假期在学java的时候见到过一道面试题,如下:
|
1 2 3 4 5 |
class Byteok{ public static void main(String[] args){ byte c = 3+4; } } |
这段代码编译的时候是可以通过的,但是下面这一段:
|
1 2 3 4 5 6 |
class Byte{ public static void main(String[] args){ byte a=3,b=4; byte c = a + b; } } |
在编译的时候,编译器会提示一下错误:
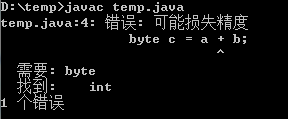 问:为什么会出现以上的报错?
问:为什么会出现以上的报错?
答案是说:数字都是以默认“int”型来进行计算,例如 byte b = 4; 会先检查右边——4是否占用了4个byte? 不是,只用了一个,那么,就可以直接赋值给b。 b = 3 + 7 ;其实就是 b = 10 ; 同上。但是如果是 b = b1 + b2; b1和b2是变量,值不确定,不能判断是否越界。而b = 3 + 7;由于是定值,就可以检查。
但是我看了之后,还是有几点不明白:
- 为什么变量的话就没办法检查?检查到目前为止的值不可以吗?
- 为什么我用C语言将byte替换为short,之后,第二段代码就可以正常编译?
回学校之后,问了老师,得到以下回复:
我查了下,得到这样的答案:
c取值范围:-128~127
编译器在编译时(byte类型取值是有限的)他在判断右边的数值的时候发现是int类型(是“常量”), 但他会判断是不是在byte字节范围之内,如果在的话,会给右边的int类型做默认的强转,他把最后的一个字节(byte八个二进制)赋值到了b这个变量当中
b1和b2是“变量”意味着这两值不确定、可能随时变化,编译器无法检查,也无法确定是否在byte字节范围之内, 他检查不了就会报错(可能丢失精度),如果是“常量”编译器就能够判断了
也就是说,java的编译系统会做一些计算工作,和c的编译功能不一样。
之后我又试了以下代码:
|
1 2 3 4 5 6 7 8 |
class Temp{ public static void main(String[] args){ final byte a = 3; final byte b = 4; byte c= a + b; System.out.println(c); } } |
编译通过,顿悟。
事实上 只要是 char int byte 这些数据只要是在进行运算的时候 都会先强制转为int型
Pingback: Java的常见误区与细节 - 莹莹之色
Pingback: Java常见的30个误区与细节! – 松松博客