数据中心里面是一个个的机架(Rack),机架里面放着服务器,怎么把这些服务器连接起来呢?如果是 ToR (Top of Rack)的架构,就是在每一个机架上放一个机架交换机,这个机架的所有机器都连接顶部的交换机,然后再用聚合交换机把机架顶部的交换机连接起来。
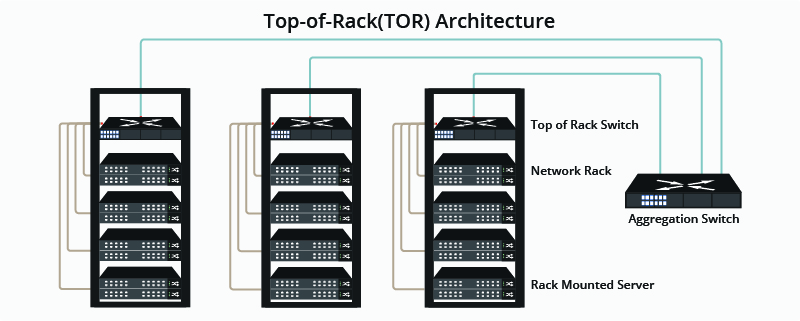
服务器和交换机是怎么连接的呢?最简单的方式是,服务器上有一个网卡,用网线把服务器和交换机连接起来。但这样做的话,我们就有了很多「单点」:网卡,网线,和交换机。高可用设计的目标就是排除掉单点,方法是添加冗余。

于是我们在服务器上再插上一根网卡,然后我们再用一根线连接服务器和交换机。
现在在服务器上,我们就有了两个物理卡,对应地,我们在操作系统上可以看到两个 interface。
|
1 2 3 4 5 6 7 |
root@ubuntu-5:/$ ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 157: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UNKNOWN mode DEFAULT group default qlen 1000 link/ether a6:99:c3:0d:14:93 brd ff:ff:ff:ff:ff:ff 158: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 82:e2:5d:48:67:fc brd ff:ff:ff:ff:ff:ff |
我们怎么配置这两个网卡呢?
首先,假设我们给两个 interface 分别配置一个 IP 地址,这样的话,在交换机和其他设备看来,这个服务器其实是两个机器,因为它是两个不同的 IP,已经失去了高可用的意义了。因为软件是需要基于 IP 来部署和交互的,拿 Etcd 来讲,假设我们部署 Etcd 在这个机器上,它就只能 listen 其中的一个 IP。如果部署两个实例分别 listen 一个 IP,那在其他实例看起来,好像是有两个不同的实例,但其实是部署在一个物理机上,这样,反而降低了可用性。因为物理机一挂就会导致两个 Etcd 实例一起失败。综上,我们要让服务器对外看起来还是一个 IP 才行。
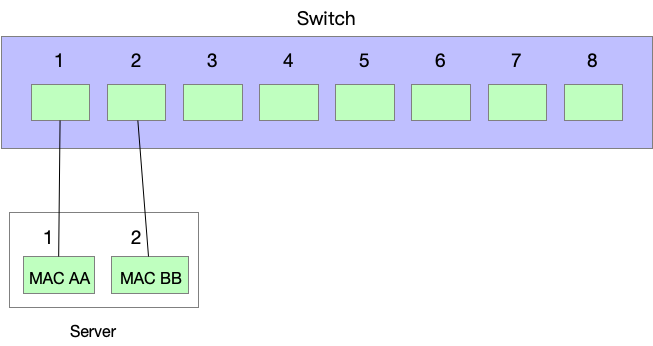
我们在考虑:假设给这两个网卡配置成一样的 MAC 地址行不行?这样,对外看起来只有一个 IP 和一个 MAC 地址,发送数据的时候可以用两条线,接收数据的时候,无论哪一条线收到都可以。看起来完美,但是忽略了一个重要的角色——交换机。
还记得交换机是怎么工作的吗?它从每一个收到的包学习 MAC 地址。两条线接到交换机上,对于交换机来说,这就是两个客户端。假设这两个网卡(客户端)的 MAC 地址一样,都是 MAC AA,那么当网卡 A 从交换机端口 1 发送数据出去的时候,交换机学习到:「MAC AA 对应端口1,发往 MAC AA 的数据都转发给端口 1」;但是当网卡 B 从端口 2 发送出去的时候,来源 MAC 地址也是 AA,交换机就学习到:「OK,现在 MAC AA 是在端口 2 了,让我修改我的 MAC 地址表,之后如果发给 MAC AA 我就往端口 B转发就好了」。过了一会,交换机的端口 1 又收到了 MAC AA 发来的数据,交换机迷惑了——「怎么这个 MAC AA 一会插在端口 1 上,一会插在端口 2 上,切换如此频繁,到底是谁的手速这么快?」。
这就是 MAC flapping 问题,指的就是同一个 MAC 地址在不同的交换机端口之间来回切换。
它的坏处有几个:
- 显而易见它会给交换机带来困扰,交换机来回修改 MAC 地址表,性能会下降;
- 对目标地址为 MAC AA 的,交换机会时而发给端口 1,时而发给端口 2,可能会造成同一个 TCP 连接的乱序问题,从而造成性能下降。
综上,我们不能对两个网卡使用相同的 MAC 地址。
但是我们可以把两张卡配置成一样的 MAC 地址,却不同时使用呀。
最简单的方案是:我们总是使用一张物理卡,当这个网卡不可用的时候,我们转而无缝切换到另一张网卡。这就是 Linux bonding 的 active-backup 模式。
配置 bonding active-backup 模式(mode 1)
从命令行配置 bonding 模式非常直观,大体的步骤是,把要配置的网卡先 down 掉,然后创建一个 bond 模式的 interface,将物理网卡设置为 bond 的 slave,最后把 bond 设置为 up,完事。(不需要手动设置物理网卡为 up,会自动 up。)
命令如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
root@ubuntu-5:/$ip link add bond0 type bond mode active-backup root@ubuntu-5:/$ip link set eth0 down root@ubuntu-5:/$ip link set eth1 down root@ubuntu-5:/$ip link set eth0 master bond0 root@ubuntu-5:/$ip link set eth1 master bond0 root@ubuntu-5:/$ip link set bond0 up root@ubuntu-5:/$ip add add 192.168.1.10/24 dev bond0 root@ubuntu-5:/$ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 5e:ee:0b:8e:e2:35 brd ff:ff:ff:ff:ff:ff 19: eth0: <BROADCAST,MULTICAST,SLAVE> mtu 1500 qdisc fq_codel master bond0 state DOWN mode DEFAULT group default qlen 1000 link/ether 5e:ee:0b:8e:e2:35 brd ff:ff:ff:ff:ff:ff 20: eth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bond0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 5e:ee:0b:8e:e2:35 brd ff:ff:ff:ff:ff:ff |
其中,ip link add bond0 type bond mode active-backup 命令又可以写成 ip link add bond0 type bond mode 0。每一个 bond mode 都有一个编号。(我们在接下来的文章中会循序渐进地介绍这些 mode)。
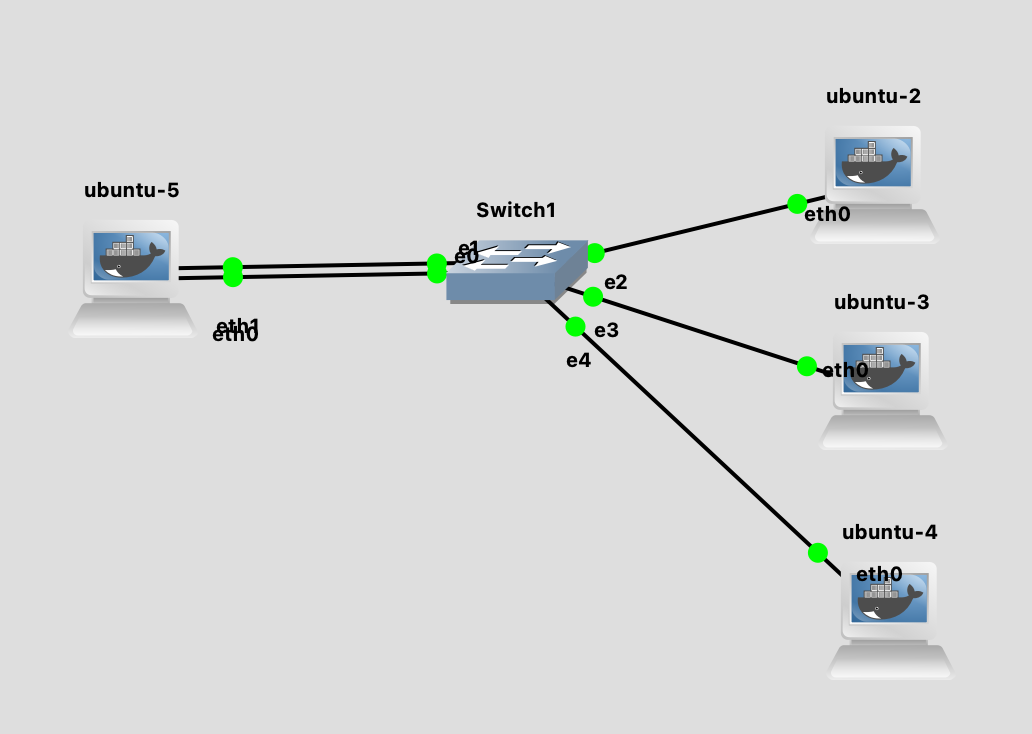
在这个拓扑图中,我们对 ubuntu-5 机器配置好了 bonding。使用 prof fs 的接口可以查看当前 bonding 的配置:
|
1 2 3 4 5 6 7 8 9 10 11 |
root@ubuntu-5:/$head /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v5.15.0-94-generic Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: eth0 MII Status: up MII Polling Interval (ms): 0 Up Delay (ms): 0 Down Delay (ms): 0 Peer Notification Delay (ms): 0 |
可见当前的 slave 是 eth0。
Failover 过程
我们已经配置好了 active-backup 模式,希望在主接口 down 之后,自动切换到 backup 接口。
但是现在的配置下,是不能自动切换的,因为 bond 不知道应该何时切换。高可用的部署中,我们加了冗余之后,还需要思考两个问题:
- 什么时候会触发切换;
- 以及如何切换。
Failover 触发
Failover 触发方案的本质是监控——要监控两条线路的状态,在一条线路 down 的时候,执行切换动作。主要的监控方式有两种:MII Monitoring 和 ARP Monitoring。
MII Monitoring
MII 的全称是 Media-independent interface,是 MAC 硬件层和传输媒介 PHY 硬件之间的接口。
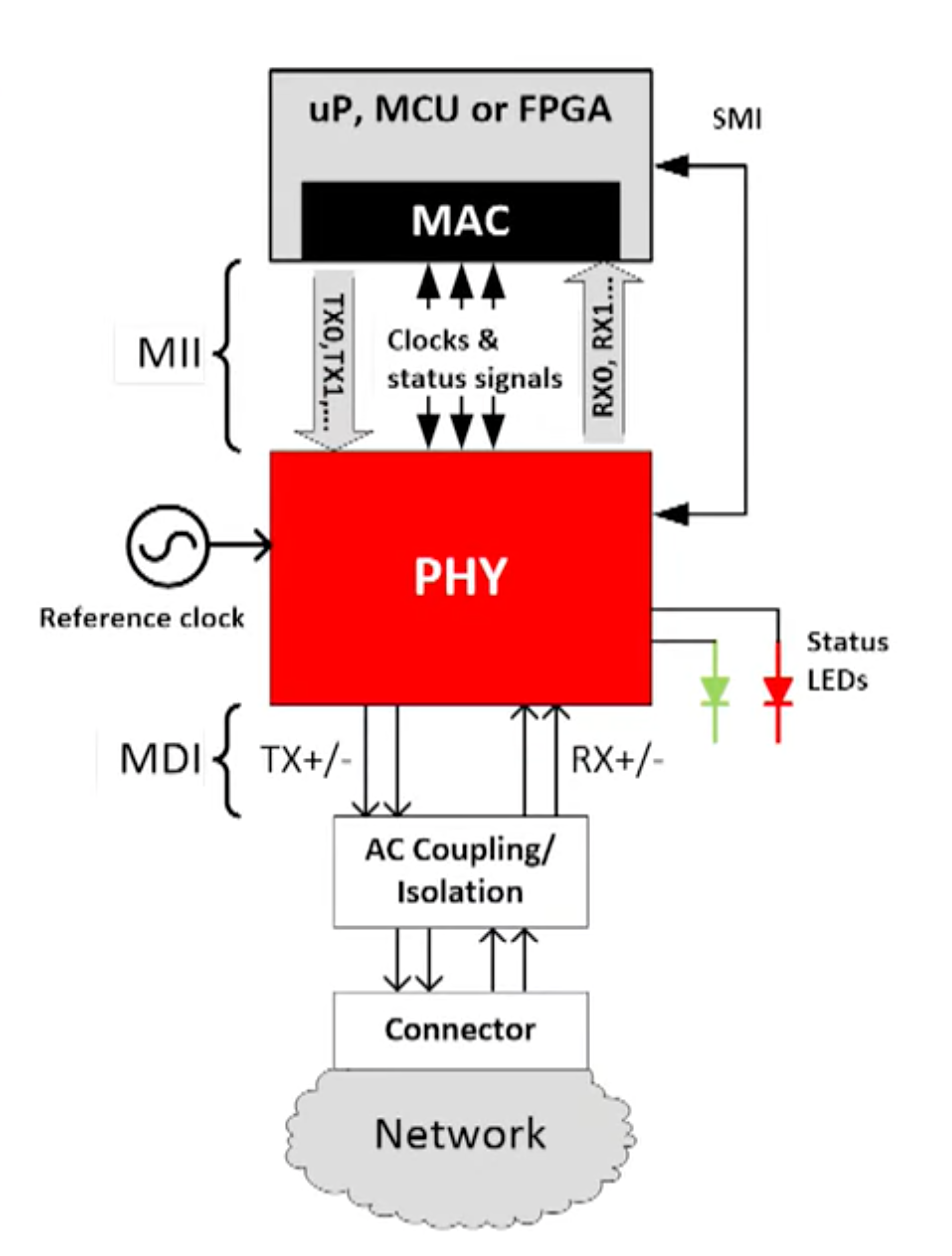
它是干什么的呢?还记得理解网络的分层模型中我们提到的「沙漏模型」吗?假设没有 MII,网卡中的 MAC 硬件直接连接物理媒介,那么每出现一种新的物理媒介,比如千兆以太网,万兆以太网,各种光纤,都要去适配所有的 MAC 硬件,是 M x N 的工作量。如果有 MII,MAC 硬件对接 MII,然后每出现一种新的媒介,只需要开发一次新的 MII 接口即可。
MII Monitoring 就是通过 MII 来检查物理物理网卡的状态。如果物理网卡挂了,通过 MII 就可以检测到。但是 MII 检查通过不能代表网络是通的。
(之前我有一个误解,我觉得 MII 只能检测网卡自身问题,无法检测像是网线不良,对端是否插线,对端设备挂了,对端设备端口挂了等问题,但是后来发现 PHY 芯片是可以检测到这些问题的,这里稍微展开一下。)
use_carrier 如果打开的话(默认就是 1, 打开的),就使用 netif_carrier_ok 来获取链路状态,底层依赖的是网卡驱动程序。大部分的网卡驱动程序都支持 netif_carrier_on/off 功能,如果不支持的话,那么链路检测永远是 up 的,即使挂了也不会触发 bonding 的切换。所以网卡如果不支持,就得把 use_carrier 改成 0。
use_carrier 能够检查出来更多的问题,原理是通过 PHY 芯片来检查以太网物理层上的电信号(载波检测、信号强度、波形和信噪比),在以太网线路上,即使线路是 idle 的,只要线路健康,也会有一些信号在线路上发送,这些信号就可以用来做健康检测。在一些高阶的以太网标准上,比如 IEEE 802.3 1000BASE-T,能够检测的故障更多。可以检测出对端交换机挂了,交换机的端口挂了等问题。
MII Monitoring 无法检测的问题是:交换机正常运行但是配置错误,或者通过了 Linux 网卡驱动的检测但是发送数据会有问题等等。
下面会演示 MII Monitoring 触发的切换。
MII Monitoring 下的 Failover 测试
我们在上面的配置中,并没有配置 miimon ,所以默认是关闭的。这里再配置下检测频率为 102ms.
|
1 |
root@ubuntu-5:/$ip link set bond0 type bond miimon 102 |
再看一下 bonding 状态,确认 miimon 已经生效,并且当前 active 端口是 eth0.
|
1 2 3 4 5 6 7 8 9 10 11 |
root@ubuntu-5:/$head /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v5.15.0-94-generic Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: eth0 MII Status: up MII Polling Interval (ms): 102 Up Delay (ms): 0 Down Delay (ms): 0 Peer Notification Delay (ms): 0 |
我们现在 ping 交换机另一端的一个主机,并且在 ping 的过程中手动 down 掉现在的 active eth0 端口。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
root@ubuntu-5:/$ip link set eth0 down root@ubuntu-5:/$head /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v5.15.0-94-generic Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: eth1 MII Status: up MII Polling Interval (ms): 102 Up Delay (ms): 0 Down Delay (ms): 0 Peer Notification Delay (ms): 0 |
ping 程序也显示,在切换的过程中一个包都没有丢。我们来分析一下这个切换过程。
Failover 过程分析
对于对端的主机来说,什么都没发生改变,因为这个 IP 对应的 MAC 地址没变,对端主机依然按照这个目标 IP 和 MAC 地址发送包过来。
出流量对于本机来说,切换也很简单,原先成 eth0 发送出去,现在从 eth1 发送出去即可。
入流量就麻烦了,我们的端口 down 了,交换机可不知道,入流量是交换机来决定从哪条线路发送过来的,所以流量还是会从端口 1 源源不断地进来。
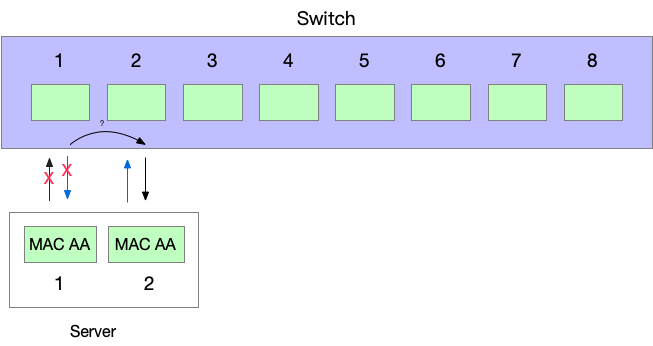
我们想要的是:让交换机现在通过端口 2 来发给我们流量,而不是端口 1.
如何做到呢?还记得交换机的工作方式吗?交换机从每一个收到的包学习 MAC 地址和端口的对应关系。利用这个,我们让交换机学习到,此时 MAC AA 对应的是端口 2,而不是端口 1。
即,我们使用 MAC AA 作为 Src MAC 从端口 2 发送点数据出去,交换机就知道了。
在 Failover 的时候用 tcpdump 来抓包,我们可以观察到在 backup 的端口发送出去的内容。
|
1 2 |
root@ubuntu-5:/$tcpdump -i eth1 -n -e arp 05:47:20.508717 5e:ee:0b:8e:e2:35 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.168.1.10 tell 192.168.1.10, length 28 |
哈,eth1 发送出去了一个 ARP 请求,它问:「谁有 192.168.1.10 的地址?请告诉 192.168.1.10。」可是这个 IP 明明是它自己呀。它这是明知故问,没有人会回复给他,它也不需要答案,发送这个 ARP 请求的目标是让交换机知道现在 MAC AA 对应端口 2。
从交换机的视角,就如同 MAC AA 原先插在端口 1 上,现在移动到了端口 2 上一样,交换机会立即把发往这个 MAC 地址的流量切换到端口 2.
这种 ARP 的用法叫做 Gratuitous ARP(不必要的ARP),有的时候是不要的 ARP 请求,有的时候是不必要的 ARP 响应(我们会在后面见到)。在 RFC 5227 中定义。
实验:交换机端口 down
我们继续用 MII Monitoring 的方式,来测试一下模拟交换机 down,看能否触发切换。
确认当前的 active 端口:
|
1 2 3 4 5 6 7 8 9 10 11 |
root@ubuntu-5:/$head /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v5.15.0-94-generic Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: eth0 MII Status: up MII Polling Interval (ms): 102 Up Delay (ms): 0 Down Delay (ms): 0 Peer Notification Delay (ms): 0 |
然后我们 ping 其中的一个主机,同时去交换机 down 掉 eth0 连接的端口。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
root@ubuntu-5:/$ping 192.168.1.12 PING 192.168.1.12 (192.168.1.12) 56(84) bytes of data. 64 bytes from 192.168.1.12: icmp_seq=1 ttl=64 time=0.939 ms 64 bytes from 192.168.1.12: icmp_seq=2 ttl=64 time=1.14 ms 64 bytes from 192.168.1.12: icmp_seq=3 ttl=64 time=5.58 ms 64 bytes from 192.168.1.12: icmp_seq=4 ttl=64 time=1.10 ms 64 bytes from 192.168.1.12: icmp_seq=5 ttl=64 time=0.892 ms From 192.168.1.10 icmp_seq=10 Destination Host Unreachable From 192.168.1.10 icmp_seq=11 Destination Host Unreachable From 192.168.1.10 icmp_seq=12 Destination Host Unreachable ^C --- 192.168.1.12 ping statistics --- 15 packets transmitted, 5 received, +3 errors, 66.6667% packet loss, time 14244ms rtt min/avg/max/mdev = 0.892/1.928/5.575/1.825 ms, pipe 4 |
可以看到现在无法完成切换,此时的 active interface 还是 eth0。因为 MII Monitoring 依然认为服务器的物理链路是好的(这个实验是在没有上文说的 use_carrier 功能下做的,所以 MII 无法检测对端的端口 down)。
|
1 2 3 4 5 6 7 8 9 10 11 |
root@ubuntu-5:/$head /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v5.15.0-94-generic Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: eth0 MII Status: up MII Polling Interval (ms): 102 Up Delay (ms): 0 Down Delay (ms): 0 Peer Notification Delay (ms): 0 |
ARP Monitoring
ARP Monitoring 的原理就是用 ARP 协议一直对某一个 IP 询问 MAC 地址,如果能够得到回复,说明网络没问题,如果得不到回复,就执行切换。
我们首先设置 miimon 为 0 来关闭 MII Monitoring,然后开启 ARP Monitoring,主要设置两个选项:ARP 检测的地址和检测的频率,这里使用 1s。
|
1 2 3 |
root@ubuntu-5:/$ip link set bond0 type bond miimon 0 root@ubuntu-5:/$ip link set bond0 type bond arp_interval 1000 root@ubuntu-5:/$ip link set bond0 type bond arp_ip_target 192.168.1.12 |
然后开始测试切换,查看现在 active 的端口是 eth1。
|
1 2 3 4 5 6 7 8 9 10 11 |
root@ubuntu-5:/$head /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v5.15.0-94-generic Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: eth1 MII Status: up MII Polling Interval (ms): 0 Up Delay (ms): 0 Down Delay (ms): 0 Peer Notification Delay (ms): 0 |
然后开始 ping,在 ping 的时候在交换机把 eth1 端口 down 掉。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
root@ubuntu-5:/$ping 192.168.1.12 PING 192.168.1.12 (192.168.1.12) 56(84) bytes of data. 64 bytes from 192.168.1.12: icmp_seq=1 ttl=64 time=1.69 ms 64 bytes from 192.168.1.12: icmp_seq=2 ttl=64 time=1.18 ms 64 bytes from 192.168.1.12: icmp_seq=3 ttl=64 time=1.06 ms 64 bytes from 192.168.1.12: icmp_seq=4 ttl=64 time=0.787 ms 64 bytes from 192.168.1.12: icmp_seq=5 ttl=64 time=1.38 ms 64 bytes from 192.168.1.12: icmp_seq=6 ttl=64 time=1.56 ms 64 bytes from 192.168.1.12: icmp_seq=7 ttl=64 time=0.686 ms 64 bytes from 192.168.1.12: icmp_seq=8 ttl=64 time=1.24 ms 64 bytes from 192.168.1.12: icmp_seq=9 ttl=64 time=1.40 ms 64 bytes from 192.168.1.12: icmp_seq=10 ttl=64 time=1.41 ms 64 bytes from 192.168.1.12: icmp_seq=14 ttl=64 time=0.997 ms 64 bytes from 192.168.1.12: icmp_seq=15 ttl=64 time=0.967 ms 64 bytes from 192.168.1.12: icmp_seq=16 ttl=64 time=1.12 ms 64 bytes from 192.168.1.12: icmp_seq=17 ttl=64 time=0.972 ms 64 bytes from 192.168.1.12: icmp_seq=18 ttl=64 time=1.22 ms ^C --- 192.168.1.12 ping statistics --- 18 packets transmitted, 15 received, 16.6667% packet loss, time 17117ms rtt min/avg/max/mdev = 0.686/1.177/1.689/0.269 ms |
可以看到第 11-13 个包丢了,一共丢了三个包。因为我们设置的频率是 1s,所以切换有些慢的。ARP Monitoring 比 MII Monitoring 能检测的网络范围更广泛。
ARP 也有问题,就是如果我们使用的 192.168.1.12 有问题,有时候回复 ARP 有时候不回复,就会导致端口来回 flapping。一个解决方法是,ARP Monitoring 支持多个 IP 检查目标,就可以避免 false alarm。
另一个坏处是会给网络带来额外的 ARP 流量。但现在网络都是万兆起步,这点流量可以忽略。
分析和总结
本文讨论了 Linux bonding 模式中的一种:active-backup。这个模式的特点是:
- 不需要交换机特殊配置,在交换机看来就是两个独立的端口;
- 由于交换机视角是独立的,所以我们可以把两根线接到两个不同的交换机上,可以实现多交换机的 Failover,避免交换机的单点故障;
- 一次只能利用一条线路,假设两条1G线路,总速率还是 1G,有一条线总是浪费的;
本质上这是个冷备方案,我们不喜欢冷备方案,因为它浪费资源。下一篇文章我们讨论如何将两条线路都利用起来。
数据中心网络高可用技术系列
- 数据中心网络高可用技术:序
- 数据中心网络高可用技术之从服务器到交换机:active-backup
- 数据中心网络高可用技术之从服务器到交换机:balance-tlb 和 balance-alb
- 数据中心网络高可用技术之从服务器到交换机:链路聚合 (balance-xor, balance-rr, broadcast)
- 数据中心网络高可用技术之从服务器到交换机:802.3 ad
- 数据中心网络高可用技术之从交换机到交换机:MLAG, 堆叠技术
- 数据中心网络高可用技术之从服务器到网关:VRRP
- 数据中心网络高可用技术:ECMP
mode 0 (balance-rr) 是不是既提供高性能(负载均衡)又提供极端情况下面的可用性?
那岂不是比 active-backup 更使用?
是的,balance-rr 是需要交换机支持链路聚合的,而这篇介绍的active-backup 可以和任何交换机工作。后面会介绍的。这篇是先介绍简单的。
不过机房用的交换机都是支持链路聚合的,要说链路聚合的话,mode4 802.3ad 是用的最多的。
“MII Monitoring 就是检测链路状态,只能检查物理链路的连通性,不能代表网络是通的。比如,交换机挂了,或交换机的端口挂了的情况下,服务器网卡没问题,就不会触发切换”
MII Monitoring是服务器内的吧,不对外发送包,交换机也感知不到,MII Monitoring只是网卡驱动程序对网卡的一种检测。
是的,只能检查网卡工作情况。
不好意思,这个地方貌似是我错了。我在原文中更新了,这一段:
> 之前我有一个误解,我觉得 MII 只能检测网卡自身问题,无法检测像是网线不良,对端是否插线,对端设备挂了,对端设备端口挂了等问题,但是后来发现 PHY 芯片是可以检测到这些问题的…
学习了,linux bonding 参数和 ovs 的不太一样
> bond-detect-mode, optional string, either carrier or miimon
请教一下,如果说MII可以检测到对端设备端口挂了,那么为什么后面的实验中关闭交换机的端口,没有能进行自动切换呢
按照文中说的,这个是要硬件支持才行的。我用的虚拟机所以不支持这个功能。
前面的实验中,关闭ubuntu-5的网卡是可以通过MII检测切换的,但是后面关闭物理交换机端口就不行,我理解虚拟机是支持的,虚拟系统里面是否有虚拟交换机,所以MII检测不到物理交换机的端口状态?
MII 是支持的,但是检测对端链路,要求网卡驱动支持 netif_carrier, 这个在虚拟机中是不支持的。
如文中所说:
大部分的网卡驱动程序都支持 netif_carrier_on/off 功能,如果不支持的话,那么链路检测永远是 up 的,即使挂了也不会触发 bonding 的切换。
明白了,谢谢
2.数据中心网络高可用技术之从服务器到交换机:active-backup
这个链接貌似没有链接成功,没法点击
感谢,已经改正
Pingback: 数据中心网络高可用技术之从服务器到交换机:balance-tlb 和 balance-alb | 卡瓦邦噶!
Pingback: 数据中心网络高可用技术之从服务器到交换机:链路聚合 (balance-xor, balance-rr, broadcast) | 卡瓦邦噶!
Pingback: 数据中心网络高可用技术之从服务器到网关:VRRP | 卡瓦邦噶!