最近在网上看了一些 BBR 的资料,简单玩了一下,这里做一个记录。
简单的介绍
BBR 是一种拥塞控制算法。拥塞控制算法的目的简单来说就避免将过多的包发到网络上,造成网络堵车。假如现在网络上比较拥堵,那么 TCP 就使用拥塞控制算法来让发送端发的慢一些。如何在不造成网络拥堵的情况下,又能利用带宽快速发送数据,就是拥塞控制算法要解决的问题了。
这篇文章介绍了常见的拥塞控制算法。一般的拥塞控制算法是通过丢包来认为网络中是否发生拥塞的,这样的问题是,网络是存在一定的概率因为错误而丢包,就会导致无法充分利用带宽;另外一个问题是网络有可能会有 buffer 存在,导致发送端认为的网络容量因为没考虑到 buffer 比实际的要高。
那么 BBR 是怎么解决问题的呢?1)不再将丢包认为是一个网络拥堵的现象;2)分别估计带宽和延迟。
以下是启用的实验。(略水)
新开一个一台 Fedora32 发行版的机器,可以看到默认的拥塞控制算法是 cubic :
[root@fedora-s-4vcpu-8gb-sgp1-01 ~]# uname -a Linux fedora-s-4vcpu-8gb-sgp1-01 5.6.6-300.fc32.x86_64 #1 SMP Tue Apr 21 13:44:19 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux [root@fedora-s-4vcpu-8gb-sgp1-01 ~]# sysctl net.ipv4.tcp_congestion_control net.ipv4.tcp_congestion_control = cubic
升级 Kernel
Kernel 的拥塞控制算法是可插拔的,这意味着我们不需要重新编译 Kernel 就可以更换拥塞控制算法。但是 BBR 要求最低是 4.9.0 才能使用。
但是 Fedora32 的内核已经是 5.x 的了,所以我就不用升级了。
Enable BBR
使用下面的命令可以启用 BBR:
echo 'net.core.default_qdisc=fq' | sudo tee -a /etc/sysctl.conf echo 'net.ipv4.tcp_congestion_control=bbr' | sudo tee -a /etc/sysctl.conf sudo sysctl -p
接下来是验证。首先确认 bbr 在可用算法中。下面这个输出应该包含 bbr (顺序不重要):
sudo sysctl net.ipv4.tcp_available_congestion_control
在验证当前生效的算法应该是 bbr:
sudo sysctl -n net.ipv4.tcp_congestion_control
最后验证 Kernel 模块已经正确加载:
lsmod | grep bbr
输出如下:
tcp_bbr 16384 0
bbr 的开启就完成了。
Benchmark
对比一下相比于默认使用的 cubic,有没有速度的提升。先安装 httpd,生成一个随机的文件,供下载测试。
sudo yum install httpd -y sudo systemctl start httpd.service cd /var/www/html sudo dd if=/dev/zero of=100mb.zip bs=1024k count=100
然后再开一台旧金山的机器,从开启 bbr 的机器上下载文件测试速度。使用下面这个命令来下载刚刚生成的这个 100MB 的文件。
$ for i in {0..10}; do curl -sL 206.189.32.132/100mb.zip -w '%{time_total}s\n' -o a.zip; done
8.484811s
7.791288s
8.281683s
7.982274s
7.814653s
8.268279s
8.332964s
8.898929s
8.489847s
8.706759s
8.124781s
测试了当前服务器上可用的几种算法,结果如下:
- cubic: 8.047663181818182(s)
- bbr: 8.084801727272726(s)
- reno: 8.060761727272727(s)
bbr 竟然是最慢的一个,-_-||
2024年3月5日更新:
BBR 的优势是需要在特定环境下才能发挥的。近期遇到一个问题,就是 探测 TCP 乱序问题 这篇文章没有解决的:我们的链路大约有 0.5% 的丢包率,在这种情况下 TCP 默认的拥塞控制算法 cubic 很容易被影响,一旦发生丢包,cwnd 会快速下降,导致传输速率很低。
下面是用 iperf3 测试的传输速度。
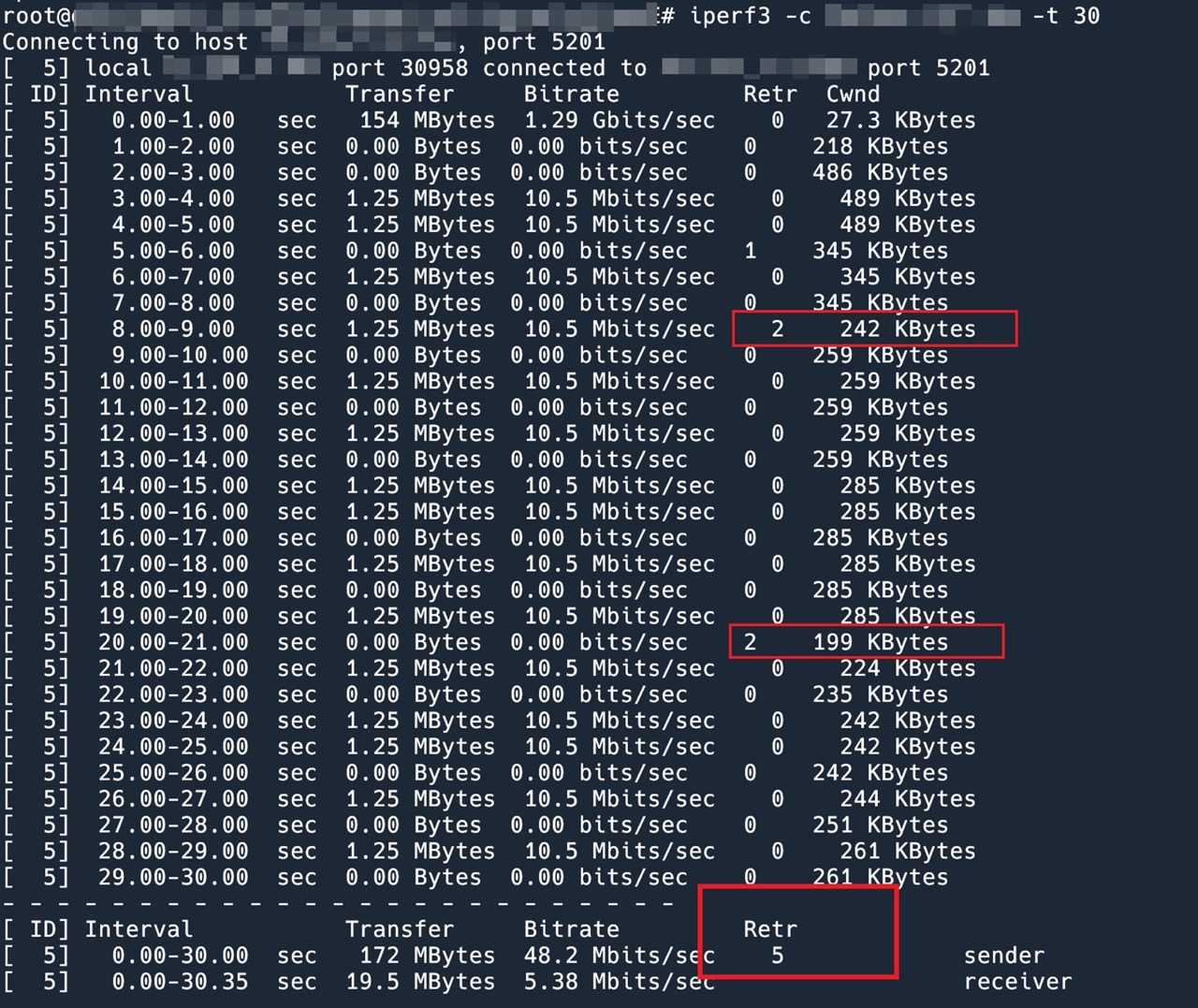
可以看到,一旦发生重传,cwnd 就会缩小。cwnd 只能维持在 200 KiB 左右。
把发送端(由于我们的场景是数据单项发送,接收端不需要修改)的拥塞控制算法换成 BBR,重新测试一遍。
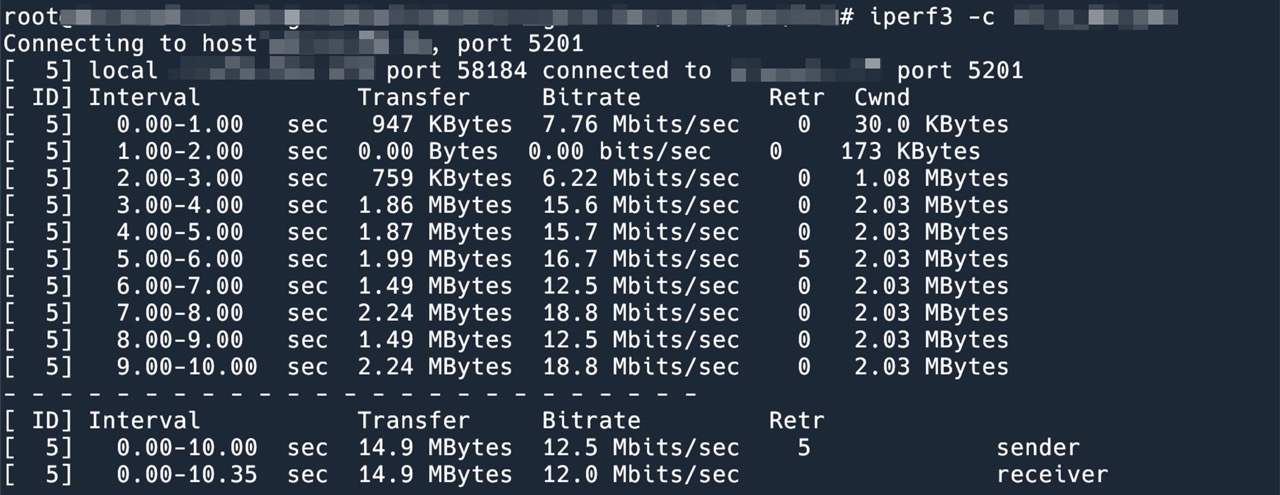
可以看到第5秒的时候依然发生了重传,丢包依旧,但是 cwnd 丝毫没有变化,cwnd 维持在前面的 10 倍左右大小。
实际效果是,原来数据需要 30 多分钟下载完成,换成 BBR 之后,只需要 2 分钟就下载完了。
参考资料:
看结果可以认为统计上没有区别,是不是阿里云的 backbone 上已经做了优化
应该是性能差别没有那么大吧,我觉得被其他的因素,比如带宽之类的更大的因素给屏蔽掉这点性能差异了。benchmark 是比较复杂的工程,我这个参考意义不大的。
正要等娓娓道来为什么bbr竟然差的时候,突然结束了。
我对 bbr 第一次有印象是好多年前用非cn2 的超便宜的非kvm 的搬瓦工小 vm,用了 kcptun 加上 bbr 测出来比没有的情况是十倍量级的带宽差别(5Mb/100Mb),不过没有对比过只有一个变量的情形。
对哦,感觉这个benchmark比较难,回头有空了再控制变量试试吧。另外因为你这个是同时加了 kcp 和 bbr,不知道这个10倍多少是 bbr 的,kcp 对加速还是挺明显的。
Pingback: 用 Wireshark 分析 TCP 吞吐瓶颈 | 卡瓦邦噶!
Pingback: TCP 长连接 CWND reset 的问题分析 | 卡瓦邦噶!