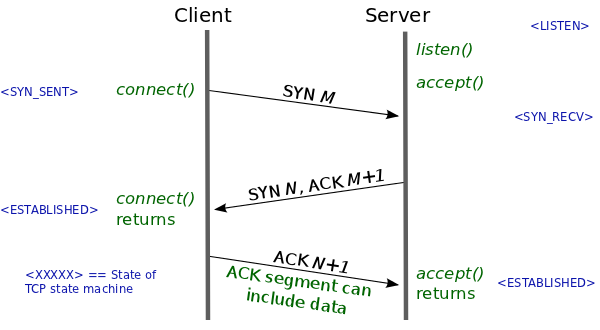
更让我惊讶的是,在原先的RFC 793描述的TCP连接建立过程中,甚至第一个包SYN也是可以带有数据的!这篇博客中有描述。但如果这样做的话,直到连接建立完成,第一次包带的数据都不能释放。所以我觉得现在的实现都没有这样做的原因是,包是节省了一些,但维护连接建立的成本更大了,更容易被SYN洪水攻击。
所以综上,TCP能不能通过两个包建立连接?不能。但是第三次ACK可以带有数据。但是ACK是必须发的,必须让对方知道自己的连接建立意图。如果收到对方第二个包SYN+ACK马上有数据要发送,那么就可以发送第三次ACK+数据;如果没有数据要发送,那么要给对方回复一个ACK,完成连接的建立。