在上一篇文章中我们讨论了 active-backup 的模式,能够在一张线路出现故障的时候快速切换,配置也比较简单。但是这种方式有一个很大的缺点——就是明明我有两张卡,但是一次只能使用一张,只有在这张卡挂了的时候才使用另一张。
这样很浪费,我们花了两张卡的钱,希望能用两张卡。我们想要的是两张卡都在工作,当其中一张卡挂了的时候,退回到使用一张卡。
在高可用的设计中,双活优于主备,主备意味着浪费。
这篇文章我们来讨论如何能让两张卡都工作。
Balance-tlb (Adaptive transmit load balancing, mode 5)
我们还是通过流量的入和出两个方向分开讨论。
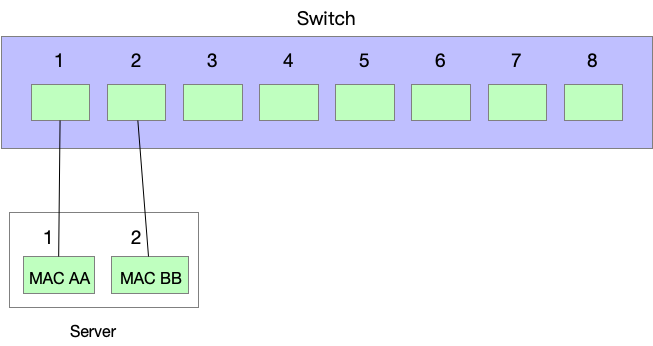
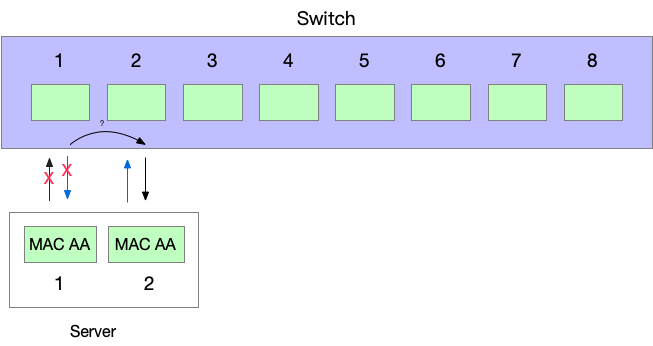
假设想要两张卡都使用,对于出方向的流量,前文提到过 MAC flapping 问题:如果同一个 MAC 一会从端口 1 发出去流量,一会从端口 2 发出流量,交换机通过收到的包学习 MAC 地址会感到困惑。所以,如果两个 interface 都往外发送数据的话,不能使用相同的 MAC 地址。
这样,问题就解决了:对于发出去的流量,我们可以用两个 interface 来发,两个 interface 使用不同的 MAC 地址,对于交换机来说,就像是两个不同的主机。
对于接收流量,我们还是只能用一个 interface 来接收。这一点怎么做到呢?还记得别人是怎么发送流量给我们的吗?需要先发送 ARP 通过 IP 获得 IP 对应的 MAC 地址,然后才能将这个 MAC 封装为二层帧的目标来发送。所以,在回应 ARP 请求的时候,我们总是使用其中一个 interface 的 MAC 地址来回复。
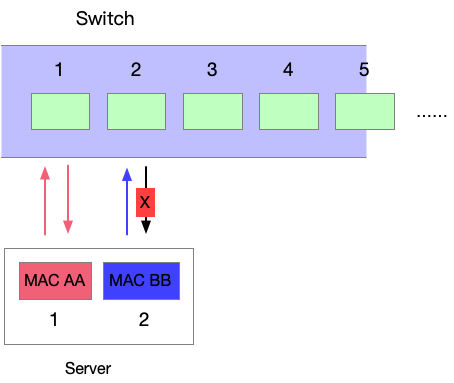
如此,我们就实现了 Transmit Load Balancing (balance-tlb):
- 对于发出去的流量,我们使用两个 interface。但是我们需要某种 hash 的机制,保证同一个 TCP 流总是走同一个 interface,不然就可能带来 reorder 问题,影响性能;(实际上,balance-tlb 模式不是简单的 hash,而是会根据两张卡的负载动态调整使用哪张卡来发)
- 对于接收流量,由于其他的客户端只知道 IP 对应一个网卡的 MAC 地址,所以入流量总是会走到其中一个 interface 上;
- 在交换机看来,有一个主机的 MAC 地址只会发出去包,但是从来没有其他人发给这个 MAC,像是一个孤独的可怜人。
虽然这样只是发出去的流量可以充分用两张卡,还是没有完全利用上手里的两张卡,但是已经比较好了。因为对于面向客户的武服务器来说,进入服务器的流量很少(请求一般都比较小),从服务器出去的流量比较多(响应一般很大),像短视频服务器,流媒体,HTTP 服务器等,尤其如此。所以这种方案是可以解决一定的问题的。
Failover 流程
现在我们有两个 interface 在工作,接收流量的叫做主,不接受流量只发送的叫做备。
假设备挂了,那么很简单,接收端不受影响。发送端只要切换到只用主来发就可以了。
假设主卦了,那么发送端要切换到只使用备来发,并且接收端的流量也要切换到备上面。
接收端的流量如何切换呢?我们现在有两个 MAC 地址,切换接收端流量,就要让发送流量的地方来切换。一个很直观的解决思路是切换 ARP。即,让其他的发送者知道,现在应该发送给另一个 MAC 地址了。但是 ARP 太慢了,在 ARP 更新到发送者那里之前,流量都会因为发送到了挂掉的 MAC 地址而被丢弃掉。
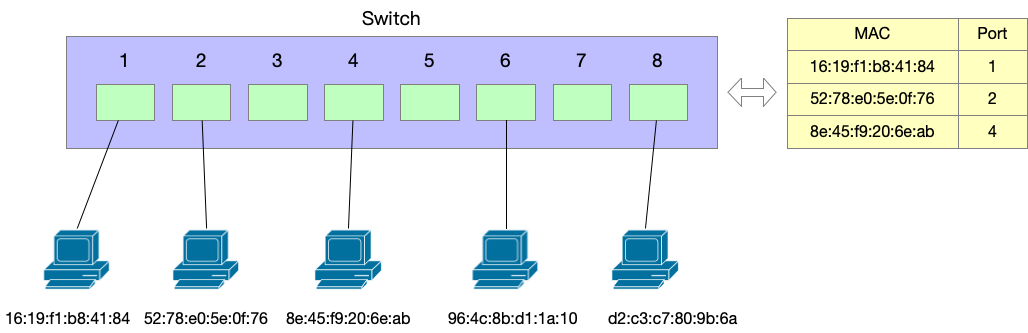
那么有没有更快的切换方式呢?发送者的流量是发送给交换机,交换机再发送给我们的。所以一个更好的解决办法是让交换机来切换,交换机原来通过端口1发给我们,现在通过端口2发送我们。如果要实现快速切换,就要求不涉及去通知发送者,发送者还是使用原来的 MAC 地址进行发送。客户端的目标 MAC 地址不能变,但是交换机转发的端口改变,这不就和我们在 数据中心网络高可用技术之从服务器到交换机:active-backup 中讨论的 Gratuitous ARP 一样吗?不过这里需要额外做的事情是,我们的主 MAC 地址所在的 interface 已经挂了,这个 MAC 地址原来在 interface A 上,现在要转移到 interface B 上,需要交换两个 interface 的 MAC 地址。(所以,balance-tlb 模式需要硬件支持改写 MAC 地址才行。)
总结一下这个切换过程,我们要保持主 MAC 地址总是可用来做到不影响 ARP 缓存,快速切换,那么就要:
- 交换主和备的 MAC 地址,这样主 MAC 地址迁移到了备上,继续存活;
- 通过备 interface (现在的主)发送一个 GARP,让交换机来更新 Mac address table,对于目标 MAC 原先发送给端口1,现在发送给端口2.
演示
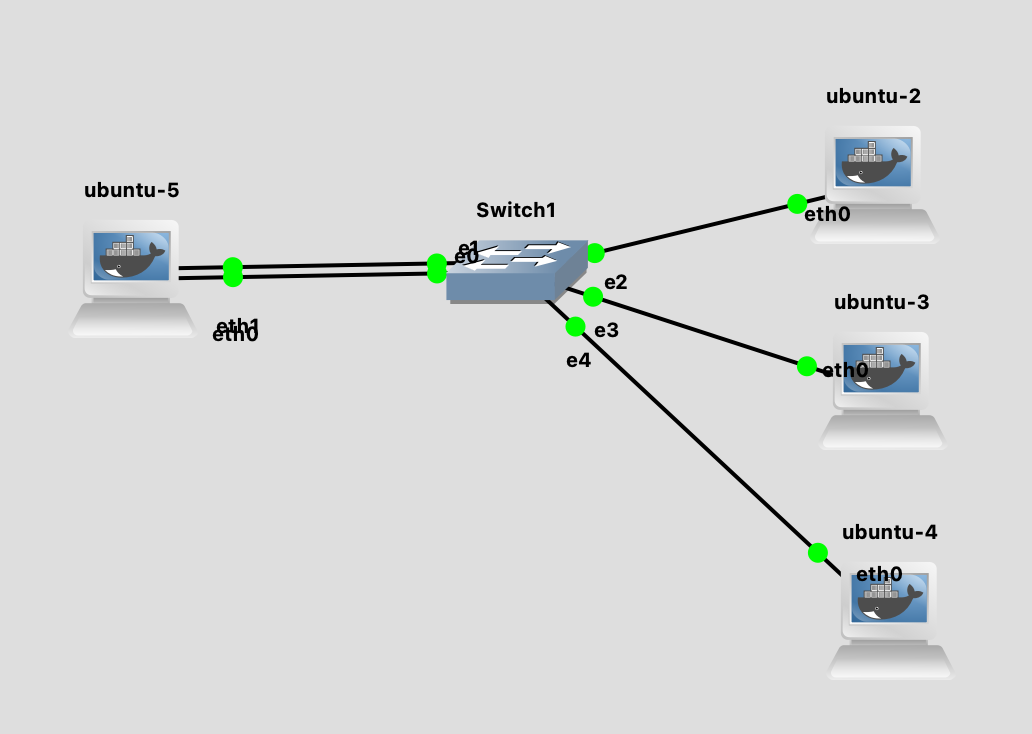
我们使用如下的拓扑图来演示,在 ubuntu-5 上面开启 balance-tlb bonding 模式,其他的 ubuntu 作为普通的客户端。
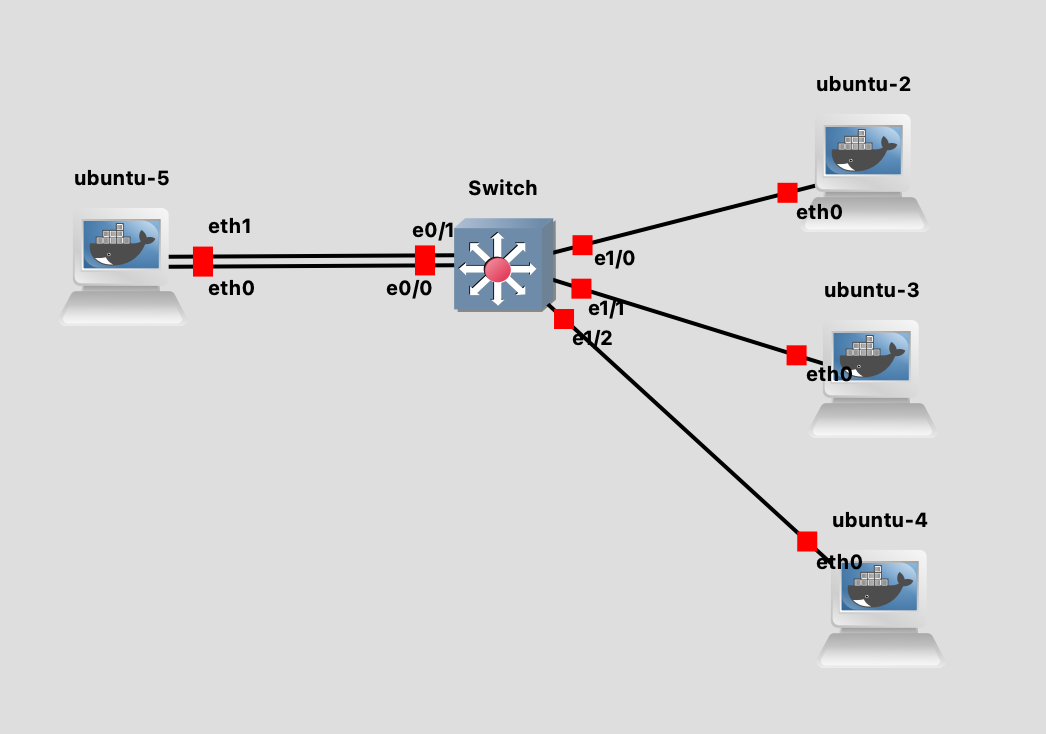
在 ubuntu5 上配置 bonding 的命令如下:
|
1 2 3 4 5 6 7 |
ip link add bond0 type bond mode balance-tlb ip link set eth0 down ip link set eth1 down ip link set eth0 master bond0 ip link set eth1 master bond0 ip link set bond0 up ip add add 192.168.1.10/24 dev bond0 |
查看网卡的信息,可以看到 bond0 interface 的 MAC 地址是和其中的一个 slave eth0 一样,这个 MAC 地址是不能挂的。eth0 这个 interface 也是当前主要的 interface,它会接收 inbond 流量。
|
1 2 3 4 5 6 7 8 9 |
root@ubuntu-5:/$ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 1a:50:9c:11:58:a3 brd ff:ff:ff:ff:ff:ff 35: eth0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bond0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 1a:50:9c:11:58:a3 brd ff:ff:ff:ff:ff:ff 36: eth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bond0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 9e:fa:f1:b5:0c:28 brd ff:ff:ff:ff:ff:ff |
如果其他客户端查询 192.168.1.10 对应的 MAC 地址,也是拿到的这个主 MAC 地址 1a:50:9c:11:58:a3,不会知道另一个 MAC 地址。
|
1 2 |
root@ubuntu-4:/$arp -a | grep 192.168.1.10 ? (192.168.1.10) at 1a:50:9c:11:58:a3 [ether] on eth0 |
我们在 ping 的同时,手动 down 掉 eth0. 会看到 1a:50:9c:11:58:a3 这个地址迁移到了 eth1 上来。
|
1 2 3 4 5 6 7 8 9 10 |
root@ubuntu-5:/$ip link set eth0 down root@ubuntu-5:/$ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 1a:50:9c:11:58:a3 brd ff:ff:ff:ff:ff:ff 35: eth0: <BROADCAST,MULTICAST,SLAVE> mtu 1500 qdisc fq_codel master bond0 state DOWN mode DEFAULT group default qlen 1000 link/ether 9e:fa:f1:b5:0c:28 brd ff:ff:ff:ff:ff:ff 36: eth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bond0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 1a:50:9c:11:58:a3 brd ff:ff:ff:ff:ff:ff |
与此同时,ping 也没有失败。
这个方案可以在发送方向使用两张卡,也能做快速的自动切换。有没有办法能够在接收方向也能用上两张卡呢?
Balance-alb 模式 (adaptive load balancing, mode 6)
要想让收到的流量也负载均衡,就涉及到发送者了。因为我们作为流量的接收方,有两个 MAC 地址,对于让流量发送到哪一个 interface 来说无能为力。
发送者是怎么决定发给哪一个 MAC 的呢?又回到了 ARP。
那么我们现在有两个 interface,分别有两个 MAC 地址,我们希望这两张 interface 各收到 50% 的流量,可以该怎么做呢?对于两个 MAC 地址,可以让 50% 的发送者发给 MAC AA,另外的 50% 的发送者发送给 MAC BB。具体来说,就是在响应 ARP 的时候,我们有时对别人说,这个 IP 对应的 MAC 地址是 AA,有时说此 IP 对应的是 BB。这样就可以对流量做到一定程度的负载均衡。这种方法叫做 ARP negotiation。
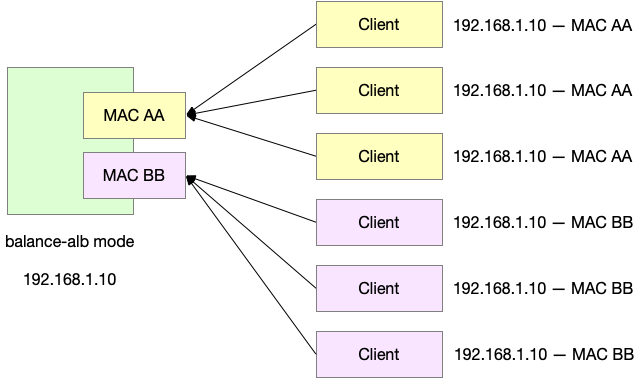
是不是有点像使用 DNS 做负载均衡?
这里面有几个技术难点。
首先,我们在回答 ARP 问题的时候,对于相同的 Client,要给出相同的答案。不能让人家一会发送到 MAC AA,一会又发送到 MAC BB,这样可能造成 TCP 乱序影响性能,对于负载均衡也不好,无法保证两个 interface 收到的流量是均衡的。这个问题的解决方法就是追踪我们回复给不同的客户端什么 MAC 地址,后续对于此客户端都回复一样的 MAC 地址。
第二个问题更难。主机得到 IP 和 MAC 之间的对应关系,不光是靠发出去 ARP 问题来询问,还会从收到的 ARP 问题中学习。当一个主机 Z 收到 ARP 问题:「谁有 xx 的地址,如果有的话,请告诉 192.168.1.10,192.168.1.10 的 MAC 地址是 YY。」不管这个主机 Z 有没有 xx 的地址,它都会从这个问题中学习到:192.168.1.10 对应的 MAC 地址是 YY,并且缓存在自己的 ARP 缓存中。
|
1 |
1a:50:9c:11:58:a3 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 58: Request who-has 192.168.1.14 tell 192.168.1.10 |
这样做可以减少很多 ARP 查询,假设主机要发送给 192.168.1.10 内容,或者要发送 ARP reply 的时候,就不必再通过 ARP 协议来询问 192.168.1.10 的 MAC 地址了,可以直接根据自己的 ARP 缓存进行发送。
但是这对我们的 balance-alb 来说很糟糕,我们好不容易骗一半的客户端认为我们的 MAC 地址是 AA,一半认为是 BB,一旦我们要询问 ARP,好了,所有的人都知道我们的 MAC 地址是 AA(或者 BB)了,接收的流量又全部去了一条线路上。
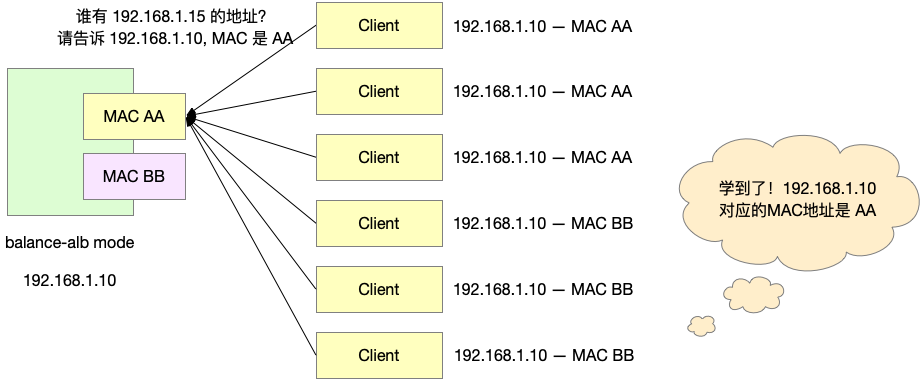
有什么方法能让我们在询问 ARP 的时候,不要让别人学习到同一个 MAC 地址呢?既然我们已经追踪了之前回复给所有客户端的 MAC 地址,能否在发送 ARP 问题的时候,对于一半的客户端使用 AA 来询问,另一半使用 BB 来询问?
这是不可行的,因为我们询问 ARP 的时候,不是发送 N 个请求出去询问 N 个客户端,而是发送一个广播包给交换机,交换机帮助我们广播给 N 个客户端。所以对于一个 ARP 问题,我们发出去的只有一个包而已,无法对于不同的客户端区别对待。
这样看来 ARP 问题刷新所有人的缓存是无法避免的了。我们能做的,只有是在刷新这些缓存之后,重新修正部分客户端的 ARP 缓存。即,我们在我们的 ARP 问题收到回复之后,再对所有人发送一个 Gratuitous ARP,使用自己不同的 MAC 地址告知这些客户端。
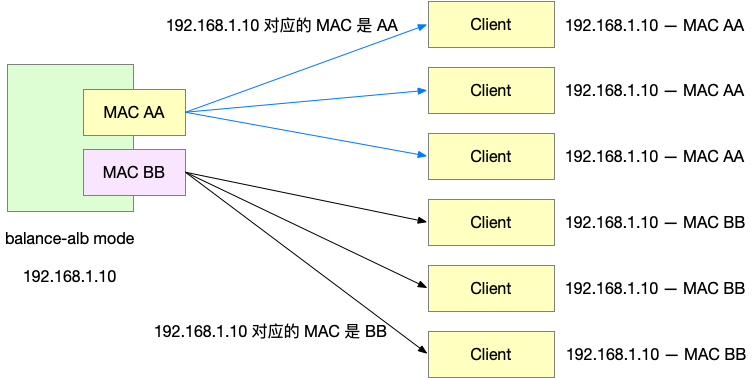
之前我们学到的 Gratuitous ARP 发送的是(不求答案的)问题,为的是更新交换机的 MAC – 端口对应关系。而在这里,我们需要更新的是客户端的 IP-MAC 地址对应关系,所以我们要发送的是(没有人问的) ARP reply。Gratuitous ARP 不仅可以是问题,也可以是 reply。当其他主机收到这个 ARP reply 的时候,会有些奇怪,但是他们也会更新自己的 ARP 缓存「我没有问你呀,为什么要告诉我你的 IP 对应的 MAC 是 xx,算了,我先记下吧。」
实验
还是上面的拓扑图,配置命令也几乎一样。唯有 mode 现在改成了 balance-alb。
|
1 2 3 4 5 6 7 |
ip link add bond0 type bond mode balance-alb ip link set eth0 down ip link set eth1 down ip link set eth0 master bond0 ip link set eth1 master bond0 ip link set bond0 up ip add add 192.168.1.10/24 dev bond0 |
配置好之后,我们在 ubuntu-5 上面查看 link,结果和之前也是一样的。
|
1 2 3 4 5 6 7 8 9 |
root@ubuntu-5:/$ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 3: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 1a:50:9c:11:58:a3 brd ff:ff:ff:ff:ff:ff 35: eth0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bond0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 1a:50:9c:11:58:a3 brd ff:ff:ff:ff:ff:ff 36: eth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bond0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 9e:fa:f1:b5:0c:28 brd ff:ff:ff:ff:ff:ff |
但是我们去另外的两台机器分别查看 ARP 记录,有趣的就来了,不同的机器显示相同的 IP 有不同的 MAC 地址:
|
1 2 |
root@ubuntu-3:/$arp -a ? (192.168.1.10) at 9e:fa:f1:b5:0c:28 [ether] on eth0 |
|
1 2 |
root@ubuntu-4:/$arp -a ? (192.168.1.10) at 1a:50:9c:11:58:a3 [ether] on eth0 |
然后我们在 ubuntu-5 尝试发出去一个 ping 包,并且在这两台机器抓包,(只抓 in 方向的包,看看其他的客户端都会收到哪些 ARP 内容)。
|
1 2 3 4 5 6 |
root@ubuntu-3:/$tcpdump -i eth0 -n arp -Q in tcpdump: verbose output suppressed, use -v[v]... for full protocol decode listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes 09:40:08.639278 ARP, Request who-has 192.168.1.14 tell 192.168.1.10, length 44 09:40:10.746098 ARP, Reply 192.168.1.10 is-at 9e:fa:f1:b5:0c:28, length 28 09:40:10.746125 ARP, Reply 192.168.1.10 is-at 9e:fa:f1:b5:0c:28, length 28 |
|
1 2 3 4 5 6 |
root@ubuntu-4:/$tcpdump -i eth0 -n arp -Q in tcpdump: verbose output suppressed, use -v[v]... for full protocol decode listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes 09:40:08.639326 ARP, Request who-has 192.168.1.14 tell 192.168.1.10, length 44 09:40:10.746289 ARP, Reply 192.168.1.10 is-at 1a:50:9c:11:58:a3, length 28 09:40:10.746300 ARP, Reply 192.168.1.10 is-at 1a:50:9c:11:58:a3, length 28 |
可以看到,所有人都收到了一开始的 ARP 广播问题,随后又收到了一个自作多情的 ARP reply,但是 reply 中 IP 对应的 MAC 地址也是不同的。
但是,理论上发送一个包就够了,我在实验的时候,每次都会收到正好2个 GARP 的包,不知道为什么,在网络上提问也没人回答,看代码也没看懂。有知情的读者欢迎赐教。
Failover 过程
Failover 的过程和 balance-tlb 基本上一样,但是现在,无论是哪一个卡挂了,我们必须要更新所有人的 ARP 缓存,不能只让交换机换端口了。
Failover 流程如下:
- 如果挂的是主,交换两张卡的 MAC 地址,如果是备,不需要;
- 发送 GARP 给所有人(Unicast),告诉所有人自己的 IP 对应的 MAC(当然是没挂的那一个)。
将 link set down 并且在其他机器上抓包,就会看到有多个 GARP 包发过来。
|
1 2 3 4 5 6 |
root@ubuntu-4:/$tcpdump -i eth0 -n arp -Q in tcpdump: verbose output suppressed, use -v[v]... for full protocol decode listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes 10:04:16.689841 ARP, Reply 192.168.1.10 is-at 1a:50:9c:11:58:a3, length 28 10:04:16.690286 ARP, Reply 192.168.1.10 is-at 1a:50:9c:11:58:a3, length 28 10:04:16.690720 ARP, Reply 192.168.1.10 is-at 1a:50:9c:11:58:a3, length 28 |
总结和分析
到现在我们讨论了三种 bonding 模式:
- active-backup:实现简单,快速切换,只能用单卡;
- balance-tlb:实现简单,快速切换,发送能用双卡,需要硬件支持 MAC 地址修改;
- balance-alb:实现简单,切换较慢,涉及 GARP 去刷新所有的客户端缓存,收发双卡,需要硬件支持 MAC 地址修改。
博客中讨论的这三种方案都是用了两张卡来讨论的,实际上这三种方案都可以加更多的卡,工作原理完全一样。(仔细想想看!)
实际上,这些都有缺点,都不是数据中心在用的方案,但是我们离「完美」的方案越来越近了,希望读者觉得这篇讨论的内容有趣,until next time!
参考资料: