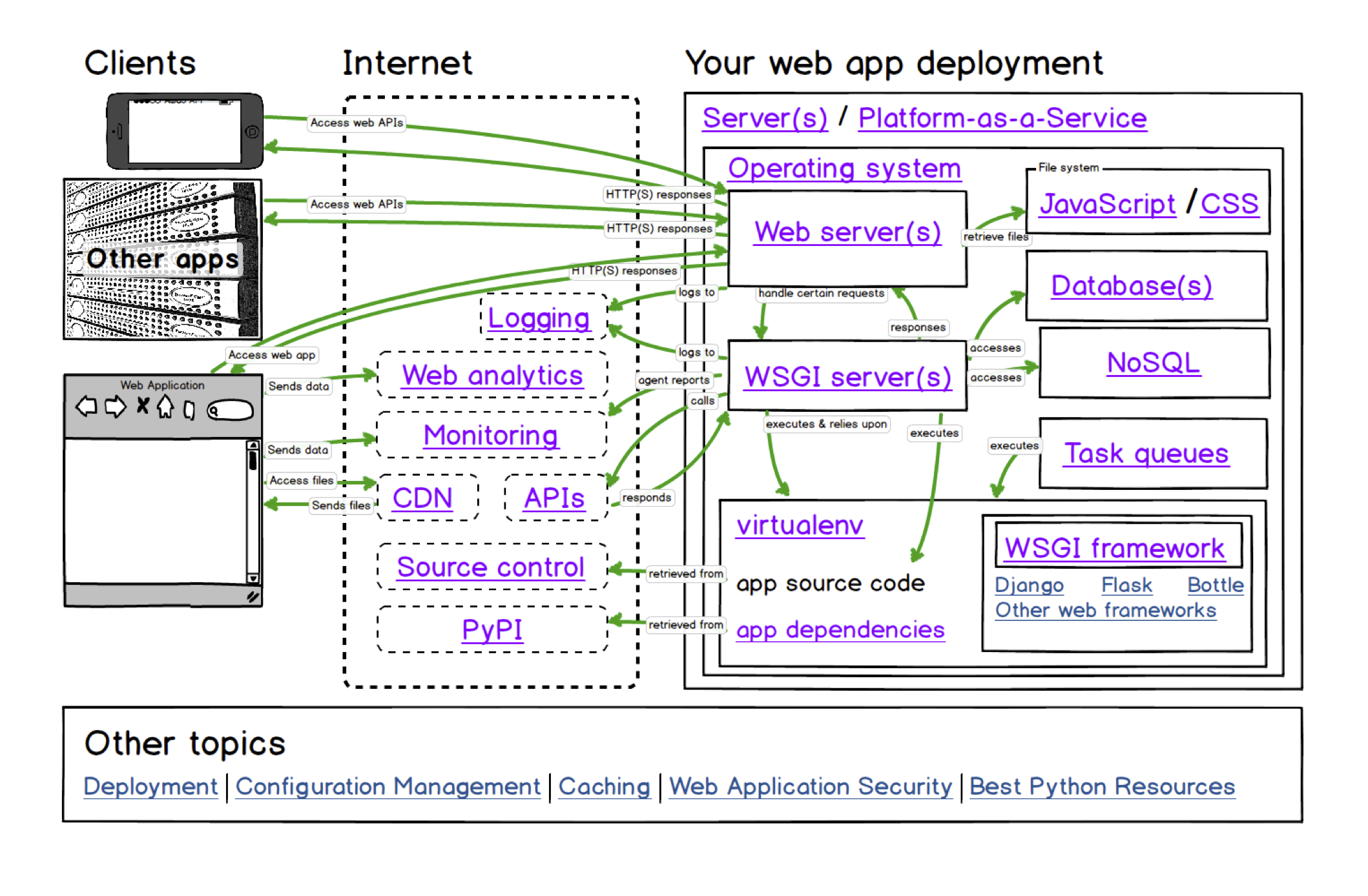
最近空闲时间在看 PyCon 的一些分享,2018年的视频好多,不知道啥时候才能看完。这里将一些个人看过比较好的记录一下。上一次的文章在这里:PyCon2018 Review (Part 1)
5. GC再见,GC你好——Instagram Django进程调优案例
当初 Instagram 禁用 GC 的那篇文章发布之后,声名大噪。Zekun Li 在大会上讲了一下 Instagram 在 Python GC 上下的功夫。起先因为 GC 回收循环引用的问题,共享内容用的少,fork 出来的进程会占用很多内存,于是 Instagram 就想办法禁用了 GC,这样可以减少 Copy-on-Write 需要复制的内存,当然禁用了 GC 肯定会有内存泄漏的问题,Instagram 的选择是保证代码质量,避免在代码中使用循环引用。然而虽然项目增长,这样严格的代码质量难以保证,Instagram 又打开了GC。
演讲者听口音应该是大陆人,这个视频有助于对内存的理解,值得一看。
推荐指数:5
演讲者:Zekun Li from Instagram
相关项目:Django, uWSGI
Youtube: Zekun Li – There and Back Again: Disable and re-enable garbage collector at Instagram – PyCon 2018
6. 一份简单的 Pythonic 指南
我见过很多人写的带有“Java味道”的 Python 代码,里面很多复杂的抽象和继承关系;在循环里自己维护下标等行为,实在头疼。这个演讲适用于新手或者从其他语言过来的人,可以快速过一下 Python 的一些不错的特性。对于写了很长时间的 Python 程序员来说,可能用处不大。吐个槽:整天被业务赶着,时间长了危害实在是大,不抽出时间看看自己的工具都有什么不错的功能,就永远不会有什么长进。
演讲者来自微软,是一位女性,比较好懂。
推荐指数:4
演讲者:Nina Zakharenko
相关项目:The Zen of Python, agithub, freezegun
Youtube: Nina Zakharenko – Elegant Solutions For Everyday Python Problems – PyCon 2018
7. 打一场值得打的仗:Facebook 的 Python 3迁移之路
现在 Facebook 的大多数项目都是运行在 Python3.6.3 上面的,但是到 2014 年,在 Facebook 内部使用 Python3 几乎是不可能的事情,大部分工程师都持 “我们将永远使用 Python2.7 的态度。一小部分人用业余时间驱动了公司向 Python3 迁移,看本篇演讲,学习如何在你的公司打一场值得的仗。变化不会自己发生,必须有人来引导做出改变。在迁移的过程中,作者首先面对的是 Facebook 所有的 build 系统都是针对 Python2.7 的,只好去一个一个修复,兼容 Python3.然后又要面对同事不停地提交 Python2 代码,作者又加入了 pyflake 检查。(一个小技巧,如果你在你们公司装的很权威,那么别人就会以为你在这方面是权威人士)
后来一些项目只是运行了 2to3,没做其他改变,结果导致因此占用内存降低了一半,运行速度提升了 40%。
Educate for the future you want, not the present you have.
美中不足的是,演讲者经常停顿和重复,对于我来说理解起来不是那么简单。
演讲者:Jason Fried
推荐指数:4
相关项目: 2to3, pyflake
Youtube: Jason Fried – Fighting the Good Fight: Python 3 in your organization – PyCon 2018
8. 字典技术的演化
这个视频是 laike9m 上次在线下给我推荐的,同样不是一个今年的 Pycon 视频,但是号称是“质量最高的一个演讲”,回来看了一下,真的很不错。
大家可能都有听说,Python3.6 里面字典的速度和内存都有了提升,同时带来一个副作用:默认有序了。并且这个副作用在 3.7 版本中写入了语言标准。Raymond 这个演讲涉及了字典的很多常见的技术,例如 Key Sharing,Open Addressing,Double Hashing 等,从头到尾展示和这些技术的演化过程、性能和原理等,介绍了 Python 的 dict 从一开始浪费内存、速度慢进化到了今天的甚至对 key lookup 有缓存。Python 基本是运行在字典上面的,即使有时候我们的感知很弱:module 是一个字典,global 是一个字典,Django 是运行在无数的字典上的,所以如果你优化了字典,你就优化了 Python。相比于 Python2.7,如果你不用 AsyncIO,你可能没有特别的理由升级到 Python3.5,但是 Python3.6 提升了 dict 的性能,这就很划算了。新的 dict (compact dict)使用 list 来存储字典的 key(这样空的位置只需要 8bytes 就够了),减少的空间同时也可以加快 hash 表的载入速度。字典还涉及到一些细节问题,比如删除元素,最后的 QA 也有很多干货。
有意思的是,Raymond在2016年就提到:Guido 目前还认为字典的 key 保持插入顺序这个特性还不能被依赖,但是他会被说付的,简直是预测帝啊。

演讲非常搞笑,Raymond 对自己的 Compact Dict 太满意了哈哈哈哈哈。

另外,我之前也花了很多时间研究字典一些相关的问题,看视频之前也可以看一下我写的这两篇博客,可能加深你对字典的理解,我自认为写的还是比较好懂的:《Hash碰撞和解决策略》、《Python 为什么list不能作为字典的key?》
演讲者:Raymond Hettinger(资深Python讲师)
推荐指数:5
相关项目:builtin dict
Youtube:
一共找到两个版本,建议都看一下,67分钟版本更早,里面比较轻松,PyCon 那个比较正式,更加条理。不过67分钟版本的后面有很多 QA,也很有价值。
- PyCon2017 37分钟版本:Raymond Hettinger Modern Python Dictionaries A confluence of a dozen great ideas PyCon 2017
- 2016年的67分钟版本:Modern Dictionaries by Raymond Hettinger
最后赠送一个我最近在听得一个 podcast(macdavid推荐的):teahour ,内容不错,挺丰富的,从区块链到编辑器都有,很适合程序员。