最近做了一个好玩的工具,叫 xbin.io 。其中有一项工作是为不同的工具来构建 Docker 镜像,让他们都运行在 Docker 中(实际上,是兼容 Docker image 的其他 sandbox 系统,没有直接用 Docker)。支持的工具越来越多,为了节省资源,Build 的 Docker image 就越小越好,文件越少,其实启动速度也会略微快一些,也会更安全一些。
这篇文章来介绍一下做 Docker Image 的一些技巧。
在之前的博客 Docker (容器) 的原理 中介绍过 Docker image 是如何工作的。简单来说,就是使用 Linux 的 overlayfs, overlay file system 可以做到,将两个 file system merge 在一起,下层的文件系统只读,上层的文件系统可写。如果你读,找到上层就读上层的,否则的话就找到下层的给你读。然后写的话会写入到上层。这样,其实对于最终用户来说,可以认为只有一个 merge 之后的文件系统,用起来和普通文件系统没有什么区别。
有了这个功能,Docker 运行的时候,从最下层的文件系统开始,merge 两层,得到新的 fs 然后再 merge 上一层,然后再 merge 最上一层,最后得到最终的 directory,然后用 chroot 改变进程的 root 目录,启动 container。
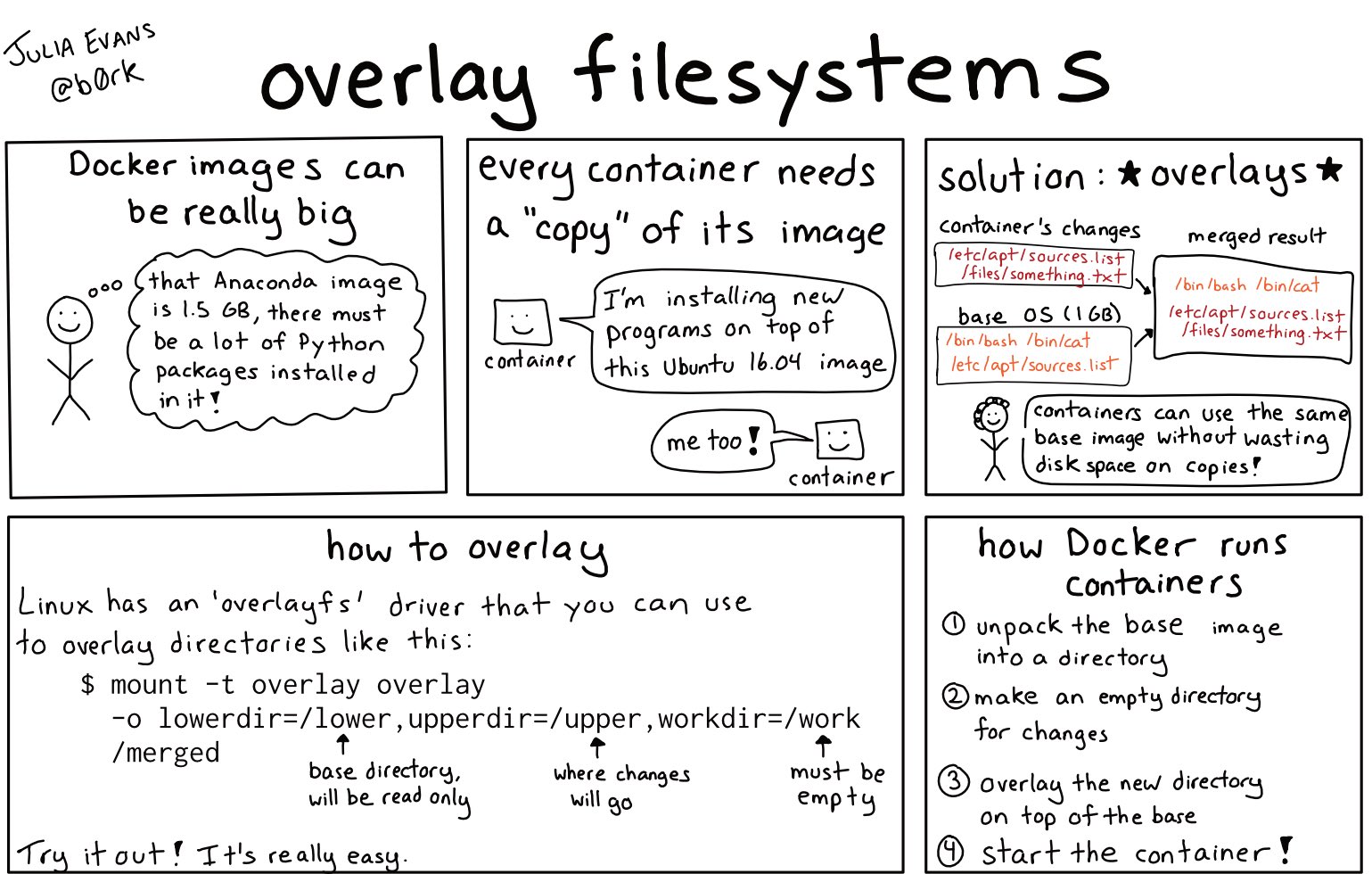
了解了原理之后,你会发现,这种设计对于 Docker 来说非常合适:
- 如果 2 个 image 都是基于 Ubuntu,那么两个 Image 可以共用 Ubuntu 的 base image,只需要存储一份;
- 如果 pull 新的 image,某一层如果已经存在,那么这一层之前的内容其实就不需要 pull 了;
后面 build image 的技巧其实都是基于这两点。
另外稍微提一下,Docker image 其实就是一个 tar 包。一般来说我们通过 Dockerfile 用 docker built 命令来构建,但是其实也可以用其他工具构建,只要构建出来的 image 符合 Docker 的规范,就可以运行。比如,之前的博文 Build 一个最小的 Redis Docker Image 就是用 Nix 构建出来的。
技巧1:删除缓存
一般的包管理器,比如 apt, pip 等,下载包的时候,都会下载缓存,下次安装同一个包的时候不必从网络上下载,直接使用缓存即可。
但是在 Docker Image 中,我们是不需要这些缓存的。所以我们在 Dockerfile 中下载东西一般会使用这种命令:
|
1 2 3 4 |
RUN dnf install -y --setopt=tsflags=nodocs \ httpd vim && \ systemctl enable httpd && \ dnf clean all |
在包安装好之后,去删除缓存。
一个常见的错误是,有人会这么写:
|
1 2 3 4 |
FROM fedora RUN dnf install -y mariadb RUN dnf install -y wordpress RUN dnf clean all |
Dockerfile 里面的每一个 RUN 都会创建一层新的 layer,如上所说,这样其实是创建了 3 层 layer,前 2 层带来了缓存,第三层删除了缓存。如同 git 一样,你在一个新的 commit 里面删除了之前的文件,其实文件还是在 git 历史中的,最终的 docker image 其实没有减少。
但是 Docker 有了一个新的功能,docker build --squash。squash 功能会在 Docker 完成构建之后,将所有的 layers 压缩成一个 layer,也就是说,最终构建出来的 Docker image 只有一层。所以,如上在多个 RUN 中写 clean 命令,其实也可以。我不太喜欢这种方式,因为前文提到的,多个 image 共享 base image 以及加速 pull 的 feature 其实就用不到了。
一些常见的包管理器删除缓存的方法:
|
yum |
yum clean all |
|
dnf |
dnf clean all |
|
rvm |
rvm cleanup all |
|
gem |
gem cleanup |
|
cpan |
rm -rf ~/.cpan/{build,sources}/* |
|
pip |
rm -rf ~/.cache/pip/* |
|
apt-get |
apt-get clean |
另外,上面这个命令其实还有一个缺点。因为我们在同一个 RUN 中写多行,不容易看出这个 dnf 到底安装了什么。而且,第一行和最后一行不一样,如果修改,diff 看到的会是两行内容,很不友好,容易出错。
可以写成这种形式,比较清晰。
|
1 2 3 4 5 6 |
RUN true \ && dnf install -y --setopt=tsflags=nodocs \ httpd vim \ && systemctl enable httpd \ && dnf clean all \ && true |
技巧2:改动不频繁的内容往前放
通过前文介绍过的原理,可以知道,对于一个 Docker image 有 ABCD 四层,B 修改了,那么 BCD 会改变。
根据这个原理,我们在构建的时候可以将系统依赖往前写,因为像 apt, dnf 这些安装的东西,是很少修改的。然后写应用的库依赖,比如 pip install,最后 copy 应用。
比如下面这个 Dockerfile,就会在每次代码改变的时候都重新 Build 大部分 layers,即使只改了一个网页的标题。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
FROM python:3.7-buster # copy source RUN mkdir -p /opt/app COPY myapp /opt/app/myapp/ WORKDIR /opt/app # install dependencies nginx RUN apt-get update && apt-get install nginx RUN pip install -r requirements.txt RUN chown -R www-data:www-data /opt/app # start server EXPOSE 8020 STOPSIGNAL SIGTERM CMD ["/opt/app/start-server.sh"] |
我们可以改成,先安装 Nginx,再单独 copy requirements.txt,然后安装 pip 依赖,最后 copy 应用代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
FROM python:3.7-buster # install dependencies nginx RUN apt-get update && apt-get install nginx COPY myapp/requirements.txt /opt/app/myapp/requirements.txt RUN pip install -r requirements.txt # copy source RUN mkdir -p /opt/app COPY myapp /opt/app/myapp/ WORKDIR /opt/app RUN chown -R www-data:www-data /opt/app # start server EXPOSE 8020 STOPSIGNAL SIGTERM CMD ["/opt/app/start-server.sh"] |
技巧3:构建和运行 Image 分离
我们在编译应用的时候需要很多构建工具,比如 gcc, golang 等。但是在运行的时候不需要。在构建完成之后,去删除那些构建工具是很麻烦的。
我们可以这样:使用一个 Docker 作为 builder,安装所有的构建依赖,进行构建,构建完成后,重新选择一个 Base image,然后将构建的产物复制到新的 base image,这样,最终的 image 只含有运行需要的东西。
比如,这是安装一个 golang 应用 pup 的代码:
|
1 2 3 4 5 6 |
FROM golang as build ENV CGO_ENABLED 0 RUN go install github.com/ericchiang/pup@latest FROM alpine:3.15.4 as run COPY --from=build /go/bin/pup /usr/local/bin/pup |
我们使用 golang 这个 1G 多大的 image 来安装,安装完成之后将 binary 复制到 alpine, 最终的产物只有 10M 左右。这种方法特别适合一些静态编译的编程语言,比如 golang 和 rust.
技巧4:检查构建产物
这是最有用的一个技巧了。
dive 是一个 TUI,命令行的交互式 App,它可以让你看到 docker 每一层里面都有什么。
dive ubuntu:latest 命令可以看到 ubuntu image 里面都有什么文件。内容会显示为两侧,左边显示每一层的信息,右边显示当前层(会包含之前的所有层)的文件内容,本层新添加的文件会用黄色来显示。通过 tab 键可以切换左右的操作。
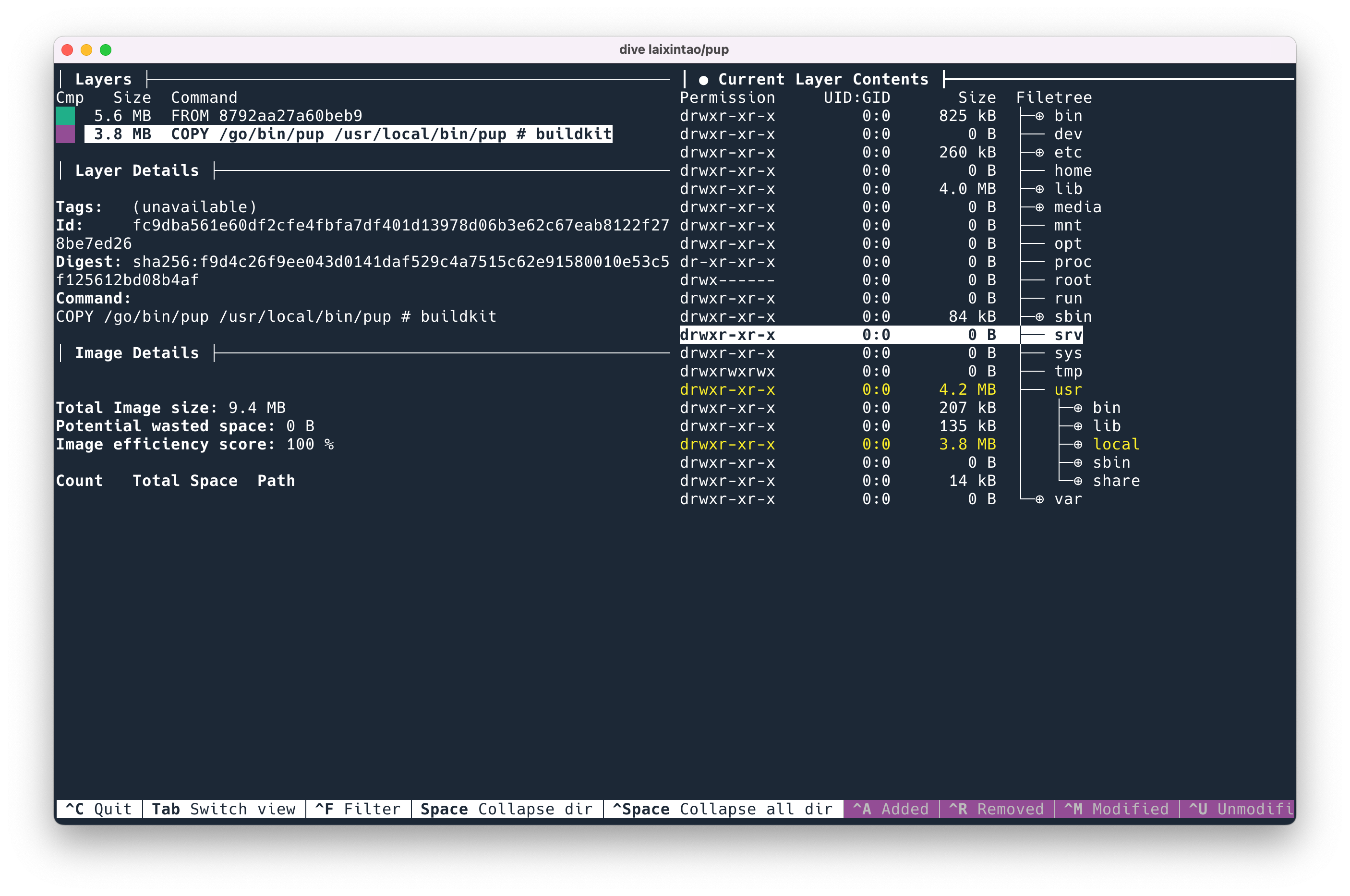
一个非常有用的功能是,按下 ctrl + U 可以只显示当前层相比于前一层增加的内容,这样,就可以看到增加的文件是否是预期的了。
按 ctrl + Space 可以折叠起来所有的目录,然后交互式地打开他们查看,就像是 Docker 中的 ncdu。
参考资料:
- https://jvns.ca/blog/2019/11/18/how-containers-work–overlayfs/
- https://www.kernel.org/doc/html/latest/filesystems/overlayfs.html
- http://docs.projectatomic.io/container-best-practices/
Pingback: 周刊第12期:每周轮子计划、程序员应该如何写博客 – 爱读书网
Pingback: Weekly Issue 12: The Weekly Wheel Plan, How Programmers Should Blog – FENQ
我个人比较喜欢在代码中维护一个小目录,里面放着一系列用于初始化的 Bash 脚本,例如:包安装、Key 拷贝等等。先把这个小目录拷贝进去,然后在 DockerFile 里面直接用 RUN 来执行。这样子 DockerFile 里面不会内容太多,同时 Bash 脚本也更好维护。
Pingback: 4 个超实用的 Docker 镜像构建技巧-陌上烟雨遥
Pingback: 4 个超实用的 Docker 镜像构建技巧-陌上烟雨遥
Pingback: 4 个超实用的 Docker 镜像构建技巧-陌上烟雨遥