这个题目很有趣,即使没有什么思路,当你打开 Wireshark 的时候,估计也能发现答案了。
电脑插上网线的时候,是可以正常上网的。但是即使能正常上网的时候,我们抓到的包也都是红色的。这些红色是有 Expert Info 标注的包。(可以通过 Wireshark Profile 配置颜色)
Expert Info 是 Wireshark 帮助我们标记出来的可疑信息。
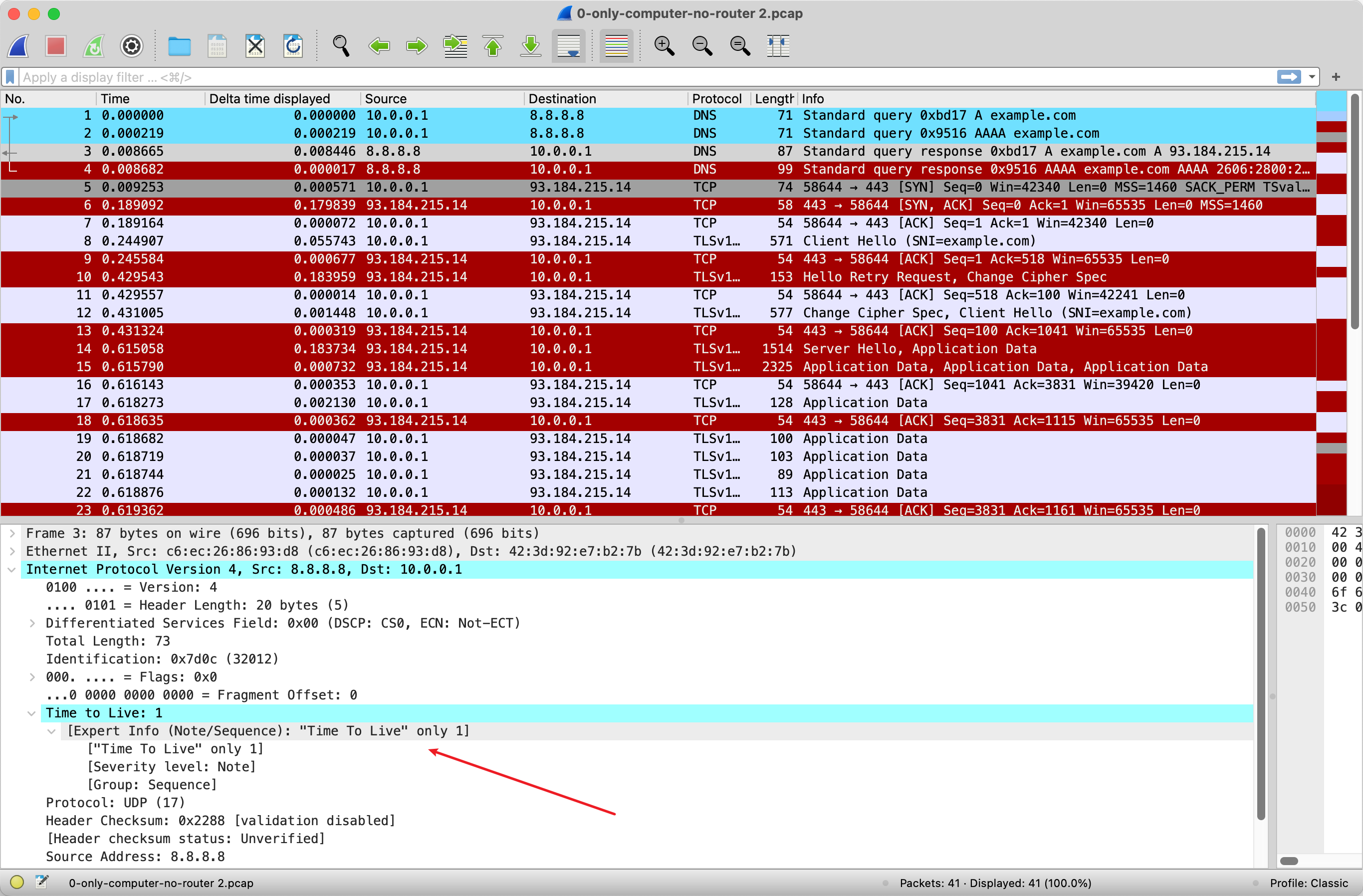
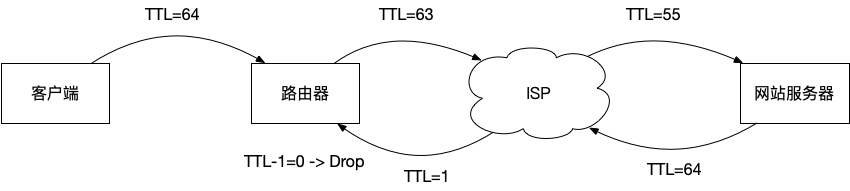
Wireshark 打开会发现明显的 Expert Info 提示 点开下面 IP 层的包,会发现 TTL 有明显的颜色标注:Time To Live only 1. 于是就真相大白了,ISP 在把 IP 包转发给用户这边的时候,无论 TTL 还剩下多少,都改成 1 才转发给用户。这样,用户的设备可以收到包却不能转发 。因为设备(比如路由器)在转发包的时候会把 TTL 减 1,如果 TTL 还是大于 0,才会转发出去;如果等于 0,就会直接丢弃。即,网络上是不存在 TTL=0 的包的,这是协议规定的。
TTL 变化的链路 TTL 的设计原本是为了防止网络出现环路 ,限制一个包能被转发的最大次数。每次转发都会 -1,最后到 0 的时候,如果包还没有到达目的地,设备就会丢弃这个包(然后可能发一个 ICMP 告诉 Src IP 这个包因为 TTL 减到 0 而寿终正寝了)。
要解决这个问题的话,我们就要去修改「路由器」的行为,让路由器收到 TTL=1 的包不要直接丢弃,而是修改 TTL=5(或者其他数字),然后继续转发给其他的设备。比如,可以用 iptables 来修改 TTL 的值 iptables -t mangle -A POSTROUTING -j TTL --ttl-set 5。
为什么三层 IP 协议会有一个 TTL 字段,但是二层没有呢?我们先来看二层是否会出现三层可能出现的环路问题 。
答案是交换机出现了环路。
交换机的工作方式是:
收到一个 Ethernet 帧,查找 MAC 地址表 ,找到这个 Ethernet 帧目标 MAC 对应的端口,然后从这个端口转发出去。这个 MAC 地址表怎么来的呢?见 2;
对于收到的这个帧,把来源 MAC 和收到这个帧的端口写入 MAC 地址表 。因为从这个端口收到了帧,说明此 来源MAC 接在这个端口下,那么下次要往这个 MAC 发送的时候,直接走此端口即可;
假设来了一个 MAC,交换机的 MAC 地址表找不到这个 MAC 地址呢?比如交换机刚启动,MAC 地址表是空的。这时候交换机就把帧发给所有的端口 (flooding),即所有主机都能收到这个帧 ,只不过大部分主机检查一下目标 MAC 不是自己,就直接丢弃此帧。而之后一个主机发现是给自己的,就欣然接受,交给网络栈处理。
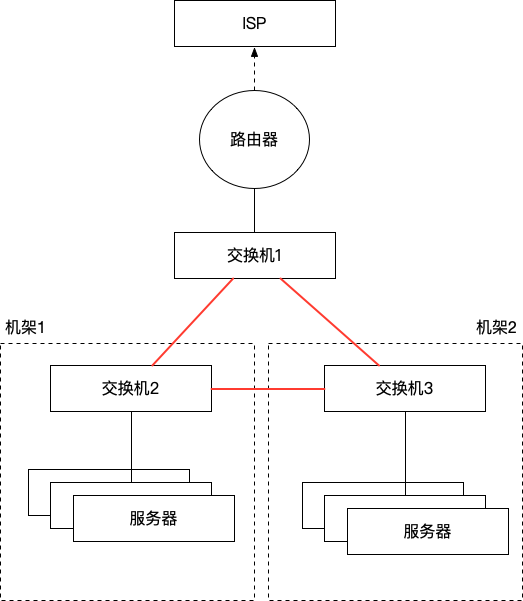
在我们的原题场景描述中,是扩容一个机架,一般在机架顶上加一个交换机 (Top-of-Rack Switching)。两个机架通都是在测试环境,需要连通,那么这个简单的网络拓扑现在就变成了这样子:
交换机出现环路连接
假设设备通电启动,服务器发送任何数据给交换机2(在题目中是 ARP 包),交换机2不知道目标 MAC 对应的端口,于是转发到它的所有端口,交换机1和3同时收到这个包,也不知道应该发给哪里,于是也转发到自己的所有端口,此时,交换机2又会收到1和3发过来的包,如上,这个包每次转发都会被放大2倍,直到最后,3个交换机都会在此网络中满载去转发这些流量,网络被堵满了,彻底瘫痪。
回到题目本身,这道题目是有一些困难的。因为我提供的 tcpdump 抓包文件,区分不出来网卡收到的包和发送出去的包。其实 tcpdump 的 -Q in 选项可以只抓进来的包(另外的参数是 -Q out 和默认的 -Q inout。这样就很明显了:
host1 $ tcpdump - Q in - i eth0
tcpdump : verbose output suppressed , use - v [ v ] . . . for full protocol decode
listening on h1 - eth0 , link - type EN10MB ( Ethernet ) , snapshot length 262144 bytes
10 : 55 : 05.327771 ARP , Request who - has 10.0.0.4 tell 10.0.0.1 , length 28
10 : 55 : 05.327775 ARP , Request who - has 10.0.0.4 tell 10.0.0.1 , length 28
10 : 55 : 05.328060 ARP , Request who - has 10.0.0.4 tell 10.0.0.1 , length 28
10 : 55 : 05.328063 ARP , Request who - has 10.0.0.4 tell 10.0.0.1 , length 28
10 : 55 : 05.328321 ARP , Request who - has 10.0.0.4 tell 10.0.0.1 , length 28
10 : 55 : 05.328323 ARP , Request who - has 10.0.0.4 tell 10.0.0.1 , length 28
可以看到 .1 这台机器去 ping .4 ,它才是应该发送 ARP 询问的人,它 ingress 怎么会收到自己发出去的请求呢?那必然是环路了,自己发出去的包经过转发,又回到了自己这里。而且还被放大了很多倍,发一个请求,远远不不断收到自己发送的请求。
在最新版本的 tcpdump 中,已经默认会展示抓包的 In/Out 方向了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
root @ foobarhost : / home / vagrant # tcpdump -i any host 1.1.1.1
tcpdump : data link type LINUX_SLL2
tcpdump : verbose output suppressed , use - v [ v ] . . . for full protocol decode
listening on any , link - type LINUX_SLL2 ( Linux cooked v2 ) , snapshot length 262144 bytes
05 : 57 : 49.350592 eth0 Out IP foobarhost > one . one . one . one : ICMP echo request , id 1 , seq 1 , length 64
05 : 57 : 49.357987 eth0 In IP one . one . one . one > foobarhost : ICMP echo reply , id 1 , seq 1 , length 64
05 : 57 : 50.353141 eth0 Out IP foobarhost > one . one . one . one : ICMP echo request , id 1 , seq 2 , length 64
05 : 57 : 50.363887 eth0 In IP one . one . one . one > foobarhost : ICMP echo reply , id 1 , seq 2 , length 64
05 : 57 : 51.354735 eth0 Out IP foobarhost > one . one . one . one : ICMP echo request , id 1 , seq 3 , length 64
05 : 57 : 51.361933 eth0 In IP one . one . one . one > foobarhost : ICMP echo reply , id 1 , seq 3 , length 64
05 : 57 : 52.356192 eth0 Out IP foobarhost > one . one . one . one : ICMP echo request , id 1 , seq 4 , length 64
05 : 57 : 52.363513 eth0 In IP one . one . one . one > foobarhost : ICMP echo reply , id 1 , seq 4 , length 64
05 : 57 : 53.358330 eth0 Out IP foobarhost > one . one . one . one : ICMP echo request , id 1 , seq 5 , length 64
05 : 57 : 53.392203 eth0 In IP one . one . one . one > foobarhost : ICMP echo reply , id 1 , seq 5 , length 64
root @ foobarhost : / home / vagrant # tcpdump --version
tcpdump version 4.99.1
libpcap version 1.10.1 ( with TPACKET_V3 )
OpenSSL 3.0.2 15 Mar 2022
那回到问题中提供的抓包文件,由于看不到进出方向这个信息,所以我们只能得到这个信息:发出去的 ARP 没有响应。原因可能就有很多了:网线没插好,交换机坏了,对面的机器故障导致收到 ARP 没有回应,有很多种可能。网络分析的时候,从哪里抓到的包 这个信息非常重要。我们是从 .1 机器上抓包的,所以只能确认 ARP 包从机器上离开了,但是没获得响应。
所以能得到这个信息的读者很厉害了。
如何从给出的抓包文件得到「环路」这个信息呢?
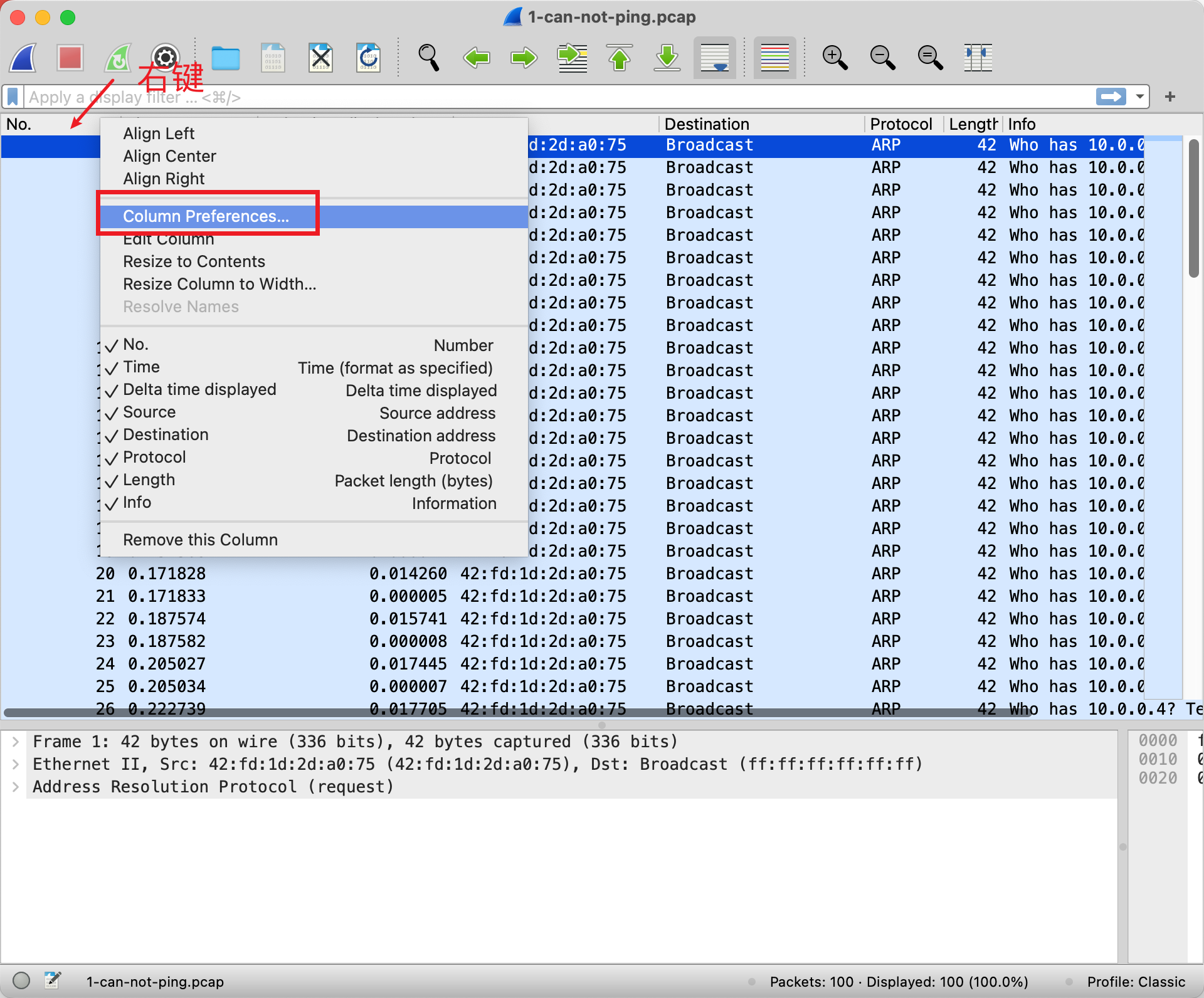
我的 Wireshark Profile 会打开 Delta Time 这个列。方法如下。先在列头右键,选择 Column Preferences…
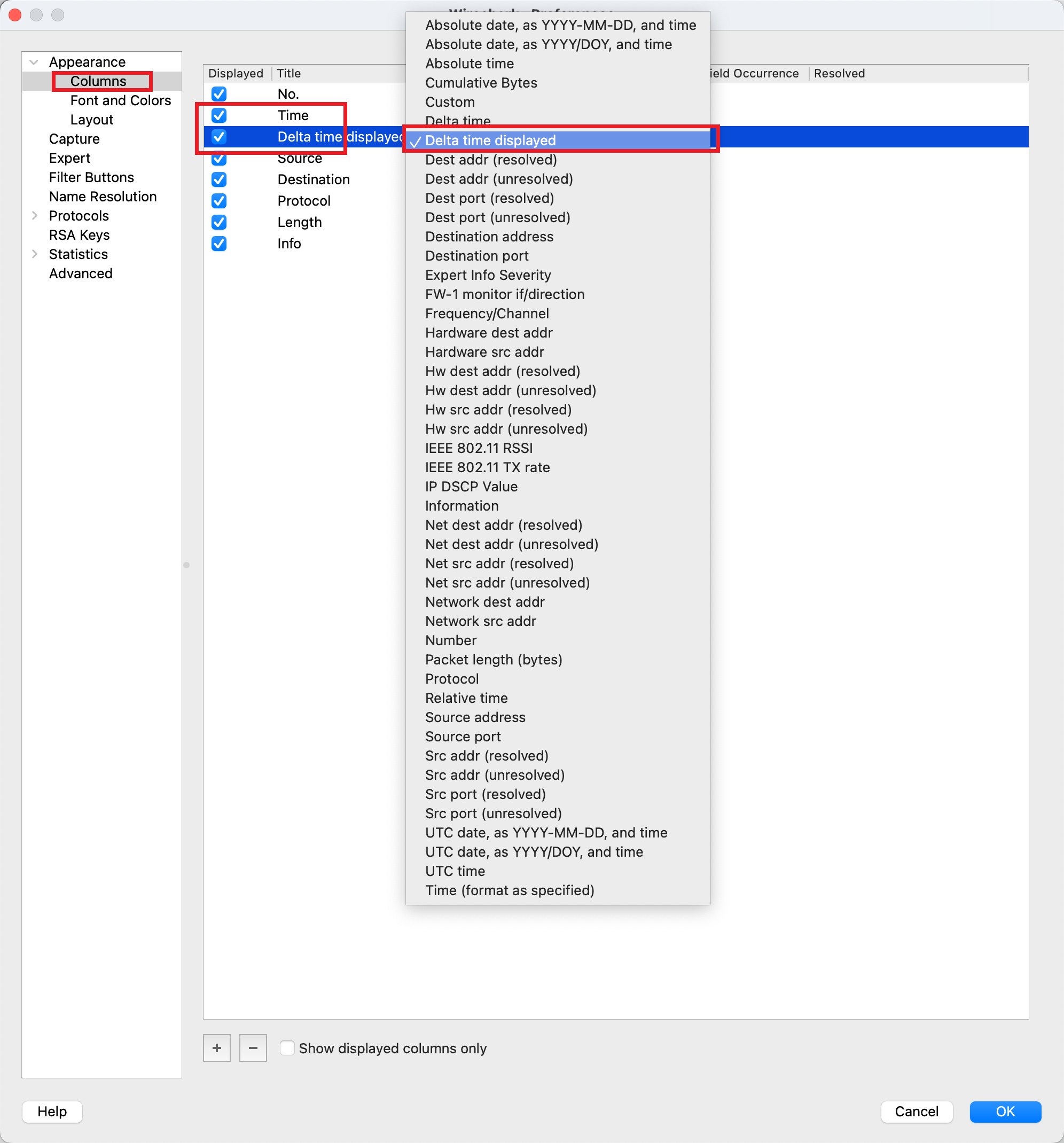
Wireshark 设置显示的列信息 然后添加一列,选择 Delta time displayed. 我喜欢加在 Time 的后面。
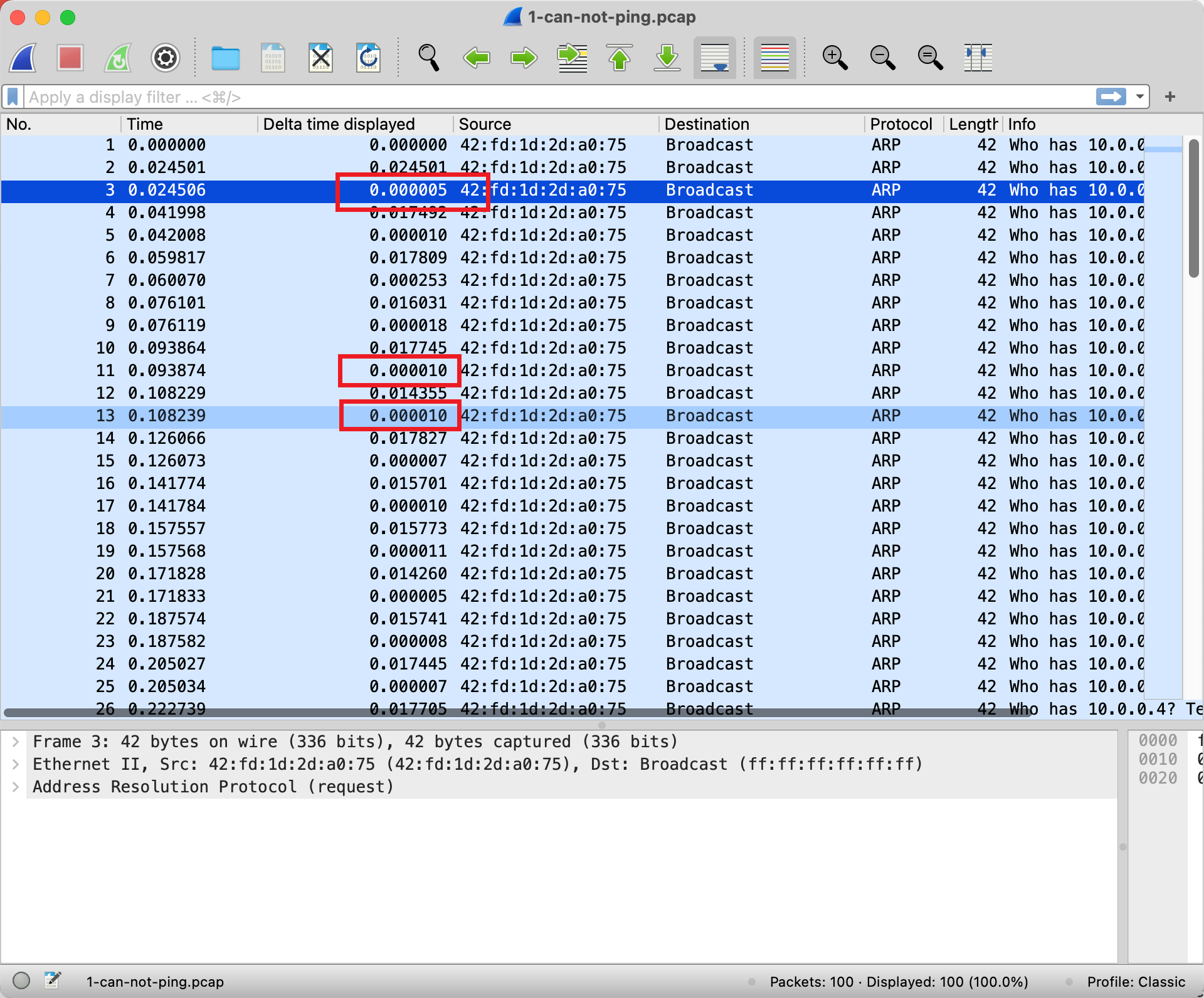
Wireshark 可以控制显示数据包的列信息 设置完成之后,列内容就看起来如下。
分析 Wireshark 包的时间信息 Delta time 的含义是:这个包抓到的时间距离上一个包过去了多久?比如第三行,表示第二个包抓到之后的 5us 抓到的。
这就很蹊跷了:主机发出 ARP 询问,为什么 5us 之后就接着又发出了另一个询问呢?难道等 5us 就开始重试了吗?(Linux ARP 重试时间是 1s,读者可以尝试一下去 ping 一个本地网络不存在的 IP 并抓包来实验一下。)虽然不同系统可能有不同的重试时间,但是 5us 就重试显然是不合理的,很多网卡的延迟都做不到 5us 。那么真相只有一个——这个不是发出去的包而是收到的包 ,网络出现环路,导致自己发出去的包被自己收到了。进一步推断出,现在这个网络的交换机都已经被环路搞崩溃了,导致网络大塞车,所有的包都无法正常转发。
总结一下,推断出这个信息,有几个难点:
要知道去分析包的时间序列;
知道 tcpdump 抓到的包是双向的。这个大家应该都会知道,只不过平时下意识通过 IP 和 MAC 的来源、目标来区分方向。这个场景比较刁钻,即使来源 MAC 是自己,却是 ingress 方向;
要知道二层也是可能存在环路的;
一楼 pandada8 在文章发布几小时内就贴了正确答案,恭喜!(可惜没奖品。)分析出第一段的读者也很棒,给你们发二等奖!
二层为什么不设置 TTL 字段?
既然三层使用 TTL 防环,而且二层也可能出现环路,为什么二层不加一个类似的 TTL 字段呢?我觉得原因有以下几点。
交换机速度为什么快,是因为在做转发的时候,直接看一下目标 MAC 地址,查表之后,确认出口,检查 CRC,然后交换机内的 Fabric 网络「连接」起来进入端口和出端口,数据直接转出去了。这中间不对 Frame 作修改。假设我们有一个二层 TTL 字段,那么就要修改这个字段,并且重新计算 CRC。这个问题在早期互联网很难解决,交换机硬件性能低,做这种复杂任务需要 CPU 来做。早期路由器用的就是 CPU(但即使这样,很多路由器都是不计算也不校验三层的 checksum 的 ,就当这个字段不存在一样,所以 IPv6 直接取消了 checksum 功能,完全依赖二层的 CRC 以及让上层协议自己去做校验),所以路由器比交换机速度慢很多。但是现在在 ASIC 上做这个事情难度不高 ,倒是将这个技术推向市场,升级 ASIC 芯片和协议难度会很高。说起来,按照早期硬件来设计的 Ethernet,还有很多不合理的地方,如果我们有能力一夜普及一种全新的 Ethernet 技术的话,我觉得最先升级的是 Ethernet 1500bytes MTU 的限制 。
我觉得最关键的原因是,做这个事情意义不大。TTL 这个机制只能作为防环的一种最后手段,并没有解决问题。在三层上讲,假设一个包的 TTL 被从 64 减到 0 最后丢弃了,那么包已经经过了 64 次转发,这些工作量已经被浪费掉了。在二层上讲,环路一旦出现,损失就更大了,每次转发流量都会被放大好几倍,可以想象,即使有 TTL,出现环路的话一个包也会被转发成千上万次,也不会有什么改善。
所以最好的方案还是防止环路的出现 。
那为什么三层还要有 TTL?因为二层网络一般是一个组织控制的,一个公司有多个网络,自己内部想怎么设计都可以。跨组织之间一般是三层,通过路由协议(最流行的是 BGP)来交换路由信息。一个网络内,我们可以通过技术手段保证没有环路,并对此负责。但是三层方面,我们不能保证邻居的网络没问题,不能保证他们不会把错误的包发送回来导致环路,所以 TTL 是一个在全局层面上,作的最后一个防线。
虽然三层有 TTL 的存在,所有的三层路由协议设计上都有防环机制,比如 Split Horizon,简单来说就是从一个接口收到的路由信息,不会再从这个接口发送。 当环路出现的时候,已经造成损失了,TTL 只是减少损失而已。
从上面的分析我们可以看出:二层环路比三层更加可怕,一是因为二层没有 TTL 机制做兜底,二是二层交换机的工作原理会有流量放大。所以二层的防环技术非常重要。
二层最基础的防环机制是 STP(Spanning Tree Protocol),简单说就是交换机在启动的时候会互相沟通,看网络是否存在环路,如果存在,就通过计算协商断开一条线,就当这条线不存在一样。逻辑上是一个无环网络。
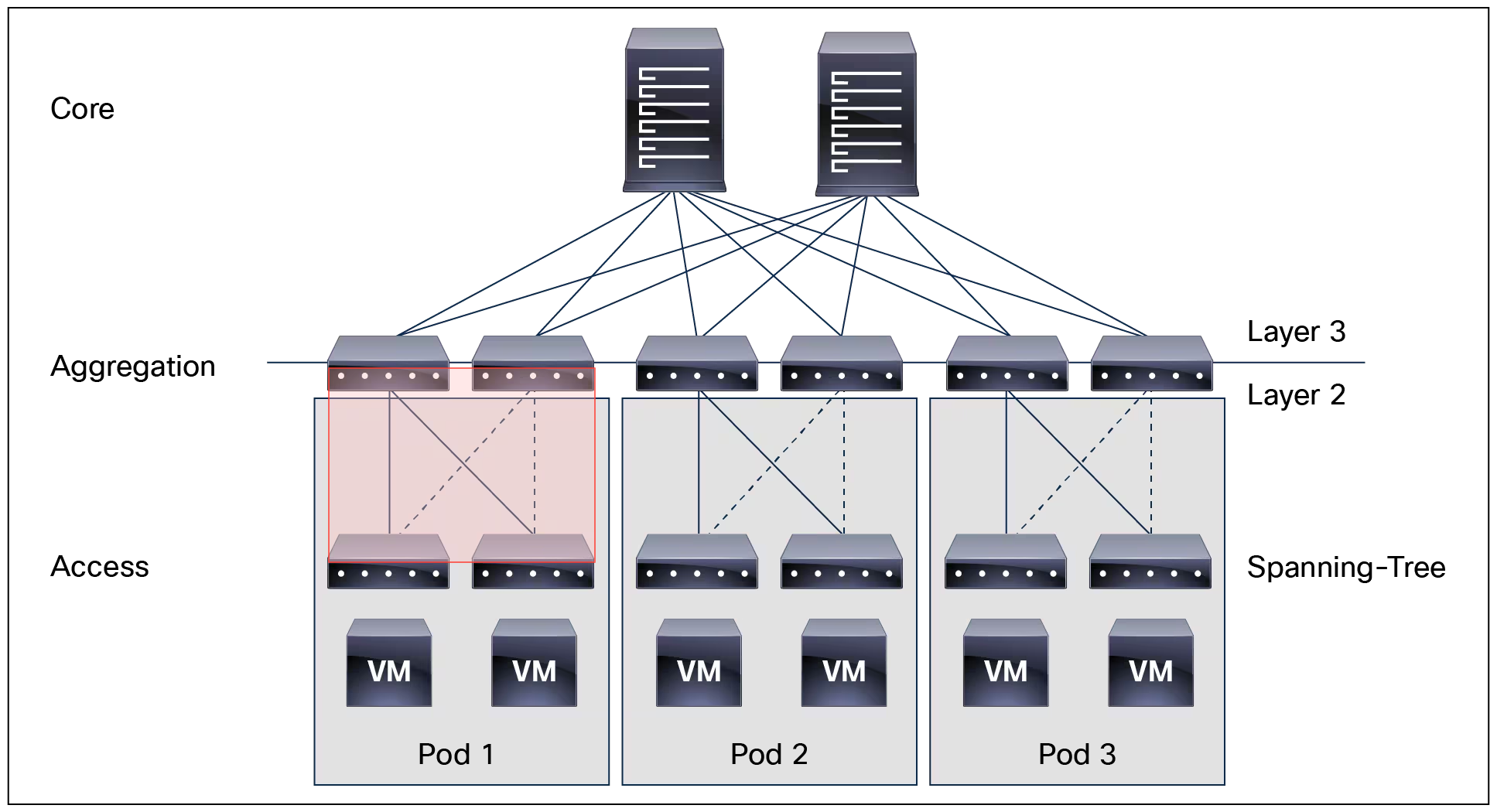
比如上一代网络经典的核心-汇聚-接入网络,可以看到红框里面其实是一个二层环路。但是运行 STP 会断开虚线的部分。
STP 有一些问题:断开线路,这就是浪费了硬件资源,没有完全利用带宽,而且每次 STP 的计算需要时间,比较慢。所以现在的二层技术,都会在设计的时候考虑到防环机制,让机制在本身不会造成二层环路。但是 STP 不会关闭,会作为一个兜底机制存在。
现在几乎所有的交换机都有 STP 功能,所以几乎看不到环路的存在了,上文题目很少在现实中见到,有些刁钻,向读者道歉!
无处不在的「环路」
说完三层和二层,我们扩展继续聊聊其他的协议。
可以说:只要有转发,就可能存在环路。
HTTP 301 重定向环路
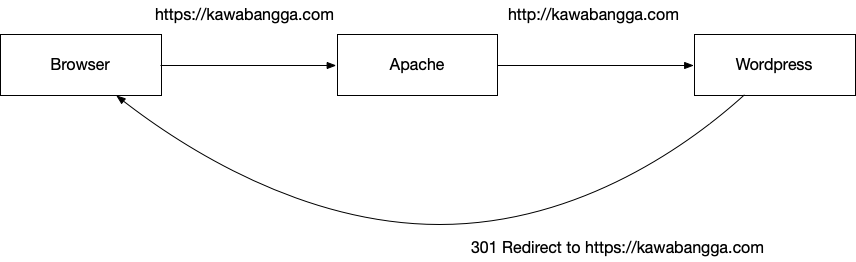
比如说我之前配置全站流量 HTTPS 重定向的时候 ,就出现过「环路」。即在 WordPress 上配置了 HTTP 都 301 重定向到 HTTPS,但是 Apache 反向代理收到用户的 HTTPS 请求之后,将 TLS 「卸载」了,转发到后段的是 HTTP,于是 WordPress 又发送了 301 重定向给浏览器。
301 重定向引起的环路 浏览器对此的防环机制是,如果重定向次数太多,就放弃并显示错误:ERR_TOO_MANY_REDIRECTS.
DNS CNAME 环路
假设我们设置 a.kawabangga.com 的记录为 CNAME b.kawabangga.com,然后设置 b.kawabangga.com 的记录为 CNAME a.kawabangga.com,会发生什么呢?
大多的的 DNS 客户端和 Recursive resolver 都限制了跟踪 CNAME 的次数,这样,即使发生循环,最后也会以失败停下来。不过最好的办法还是在配置的时候就发现出现了环路(配置系统进行检查?)
比如,使用 dig 来查询这种 DNS CNAME 的话 ,dig 会一起将两个 CNAME 结果返回。
如果不限制查询次数的话,就会出问题了。曾经就遇到过 DNS Recursive resolver 没有限制查询次数而引起的故障。
CDN 转发的环路
CDN 的一个主要功能就是把访客的请求转发给真实服务器。想象这样一个场景,假设真实服务器也是一个 CDN 呢?如果我在一家 CDN 的控制台,配置转发请求到 CDN 公司 B,然后去 CDN B 配置转发到 CDN A。那么只要发送一些请求,就可以把两家 CDN 公司的流量都占满了。
解决方法就是识别出来这个请求我是否已经转发过了。RFC 7230 规定可以使用 Via 字段来标志。但是这个字段有一些历史问题,以及太大了,有性能问题,而且很多服务器无法处理。所以 Cloudflare, Fastly and Akamai 这些厂商又联合定义了一个新的类似方案 。
最后总结一下,这一篇的分析中,在网络分析方面,我们学会两招:
注意 Wireshark 给我们提供的专家信息。TCP 如果发生重传,乱序等,Wireshark 就会给我们标注出来(注意后面可能要考哦~)。这些在 tcpdump 命令行是没有的,tcpdump 是抓包展示,不会有包之间的关联分析信息。
注意分析时间序列。
在网络设计方面,我们讨论了环路,做相关设计的时候要时刻提防无限循环的破坏力。顺带八卦了网络的一点历史和硬件知识。
Until next time!
==计算机网络实用技术 目录==
这篇文章是计算机网络实用技术系列文章中的一篇,这个系列正在连载中,我计划用这个系列的文章来分享一些网络抓包分析的实用技术。这些文章都是总结了我的工作经历中遇到的问题,经过精心构造和编写,每个文件附带抓包文件,通过实战来学习网路分析。
如果本文对您有帮助,欢迎扫博客右侧二维码打赏支持,正是订阅者的支持,让我公开写这个系列成为可能,感谢!
没有链接的目录还没有写完,敬请期待……
序章 抓包技术以及技巧
理解网络的分层模型 数据是如何路由的
网络问题排查的思路和技巧
不可以用路由器? 网工闯了什么祸? 网络中的环路和防环技术 延迟增加了多少? TCP 延迟分析 压测的时候 QPS 为什么上不去? 压测的时候 QPS 为什么上不去?答案和解析
重新认识 TCP 的握手和挥手 重新认识 TCP 的握手和挥手:答案和解析 TCP 下载速度为什么这么慢? TCP 长肥管道性能分析 后记:学习网络的一点经验分享
与本博客的其他页面不同,本页面使用 署名-非商业性使用-禁止演绎 4.0 国际 协议。