在 四层负载均衡漫谈 介绍了四层负载均衡需要解决的问题,和一些常用的解决方案之后,通过学习一些其他公司的四层技术方案,我们会发现不同的公司在针对自己的业务做定制的时候,会有不同的取舍,非常有意思,我们精彩继续。
今天来分析 Cloudflare 的四层负载均衡方案:Unimog,主要参考的是这篇 Unimog – Cloudflare’s edge load balancer。Cloudflare 是一家做 CDN 的公司,四层负载均衡对他们来说至关重要,在技术选择上面,可以看到相比于 Google 的 Maglev,Cloudflare 选择的是性价比更高,更适合他们的方案。
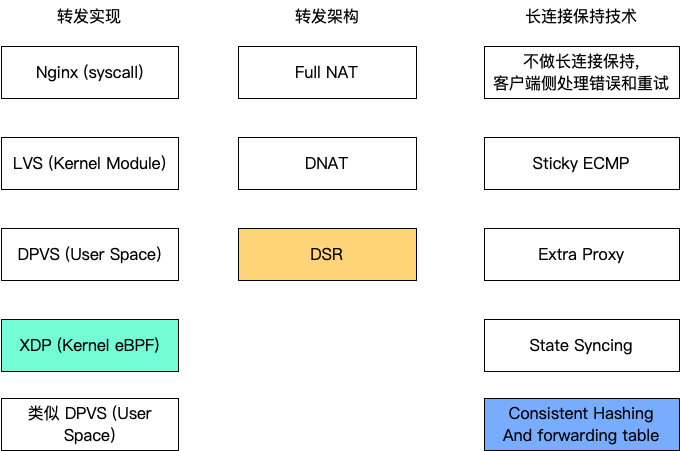
Cloudflare 这家公司是使用自己设计的硬件服务器的,按照自己的情况量身定制,最新一代已经是第 12 代(中文版)了,最新架构采用了 2U 的设计,看似浪费空间,但是整体上可以降低机架的功率,2U 可以用大风扇,散热性能会更好,总拥有成本(TCO)更低。而且,Cloudflare 机房的空间看起来不是很紧张,这种设计符合达到他们的最大性价比。以此高效的运营效率,无所不用其极降低生产成本,才可以让 Cloudflare 提供免费的服务,为付费用户提供优质的服务。
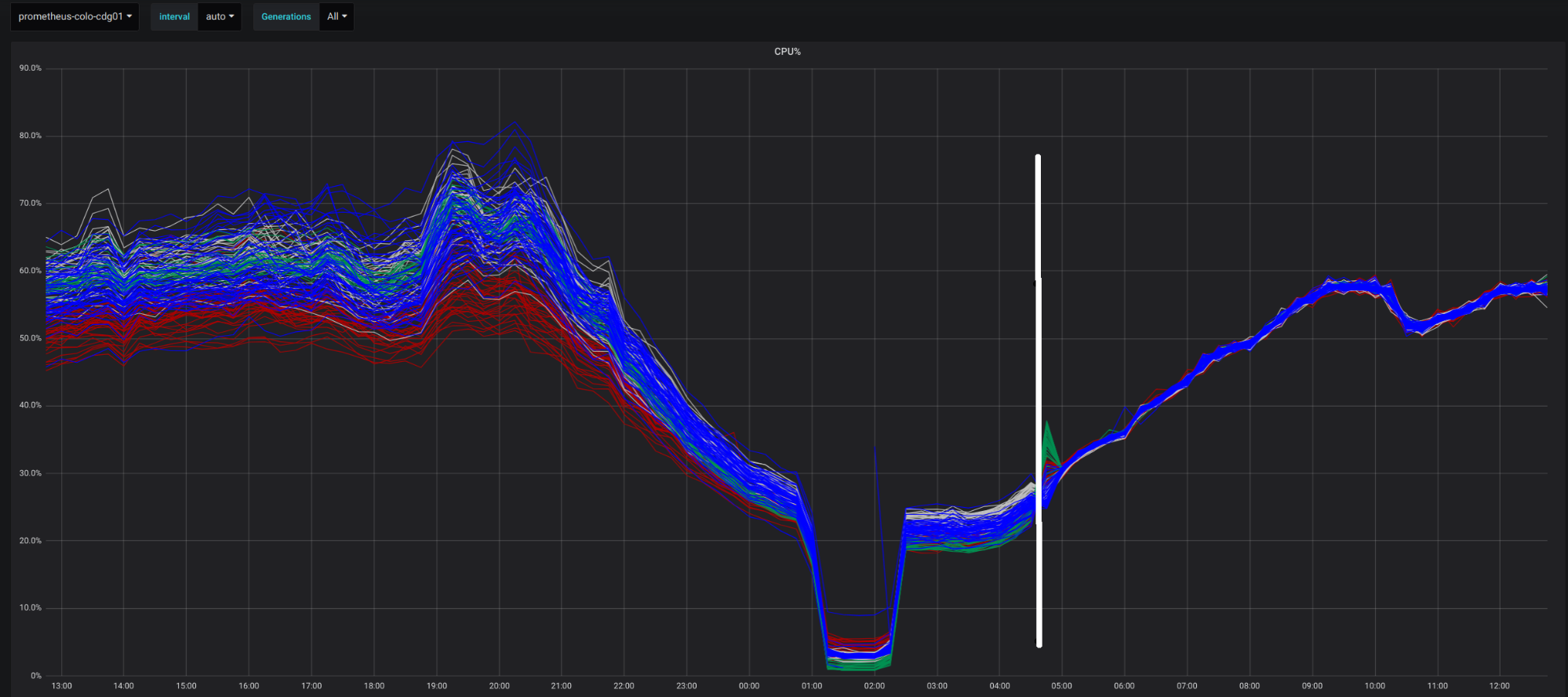
CPU 的性能逐年提高,服务器已经设计到 12 代了,那么前 11 代怎么办?难道上架新服务器,就直接退役旧服务器吗?肯定不是的,要让服务器在岗位上榨干最后一点价值。所以机房内的服务器都是不同型号混合部署的。这时候就有一个问题:新的服务器性能好,旧的服务器性能差,如果应用大规模部署,有的在新服务器上,有的在旧服务器上,如果负载“均衡”发给每一台机器上的 QPS 都相等——QPS 太高的话,会让旧服务器上服务的请求延迟比较高;QPS 太低的话,会让新服务器的 CPU 利用率不足。
所以 Unimog 有一个非常重要的特性,就是可以根据(RS)机器的负载自动调整连接数量:如果负载低了,会承载更多的连接,负载高了,新连接就不会过来,所谓能者多劳。(对比之前 Google 的负载均衡设计可以看出,Google 着重的是稳定性,能够近乎完美地保持连接,即使应用升级也不会发错,但是每一个 Maglev 实例收到的请求是一样的,Maglev 发给 RS 的 QPS 也是等分的。)
动态负载均衡还有一个好处:有一些连接花费的时间比较多,有些花费的时间少,动态调整负载,可以在连接成本不均衡的情况下达到负载均衡。有时候机器上同时运行了其他程序带来一些额外负载,动态负载均衡也能在这种情况下降低此机器的连接数。这都是静态的权重调整做不到的。
通过下图可以看出,在部署 Unimog 之后,所有服务器,不管型号新旧,利用率趋于一致。
Unimog 的设计原则是软件兼容硬件。Unimog 要运行在 General Purpose 的服务器上,而不是运行在专用服务器上。这样,硬件团队可以根据机房设计最大效率的机器,软件团队去榨干硬件的性能,优化整体的效率。
除了这些,Cloudflare 在意的地方还有一个,就是性能。因为作为 CDN 公司,最重要的业务就是防 DDoS,保护客户的网站,所以高性能丢弃攻击者的数据包是一个重点功能。
全都是负载均衡
基于以上特点,Cloudflare 的部署看似疯狂但是又很合理——机房内的所有机器都是负载均衡器。即所有的机器都安装了四层负载均衡,路由器无论把包转发给哪一个机器,这个机器都可以转发到正确的 RS 上。
这样做有几个好处:
- 负载均衡不需要做容量规划了,因为能用的机器都已经用上了;
- 最大限度做 DDoS 防护(主要由四层负载均衡的一个组件,L4Drop 来负责),也是因为所有能用的机器都上阵了。Cloudflare 总体的网络架构是 Anycast,即200多个城市的机房都宣告一样的 VIP 路由出去,用户访问一个 Cloudflare 的 IP,会被路由到最近的地方。所有的机房都能处理所有的流量,机房内所有的机器都能处理流量,最大化了自己的资源来运行业务;
- 运维架构简单,因为所有的机器都是一样的。其实除了 Unimog,在 Edge Server 上都运行了 Workers, WARP 等业务,Edge Server 都是一样的。
- 如果单独划出来机器部署负载均衡,为了让效率最大化,要花很大的努力让它达到最大的吞吐,比如优化 LB 之前的网络链路,优化最大吞吐下的性能瓶颈。而全员 LB 的情况下,就不需要为了让机器达到最大的 load 做优化了。
要做到这个,在设计上要求 Unimog 能够和应用一起部署。应用不能影响 Unimog 的运行,Unimog 的部署也不影响应用。
转发链路
像 Cloudflare 这种主要防护 ingress 方向的流量,用 DSR 是再合适不过了。
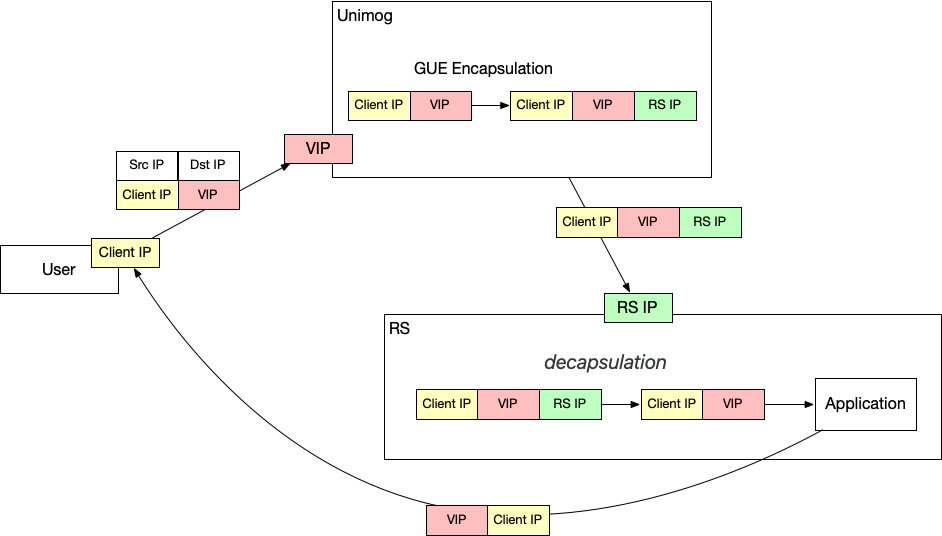
和 Google 相同的是,Cloudflare 也是用了封包来跨越 2 层。和 Google 不同的是,Cloudflare 用的方式是 GUE(Generic UDP Encapsulation),而不是 GRE。就是把二层包放到一个 UDP 包里面传输。
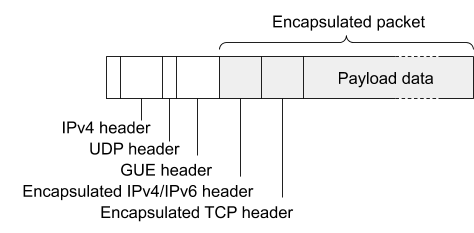
封装就要解决 MTU 超过 1500 bytes 的问题。Google 的方式是 MSS Clamping, 而 Cloudflare 的方式是用 Jumbo Frame,因为超过 1500 bytes 的封装部分只发生在机房内部,只要机房内能够传输 MTU 超过 1500 bytes 的包,就不会有问题。而且,Jumbo Frame 可以允许网络设备将多个小包合成一个大包来转发,效率更高。
连接保持技术
因为网络流量大,而且部署的 LB 实例很多,所以在 LB 实例之间同步状态的做法就不可行。
Cloudflare 用的连接保持方案类似 Google Maglev:所有的 LB 实例自己做决定,但是要保证对于相同的TCP 四元组,要得到相同的 RS IP。这样,就能保证,属于相同的 TCP 连接的包总是能到相同的 RS 上。
选择 RS 的流程如下:
- LB 实例独立计算 TCP 四元组 hash,得到一个 hash 值;
- 根据这个 hash 值查表,这个表叫做 forwarding table,然后得到一个 RS IP;
- 转发到 RS IP;
由此流程可以看出,保证相同四元组达到相同的 RS 的关键,是所有的 LB 都使用一样的 forwarding table。这个 forwarding table 是 control plane 统一下发的。(这个和 Google 不同,Google 是独立计算。)
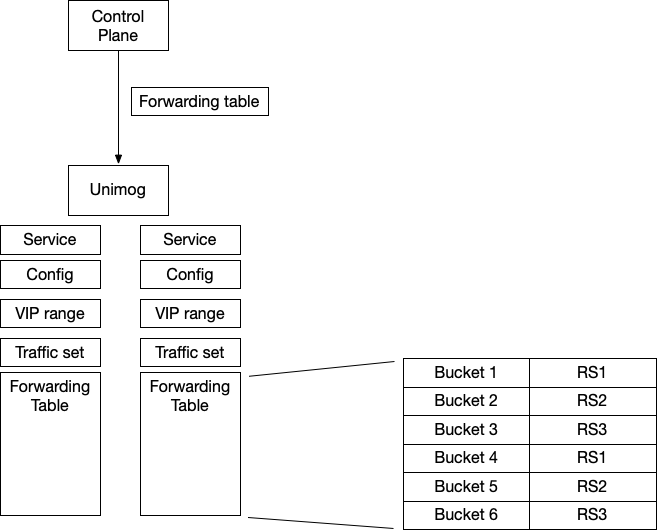
如何调整不同的 RS 的流量比例呢?假设有 100 个 RS,那么就设置 100 倍的 bucket 数量,即 1 万个。每 100 个 bucket 对应 1 个 RS。如果要让有的 RS 收到的流量多,可以将更多的 bucket 对应到这个 RS。
这样也解决了另一个问题,假设 RS A 下线了,那么不需要重新计算整个 forwarding table,只需要将 RS A 对应的 bucket 修改成其他的 RS 好了。只有 hash 到 RS A 的 TCP 连接需要到其他的 RS 上去。
这里还有一个问题:如果 forwarding table 变了,比如 RS A 的 bucket 替换成了 RS B,对于新的 TCP SYN 包,转发到 B 是没有问题的。但是原来连接 A 的,如果到了 B,会被 B 直接拒绝,返回 RST——我不认识你。所以这里要解决一个问题,就是 forwarding table 发生变化的时候,已经存在的连接要保持住,比如原来发送给 A 的,还是需要发送给 A。
解决方案非常巧妙:forwarding table 中,每一个 bucket 都对应两列 RS,第一列是当前主转发表(First hop),第二列是备份转发表(second hop)。当发生变化的时候,对应的 bucket 主转发表 RS A 变成了 RS B 或者 RS C,备转发表变成 RS A,如下图所示。
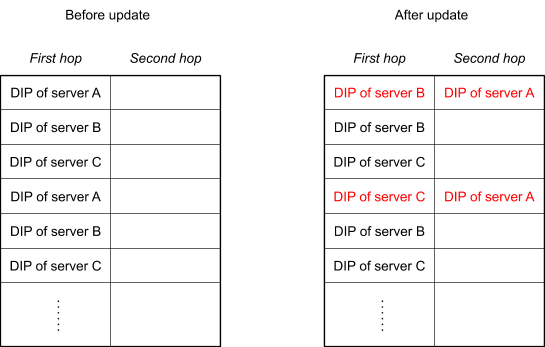
当一个 RS 机器收到包的时候(比如 RS B),先检查一下当前机器上有没有这个 TCP socket,如果有,正常处理。如果没有,就再次转发,按照备转发表转发到 RS A。
但是假设这个 RS A 要下线了,那它在备转发表里面要待多久呢?这个问题文章没有解释,我发邮件了问了 Cloudflare 这篇博客的作者 Daivd Wragg,Daivd 给我回复了非常详细的解释:
- 删除实例在 Cloudflare 不太常见,更常见的是短暂移除,reboot,然后回到集群,几乎所有的机器每月都会重启一次,所以每一个连接在 24 小时之内都有 1/30 的几率被 reset;
- 如果要移除的话,如文中所说,会进入到 drain state,在备表中,这个状态只会维持几分钟;
- 简单来说,连接可以归为两类:short-lived 和 long-lived。几分钟足够所有 short-lived 连接结束了,剩下的都是 long-lived,如果 drain 状态 30min,可能会有部分连接正常结束,但是不会很多,大部分超过几分钟的连接会存在数小时甚至数天,继续等待也不会带来更多显著受益,但是会让操作效率大大降低,所以只等待几分钟。
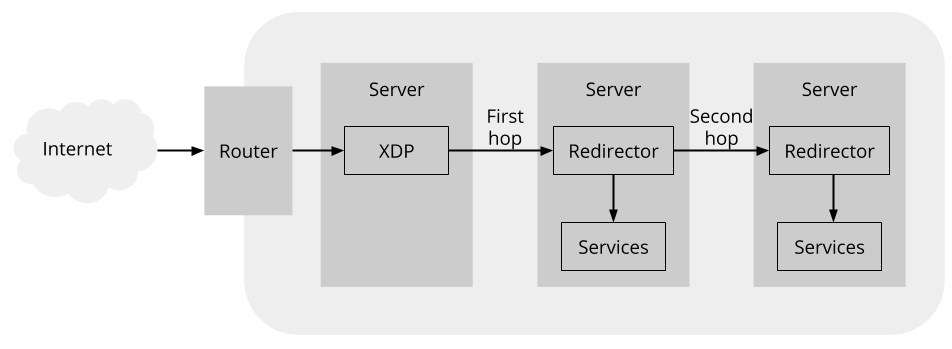
因为这个检查和 备转发表 转发,是在 RS 上实现的,所以不是 Unimog,而是一个 Redirector 组件。
这里有一个细节优化是,前面的 XDP 程序必定经过一次 hash + 查表了,在那时候,XDP 程序会将主表和备表结果都拿到,然后将备表的 RS 封装在 GUE 的 extension 中。这样,如果 Redirector 要转发的话,就不需要查表了,直接从 header 中拿到 RS IP 就可以了。
多一跳毕竟不太好,会增加延迟。不过好在这只会发生在当 forwarding table 有变化的时候影响长连接,这部分流量比较小,只占 1%。
Redirector 也负责 GUE 封装的卸载,即上面提过的在 RS 端做的 decapsulation。
和 Unimog 不同,Redirector 不是在 XDP 里面实现的,而是作为 TC classifier program 实现的。因为 XDP 跳过了大部分的网络栈,tcpdump 看不到,不好 debug。而相比 Unimog,XDP 带来的性能提升在 Redirector 这里不明显。所以可以用牺牲一点效率来换取更好的 debug 体验。
这个实现中,forwarding table 只保存了 2 个 hop,假设一个 bucket 在一段时间内变换两次:从 A -> B 然后 -> C, 那么 forwarding table 中只会记录 B 和 A,原来和 A 之间的连接就会失效。Beamer 论文提出用 3 个 hop,连接保持功能将更稳定。Cloudflare 认为,2 个 hop 就足够了。他们有一个优化是,在修改 bucket 的时候,尽量挑选时间最长没有变化的(leatest-change),去修改。比如扩容一个 RS X,就挑选一些很久没有变化过的 bucket,改到 RS X。
另外,如果把 buket 对应的主表记录和备表替换的话,只会影响谁来处理新的连接,而不会影响已经存在的连接。几乎也是「免费的」,所以,Unimog 会通过这种方式调整主备两个 RS 之间的负载。
基于 XDP 的软件实现
Unimog 选择了 XDP 来做包转发。这个选择非常适合 Cloudflare:
- 如果使用 DPDK 的话,需要和网卡配合,这样对硬件有要求了,而 Cloudflare 的思路是软件兼容硬件,任何机器都能跑负载均衡;
- Kernel Module 不方便开发测试和部署;
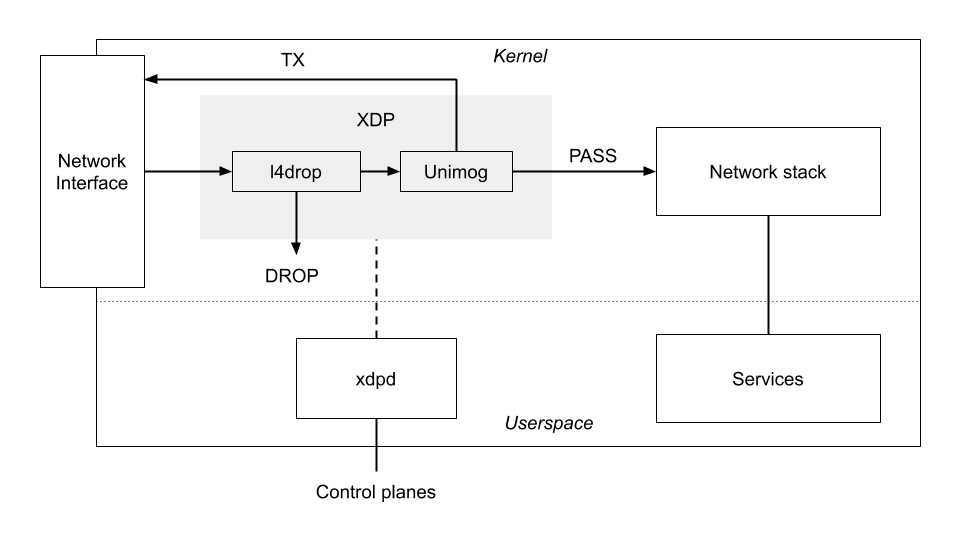
XDP 允许我们把程序直接 attach 到网卡上,每次有包过来,就会执行我们的程序。程序执行之后会得到三种结果中的一种:
- DROP 丢弃,这是 l4drop 的主要功能,把攻击者的包直接这里类丢弃
- TX 转发,XDP 程序可以直接对 packet 作出修改,然后通过网卡转发出去
- PASS l4drop 和 Unimog 都不处理,交给 Kernel 来处理。因为上面提到过,一台机器部署了不止 Unimog 一个程序,其他的程序可以正常使用 Kernel 的技术栈
从这个架构图可以看出,丢包发生在几乎最前面,差不多在网卡上了。在应对攻击的时候,机器采取了最大的性能进行丢包,而且用上了所有的机器资源,让 Cloudflare 能够提供的防护能力最大化。
XDPD
XDPD 是 XDP daemon 的意思。对比之前 Google Maglev 讨论配置下发的部分,这里就由 XDPD 负责。
XDPD 的主要工作是:
- 负责初始化 XDP 程序,将 XDP 程序 attach 到内核,并且帮 XDP 程序初始化需要的 map 等;
- XDP 程序运行需要读一些动态的配置信息,这些配置信息由 XDPD 从控制面获取。由于使用 map 传递,需要借助 helper function,性能会差,所以 XDPD 在 load XDP 程序之前会将这些值直接作为 const 插入到程序中;
- 负责暴露监控需要的 metrics 信息,也是从 map 中读取数据暴露实现的;
- xdpd 支持优雅重启,升级的时候不会中断 Unimog 和 l4drop;
这个架构的性能高,资源消耗少。LB 自身消耗的资源,对比服务用户业务消耗的资源,比值是 1%,也就是说 LB 几乎不消耗资源,免费的 LB。
以上几乎就是数据面的技术内容了。Unimog 还有一个重要依赖,就是控制面。
控制面 Conductor
控制面叫做 Conductor,负责 forwarding table 的生成,健康检查,RS 管理,负载均衡(通过调整 forwarding table)等等。
Conductor 基于 Consul 来实现:
- 使用 Consul 的 KV 存储来下发 VIP 配置和 forwarding table
- 依赖 Consul 对 Unimog 做健康检查
- 使用 Consul 的锁功能,确保只有一个 Conductor 在 active 状态,如果挂掉了,其他的 Conductor 实例可以拿到锁并开始运行
Conductor 会周期读 Prometheus 中的 metrics,判断 RS 的负载,然后根据负载去调整 forwarding table 中 RS 出现的次数,以此来平衡所有的 RS 之间的负载。
在分布式的系统中,还会有很多复杂的问题。在部署 Conductor 之后,他们发现会出现整个机房都在 overload 的情况:一开始是一些机器出现负载较高,然后健康检查发现问题,Unimog 停止发给这些 RS 流量,自动迁移到其他机器,然后其他机器也开始 overload,最终导致整个集群都 overload。目前文中说的解决办法是,Conductor 需要区分部分机器 overload 和当前整个机房负载整体较高的情况。
UDP 的支持
UDP 是无连接的,分成两种场景讨论。
一种是 ping-pong 类型,像 DNS,一个包出去,一个包回来,这种可以跳过 2 hop 的维护,一个 hop 必中。
另一个是请求发出去,响应源源不断的回来。这种场景,还是要维护这些包都到同一台 RS 上。可以用和 TCP 一样的方法来处理,但问题是 UDP 没有 SYN 包,怎么来区分出来是否是新建的连接呢?
方案是这样的,我们还是像 TCP 一样维护 2 hop 的表:
- 第一个 hop 的 Server 收到之后,检查当前机器是否有对应 4 元组的连接(是的,UDP 虽然是「无连接的」,但是你在 Linux 用
ss工具来查看,也是能看到 UDP 的「连接的」,实现上也有 socket 和连接的概念); - 如果没有,直接转发给第二个 hop。
于是现在 UDP 的新连接几乎都去第二个 hop 了。和 TCP 相反。
所以 Conductor 在添加 Server 的时候,如果想要它接收 TCP 流量,应该放到 first hop,如果想让它接收 UDP 流量,应该放到 second hop。(这个地方我感觉很奇怪,之前的描述,第二 hop,即备份表,应该是即将下线的 Server 正在 drain connection,这时候作为 UDP 不是反而开始接收流量了嘛?虽然问题不大,但是不如让 UDP 永远尝试 second hop 先,如果找不到再去 first hop,好像更好,可以保持行为一致。我的这个想法带来的另一个问题是,在实现上讲,这里先去第二个 hop,再去第一个 hop,从网络层面更加违反直觉。评论l2dy指出。)
这种还有一个缺点,就是如果使用 unconnected sockets,在系统找不到对应的四元组的话,就无法工作了。
有一些 UDP 流量本身有 flow 的概念,比如 QUIC。这样,即使像手机这种设备经常变换 IP 的情况,flow id 也是不变的。Unimog 可以从这些 UDP 流量中识别出来 flow id,然后基于 flow id 做 hash,而不是基于 4 元组。这样即使 IP 变了,同一个 flow 也可以保持住。目前 WARP 产品用了这个特性。
Special thanks to David Wragg for patiently answering my questions.
请教几个问题:
1. 这种DSR模式的负载,出方向的带宽,一般怎么统计啊?在各个real server上统计吗?
2. “Unimog可以根据机器的负载自动调整连接数量”, Unimog能接收多少连接,是看router转发多少连接到Unimog吧,router转发一般就是ecmp到多个Unimog节点吧,不同的Unimog应该接收大概相同的连接吧,怎么能根据自己的负载来调节处理的连接数量?
3. “保证相同四元组达到相同的 RS 的关键,是所有的 LB 都使用一样的 forwarding table。这个 forwarding table 是 control plane 统一下发的。(这个和 Google 不同,Google 是独立计算。”:这个forwarding table,应该每个负载节点多是一样的吧,google为什么要独立计算啊?
哇,感谢留言,这么短时间就发现了这么深刻的问题,厉害。
1. 不是很清楚问题,为什么要统计带宽呢?评估负载吗?对于 RS 来说,带宽完全不是问题,RS 性能远远不及 LB,是不会达到线速的,对于负载来说更重要的是 CPU 时间。如果要统计的话,需要看维度,统计机器维度的话要在 RS 做,要是基于 IP 的话,也可以在其他地方计数。
2. 这个是我理解错了,抱歉。router-unimog 这一段是不能调整的,调整的主要是这段 unimog – RS。文中提到了可编程交换机,使用这种或许可以做到,但是目前部署的方式还是普通商业路由器 + 全员负载均衡的。但是因为部署的 LB 数量众多,LB 消耗的资源又只有 1%,所以这部分不均衡不会带来很大的影响。原文相关部分已经修改。
3. 每个负载节点不是一样多的,Unimog 的表是统一下发的,本质是 hash 值 与 RS 的对应,可以让 100 个 bucket 对应 RS A,然后 10 个 bucket 对应 RS B,这样 RS A 就可以和 RS B 承担一样的流量。Google 为什么要独立计算呢?其实不是非常确定是否是独立计算的,因为论文中没提到有负载下发 lookup table 的内容,而且 configuration 的部分又提到了 BP,所以推测是只根据 BP 每一个 Maglev 在初始化的时候自己计算好 lookup table 的吧。其实想说的核心问题是,Maglev 本身对 RS 没有调整权重的功能,它的核心设计目标是保持连接的稳定性。
第一个问题,我没表达清楚,我想问的是,DSR这种负载模式,只有入方向过负载,出方向不过负载,出方向的监控怎么统计啊,比如带宽等指标。
RS 监控就可以吧。这个监控的目的是什么?
DSR模式,egress流量由L7 LB节点统计,这里一般是由TC hook实现,而且在L7 LB TC可以双向流量统计。
> 这个地方我感觉很奇怪,之前的描述,第二 hop,即备份表,应该是即将下线的 Server 正在 drain connection,这时候作为 UDP 不是反而开始接收流量了嘛?虽然问题不大,但是不如让 UDP 永远尝试 second hop 先,如果找不到再去 first hop,好像更好,可以保持行为一致。
因为 UDP 没有 SYN,无法判断一个包是新连接还是现有的。这时候为了确认有没有已有连接,包必须经过两个 hop(除非第一个 hop 就命中连接表)。反过来先去 second 再去 first hop 的话,状态是在 “first hop” 里保存,但实际的第一个 hop 是 “second hop”。这和没反转是一样的,还是比 TCP 多了一跳。
是的,原文这里不是想说可以节省一个 hop,UDP 这种 2 次 hop 是无法避免的。
我想说的是,这样不就可以让 UDP 和 TCP 新连接去哪里的行为一致了嘛?比如我要加节点,加到 hop 1 的地方,就可以预期无论是 TCP 还是 UDP,它就开始接新流量。而现在的话,我要让一个新的实例接收流量,我就要想到如果是 TCP 的话就加到 hop1,如果是 UDP 的话就加到 hop 2,会有心智负担。
你想说的可能是引入 primary 和 secondary hop 的定义,对于 UDP 来说 second hop 是 primary。
hop 本来就有网络中的先后顺序。如果把第二跳定义为 fisrt hop,心智负担更重了。
确实,这个是没想到的。这样看来还是原来的设计比较好。
这个我阅读原文也有疑问,感觉和TCP保持一致会更好点。
UDP applications with flows 如果把新的rs放到slot1,老的放到slot2,先看有没有slot2的session,没有再使用新的rs1,不是和TCP一致了么? 不知道为啥要把新的rs放到slot2==
「我的这个想法带来的另一个问题是,在实现上讲,这里先去第二个 hop,再去第一个 hop,从网络层面更加违反直觉。评论l2dy指出。)」
意会了,感谢楼上
是的,现在这样在文档中写清楚了的话问题也不大。
第一张图里提到了 Nginx,但 Cloudflare 已经换成 Pingora 了,可以更新下。
> Unimog 的设计目标是软件兼容硬件,Unimog 要运行在 General Purpose 的服务器上,而不是运行在专用服务器上。
Google 的 Maglev 和 AWS 的 Hyperplane 也都是这个策略,Google 论文中是说 “Maglev is a userspace application running on commodity Linux servers”,Hyperplane 则是跑在 EC2 VM 上的。Unimog 强调的更多是和应用服务混部,而不是硬件兼容性。
忽略第一句吧。。才发现第一张图里 Nginx 只是举个例子,不是说 Cloudflare 在用。我以为 Nginx 放在这里是说作为更上层的七层负载均衡来着。
没找到有 Nginx 的图,你指的是 四层负载均衡漫谈 这篇吗?
是指左上角白色底的 Nginx (syscall)。单独看的时候还以为这张图是从底往上的技术栈,再看另一篇才发现没有上下顺序关系,是只看高亮的那几块。
有道理。我修改一下。
Google 既然要在应用层操作网卡,是不是意味着对网卡有要求?至少要硬件和驱动支持才行。XDP 的话就没有这样的要求了。
当然是有要求的。 “With proper support from the NIC
hardware, we have developed a mechanism to move
packets between the forwarder and the NIC without any
involvement of the kernel”
Pingback: 四层负载均衡分析:美团 MGW | 卡瓦邦噶!
Pingback: 四层负载均衡分析:GitHub GLB | 卡瓦邦噶!
文里提到Unimog支持动态负载均衡技术,也是通过修改forwarding table,将高负载的RS替换为低负载的RS实现的吗?如果是这样的话,为了保证利用率尽量一致,改变的频率听起来会很频繁,感觉有不小的可能与RS下线产生冲突。比如RS A要下线,将RS B排到first hop,RS A放在second hop,同时Unimog检测到RS B负载较高,打算将一些指向RS B的bucket替换成负载较低的RS C,如果选到了之前RS A的bucket就不对劲了。
是的。这个问题非常好,所以文中也说如果用 3 hop 的话类似问题会大大缓解。
以您说的例子:比如RS A要下线,将RS B排到first hop,RS A放在second hop,同时Unimog检测到RS B负载较高,打算将一些指向RS B的bucket替换成负载较低的RS C,如果选到了之前RS A的bucket就不对劲了。
文中也提到尽量修改 leatest-change 的:
比如RS A要下线,将RS B排到first hop,RS A放在second hop,这个不变;同时Unimog检测到RS B负载较高,打算将一些指向RS B的bucket替换成负载较低的RS C,这时候我们选择 first hop 是 RS B 但是很久没有改变的,(不去修改刚刚和 RS A 交换的),假设负载还是需要降低,那么在过几分钟之后,待 RS B 和 RS A 的交换完全同步,旧连接关闭,那么就可以进行替换了。
这种方式应对的也是服务器负责不均衡的情况,不会用来解决流量突增的情况。流量突增应该依赖 hash 算法的散列程度解决。所以,对服务器负责不均衡的情况处理也不会特别频繁的。