lxml是Python处理xml文档的一个库,速度快,易编程,可以“make life easier”。这篇文章是lxml的快速上手教程。
XML在lxml中的表示
在DOM中,文档是以节点(node)的形式组织的。某节点又有子节点,表示Elements,Attributes,Text等。
例如,下面这个DOM可以用如图所示的节点组织。
|
1 2 |
<p>To find out <em>more</em>, see the <a href="http://www.w3.org/XML">standard</a>.</p> |
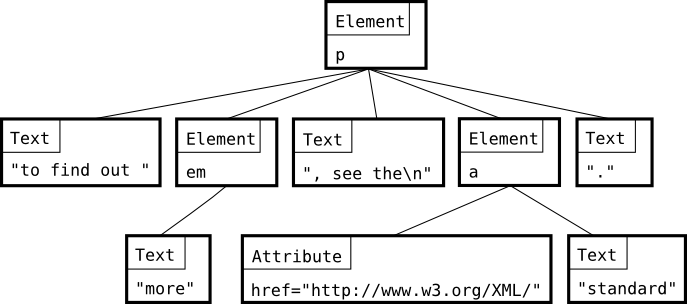
在lxml中,只有Element,Element有子Element,构成一棵树。Element有一下属性:
- .tag – element的名字,比如“p”或“em”等
- .text – 元素的文本内容,从开头到第一个子节点。如果从开头到一个子节点没有内容,那么就是None。比如p的text是”To find out”
- .tail – 元素后面的内容,到下一个元素为止。比如em的tail是”, see the”
- .attrib – 元素的属性。“
<h2 class="arch" id="N15">”的.attrib就是 “{"class": "arch", "id": "N15"}” - (子元素列表) – Element的很多行为都和list类似,可以用来索引。比如Element[0]就是表示Element的第1个子元素。可以使用len()查看这个Element一共有多少个子元素
上面的DOM使用lxml的Element表示:
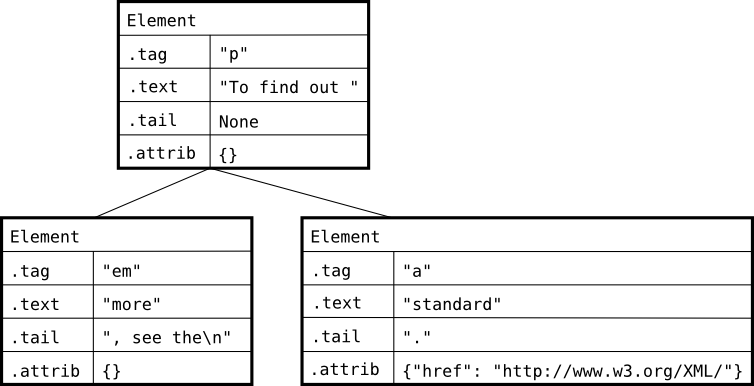
注意.tail,比如,”,see the \n”本来在DOM中是p的节点,但是在lxml里成为了em的.tail属性。
操作Element
在lxml中,一个Element实体的表现和Python的list很相似,可以使用len()获得这个Element的子元素的数量,可以使用下标操作子元素,可以使用replace(), delete()等方法。假设E是一个Element实体,那么可以进行以下操作。
- 通过E[i]获得第i+1个元素
- 通过E[start:end]获得从start到end之间的元素
- 可以通过下标替换一个元素:E[i] = c
- 删除一个元素:del E[i]
- 通过循环迭代所有元素:
-
12for kid in node:print kid.tag
- 通过append()添加子元素
- 使用clear()将子元素清空,此外:
.attrib字典将清空- tail和text将设置为None
此外,Element还有一些其他的方法。
Element.find()
|
1 |
E.find(path[, namespaces=D]) |
找到和path匹配的元素,如果有多个,返回第一个。可以查找子元素的子元素,”tag1/tag2/…/tagn“。
Element.findall()
|
1 |
E.findall(path[, namespaces=N]) |
找到所有匹配的元素,以列表的形式返回。
Element.findtext()
|
1 |
E.findtext(path, default=None, namespaces=N) |
找出所有和path(path是Element的后代即可)匹配的元素中的文本。如果有多个,返回第一个。如果匹配path但是元素没有文本,返回”(default在这种情况下不会使用)。
Element.get()
|
1 |
E.get(key, default=None) |
获得一个attribute的值,如果没有,使用default。
Element.getchildren()
|
1 |
E.getchildren() |
获得所有子元素(感觉这方法和元素本身一样啊……)
|
1 2 3 4 5 6 7 8 9 10 11 |
>>> xml = '''<corral><horse n="2"/><cow n="17"/> ... <cowboy n="2"/></corral>''' >>> pen = etree.fromstring(xml) >>> penContents = pen.getchildren() >>> for content in penContents: ... print "%-10s %3s" % (content.tag, content.get("n", "0")) ... horse 2 cow 17 cowboy 2 >>> |
Element.getiterator()
|
1 |
E.getiterator(tag=None) |
得到元素的迭代器。如果tag省略,元素本身会作为第一个元素。
比如遍历下面这个树。
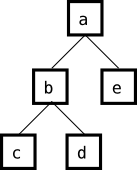
|
1 2 3 4 5 6 7 8 |
>>> xml = '''<a><b><c/><d/></b><e/></a>''' >>> tree = etree.fromstring(xml) >>> walkAll = tree.getiterator() >>> for elt in walkAll: ... print elt.tag, ... a b c d e >>> |
Element.insert()
|
1 |
E.insert(index, elt) |
插入一个新的子元素。
Element.items()
就和字典的items()一样,会返回一个tuple的list。
|
1 2 3 4 |
>>> node = etree.fromstring("<event time='1830' cost='3.50' rating='nc-03'/>") >>> node.items() [('cost', '3.50'), ('time', '1830'), ('rating', 'nc-03')] >>> |
Element.iterancestors()
|
1 |
E.iterancestors(tag=None) |
和Element.getiterator()类似,不过是从当前节点开始,往上遍历祖先,直到遍历到根目录。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
>>> xml = '''<class sci='Aves' eng='Birds'> ... <order sci='Strigiformes' eng='Owls'> ... <family sci='Tytonidae' eng='Barn-Owls'> ... <genus sci='Tyto'> ... <species sci='Tyto alba' eng='Barn Owl'/> ... </genus> ... </family> ... </order> ... </class>''' >>> root = etree.fromstring(xml) >>> barney = root.xpath('//species') [0] >>> print "%s: %s" % (barney.get('sci'), barney.get('eng')) Tyto alba: Barn Owl >>> for ancestor in barney.iterancestors(): ... print ancestor.tag, genus family order class >>> for fam in barney.iterancestors('family'): ... print "%s: %s" % (fam.get('sci'), fam.get('eng')) Tytonidae: Barn-Owls |
Element.keys()
|
1 |
E.keys() |
返回所有attributes的key。
Element.xpath()
|
1 |
E.xpath(s[, namespaces=N][, var=value][, ...]) |
非常常用的一个方法,关于xpath有太多要说的了,以后再写吧……
这是依赖于 libxml2 的吗?
XML 的这一套工具链确实不错,我其实挺喜欢那个 XSTL 的。
应该是这样的。
不过就我目前的工作内容来说,XML和HTML都一样……并没有感到明显的区别
Pingback: Python爬虫实践入门篇 – ITPCB