数据中心的网络和家用网络有很大不同,家用网络一个小路由器就够了,挂了的话,就忍受一下没有网络的时间,然后去网上下单再买一个换上。数据中心可不行,所有的东西都要设计成高可用的。
这篇文章来讲讲在数据中心网络用到的技术,主要是和高可用相关的。
本文谈到的网络,重点是3层及以下。因为 4 层是端对端的,如今主要是在服务端软件进行高可用设计,我们在四层负载均衡漫谈里讨论了这些技术并且分析了很多案例。
意义和必要性
高可用指的是,任何一个组件坏了,都不影响其他的服务。比如说,服务器的电源坏了,还要能继续提供服务。怎么做到呢?再加一个电源。高可用的本质就是加机器(冗余硬件),笑。
现在的软件都是高可用设计了,无状态的可以随意扩展,有状态的比如 Etcd 可以部署多个实例,实例之间自己选举,自动 Failover,是不是对机器的可用性要求就低了?
假设一台服务器运行1年不出问题的概率是 99%,那么如果部署一万台服务器的话,1年之内就会有 1% * 10000 = 100 台会出现问题。如果部署的足够多,那么小概率发生的事情在绝对数量上就不会小。如果机器的可用性不够高,那么即使像 Etcd 3 副本部署,同时有 2 台出现故障的概率也会变大。而且,同一个批次的硬件很可能在大约同一时间出现故障,我就见过多次 RAID 里同时坏两块盘的情况。
高可用设计对维护操作也很友好。为了不剧透网络部分好玩的内容,我们还是拿电源举例。现在的服务器大部分是 Dual PSU (Dual Power supply unit,双电源)设计,支持热插拔。如果一个电源坏了,另一个直接继续提供服务,技术人员可以拔掉坏的,换上新的,不需要停机时间。否则的话就麻烦了,需要联系机器负责人,机器负责人联系上面运行的进程负责人,大家开始迁移服务,然后才能操作。
像双电源的设计还可以缩小故障影响范围,比如两个电源单位,分别去连接两条电线。假设一个强电线路挂了,就和电源单位挂了一样,另一个电源直接上岗。如果没有的话,可能大批的服务器就下线了。
说到底,最重要的是交付的服务质量。对于数据中心来说,交付的服务就是机器,提高服务质量就是最大程度提高机器的可用性。向客户提供服务的时候,尽最大努力提高服务的质量;使用别人的服务的时候,要假设别人的服务可能挂掉。所以 PaaS 平台使用这些机器,要假设机器会挂,使用其他技术手段提高 PaaS 的可用性,提供给别人用;SaaS 使用 PaaS 的时候,也假设 PaaS 也可能会挂,通过技术提高自己软件服务的可用性。
所以在数据中心中,机器都尽可能设计成了高可用的:硬盘用 RAID 做容器,电源做冗余,网络做冗余。这个博客使用的虚拟机,已经 1117 天没有关机了,可用性非常高。

这个系列文章就来谈谈网络是怎么实现高可用的。比如,从服务器到交换机的链路如何做到高可用,从交换机到交换机,从服务器到网关路由器,等等。
明确一下网络高可用的目标。服务器最终的目标是提供服务,服务通过应用层网络协议提供出去:HTTP,webRTC 等等。这些协议都是基于 TCP 或者 UDP,由于四层的高可用技术主要是四层负载均衡解决了,四层负载均衡一般使用的是商用服务器,在这些服务器前面的网络设备主要工作在二层和三层,对于这些设备来说,四层网络就是这些设备要传输的数据。这些设备要做的就是:确保四层数据的传输是高可用的,或者说,尽量在三层 IP 协议上保证可用性,这也是 IP 协议的设计:Best effort.
最后我们这样总结一下这些技术的最终目标:在服务器上 ping 一个互联网 IP,中间的硬件无论哪一个挂了,高可用的网络设计都要保证能够继续 ping 的通(中间可能会有短暂的丢包)。
基础知识回顾
在讨论这些好玩的技术之前,我们先重新认识一下机房中的设备,和这些设备的工作方式。和网络相关的,主要就是服务器、交换机、和路由器了。
服务器
服务器是最常见的终端设备了,也是开发者最熟悉的设备。它没有网络的转发功能,是其他网络设备的主要用户。
在讨论服务器的时候,我们要从两个方面分开讨论:
- 发出流量,又叫 Transmit, outbound;
- 接收流量,又叫 Receive, inbound;
流量都是通过网络单元的形式发送出去的,在三层叫做包,二层叫做帧。服务器拿 Linux 来距离,在发送数据的时候,无论是 TCP 还是 UDP,都是先封装成三层数据包,再封装成二层数据帧,最后通过物理层让网卡发送数据。不是所有的数据都是基于三层协议发送的,但是数据一定是通过二层协议发送出去的,因为二层是连接物理层的电信号和数字信号的地方。数据中心的二层协议一般就是 Ethernet 了。
数据封装成三层包很简单,因为应用发送数据的时候已经指定了 IP 地址,kernel 根据这些信息封装添加 I P header 就完成了。
封装成二层也很简单,主要是添加二层 Header 和计算 CRC。Header 中最重要的是放上自己的 MAC 地址和目标的 MAC 地址。怎么知道目标 MAC 地址应该写啥呢?首先根据要发送的目标 IP 和自己的子网判断目标 IP 是否和自己在同一个子网,如果在同一个子网,那么目标 MAC 地址就写目标 IP 的 MAC 地址;如果不在同一个子网,就写默认网关 (default gateway) 的 MAC 地址。那又怎么知道目标 IP 或者默认网关的 MAC 地址是什么呢?机器本地是没有办法知道的,所以要通过网络协议询问,即 ARP 协议。
想知道一个 IP 对应的 MAC 地址,就设置一个问题,问「谁有 IP xxx 的 MAC 地址?如果知道,请回复给 IP yyy,yyy 的 MAC 地址是 B。」前面提到 ARP 也是基于二层的,我们就得把这个问题封装到二层中,来源 MAC 就是自己的 MAC,B,目标 MAC 地址是 FF:FF:FF:FF:FF:FF,即广播给所有的人。这时候所有人会收到这个 ARP 问题,但是只有 IP 是 xxx 的会回复,告知其 MAC 地址。其他人虽然不回复,但是也会收到这个 ARP 问题,通过这个 ARP 问题,所有的人都知道了:「哦,虽然不需要我回答,但是我也获得了 yyy 的 MAC 地址,我先记下来,说不定以后用得到呢。」
通过 ARP 协议拿到了 MAC 地址,就可以完成二层的封装了,最后通过物理层发送出去。ARP 协议的目的就是找到 IP 和 MAC 地址的对应,这个记录会在机器上缓存一段时间,减少 ARP 查询量,也能减少 ARP 带来的延迟。
接收流量的行为很简单,网卡从物理层收到网络数据,解析成二层数据帧,判断目标 MAC 地址是否是发给我的,如果不是就丢弃,如果是,就把数据交给 kernel。如果是广播报,就根据协议判断是否需要回复,如上面提到的 ARP。
交换机
交换机和路由器都是流量转发设备,对它们来说,流量就没有发出和接收的区别了,它们的工作都是将收到的网络包转发出去。交换机工作在二层,路由器工作在三层。
交换机的转发逻辑很简单,它只看二层的 header 来完成转发。交换机有一个 MAC address table,是 MAC 地址和交换机端口的对应,交换机启动的时候 MAC address table 是空的,也不需要配置和导入数据,交换机可以自己「学习」。收到一个二层数据帧,交换机做的事情如下:
- 把来源 MAC 地址和来源端口号记录到 MAC address table 中,这就是交换机的「学习」过程,它从每一个收到的包进行学习;
- 根据目标 MAC 查找自己的 MAC address table;
- 如果找到目标 MAC 对应的端口号,就从这个端口把数据转发出去;
- 如果找不到,就转发到除了来源端口之外的其他端口(参考上文服务器收到帧的操作,如果不是发给自己的,会丢弃);
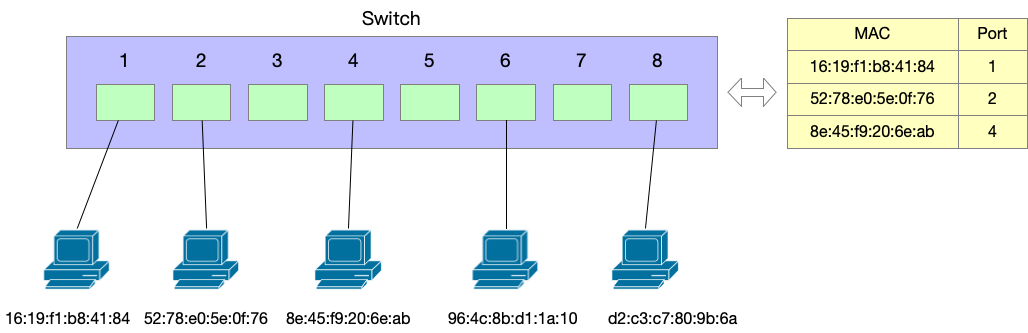
MAC 地址表中,一个 MAC 地址只能对应唯一一个端口,不能对应多个端口。即,表示这个 MAC 转发到这个端口;但是一个端口可以对应多个 MAC 地址,或者说,多个 MAC 地址可以对应到同一个端口,因为一个端口后面不仅仅可以是服务器,也可以是交换机。
路由器
路由器工作在三层,但是三层必须要依靠二层承载才能工作,所以路由器里面也有一个二层实现。在每次收发数据包的时候,它的工作方式是和服务器一样的,都是通过 ARP 询问 MAC 地址,然后把要发送的三层包添加二层 header(主要是 MAC 地址),发送出去。对于交换机的视角来说,路由器和服务器一样,都是它的「客户」。
在转发数据包的时候,路由器每次拿到一个 IP 包,就检查自己的路由表,找到一个出口端口,然后从这个端口发送出去。
它和交换机一样,主要的工作是「转发」,只不过交换机参考的是 MAC 与端口的对应表,路由器参考的是 IP 与端口的对应表。
路由表怎么来呢?路由器有两个「面」:控制面和数据面。控制面负责生成路由表,数据面负责将进来的包经过查找路由表转发出去。
路由表有两种方式生成,一种是静态的配置。其实 Linux 服务器也有一个路由表,通过 ip route 命令可以看,只不过里面的项目很少,最重要的是默认网关,默认网关一般使用静态配置。但是对于路由器来说,端口太多,只有一个默认网关是不够的,在数据中心中,基本上不使用静态配置的方式。
另一种就是动态协商,比如 EIGRP,BGP,OSPF 等等。简单来说,就是路由器之间互相交换自己能够连接到的子网的信息,路由器根据这些信息生成路由表。
讲了这么多无聊的东西,我们终于可以开始讨论有趣的高可用方案了。不过无聊归无聊,后面用到的技术其实就是对这些基础行为的巧妙利用(或者说,滥用?)。所以复习一下还是有必要的。
下一篇文章,我们从分析如何让服务器到交换机的连接做到高可用开始讨论。
数据中心网络高可用技术系列
- 数据中心网络高可用技术:序
- 数据中心网络高可用技术之从服务器到交换机:active-backup
- 数据中心网络高可用技术之从服务器到交换机:balance-tlb 和 balance-alb
- 数据中心网络高可用技术之从服务器到交换机:链路聚合 (balance-xor, balance-rr, broadcast)
- 数据中心网络高可用技术之从服务器到交换机:802.3 ad
- 数据中心网络高可用技术之从交换机到交换机:MLAG, 堆叠技术
- 数据中心网络高可用技术之从服务器到网关:VRRP
- 数据中心网络高可用技术:ECMP
Pingback: 数据中心网络高可用技术之从服务器到交换机:active-backup | 卡瓦邦噶!
拿电源距离 -> 举例
最重要的交付的服务质量 -> 的是
> 在服务器上 ping 一个互联网 IP,中间的硬件无论哪一个挂了,高可用的网络设计都要保证不出现丢包。
按 best effort 的定义是不会做这个保证的。 https://en.wikipedia.org/wiki/Best-effort_delivery
考虑到实际情况,最终目标并不是保证完全不出现(这也不现实),而是 best effort 并保障 QoS 下的 fairness。
嗯,这部分描述不对,我改一下。
发出流量,又叫 Transmit, outboond;
————
outboond -> outbound
谢谢,已改正。
Pingback: 数据中心网络高可用技术之从服务器到网关:VRRP | 卡瓦邦噶!