Python的property可以让我们很方便地将一个object的函数当做一个属性来操作,可以赋值、读取。
|
|
class Parrot: def __init__(self): self._voltage = 100000 @property def voltage(self): """Get the current voltage.""" return self._voltage p = Parrot() p.voltage # 100000 |
但是不支持class,如果想使用这个特性,就要实例化对象。我去参考了celery实现的class_property,发现有一行特别难懂,花了很长时间琢磨,终于是看懂了。
celery的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
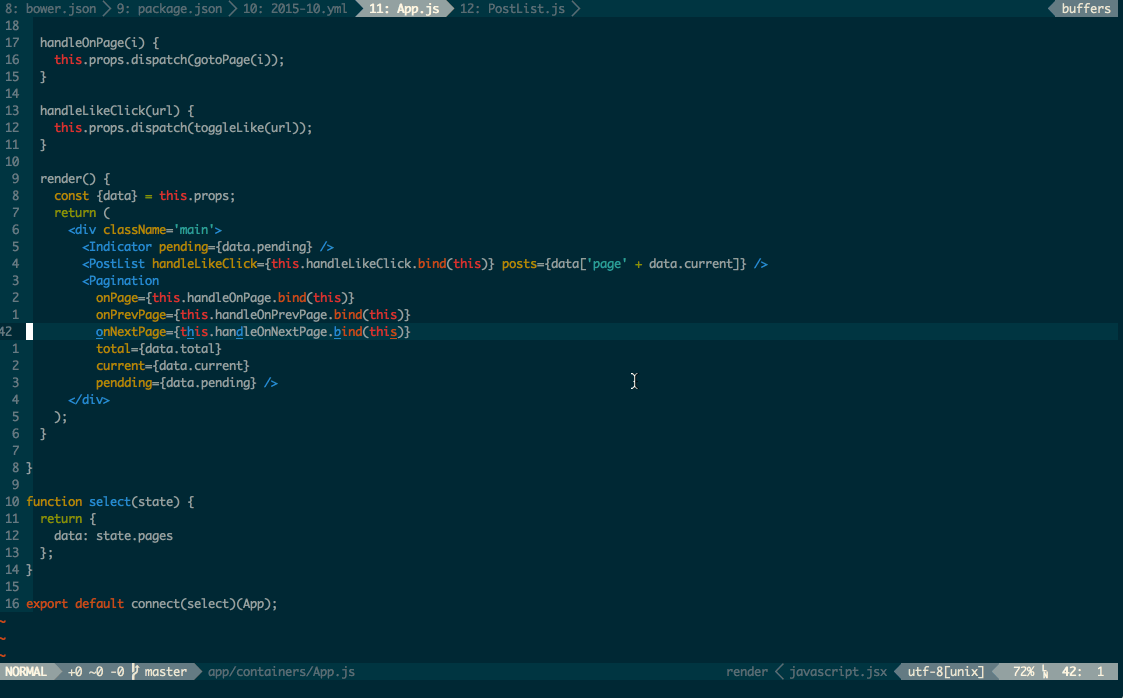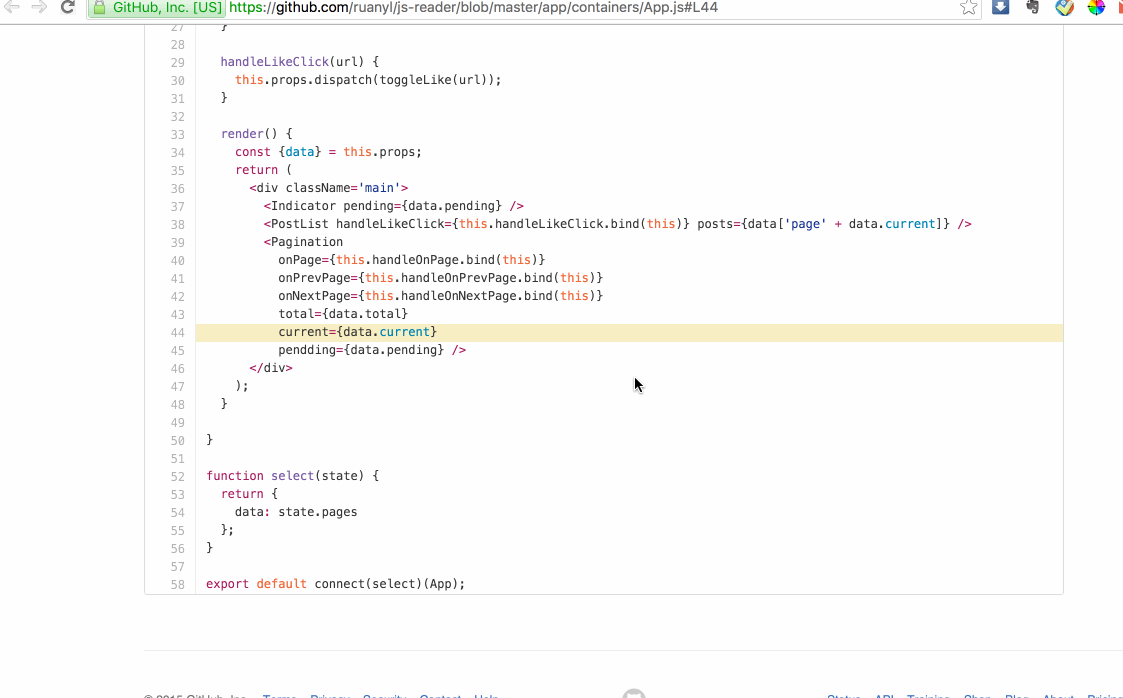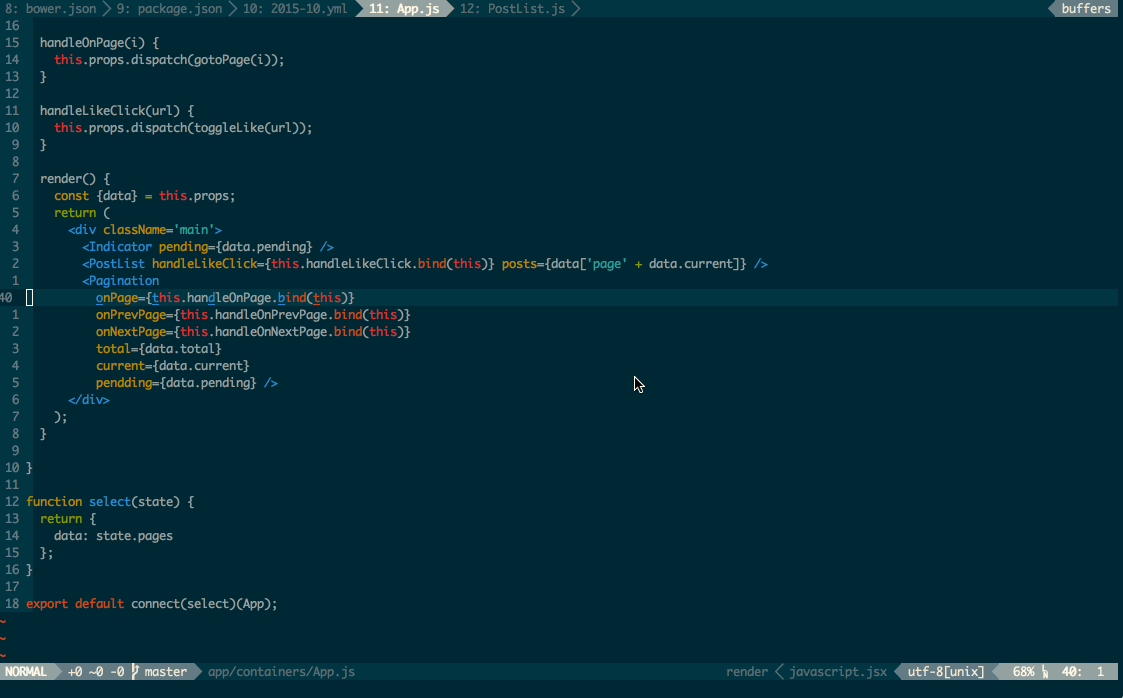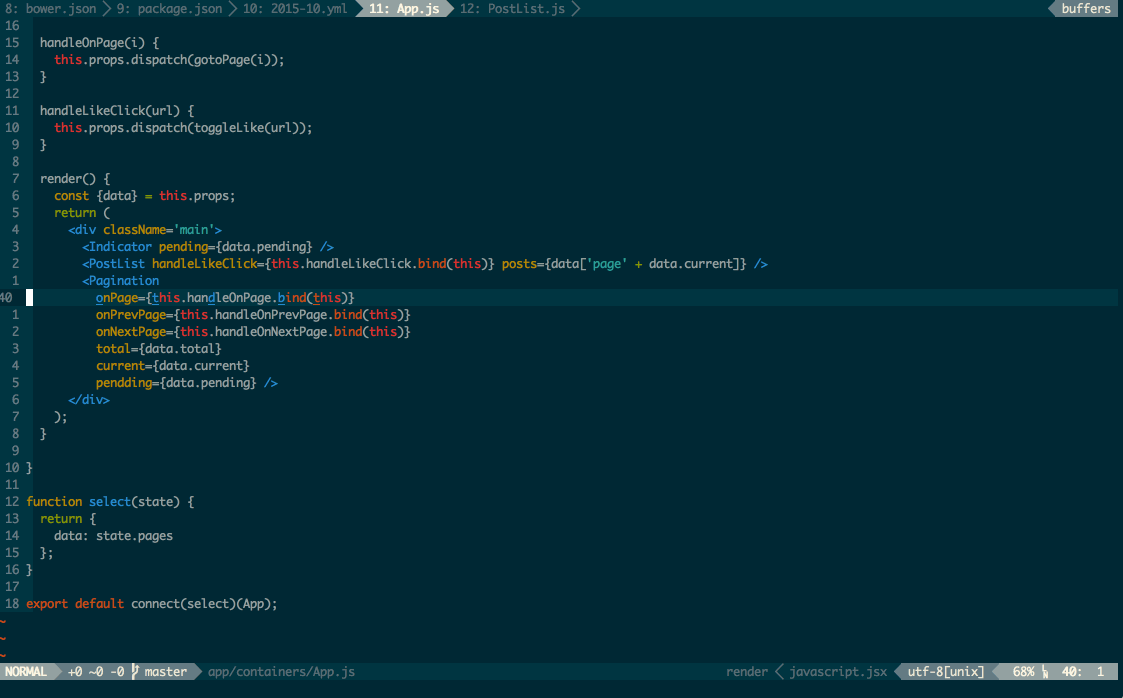
class class_property(object): def __init__(self, getter=None, setter=None): if getter is not None and not isinstance(getter, classmethod): getter = classmethod(getter) if setter is not None and not isinstance(setter, classmethod): setter = classmethod(setter) self.__get = getter self.__set = setter info = getter.__get__(object) # just need the info attrs. self.__doc__ = info.__doc__ self.__name__ = info.__name__ self.__module__ = info.__module__ def __get__(self, obj, type=None): if obj and type is None: type = obj.__class__ return self.__get.__get__(obj, type)() def __set__(self, obj, value): if obj is None: return self return self.__set.__get__(obj)(value) def setter(self, setter): return self.__class__(self.__get, setter) |
使用方法如下:
|
|
class Logging: @class_property def already_setup(self): return True Logging.already_setup # True |
这段代码能work,而是没有任何问题。装饰在class内的一个函数上,可以将此函数的返回值作为一个class的属性,可以通过class和instance来访问,并且还支持setter。
首先,__init__()比较好理解,传入getter和setter,将其转换为classmethod然后绑定到内部的变量上,以便后来调用。
setter()方法也比较好理解,可以当做装饰器调用, 然后已有的self.__get和传入的setter重新初始化一个class_property,如果已经有getter的话,这里也不会对getter造成影响。参考下面的例子:
|
|
@already_setup.setter # noqa def already_setup(self, was_setup): self._setup = was_setup |
然后看__get__和__set__方法,很明显,这里使用的描述器。(关于描述器,我之前有一篇博文详细讲了描述器——理解Python对象的属性和描述器。)第一个if判断是为了确保用class_property装饰的属性通过instance也能访问到。
最后到了最让人不理解的部分了,如果要我实现的话,是直接返回getter就可以了:
return self.__get()
这样看起来也没问题:访问Logging类的时候,发现没有这个already_setup这个属性,然后试图访问描述器,描述器__get__()中返回self.__get()不正好是getter会返回的结果吗?
于是我将这行return改成了上面我的意思,结果报错:
|
|
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-20-6db509700877> in <module>() ----> 1 class_property(Logging.already_setup)() <ipython-input-14-9345a093811c> in __get__(self, obj, type) 20 print(self.__get) 21 print(self.__get.__get__(obj, type)) ---> 22 return self.__get(obj) 23 24 def __set__(self, obj, value): TypeError: 'classmethod' object is not callable |
classmethod为什么不是callable的呢?因为classmethod本来就不是callable的!在之前的文章中,我模拟了classmethod的实现:
|
|
class ClassMethod(object): "Emulate PyClassMethod_Type() in Objects/funcobject.c" def __init__(self, f): self.f = f def __get__(self, obj, klass=None): if klass is None: klass = type(obj) def newfunc(*args): return self.f(klass, *args) return newfunc |
它的原理是这样的:Class读一个属性的时候,如果Class.__dict__有该属性并且属性不是一个描述器,就返回该属性;如果该属性是一个描述器,就调用它的__get__方法。
举个例子说,下面的代码:
|
|
class Foo: @classmethod def bar(cls): return "hello" Foo.bar() # hello |
在调用的时候,先看Foo.__dict__里面的bar是一个描述器,那么调用就转换成:
Foo.__dict__['bar'].__get__(None, Foo)()
回到我们的class_property上来,拿最初的Logging举例。用了class_property装饰的already_setup使用起来(Logging.already_setup)就是:
Logging.__dict__['already_setup'].__get__(None, Logging)()
执行我们的class_property的__get__之后,也就是
Logging.__dict__['already_setup'].__get()
此时,橙色的部分拿到的是一个class_property处理之后的classmethod,而上面我们可以看到,classmethod并不是callable的,而是通过描述器协议,class在调用的时候会默认调用__get__,然后拿到一个和class绑定之后的func,这时候的func才是可以调用的。
celery里面原来写的return,调用链展开就是:
Logging.__dict__['already_setup'].__get.__get__(obj, type)()
其中橙色的部分依然是拿到了classmethod,即:
Logging.classmethod_get.__get__(obj, type)()
classmethod的__get__()返回的是一个unbound method,即
Logging.already_setup()
这样调用就没问题了。
所以说,这里手动调用__get__(obj, type)的原因是,描述器协议之能调用一次,如果返回的还是一个描述器,那么并不会继续调用__get__方法,需要手动调用。