到现在我们讨论了 3 种 Linux bonding 模式:active-backup, balance-tlb, balance-alb. 这些方案都不够完美,各有利弊。那么有没有完美的方案呢?前面讨论的方案都没有需要交换机支持特殊功能,假设我们可以在交换机上做一些事情,交换机可以如何配合服务器来做到完美的双线双活?
我们重新思考一下我们的需求:
- 我们有两条线,我们想充分利用两条线的带宽;
- 当有一条线挂的时候,就只用另一条线,自动切换。
将这个需求转换到对交换机的要求,那具体就是:
- 交换机将两条线路视为一条线路,即对于物理端口 1 和 2,在 MAC 地址表中,不再记录 MAC 地址 AA 对应的端口是 1 还是 2,而是记录为 虚拟1号端口,虚拟1号就是物理 1 和 2 的结合体,这样就没有 MAC flapping 的问题了。对于:
- 发送数据,交换机对于发往 MAC 地址 AA 的 Frame,可以自由选择从 1 还是 2 来发送,但是要保证一个数据流总是发送到一条线路,来尽量保证顺序。对于广播数据,也只需要广播给两个端口中的一个即可;
- 接收数据,无论从物理端口 1 还是 2 收到的数据,都视为从虚拟端口 1 收到的数据,如果修改 MAC 地址表,就将学习到的 Src MAC 地址记录为虚拟端口 1。如果从 1 或 2 收到广播数据,不需要再发给物理端口 1 或 2。
- 当其中一条线路 down 的时候,只从另一条好的线路发送数据;
实际上,交换机完全能做到这种事情,这个功能叫做链路聚合。简单,就是将两条线虚拟成一条线。
这里说个题外话,链路聚合技术,英文名字叫 Link Aggregation. 但是它还有很多其他的很多名字:
- Ethernet bonding
- Ethernet teaming
- Link bonding
- Link bundling
- Link teaming
- Network interface controller (NIC) bonding
- NIC teaming
- Port aggregation
- Port channeling
- Port trunking
- Eth-Trunk
- EtherChannel
不要被这些吓人的名字唬住了,其实说的都是上文链路聚合这点简单的东西……
其中,Trunking 一般是说交换机之间连接模式,用来让不同的交换机上的相同 Vlan 能够互通。不同厂商的设备都有自己的一套命名逻辑,这些名字要结合语境来理解,知道它们说的是什么。
为什么要起这么多有迷惑性的名字呢?简单来说就是为了卖设备。像笔者写的这么直白,怎么忽悠客户购买上万元的设备呢?EtherChannel,听着多牛逼。但是你 Cisco 起名叫 EtherChannel,我华为也叫这个名字未免就显得我抄了你的,我就叫个 Eth-Trunk,还用上个缩写,显得更牛逼。实际都是差不多的东西,咱可不能被忽悠瘸了。
公开的网络协议方面,命名是很统一的,但是涉及技术实现,就有很多高大上的名词和缩写了。
回到我们高可用的话题上,链路聚合具体做的事情就是将多个物理线路组合成一个逻辑线路,对于交换机系统,就如同只有一条带宽更高的线一样——虚拟线路的带宽是所有物理线路的总带宽。当某条线路挂掉,发送的流量可以自动切换到其他线路上。
链路聚合应用很广。我们的公司附近最近新盖了一个办公大楼,要部署网线,像这种工程,挖路布线,成本都在人工上,埋一根线和十根线成本差别不大。假设 5 年之后网络大发展,带宽不够用了,再挖开路面重新施工,成本就得再来一次。那就不如一开始埋上十根线,之后可以通过链路聚合来获得更多的带宽。
布线施工现场

有了这个技术,交换机能替我们办点事,服务器这边的事就好办多了。利用这个功能,我们再来看服务器这边如何做到高可用。
Balance-xor (mode 2)
链路聚合可以把多条线路「捆绑」在一起,对于同一个 flow,需要保持使用同一条线路来发送,如何选择线路呢?
链路聚合并没有规定线路选择算法(或者叫路由算法,负载均衡算法),原因是:
- 没有必要,即使运行链路聚合的服务器和交换机使用不同的算法,在数据的两个方向上都不会有问题;
- 如果要标准化,会花费很多精力去对这些算法标准化,来统一不同的厂商;
- 具体使用什么算法最好,通常取决于拓扑结构和流量特征;
- 不标准化算法可以留给厂商优化的空间(比如一些高端交换机支持动态负载均衡,根据线路使用率来调整);
所以:
- 链路聚合中的负载均衡算法并不作标准化,只对算法提需求;
- 需求就是对于同一个 flow 要始终选择同一个路线;
- 对于流量的接收,需要兼容所有算法。即作为链路聚合的接收端无论发送端使用什么样的算法来发送,都能正确处理收到的包,无论从哪一条物理线路收到流量,都如同在虚拟线路上收到一样。
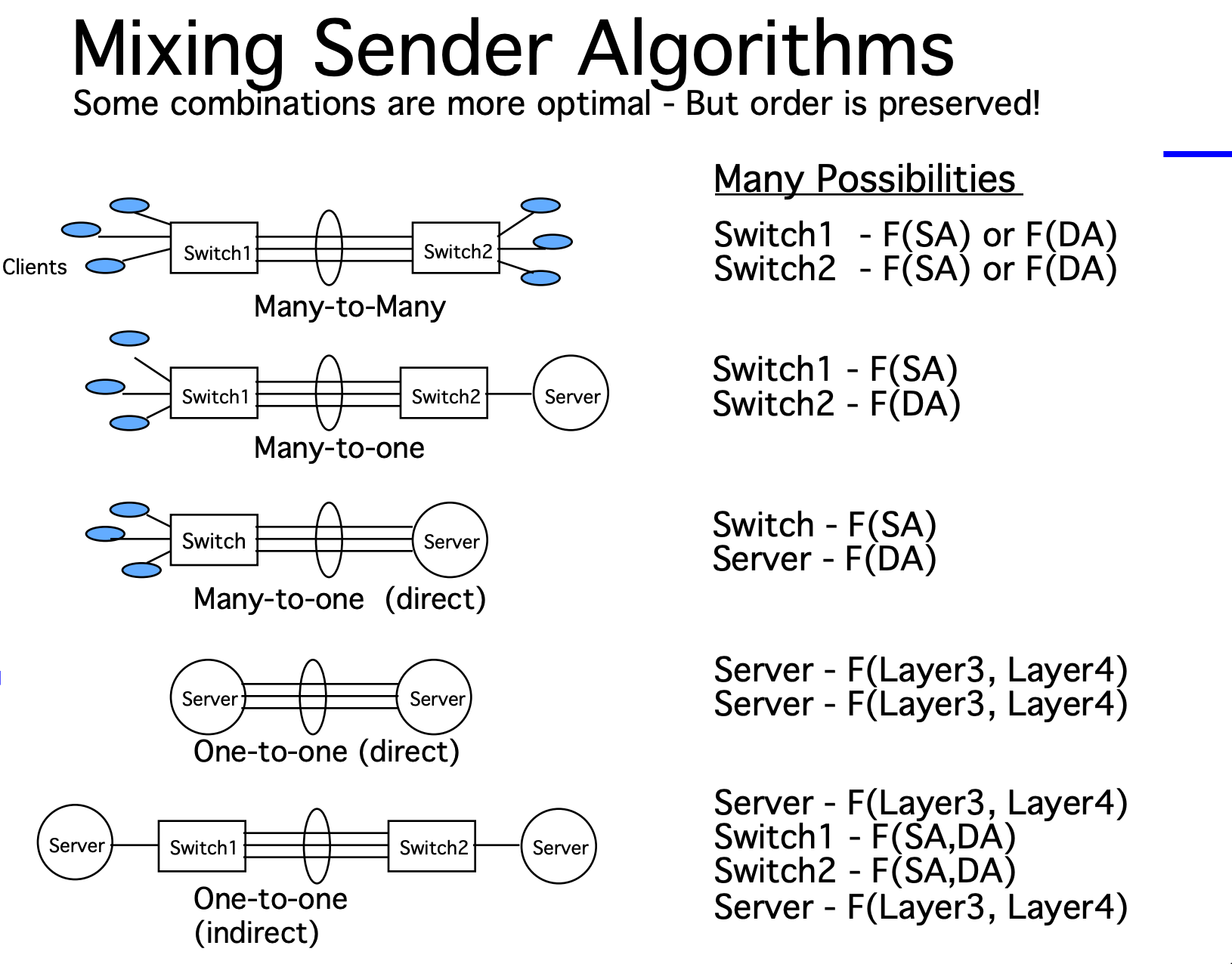
所以,发送端可以自己选择负载均衡算法。聚在均衡算法本质上就是根据包的 header 计算 hash,然后根据 hash 来决定走哪一条线。常用的 header 有:
- Source MAC Address (SA)
- Destination MAC Address (DA)
- Layer 3 (IP)
- Layer4 (Port)
balance-xor 模式就是在链路聚合的模式下,使用一种负载均衡算法来选路。默认的算法是:(src mac address XOR dest mac address XOR packet type ID) modulo slave account.
也支持使用 xmit_hash_policy 来选择其他算法。xmit_hash_policy 支持的算法有:
- layer2
- layer2+3
- layer3+4
- encap2+3
- encap3+4
配置实验
我们还是使用前面一直在用的拓扑图做实验。
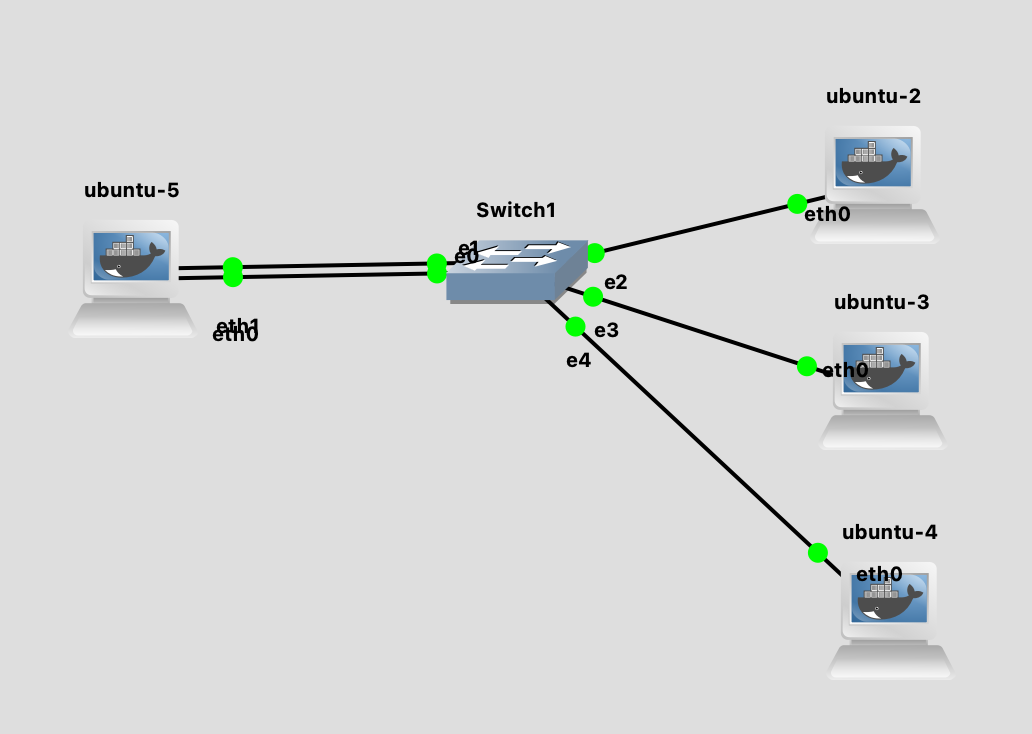
在 ubuntu-5 上,用如下的命令配置好 bonding:
|
1 2 3 4 5 6 7 |
ip link add bond0 type bond mode balance-xor ip link set eth0 down ip link set eth1 down ip link set eth0 master bond0 ip link set eth1 master bond0 ip link set bond0 up ip add add 192.168.1.10/24 dev bond0 |
查看 ip link ,发现这下 bond0 和两个 slave eth0, eth1 都是一样的 MAC 地址了:
|
1 2 3 4 5 6 7 8 9 |
root@ubuntu-5:/$ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 0a:56:27:5a:c9:13 brd ff:ff:ff:ff:ff:ff 67: eth0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bond0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 0a:56:27:5a:c9:13 brd ff:ff:ff:ff:ff:ff 68: eth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bond0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 0a:56:27:5a:c9:13 brd ff:ff:ff:ff:ff:ff |
在交换机上面将 Eth0/0 和 Eth0/1 配置成 Etherchannel 之后,再查看 MAC 地址表:
|
1 2 3 4 5 6 7 8 9 10 11 |
Switch#show mac address-table Mac Address Table ------------------------------------------- Vlan Mac Address Type Ports ---- ----------- -------- ----- 1 066f.f664.d647 DYNAMIC Et1/1 1 0a56.275a.c913 DYNAMIC Po22 1 96c8.0a3b.35c6 DYNAMIC Et1/2 1 ded9.7b23.5f19 DYNAMIC Et1/0 Total Mac Addresses for this criterion: 4 |
会发现 0a:56:27:5a:c9:13 这个 MAC 地址对应的既不是 Eth0/0 也不是 Eth0/1,而是 Port Channel 的虚拟接口 Po22。
执行一个 ping 命令,我们甚至可以看到 ping request 从 eth1 发出去,reply 从 eth0 收到的奇观。这是因为 Linux 和交换机使用了不同的负载均衡算法。这也是没问题的,只要 request 始终走一张卡,reply 始终走另一张卡,就可以看作是 flow 没有乱序。
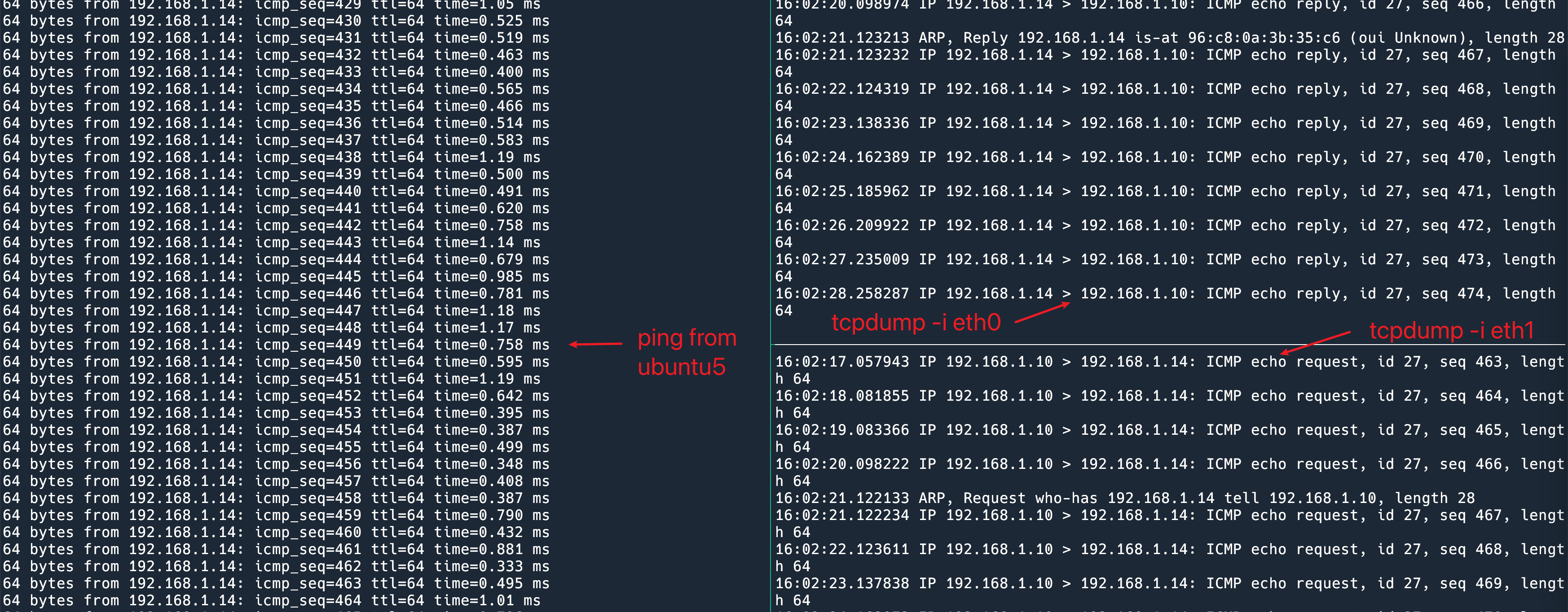
由于发送出去的选路是 Linux 和交换机双方自由决定的,所以故障切换就有一些难度。难点是双发各自不知道对方的状态。之前我们在 Linux 这边就可以完成切换,因为我们什么都不需要交换机来做。现在不行了,假设我们这边网卡挂了,交换机不知道,交换机还是会往这张卡发送,这些包就被丢弃了。
为了解决这个问题,在 Linux 侧,我们应该使用 ARP monitoring 而不是 MII monitoring,这样就可以检测整个链路的状态。在交换机侧也需要配置类似的检测切换机制。
还真是麻烦呢,先不说这些配置有多复杂,光是「是否应该切换」这个问题也无法检测准确,ARP monitoring 可能由于目标 IP 的问题导致误切换。
看来,我们距离完美方案还有一步之遥,下一期我们讨论更加智能的链路聚合。在开启下一期之前,我们再来讨论两个「神奇」的 bonding 模式。
Balance-rr (mode 0)
balance-rr 中 rr 的意思是 round robin,意思是轮询使用所有的 interface 来发送包。我把这个模式配置好,ping 一下,读者就了然了。
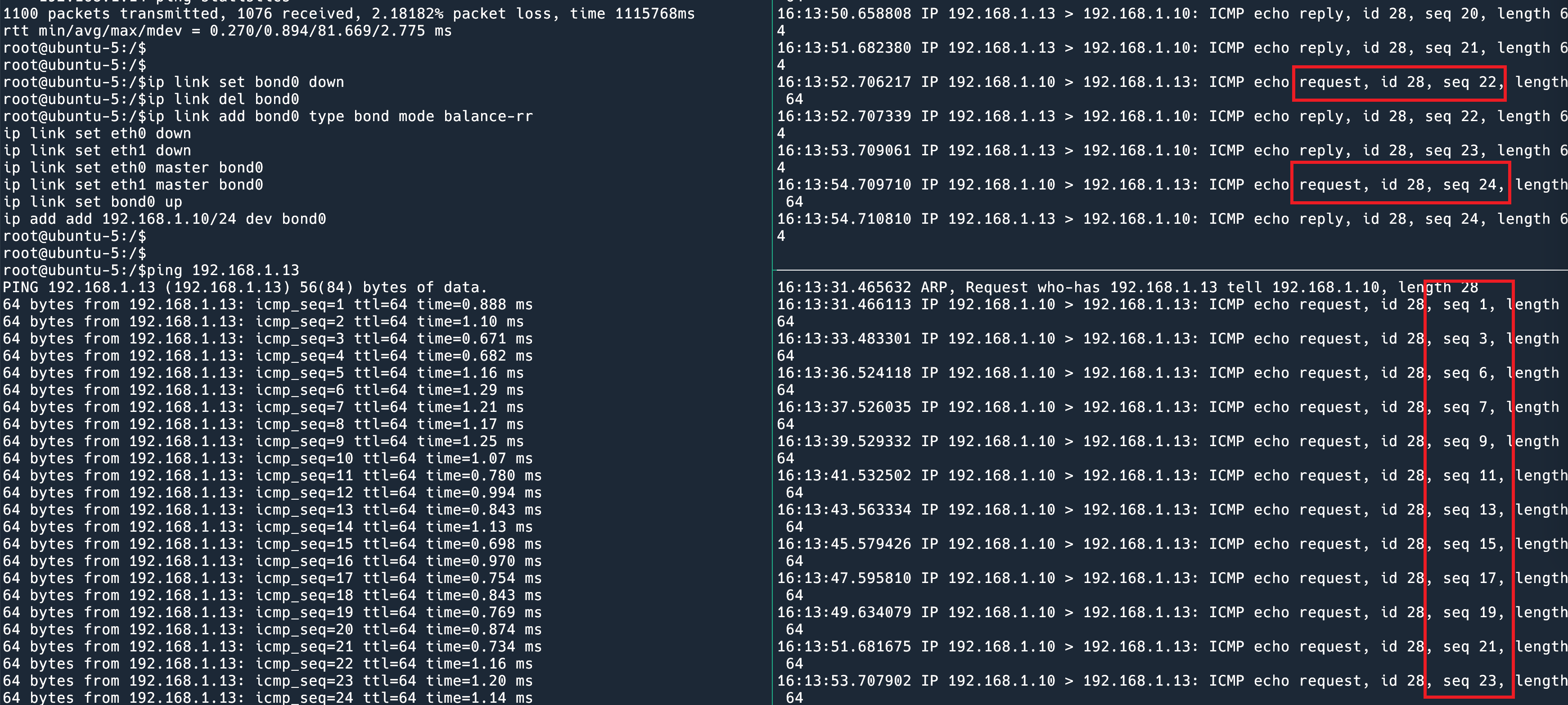
右边上下两个面板分别是两张网卡的 tcpdump. ping 的 reply 可以忽略,因为这是交换机决定的走哪条线。我们专注看 request。这个 request 可就有意思了,它一会从 eth0 发出去,一会从 eth1 发出去,而且是准确的一个包换一次。
这就是 balance-rr。balance-rr 是唯一一个对于同一个 flow 可以使用所有网卡的 bonding 模式。什么意思呢?假设服务器有两张 10G 网卡,做好 bonding,非 balance-rr 的情况下,由于同一个 flow (同一个 TCP 连接)会走同一张卡,一个 TCP 连接最大速率是 10G,假设建立很多 TCP 连接,也许可以用上 20G 的速率。而 balance-rr 可以让同一个 TCP 连接能够用上 20G 的速率。实际上这样会造成乱序,所以 TCP 的例子不是很恰当,派上用场的场景很有限,对于某些基于 UDP 的不关心 flow 顺序的协议可能会有用。
Broadcast (mode 3)
这个就更有意思了,顾名思义,这个模式就是把要发送的包复制到所有的 interface 发送。
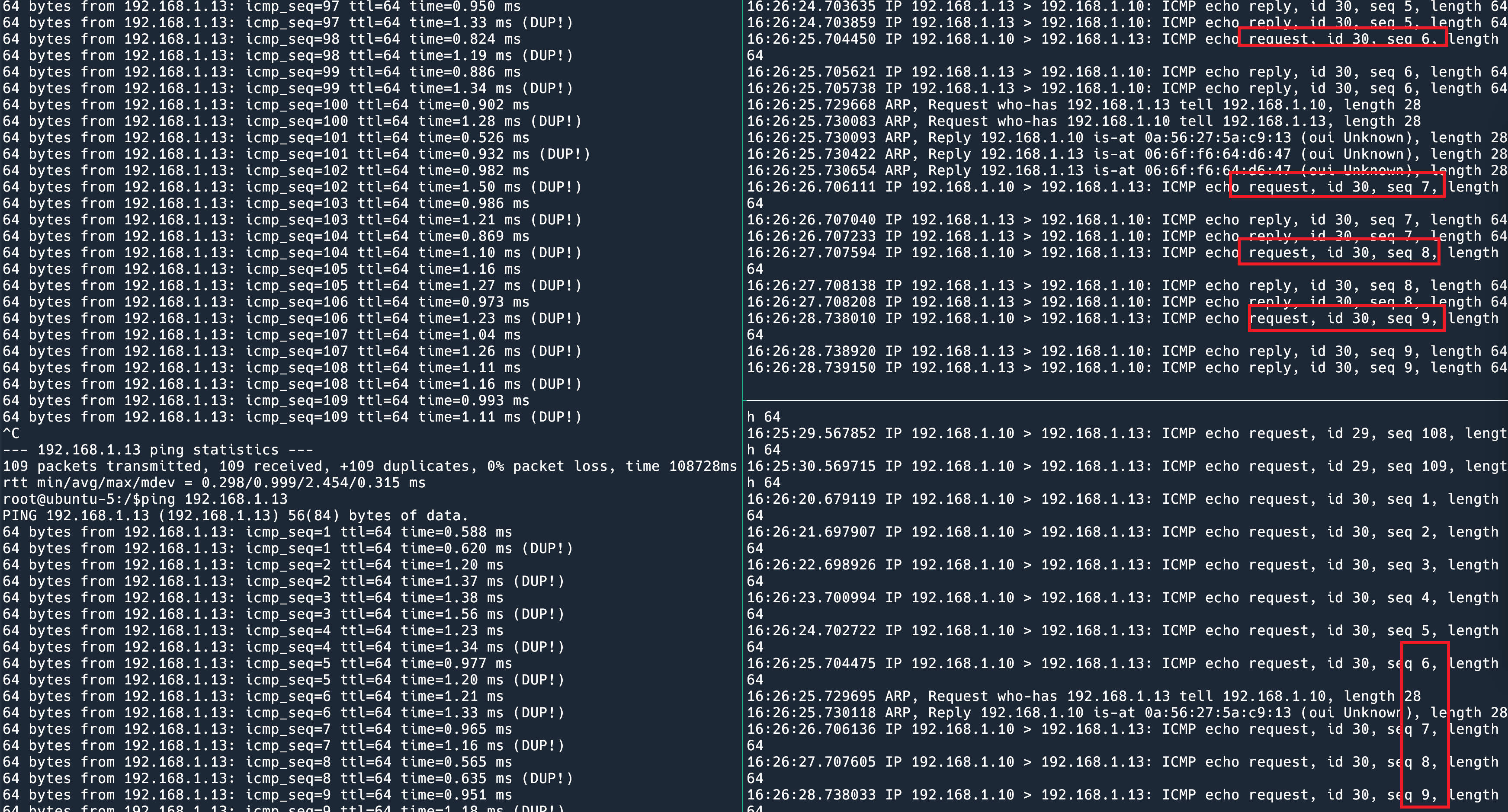
这个模式有什么用处呢?也许可以用于流量复制。
在这个模式下光有交换机的链路聚合还不行,因为包从 Linux 这里就复制 2 次了,所以如上图,每一个 ping request 都发出去 2 次,收到 2 个 reply。特殊的拓扑结构才会用到这种模式。
这篇就写到这里,写了这么久,我们的一个包还没找到从服务器传到交换机的「万无一失」的方案呢。别急,希望读者还觉得有趣,我们距离完美方案已经很近了。Until next time!
参考资料:
数据中心网络高可用技术系列
- 数据中心网络高可用技术:序
- 数据中心网络高可用技术之从服务器到交换机:active-backup
- 数据中心网络高可用技术之从服务器到交换机:balance-tlb 和 balance-alb
- 数据中心网络高可用技术之从服务器到交换机:链路聚合 (balance-xor, balance-rr, broadcast)
- 数据中心网络高可用技术之从服务器到交换机:802.3 ad
- 数据中心网络高可用技术之从交换机到交换机:MLAG, 堆叠技术
- 数据中心网络高可用技术之从服务器到网关:VRRP
- 数据中心网络高可用技术:ECMP
总算碰到生产环境中的场景了,目前我们机器使用的bond模式就是楼主即将要介绍的802.3 ad
好,马上就写下一篇!
嘿嘿好的,不过计算机网络使用技术专栏还更不哈哈
hello 如果没有交换机, 博主一般用什么来模拟交换机做实验
你好,我一般用 GNS3 来模拟