今天我们来赏析 GitHub 的四层 LB 设计。
GitHub 的 GLB 是开源产品(当然了!),从架构上看,和之前介绍的 Cloudflare Unimog 很像,因为 GLB 是 Unimog 实现的重要参考。后面还会介绍一个叫做 Beamer 的四层负载均衡,也是参考了 GLB。所以 GLB 的连接保持设计创新性很强。
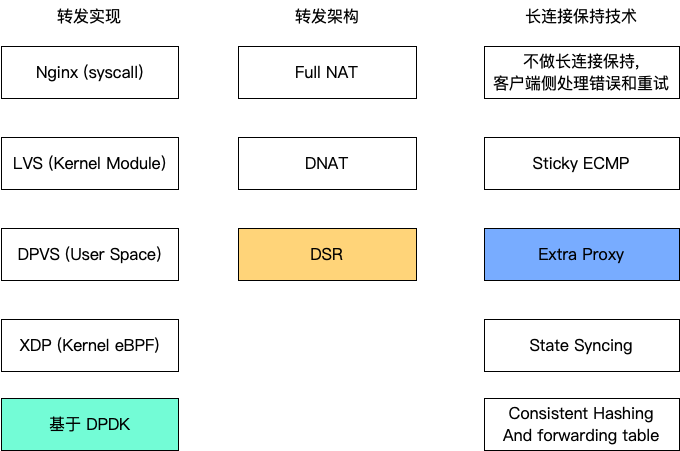
被借鉴最多的就是 GLB 的连接保持技术,所以我们直接从最精彩的开始讨论。
连接保持技术
Cloudflare Unimog 的连接保持方案和 GitHub GLB 几乎一致,所以我们在之前几乎都已经讨论过了。
简单总结一下:GLB 作为四层负载均衡,在 GLB 实例之间不需要同步任何信息。在转发的时候,每一个 GLB 根据 TCP 连接五元组 hash,独立作出决策,选中一个 RS 进行转发。
转发的过程是:
- GLB 收到一个包,根据包的五元组计算 hash(不管是不是 SYN,都一样对待);
- 根据 hash 查找转发表,找到对应的 2 个 RS,一个是主 RS 一个是备 RS,然后转发到主 RS;
- 主 RS 收到包之后,检查这个包是不是属于自己机器上的连接,如果是,就交给协议栈处理,如果不是,就转发到备 RS(备 RS 的地址记录在 GLB 发过来的包中)。
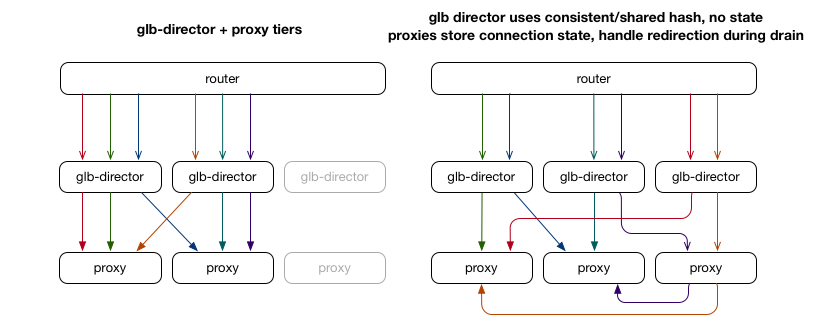
对比 Google Maglev 保持连接的方案有「两层」来保证同一个 flow 到同一个 RS 上:每一个 LB 实例都根据 SYN 包记录连接对应的 RS,即 connection table;然后使用一致性 hash 尽可能让相同的五元组选择相同的 RS。是属于「 connection table + hash查转发表」的方式。
而 GLB 的方案中不存在任何的状态保存,SYN 包和其他的包都可以使用一样的逻辑来转发,第一次转发不对就转发第二次,可以认为是「hash查转发表+hash查转发表」。Maglev 论文中提到了一些特殊情况,比如遇到 SYN DDoS 攻击的时候可能造成内存问题,在 GLB 这里就没有。
除了不用保存数据,这个转发方案和 Google Maglev 相比还有一个优点:Maglev 论文中提到,如果 Maglev 数量有变化,RS 数量也有变化,这样就会导致之前的 TCP 连接的包被发送到一个新的 Maglev 上,这个新的 Maglev connection table 中没有保存这个连接的状态,经过自己的 hash 计算选择 RS 会和之前的不一样(因为 RS 数量变化导致 hash 结果会有可能不一样),这时候连接就断了。GLB 就没有这个问题,GLB 实例可以和 RS 同时做变化。
转发表的生成
在这个方案中,转发表的生成是关键的一步。
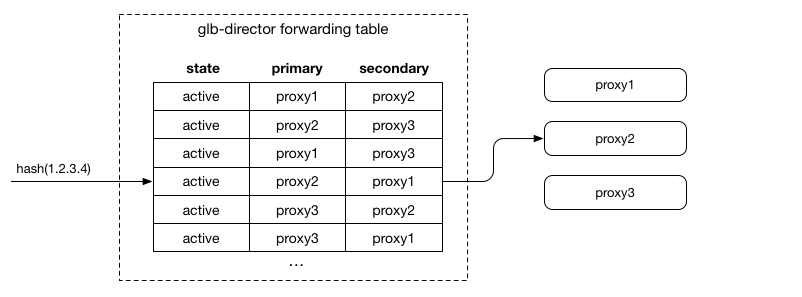
转发表要满足一下几个条件:
- 在 RS (就是图中的 proxy)修改的时候,只有变化的 RS 在表中会修改,没有变化的 RS 在表中的位置不变。即不能对整个表完全重新 hash;
- 表的生成不依赖外部的状态;
- 每一行的两个 RS 不应该相同(不然的话就相当于没有备 RS 了);
- 所有 RS 在表中出现的次数应该是大致相同的 (负载均衡);
实现方式是类似 Rendezvous hashing:对于每一行,将行号+ RS IP 进行 Hash 的到一个数字,作为「分数」,所有的 RS 在这一行按照分数排序,取前两名,作为主 RS 和 备 RS 放到表中。
然后按照以上的四个条件来分析:
- 如果添加 RS,那么只有新 RS 排名第一的相关的行需要修改,其他的行不会改变;
- 生成这个表只会依赖 RS 的 IP;
- 每一行的两个 RS 不可能相同,因为取的前两名;
- Hash 算法可以保证每一个 IP 当第一名的概率是几乎一样的;
不过要注意的是:在想要删除 RS 的时候,要交换主 RS 和 备 RS 的位置,这样,主 RS 换到备就不会有新连接了,等残留的连接都结束,就可以下线了;在添加 RS 的时候,每次只能添加1个,因为如果一次添加两个,那么这两个 RS 如果出现在同一行的第一名和第二名,之前的 RS 就会没来得及 drain 就没了,那么之前的 RS 的连接都会断掉。
转发架构和封装
GLB 也是使用的 DSR 转发架构,在这个系列之前的文章已经介绍过了,这里不重复了。
LB 到 RS 的转发, GLB 一开始使用的是用 GRE 封装然后放到 FOU 里面,现在直接换成了 GUE。上文提到的备 RS 的 IP 地址可以放到自定义的 GUE header 里面。
为什么不用 IPIP 来做封装呢?IPIP 是把一个 IP 包放到另一个 IP 里面做转发,看起来 header 更少。但是这样的话就没有地方放备 RS IP 了,唯一可行的地方是 underlay 的 IP 包的 option 里面。这会导致一个问题,就是路由器不认识这个 option,会涉及到需要 CPU 来处理,速度就更慢(叫做 Layer 2 slow path)。
为什么封装到 UDP 里面,而不是 IP 里面呢?如果是放到 UDP 包里面,那么对于负责转发的路由器来说,这个包就是一个普通的 UDP 包,可以按照四元组做 hash。如果是 IP 的话,对于路由器来说只能看到 IP 的数据,不会去解析内层的 overlay 的包内容,中间的路由器,以及 NIC,都会放到同一个 queue 中,如果一个 IP 对的流量太大的话,就会有性能瓶颈。
转发实现
GLB 是基于 DPDK 实现的。
因为设计上是无状态的,所以可以用 DPDK Packet Distributor 把工作散到任意数量的 CPU 上,并行执行,扩展性很强。
官方博客中提到支持 TCP over IPv4 or IPv6,也支持 ICMP,支持 PMTUD。没提到 UDP,应该是不支持 UDP?GitHub 的业务涉及 UDP 的应该不多。
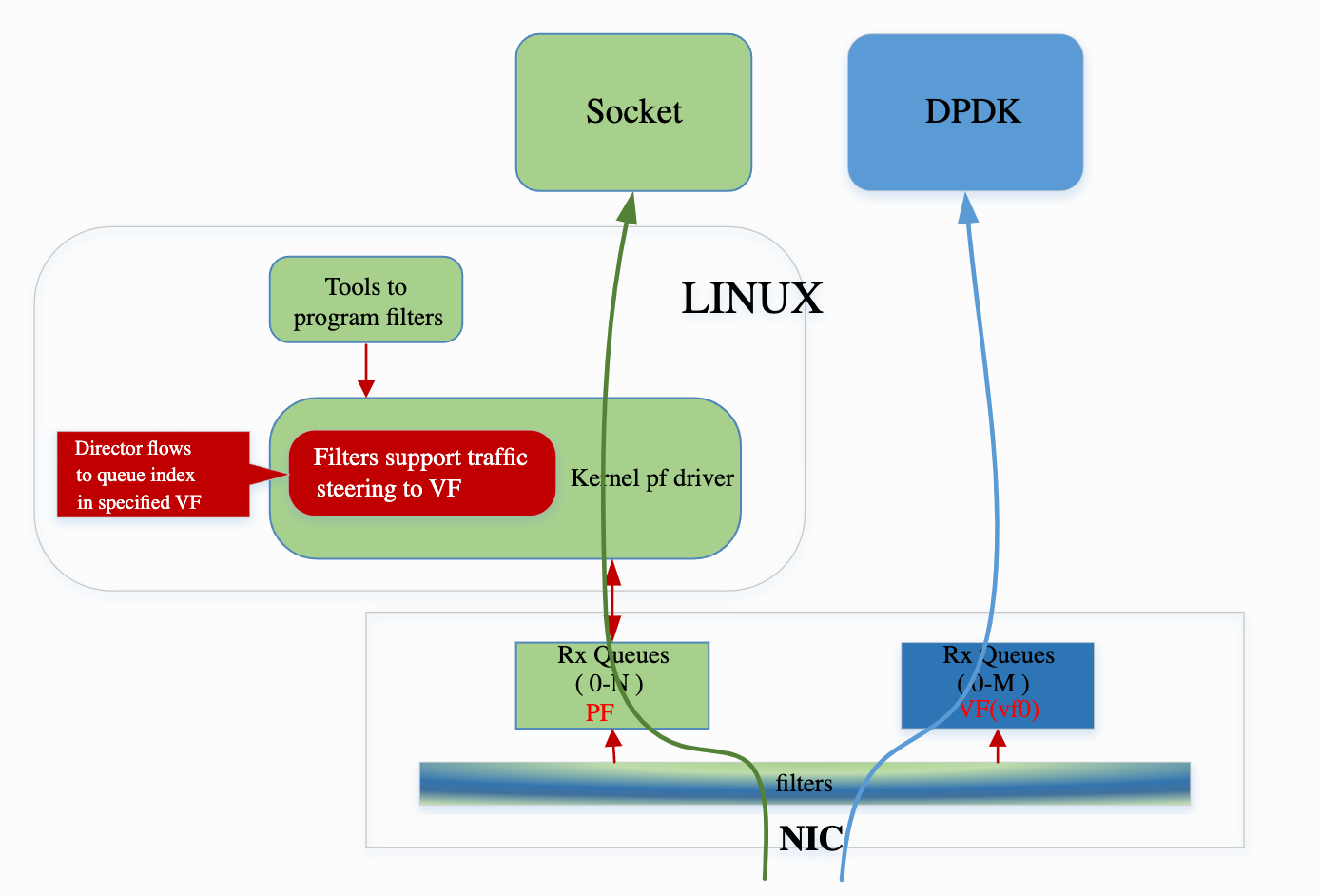
使用 DPDK 就有一个问题:流量都被 GLB 接管了,那么那些非数据面的流量怎么办?比如 sshd 等程序,这些程序是用 Kernel socket API 编写的,不支持 DPDK 的接口。
一种方法是安排单独的网卡接口,专门用于这些应用。DPDK 的流量走单独的网卡,控制面走单独的网卡。
GLB 是用了 Flow Bifurcation,就是可以将一个物理网卡虚拟成多个虚拟网卡,Kernel 协议栈和 DPDK 流量分别走不同的虚拟网卡。硬件网卡可以将流量区分出来走哪一个虚拟网卡,这部分功能几乎是不占用 CPU 的,所以不会有额外的资源消耗,也能达到线速。
Flow Bifurcation 可以使用下面两种硬件功能来实现:
- SR-IOV 是一个 PCI 标准,支持将一个物理卡虚拟出多个虚拟卡。云厂商虚拟机场景用的比较多。虚拟卡都有单独的 queue,MAC 地址和 IP 地址,物理卡可以根据 MAC 地址将流量分到不同的虚拟卡中;
- 大部分的 NIC 都支持编程 Packet classification filtering,让硬件来将不同的流量分到不同的 queue;
其他部分
测试
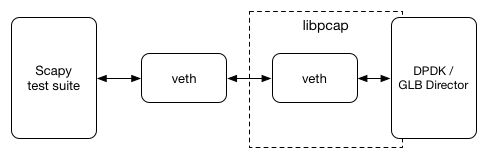
使用 DPDK 的 Environment Abstraction Layer (EAL) ,可以让基于 libpcap 的 interface 像物理卡一样,不需要专用物理网卡就可以做端到端测试,配合 Linux 的 Virtual Device 功能和 Python 的 Scapy 编程库,在任意 Linux 系统上就可以跑测试,VM 都可以。
健康检查
在 GLB 实例上运行健康检查程序,从实际的 tunnel 去检查后端的端口,如果认为不健康,就直接交换主 RS 和备 RS。这样新连接会去好的 RS,旧连接可以尝试不健康的 RS,最大努力保持连接。如果健康检查失败是 False Positive 也不要紧,只是影响包的转发路径而已。
RS 上的二次转发
基于 Netfilter 和 IPtables 实现:如果是 SYN 或者连接在本地存在,就接受,否则就转发到 备 RS。
参考资料:
- Introducing the GitHub Load Balancer (2016)
- GLB: GitHub’s open source load balancer (2018)
- 项目主页:https://github.com/github/glb-director
- GLB Director Hashing: Generating the GLB Forwarding Table
- GUE Header usage in GLB
- Example Setup with Vagrant
Typo: 后段 -> 后端
感谢,已改正。
现在业界把负载看成一个有状态的服务啊,还是无状态的服务啊,负载有必要关注连接的syn,established,timewat这些状态吗
可以理解为无状态的,有必要关注。
如果把负载当成无状态的,那为什么还要关注链接的状态呢
取决于实现,之前博客介绍的 Unimog 是不关注状态的。