Hot Potato Routing——烫手的山芋。指的是 ISP 在路由转发的时候,不会选择最优的路线,而是会选择最快能把这个包转出自己的自治域的路线。
如下图的路由中,假设有 3 个 ISP,分别控制 3 个自治系统AS(Autonomous System)。如果有一个包要从 A 转发到 X,那么在 AS1 中,A 路由器将会把包转发给 B,B 如果采用 Hot Potato Routing,将会直接把包转发给 D,完整的路线是 B-D-G-F-X,图中蓝色线路所示。而实际上最短的路径应该是 A-B-E-F-X(假设途中所有线路的 metric 相等,我们只看跳数)。
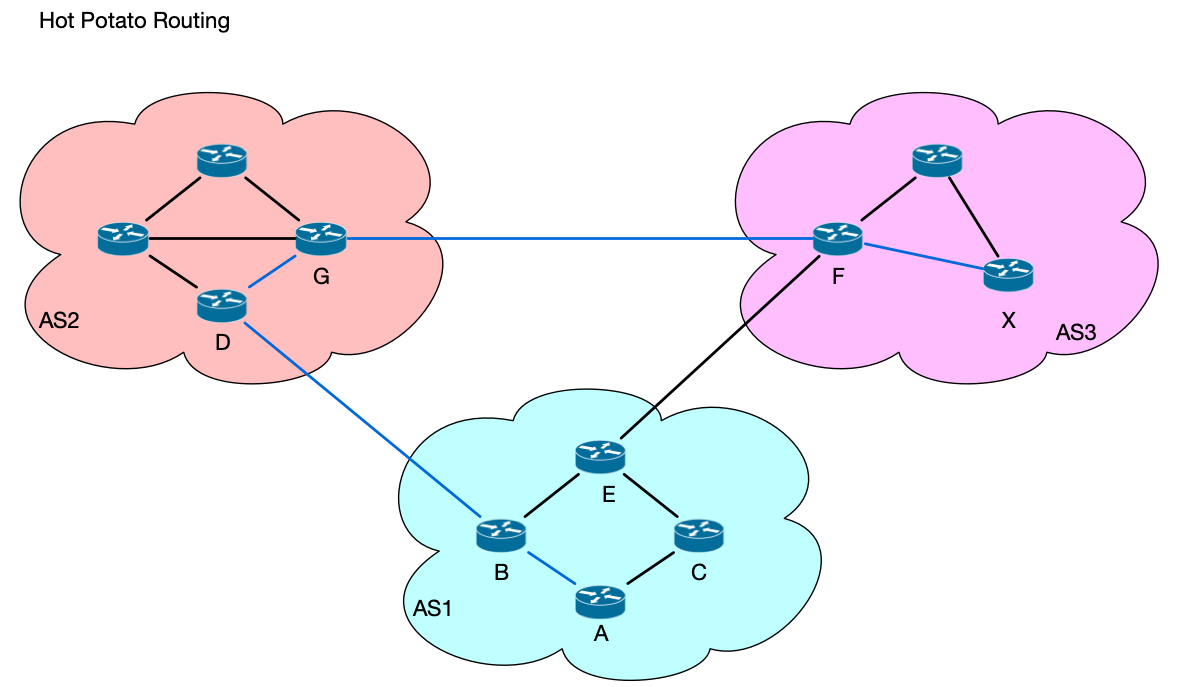
B 路由器之所以这样做,是因为在运营商的网络里,质量是第二要考虑的内容,Policy 才是第一要考虑的。路由器 B 已经知道全局最优路线是 E,但是如果选择全局最优路线,那么就需要经过 AS1 的另一台路由器 E,即 B-E 要转发这个包,但是如果直接丢给 D,E 就不用做转发了,这样,AS1 的工作就最少。
维基百科中说,Hot Potato Routing 是大部分运营商的路由策略。Hot-potato routing (or “closest exit routing”) is the normal behavior generally employed by most ISPs.
每个人都在用最自私的策略来降低自己的工作量,但是却让全局的工作量增加了,自己的工作量实际上也是增加了的,整体的服务质量却降低了——用户的请求需要绕得更远才能到达目标。
这不就是很多大公司的工作方式吗?
大公司给每个人规定了 KPI(就不提 OKR 了,OKR 在大部分公司的实践其实就是 KPI)。收到新的任务,每个人做的最优选择就是把和 KPI 不相关的工作「转发」出去。
刚加入蚂蚁金服的时候,带我的师兄让我找 A 同事要一个测试环境,来熟悉我要接手的业务。于是我去找 A,A 让我找 B,B 让我找 C——一直找了 6 个人,给我一点小小的震撼,我上家公司技术人员才不过 20 人,现在入职 1 天就认识了 6 个人,不愧是大公司。最神奇的是,最后一个人也没给我答案,而是让我找第一个人 A,居然出现环路了。
在蚂蚁的时光,有一半是在「闭关室」度过的。「闭关」也是一个我第一次经历、现在想想很可笑的事情。「闭关」就是一个团队不在原来的工位办公了,大家都搬到一个会议室里面工作,会议室预定几个月。美名为「项目攻关」。别人过来问问题,提需求,我们都可以说「我们在闭关,需要专心做我们的项目。」但是我们的工作也会遇到问题,需要其他的团队配合,于是我们去找其他团队合作,其他团队也是「不好意思,我们在闭关。」最后就成了你也在闭关,他也在闭关,大家都在闭关。
我觉得最理想的工作方式是像 DNS Recursive Resolver 一样。有人来问我问题,我应该给他解答。如果我不知道答案,那么我应该去问知道答案的人,得到答案告诉原来的提问者,这样一来我也知道了答案,下次如果有人来问,我就可以直接回答了,就像 DNS Recursive Resolver 的缓存一样。如果比较忙,我没有时间去问下一个人,应该拉一个群,加上提问者和能解决问题的人,由我来解释一下问题和背景。因为我经过和提问者的沟通,多少理解需求和背景了,很多提问者无法一次性把我们需要的背景解释清楚,我现在如果在群里一次性说明背景,就可以减少提问者和其他人的沟通成本。如果每个人都这么做的话,那么所有的问题都可以用最快的方式解决,整体花费的工作量就可以变小。
但是实际是行不通的,因为公司给每个人都安排好了 KPI。这些事情不在 KPI 里面,做这些工作实际上是不被绩效系统承认的,每个人要专注于完成自己的 KPI。更糟糕的是,如果做一个糟糕的「转发者」,一问三不知只会转发,那么收到的请求就越来越少,别人知道,问你不会得到答案,下次就不会问了。相反,如果这次别人问你得到了满意的答案,那么下次他还会来问你,每次都会来问你,收到的问题会越来越多,提问者甚至会变成「转发者」,他知道你能回答某些方面的问题,那么别人来问他的时候,他会立即转发给你。
也许 Hot Potato Routing 才是在大公司的生存之道,只有在小而美的公司才能做到用不自私的工作方式来工作。当初那些有理想的前同事,现在几乎都已经离职了(当然,没有离职的也有有理想的)。
哈哈,可以感受到这篇短短的文章后面是多少血和泪!大公司还是小公司,自私自利还是为他人为集体着想,做容易的事还是正确的事,只能说“懂的都懂”了。别对自己太苛刻就好。
“有人来问我问题,我应该给他解答。如果我不知道答案,那么我应该去问知道答案的人,得到答案告诉原来的提问者,这样一来我也知道了答案,下次如果有人来问,我就可以直接回答了,就像 DNS Recursive Resolver 的缓存一样。”
这个流程很像并查集中的路径压缩
> 如果这次别人问你得到了满意的答案,那么下次他还会来问你,每次都会来问你,收到的问题会越来越多
解答问题可以拆分为理解问题和获取回答两个阶段,以及执行从问题转化而来的任务。现在已经有公司在实验用 LLM 模型来理解问题,但对于跨服务边界的问题通常还是需要有人来协调。在某些公司就是由 SRE 来承担这个角色。
而在获取回答阶段,如果需求很明确且问题没有横跨服务边界,我会建议提问人直接去找能解决问题的人(服务 owner),并且最好是以经验能够共享、传承的方式,即不涉及敏感信息的情况下,直接使用公开群或者对话能作为语料/参考复用的 help desk。
> 我觉得最理想的工作方式是像 DNS Recursive Resolver 一样。
以目前技术发展的方向看,我觉得最理想的方式是使用 AI 对话来拆解需求,将 FAQ 提供给 AI 来回答常见问题,这些解决不了的再人工处理。理想的情况应当降低整体的工作量、且在流程上的效率提升能有大范围的收益(例如 LLM 模型的迭代、跨服务边界问题和需求的拆分与总结),而不是工作量改如何在人之间转移。
能称之为最理想的前提是 AI 不具备与人类等同的智能和道德地位,不过估计技术发展还不会那么快,哈哈。
最大的难度是 AI 的内容不能一定正确和有用吧。
阿里是雇佣了很多外包员工来做某框架 L1 客服,如果解决不了问题,至少可以将 L1 总结的信息转给 L2(框架开发人员),这样 L2 就可以直接获得准确的背景信息了。
或许有一天 AI 可以代替 L1.
深有感触,甚至用户来问问题,也是在帖子里做@接力。。
D不会把到X的路由指到B吗?互相推诿,会不会成成环了?
实际上应该会根据 ISP 之间的协议有 Policy-Based Forwarding 吧。