今天花了很长的时间在排查一个诡异的问题,值得记录一下。
本来是想写一个 HTTP 的服务,你告诉这个 HTTP 服务一个 IP 地址和端口,这个 HTTP 服务就可以返回通过 TCP 访问这个 IP 端口的延迟。因为我们每次做 chaos 注入的时候都要测试一下注入延迟成功了没有,有了这个服务,这个测试就可以自动化。
其实很简单,收到请求之后用 TCP ping 几次拿到延迟,然后返回就可以了。
之前测量 TCP 的延迟使用的都是 hping3,Redis 的作者 antirez 写的。然后就想到用这个工具来做测试好了。
搜索了一下发现没有 Python 的 binding,所以打算粗暴一些,直接在 HTTP 服务里面 fork 出来一个进程做测试,然后去处理 stdout,grep 出来延迟的数据。很快就写好了,代码大体如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
def hping3(request): """ test latency using hping3 params in json body: dest_ip: str dest_port: int count: int :return: list of floats, each one is a latency, if total count less than ``count``, it means some ping get timeout. """ data = request.body logger.info( "received hping3 request, headers: {}, body: {}".format(request.headers, data) ) data = json.loads(data) dest_ip = data.get("dest_ip") dest_port = data.get("dest_port") count = data.get("count") command = "/usr/sbin/hping3 {} -p {} -c {} --syn".format(dest_ip, dest_port, count) logger.info("hping3 run command: {}".format(command)) complete_process = subprocess.run( command, capture_output=True, shell=True, ) returncode = complete_process.returncode stdout = complete_process.stdout.decode() stderr = complete_process.stderr logger.info( "result returncode={}, stderr={}, stdout={}".format(returncode, stderr, stdout) ) latency = [] for line in stdout.split("\n"): matched = match_hping_ms.search(line) if matched: latency.append(float(matched.group(1))) return JsonResponse({"latency_ms": latency, "hping3_returncode": returncode}) |
很简单的一段代码,收到请求,调用命令,返回结果。框架使用的是 Django,在本地测试一切正常,然后发布到 staging, 噩梦开始了……
在 staging 环境中,测试的时候发现,HTTP 请求发过去永远收不到回应,最后会得到一个 504 Gateway Timeout 的结果。去容器(应用运行在一个容器里面)看,发现 hping3 进程一直没有结束,像是卡住了。
一开始有很多错误的怀疑,比如怀疑 hping3 需要 TTY 才能执行,以为 hping3 需要使用绝对路径等…… 但是想想同样的代码在本地可以运行正常,就应该不是这些原因。一个验证就是,我去应用运行的环境中开一个 Python 的 REPL 执行这段代码,是能正常得到结果的。在应用运行的环境直接运行 hping3 命令,也是没有问题的。
然后怀疑 hping3 没有足够的权限来运行,因为 hping3 发送的是 raw TCP/IP 包,需要 CAP_NET_RAW 才能执行。去容器里面检查了一下,发现这个 capability 也是有的。
到这里,其实已经花费了很多时间了,得到的事实有:
- 容器里面执行 hping3 是完全没有问题的,权限是足够的
- 直接使用 Python3 的 REPL 执行这段代码也是没有问题,代码逻辑是对的
到这里你能猜到问题出在哪里了吗?
其实还有一个运行环境没有提到,就是 uWSGI. 这个 Python 写的服务是作为 WSGI 应用跑在 uWSGI 里面的。不知道和 uWSGI 有没有关系(直觉告诉我是有的,比直觉更厉害的同事也告诉是有关系的)。于是我打算直接使用 python manage.py runserver 在容器里面跑起来试试……
一切正常了。
所以 python 直接跑应用没问题,用 uWSGI 运行就有问题。现在问题锁定在 uWSGI 上面了。为了复现这个问题,我写了一个最小的测试用例。
首先需要一个文件,叫做 pingapp.py。
|
1 2 3 4 5 6 7 8 |
vagrant@vagrant:~$ cat pingapp.py import subprocess def application(env, start_response): start_response('200 OK', [('Content-Type','text/html')]) p = subprocess.run("hping3 --syn 104.244.42.1 -p 80 -c 3", shell=True, capture_output=True) print("return code={}".format(p.returncode)) return [p.stdout] |
然后使用 uWSGI 运行这个程序:uwsgi --http-socket :9090 --wsgi-file pingapp.py --threads=4.
uWSGI 的版本是 2.0.20,Python 的版本是 3.7.5, 但其实这不重要。
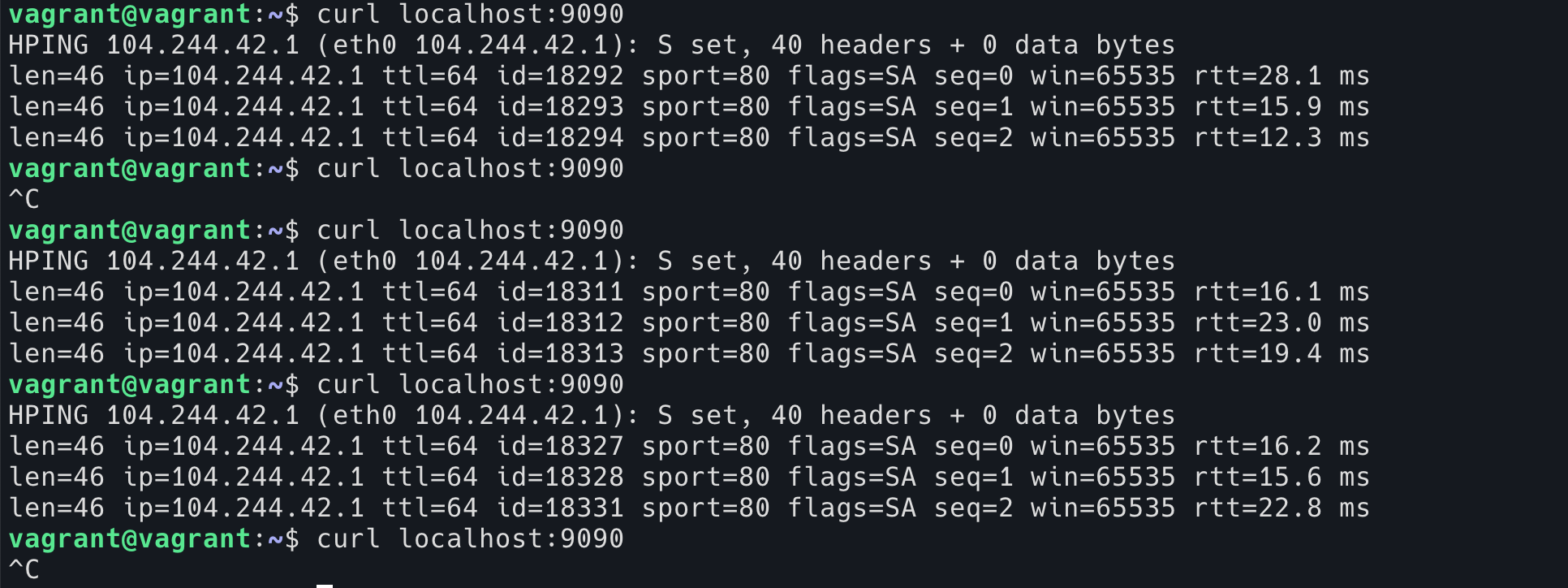
最后,访问这个程序,即 curl localhost:9090.
如果是 uWSGI 的问题的话,我们期望这里已经可以复现问题了,即 curl 命令会卡在这里,然后进程( ps -ef )里面出现一个 hping3 的进程,结束不了。
如同……下面这样:

图1 – 卡住的 hping3
但现实是……这个程序一点问题没有,运行地丝般顺滑。
这就见鬼了,直接没了思路。我的应用和这个最小的复现代码根本没什么(太大的)区别啊!我又没有用一些奇奇怪怪的 lib。
后面我实在解决不了了,找了(大佬)同事帮忙,花了很多时间,找到以下事实:
- hping3 卡住了,发现 SIGTERM 结束不了它,只能
kill -9 - 然后发现 uwsgi 进程也有一样的行为了,只能
kill -9去杀它 - hping3 程序被 uwsgi 正常起起来是没问题的,起来之后运行不了
- …… 以及中间奇奇怪怪的现象,就不细说了,其实都不重要
最后虽然也找到了根因,但是走得路太弯了。本文从这里开始,就以事后诸葛亮的视角,看看有了上面的信息,我们怎么从正确的思路一步一步找到问题。
首先,同样的环境,在 shell 里面可以正常执行 hping3 但是 uWSGI 里面却不可以,既然 uWSGI 能正常开 hping3 进程,我们就可以看看这个进程到底卡在了哪里?
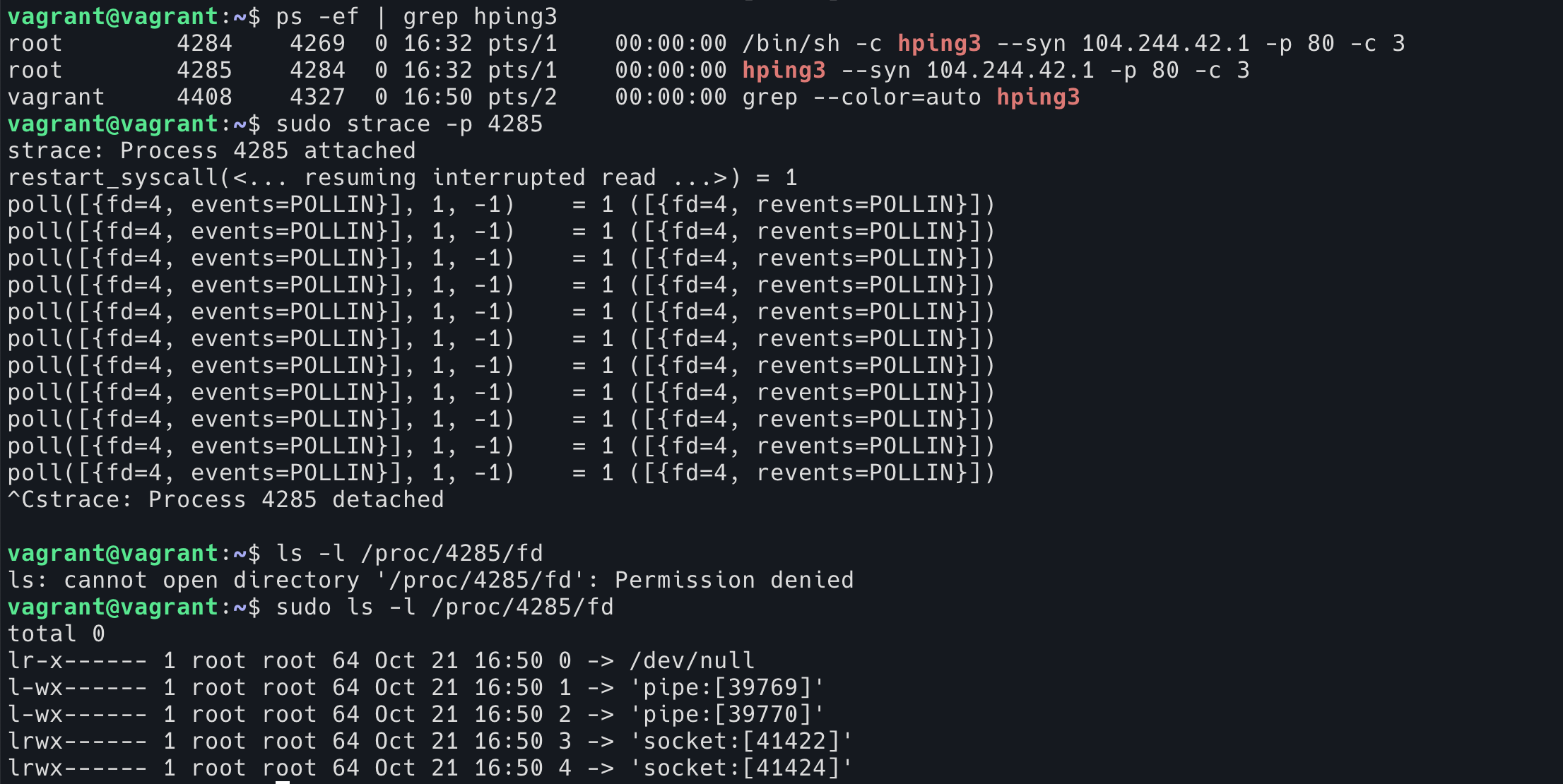
通过 strace 可以发现它一直在 poll 4 这个 fd,然后查看这个 fd,发现它是一个正常的 socket,应该就是 ping tcp 端口使用的那个 socket.
然后,我们应该去看一下,正常的 hping3 的 trace 是什么样子的。
strace hping3 104.244.42.1 -p 80 --syn -c 1
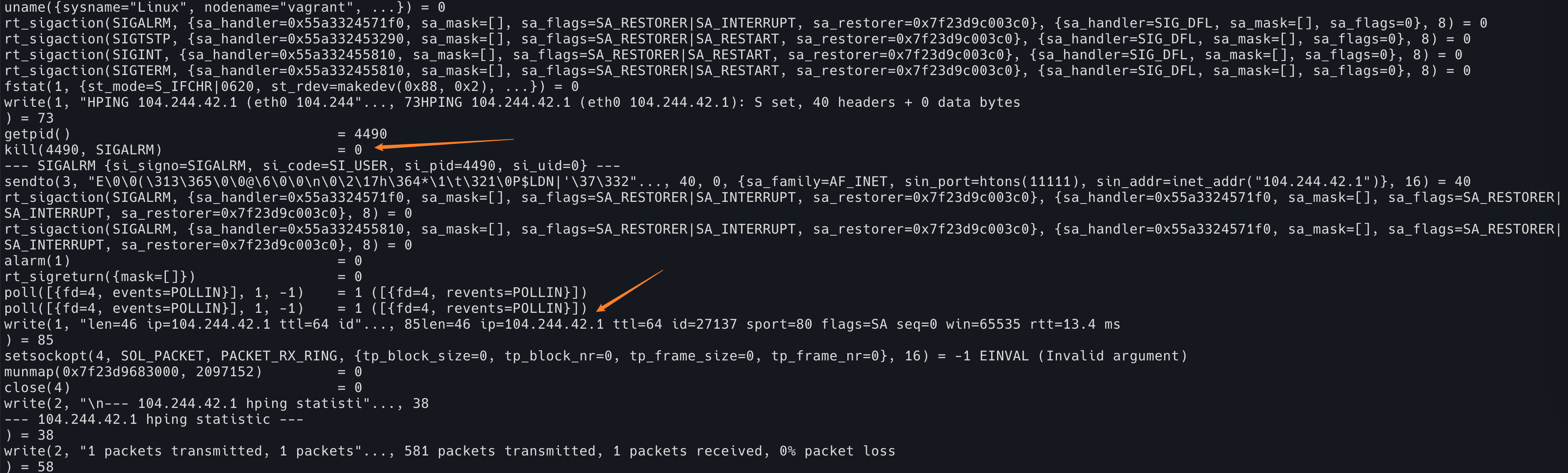
可以看到 poll 附近很神奇,下面突然就开始 write 到 stdout 内容了。不知道怎么结束的。
但是往上看,有一段代码获取了当前的 pid,然后给自己发送了 SIGALRM。再往前,发现注册了 SIGALRM 的 handler.
SIGALRM 是什么呢?
SIGALRM is an asynchronous signal. The SIGALRM signal is raised when a time interval specified in a call to the alarm or alarmd function expires.
看起来是用来做异步的。
搜索了一下 hping3 的代码。发现代码里确实是用这个信号的。
|
1 2 3 4 5 6 7 |
/* use SIGALRM to send packets like ping do */ Signal(SIGALRM, send_packet); /* binding */ if (ctrlzbind != BIND_NONE) Signal(SIGTSTP, inc_destparm); Signal(SIGINT, print_statistics); Signal(SIGTERM, print_statistics); |
那么我们的 uWSGI 下的异常 hping3 是否是因为没有收到这个 SIGALRM 而一直在傻 poll 呢?
在上面的 图1 中,卡住的 hping3 pid 是 4285,我们看下这个进程能否处理信号:
|
1 2 3 4 5 6 |
root@vagrant:/home/vagrant# cat /proc/4285/status | grep Sig SigQ: 5/3571 SigPnd: 0000000000000000 SigBlk: fffffffe7ffbfeff SigIgn: 0000000000000000 SigCgt: 0000000180086002 |
这里可以发现 SigBlk 不是全 0 的,说明有 signal 被 block 了。SigBlk 是个 64 个 bit 组成的 bitmask,每一位代表一个 signal 是否被 block,1 是 block,0 是没有 block。从右到左分别表示 1-64 号信号。
举例:
|
1 2 3 4 5 6 7 8 9 10 11 |
00000000280b2603 ==> 101000000010110010011000000011 | | | || | || |`-> 1 = SIGHUP | | | || | || `--> 2 = SIGINT | | | || | |`----------> 10 = SIGUSR1 | | | || | `-----------> 11 = SIGSEGV | | | || `--------------> 14 = SIGALRM | | | |`-----------------> 17 = SIGCHLD | | | `------------------> 18 = SIGCONT | | `--------------------> 20 = SIGTSTP | `----------------------------> 28 = SIGWINCH `------------------------------> 30 = SIGPWR |
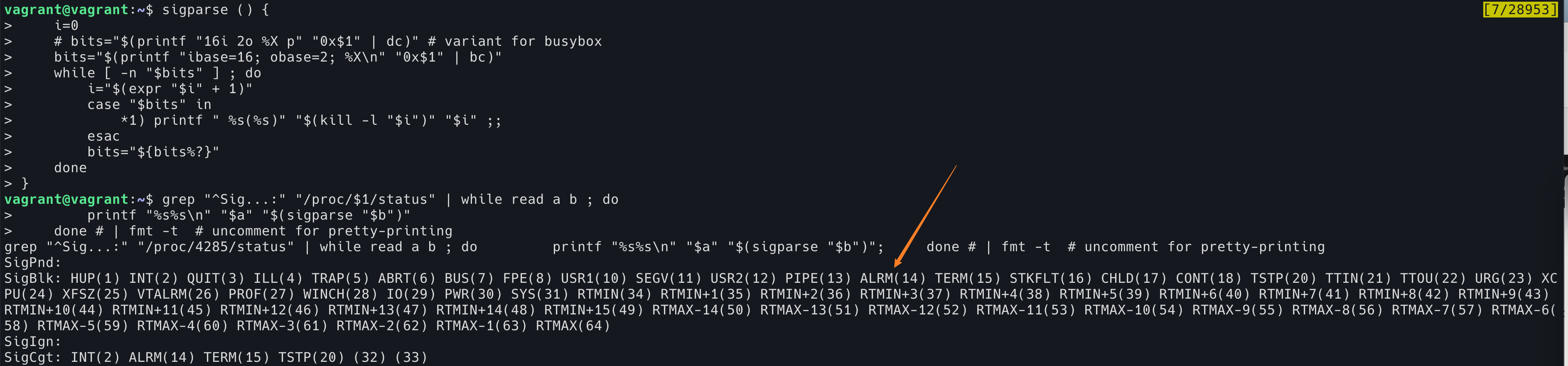
可以使用下面这段脚本去 parse 到底哪些信号被 block 了:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
sigparse () { i=0 # bits="$(printf "16i 2o %X p" "0x$1" | dc)" # variant for busybox bits="$(printf "ibase=16; obase=2; %X\n" "0x$1" | bc)" while [ -n "$bits" ] ; do i="$(expr "$i" + 1)" case "$bits" in *1) printf " %s(%s)" "$(kill -l "$i")" "$i" ;; esac bits="${bits%?}" done } grep "^Sig...:" "/proc/4285/status" | while read a b ; do printf "%s%s\n" "$a" "$(sigparse "$b")" done # | fmt -t # uncomment for pretty-printing |
可以看到,hping3 需要的 14 号信号正好被 block 了。
在 manual 中得知:
A child created via fork(2) inherits a copy of its parent’s signal mask; the signal mask is preserved across execve(2).
所以说,我们正常的 hping3 可以收到 signal,但是 uWSGI 里面 fork 出来的进程就不可以,可能是 hping3 从 uWSGI 里面继承了 signal mask,导致它也去 block 14 这个 signal 了。
我们可以去看下 uWSGI 里面是否也是 block 了这个 signal 的:
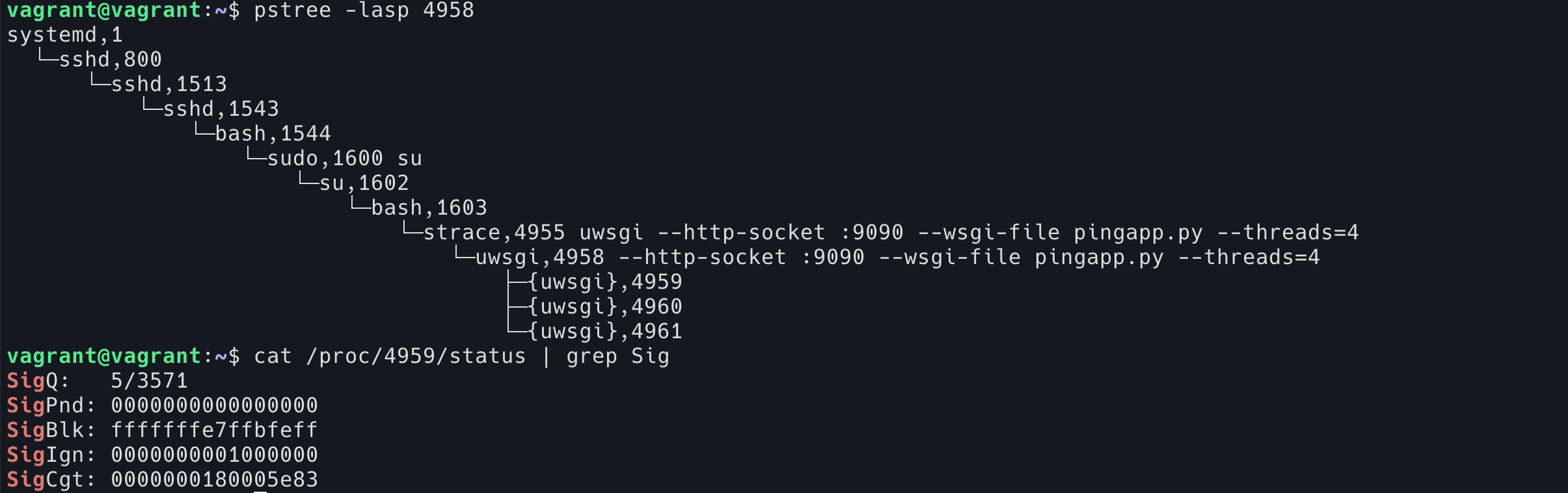
果然是的。
在代码中发现,里面只有 core_id = 0 的 thread 是处理信号的,其余的 thread block 了所有的信号。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
void uwsgi_setup_thread_req(long core_id, struct wsgi_request *wsgi_req) { int i; sigset_t smask; pthread_setcancelstate(PTHREAD_CANCEL_ENABLE, &i); pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS, &i); pthread_setspecific(uwsgi.tur_key, (void *) wsgi_req); if (core_id > 0) { // block all signals on new threads sigfillset(&smask); #ifdef UWSGI_DEBUG sigdelset(&smask, SIGSEGV); #endif pthread_sigmask(SIG_BLOCK, &smask, NULL); |
这段代码是 core_id 如果大于0,那么 block 所有的信号,如果不大于 0,就处理信号。
所以到现在也就明白我写的那个最小的 case 为什么不能复现了:我使用了默认配置,只有一个 thread,core_id =0,它永远可以处理信号。而生产环境开了 64 个 thread,只有 1/64 的几率能够处理信号从而让应用正确返回。
我们可以重新验证一下,开 2 个 thread,预期是它会有 50% 的几率卡住:
uwsgi --http-socket :9090 --wsgi-file pingapp.py --threads=2
果然是,50% 能得到结果,50% 会卡住。
到这里就真相大白了。至于修改呢,我打算直接用 socket.connect 来测量 tcp 的连接时间。因为 TCP 是 3 次握手的,但是对于客户端来说基本上只花费了一个 RTT 的时间。测试下来,这样得到的时间和 hping3 也是一致的。
另外这个故事告诉我们,uWSGI 下 fork 出来的子进程最好都默认信号不工作,虽然 core_id =0 是可以处理信号的,但是这个作为 uWSGI 本身回应信号的设计就可以。发现 uWSGI 的代码中还有很多别的地方调用了 sigprocmask(2),可能还有其他屏蔽信号的地方。
有一位智者同事曾经跟我说过这么一句话:
Learn some eBPF, xintao!
看来是时候认认真真学一学 eBPF 啦。
教训:
1. 阻塞式问题一定要仔细看 strace(1) 的结果
2. 不要相信黑盒的节操, 给自己发信号来实现业务逻辑, handler 里还有大片的异步信号不安全的函数, 我想都不敢想, 他们就敢这么做; 要是用 self-pipe trick 我都能通过 strace 一眼看出这里的实现了 (poll(2) -> kill(2) -> write(2)).
3. 如果自己写的应用依赖信号传递, 那么在应用的开始要重置 signal mask.
4. 如果自己写的应用要 fork + exec 子进程, 在 exec 之前重置 signal mask.
3 和 4 都是 SUSv3 里提到的, 上了两次当了, 自己以后可不要给自己挖坑了.
tql, Orz
SUSv3 这种东西也有必要阅读吗?感觉太枯燥了……
专门看了一眼 SUSv4, 里面依然有这样的说法:
(from susv3-2018/funcitons/exec, rationale)
> This volume of POSIX.1-2017 specifies that signals set to SIG_IGN remain set to SIG_IGN, and that the new process image inherits the signal mask of the thread that called exec in the old process image. This is consistent with historical implementations, and it permits some useful functionality, such as the nohup command. However, it should be noted that many existing applications wrongly assume that they start with certain signals set to the default action and/or unblocked. In particular, applications written with a simpler signal model that does not include blocking of signals, such as the one in the ISO C standard, may not behave properly if invoked with some signals blocked. Therefore, it is best not to block or ignore signals across execs without explicit reason to do so, and especially not to block signals across execs of arbitrary (not closely cooperating) programs.
总之就是一群有 bug 的应用相互挖坑, 最后用户遭殃的故事.
学到了,谢谢
Good debug!
经典老番之一了,应用自己定义的非标行为奇奇怪怪
BTW 在这个场景下,eBPF 这种东西说实话不如 static trace 的工具方便与好用
嗯,这个场景确实没怎么用上,只是最后的验证稍微用了下。
专门看了一眼
Pingback: 寻找丢失的信号 | 卡瓦邦噶!