一个数据中心有一万台机器,如何将这些机器连接起来?
最直观的方式是在每一个 Rack (机柜)上放一个交换机 (TOR, Top-of-Rack),然后再用更大的交换机作为核心,把所有的 TOR 连接起来,组成一个集群。Google 在 2004 年使用的就是这种方式。
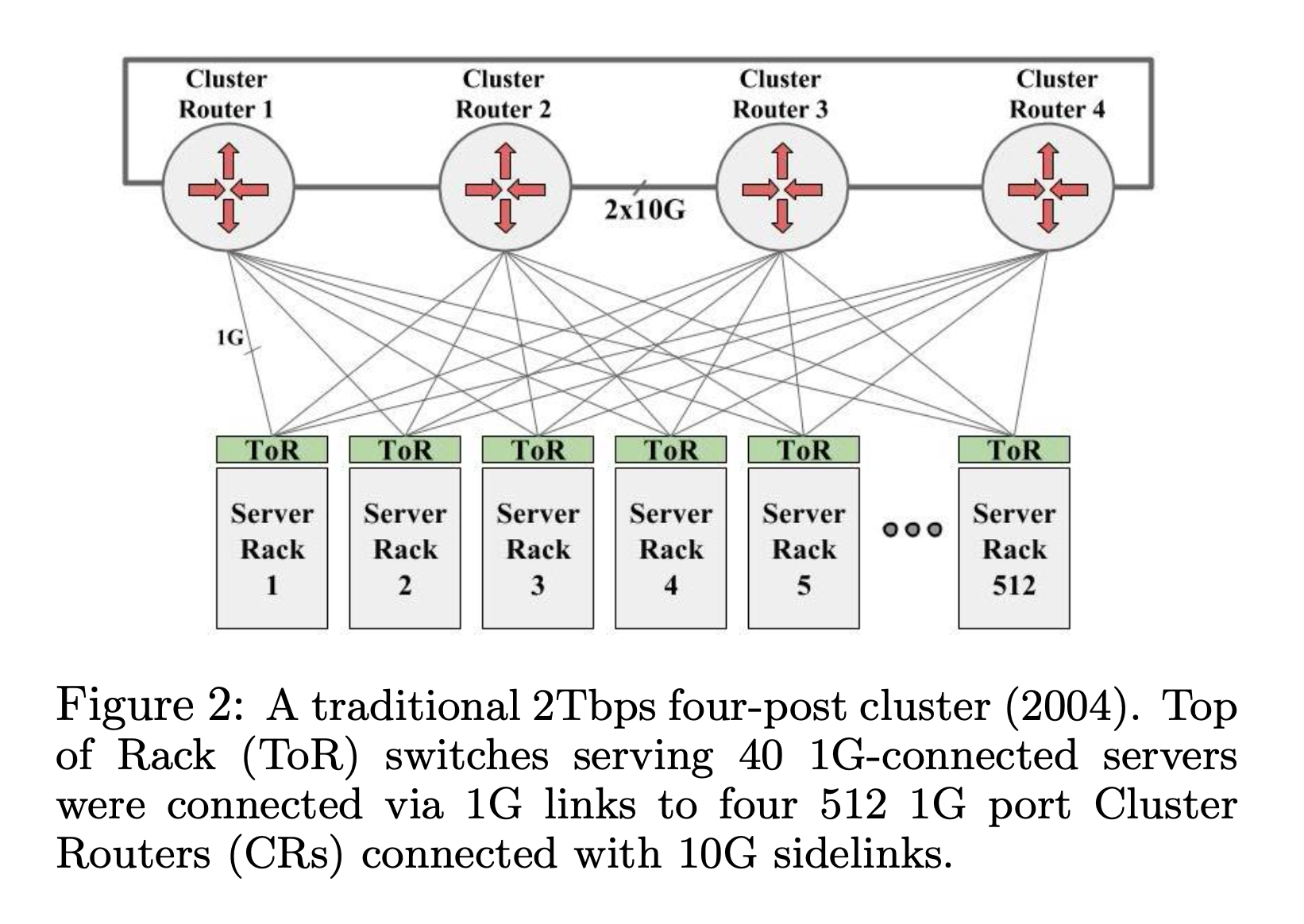
高端的集群交换机 (CR) 有 512 ports,那么每一个 CR 可以连接 512 个 TOR,4 个 CR 可以提供 512 * 4 ports, 每一个 TOR 使用两条线连接 CR,那么一共可以支持 512 * 4 / 2 = 1024 个 TOR。每一个 TOR 支持同 Rack 的 40 个 1RU 机器,一个最大支持 4万台机器 (1024 * 40 = 40960) 的集群就组成了。
虽然支持的机器数量足够了,但是这个集群存在很多问题。
问题1: 严重的 oversubscribe,TOR 下的机器之间有 1G 带宽,但是 TOR 上行只有 2G,跨越 CR 的带宽就更小了。
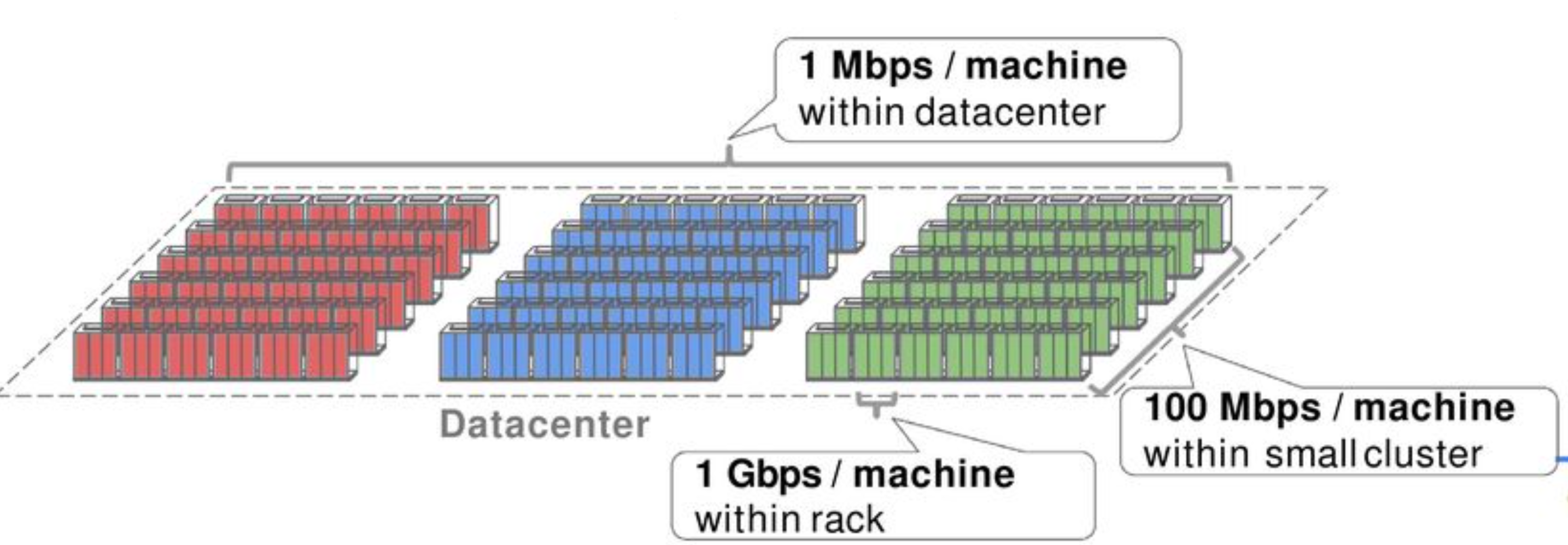
这对应用的扩容影响很大,如果应用之间有带宽需求,就必须使用复杂的调度算法,来让带宽需求高的应用尽可能部署在一起。Google 的业务中,搜索,广告需要大量的索引生成和存储,对东西向(服务器和服务器之间)的带宽要求越来越高,集群之间的带宽成为严重的瓶颈。
假设所有的机器点到点直接的带宽都是 1G,那应用就可以自由地扩容,调度算法就可以很简单,不必考虑 Locality,伸缩能力也更强。
问题2: 部署机构最好能够横夸更大的故障域。数据中心的电力是按照楼层部署的,如果电源失败,那么整层机器都会下线。所以,软件最好部署在集群的多个故障域来提高可用性。但是,这又和上面说的,要尽量把软件部署在一起来利用同集群内更高的带宽违背。这也证明了扁平化大网络的必要性。
问题3: 受集群交换机 CR 的限制。这个结构能够支持多大的规模,完全取决于集群交换机的带宽,端口数。集群交换机能做到多高端,就看思科、华为这种设备制造商的能耐了。
这些高端交换机通常成本高昂,因为这些设备的技术通常是从 ISP 下放的。高端交换机的需求大部分都在 ISP 那边,像 Google 这种数据中心规模的客户很少。以 ISP 为核心客户的交换机还有以下问题:1)交换机都是单个独立配置的,但在数据中心中都是静态的拓扑结构,大量交换机使用独立配置的方法很复杂;2)花高成本实现的 HA 对于数据中心来说不划算。WAN 线路非常昂贵,挂掉一个交换机的损失很大,所以在 ISP 这边花大成本实现 HA 是值得的。但是在数据中心,线路都是多路部署的,很便宜,交换机挂了影响也不大。这些高成本实现的高可用交换机就不划算了;3)ISP 交换机需要支持很多 feature 来满足路由 policy 的需要,也要支持很多路由协议,来满足不同的区域间路由。但是在数据中心,拓扑结构是有一个实体控制和设计的,而且是静态的,一种路由协议就足够了,所以 ISP 级的高端交换机上大部分的 feature,在数据中心是没有用武之地的。
除去这些缺点,还有一个最大的问题,就是 Google 需要的交换机在市场上买不到,无论花多少钱,都没有交换机产品能够支持 Google 的规模。
Google 把数据中心作为一个巨型计算机来使用1,把很多磁盘磁盘当作是一个大型的文件系统来用2,那么为什么不把很多个 Switch 当作一个 Switch 来用呢?
本文算是对 Google 在 2015 年发布的论文 Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network3 的精读,介绍了 Google 的数据中心网络 10 年间使用过的 5 代架构。
设计原则
Google 的数据中心网络设计有三个核心的原则,这三个原则也是和其他的数据中心很不一样的地方。
Clos 网络结构
Clos 是现在数据中心网络的主流设计,简单来说,它可以将多个芯片组合成一个交换机,交换机组合成更大的交换机,一组交换机相互连接,组合成一张网(fabric),从而支持数据中心级别的网络需求。
它能提供:
- 能够让所有的接入机器达到全双工线速的带宽;
- 大量的多路访问,可以让交换机故障的时候降低影响;
- 几乎可以无限扩展。(但实际上不会特别大,因为网络规模受限于控制面的扩展能力,以及为了缩小失败域);
具体的 Clos 是什么,以及实现,可以见下文讨论的第一代架构。
商用芯片
上文提到,小批量,大功能集,高可用的高端交换机不适用于数据中心。所以 Google 采用普通的、General purpose 的,技术已经比较成熟,大规模生产的商用芯片。
这样的好处是性价比高,可以用廉价的硬件打造适合数据中心的设备。新的芯片面世,可以直接升级设备,用上最新的芯片来支持最高的带宽(从下面 5 代架构的发展也可以看出来,几乎是新技术一出现,Google 就开始切换了)。能够快速平滑升级设备,Clos 架构也功不可没。
中心化的控制面
因为 Clos 架构的部署和运行需要大量的设备。如果像传统网络一样,对每一台设备登录,单独配置,就会有大量的维护工作,而且容易出错。
Google 的网络使用自己设计的控制面,所有的交换机设备都存储了整个网络的拓扑图,交换机上报自己和邻居之间的线路状态,给中心控制面,控制面下发这个链路的状态给所有的交换机。然后这些交换机基于自己存储的拓扑图和链路状态计算路由。
这个和传统的网络不同:传统的网络中,链路状态检测,拓扑图的发现(如果是 link-state routing 的话),以及 routing 的计算,都是在本地完成的。
和某一些 SDN 也不同,比如 Open vSwitch4 的 OpenFlow5,拓扑图和路由计算都是放在中心点的。
Google 的网络有点像介于两者之间。
五代网络机构
接下来就逐一介绍 Google 设计和使用过的五代网络架构。我们从第一代开始讨论,第一代的篇幅会稍微多一些,后续的就简单了,相同的原理就不需要再次介绍了。
一、Firehose1.0
Firehose 1.0 是 Google 的首个自研网络。设计目标是:
- 支持 1万 服务器的集群;
- 集群内任意一个服务器到另一个服务器的带宽可以达到 1Gbps;
那么原材料有什么呢——一个 8 个接口的卡(所谓的商用芯片)。但是使用 Clos 架构,我们可以将上万台服务器用 8 接口的卡连接起来。
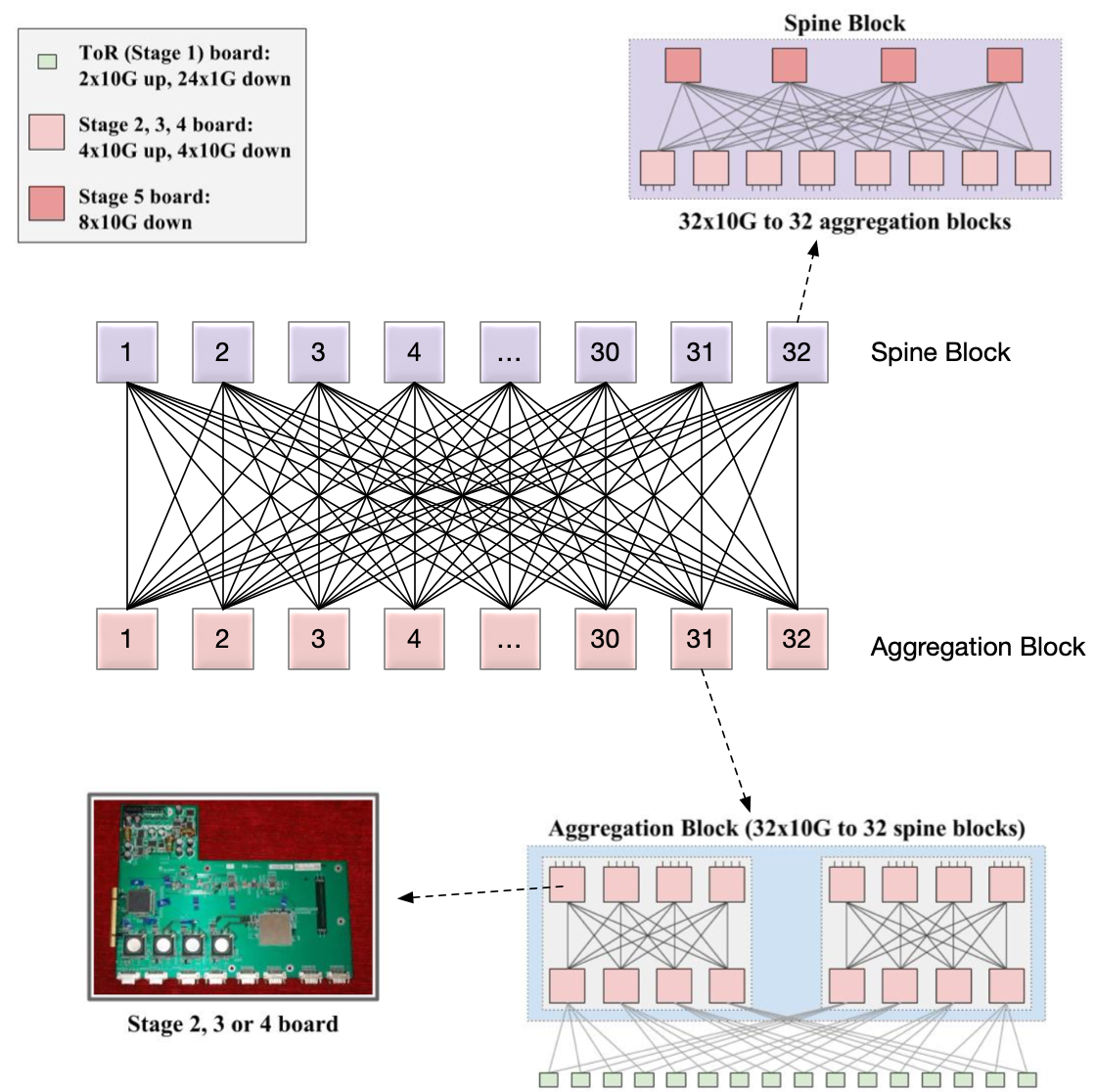
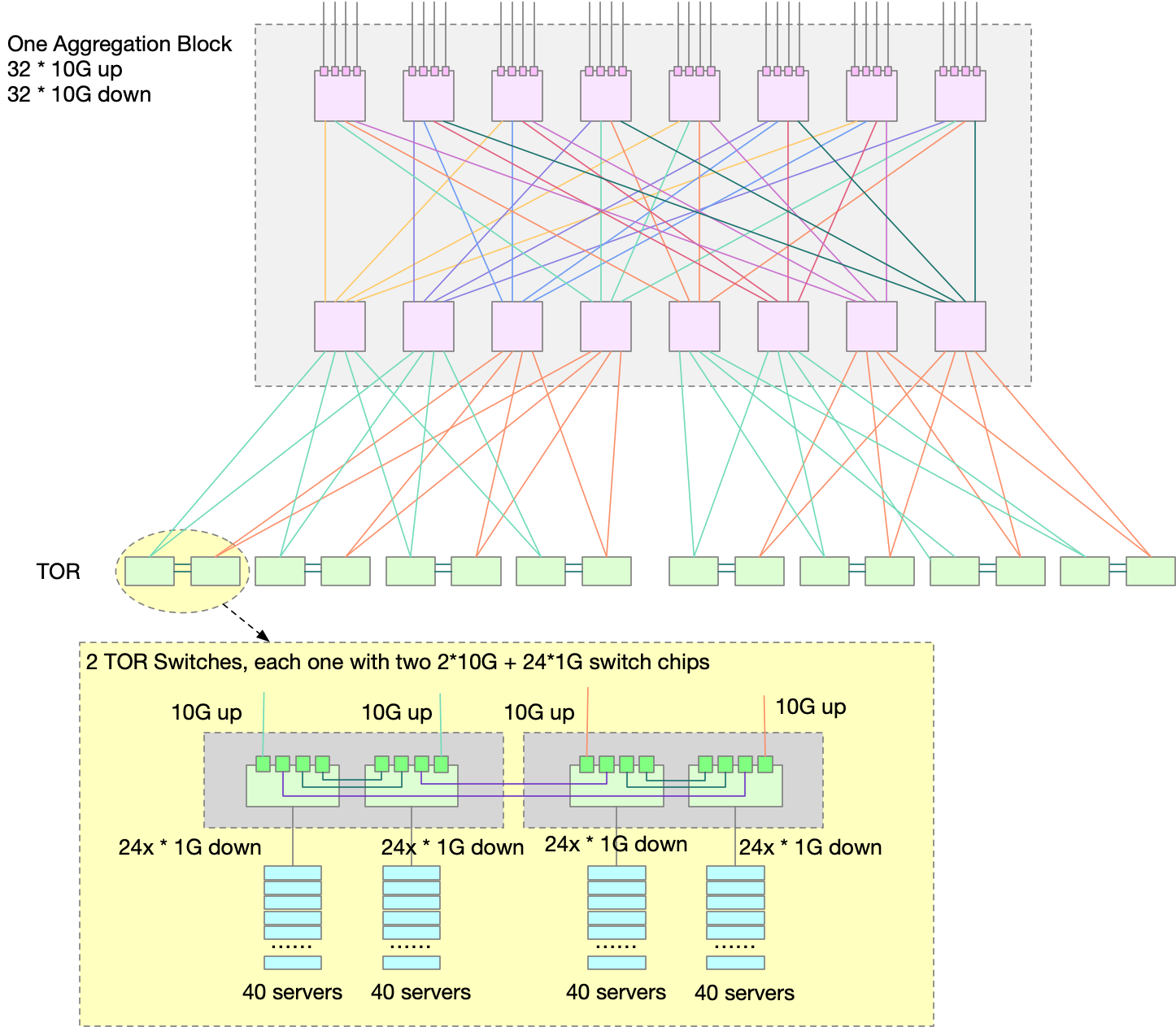
ToR Switch 使用的应该不是同样的 8x10G 卡,而是 2x10G up, 24x1Gdown. 每一个 ToR 向下连接同 Rack 的 20 台机器,向上使用两条线连接 Aggregation Block,每一条的带宽是 10G,这样,总下行和总上行是对等的,都是 20G,每一台机器都是 1Gbps 带宽。
再看 Aggregation Block。8个接口肯定是不够用的。但是我们可以使用 Clos 架构,用 8接口的卡组装起来一台接口更多的交换机。方法是:取4张卡在上,4张卡在下。上4张卡每一张里面使用4个接口,分别连接下四张卡。这样,一共8张卡,每张卡有4个接口内部连接使用,4个接口作为对外连接,相当于8张卡做了一个 4 * 8 * 10G,共 32 接口,每个接口带宽 10G 的「交换机」。这样的组合,在一个 Aggregation Block 里面可以放两组。如下图所示。
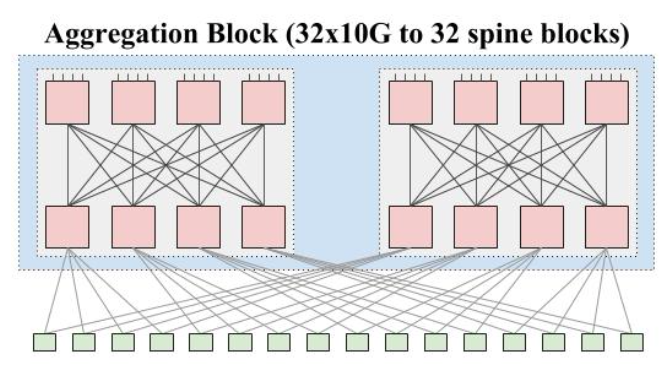
图中每一个粉红色的方块都表示一个 8x10G 网卡,如此连接,总共可以有 8网卡 x 4 x 10G = 32x10G up,同理 32x10G down。总体上,可以看作是一个 64x10G 的交换机了。在本文中,我们将它称作是一个 Aggregation Block。
其中,ToR 有 2x10G up,使用两条 10G 的 link 连接到 同一个 Aggregation Block 的两个模块中。每一个 Aggregation Block 有 32x10G 向下接口,每一个 ToR 用 2 条 link 连接到 Aggregation Block,向下总共可以连接 16 个 ToR。
一个 Aggregation Block 总共可以支持 16 ToR x 20 Server = 320 Servers, 并且所有服务器之间都是 1G 带宽的。
但是 320 台服务器肯定是不够的,我们需要添加多个 Aggregation Block。
我们可以继续使用 Clos 架构交换机的思想来设计一个交换机集群。现在,我们把一个 Aggregation Block 看作是一个整体,假设有 32 个 Aggregation Block,我们可以使用一个 32 口的交换机把这些 Aggregation Block 都连接起来。
怎么制作一个 32 接口的交换机呢?还是使用刚刚的方法。
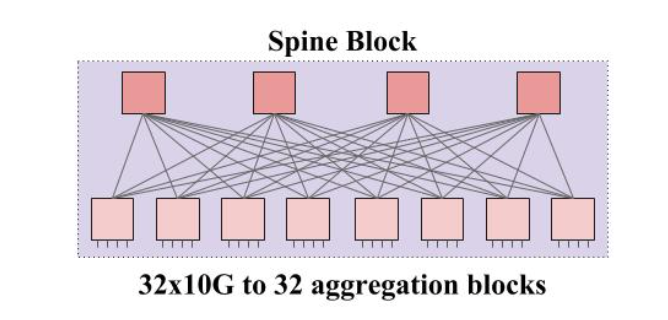
只不过这个交换机没有 Up link 了,都是 Down link。按照这个方法连接,一共可以提供 8×4 个 1G 接口。这样,一个 Spine Block 就可以把所有的 Aggregation Block 连接起来。缺点是跨 Aggregation Block 的带宽只有 1G。但是 Aggregation Block 向上有 32 个接口,所以我们总共可以使用 32 个 Spine Block,每一个 Spine Block 都连接所有的 Aggregation Block。
这样,32 个 Spine Block 提供的带宽就是 32x32x1G, 所有 Aggregation Block 向上的带宽也是 32x32x1G,所有的服务器,无论是同 Aggregation Block 还是跨 Block 都有 1G 带宽了。最多支持 32 个 Aggregation Block,一个集群最多就可以提供 320×32=10240 Servers.
把 32 个 Spine Block 加 32 个 Aggregation Block 看作是一个整体,就相当于是一个有 512 个接口的交换机。这个连接方式就是 Clos 架构,要注意的是,每一个 Spine 都连接了所有的 Aggregation Block,但是 Spine 之间是没有连接的。
这种架构的好处是:
- 减少环路的出现;
- 网络比较扁平。服务器到服务器的跳数是可以预期的;
- Multi-Path。跨 Aggregation Block 之间的路径非常丰富,可以选择 32 个 Spine 中的任意一个;
- 支持水平扩展和缩容。比如,如果跨 Aggregation Block 如果不需要这么多的带宽,可以只部署 16 个 Spine,这样的话,Aggregation Block 的带宽就有 1:2 的 Oversubscription;
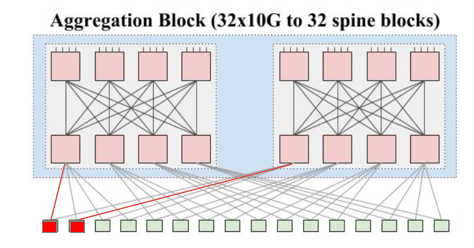
这个架构存在一个问题,就是 ToR 到 Aggregation Block 的线路不够多样。本质上,每一个 ToR 只用两条线连接到逻辑上的两组 Fabric(Fabric 就是指的交换网,在这里,指的是 Aggregation Block 中两个 Fabric 中的一个)。
如果两个红色的 ToR 分别有一个 Link down,那么这两个 ToR 下的服务器彼此之间就无法连通了。但是这两个 ToR 下的机器都可以和其他的机器连通。
此时,作为第一代架构,Google 还没有制造自己的交换机的经验。但是 Google 有丰富的服务器制作和维护经验。
当你手里握着一把锤子,看什么都像钉子。
所以 Google 尝试用服务器来制作交换机:把 8 接口的卡通过 PCI6 接口插到服务器上。这样有很多其他问题,服务器不像交换机一样,可以长时间稳定运行。服务器需要升级和维护的次数更加频繁,并且启动时间更长。作为 ToR 的服务器问题更大,因为 ToR 一旦下线维护,意味着这个 ToR 下的服务器都下线了。
从本文后面对 Google 自研网络协议、控制面等的投入也可以看出,除了网络架构,相关的配置套也非常重要。所以 Firehose 1.0 作为起步阶段,遇到很多问题,比如 Clos 架构类似 Full mesh,需要大量的接线工作,电力稳定性问题,高可用问题,等等。Firehose 1.0 并没有实际投入到生产中,不过作为一个实验性的尝试,已经给 Google 带来了很多宝贵经验。
二、Firehose 1.1
第二代架构叫做 Firehose 1.1,从名字也可以看出,它是 Firehose 1.0 的升级版,解决了很多问题,真正地投入生产了。
FH1.1 不再使用服务器做交换机的思路,而是直接定制了机箱专门用于路由器,机箱可以支持最多 6 个线卡,使用专门的单板机 (Single-Board Com- puter, SBC) 来通过 PCI 控制线卡。
一个 Aggregation Block 还是由 16 个线卡组成,所以至少需要 3 个机箱,分别放 6、6、4 个线卡。正好可以放在一个 Rack 中。如下图所示。
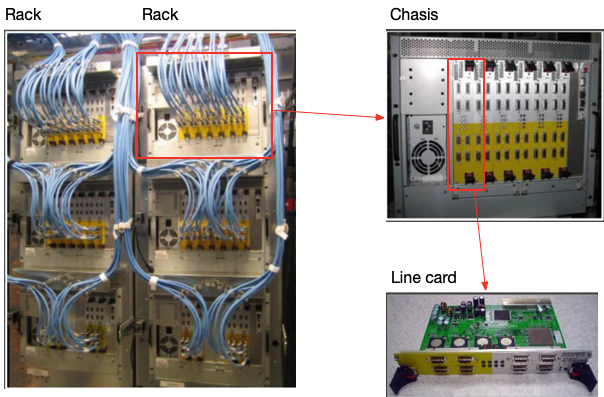
机箱内部没有连接卡的背板,所有的卡还是通过机箱外的线路相互连接的。线卡也采用了和 1.0 不同的硬件。SBC 通过带外管理 (out-of-band) 来和 CPN 网络 (Control Plane Network) 连接, CPN 网络在下文还会详细讨论。
Spine Block 的拓扑结构和 1.0 大致一样。
ToR 的设计和之前不同。现在 ToR 使用的卡是 4x10G+24x1G,其中:
- 4x10G 向下连接最多 40 台服务器;
- 2x10G 向上连接 Aggregation Block;
- 每一个 ToR 都是用两个卡,两个卡使用 2x10G 互相连接;
这样,一个 ToR 就可以有 4x10G up, 48x1G down. 在 1.1 的结构中,ToR 是两两一组搭配在一起的,意味着 4x10G up 中,有 2x10G 是连接 Aggregation Block,2x10G 连接的是邻居 ToR。综上,每两个 ToR 可以向下连接 80 台服务器,4x10G 连接到 Aggregation Block。up:down 会有 1:2 的 oversubscrib。到这里可能比较复杂了,读者可以和 Aggregation Block 一起参考下图理解。
Aggregation Block 与 1.0 有些许不同。还是 16 个卡组成一个 Aggregation Block,但是不再像 1.0 一样,8个卡组成一个全连接,每个 Aggregation Block 是两组 Fabric。而是 16 个卡直接组成一个 Fabric。接线就有些复杂了,我这里画了一个彩色的图。可以看的稍加清晰一些。
1.0 中提到的同一个 Aggregation 的 2 个 ToR link down 的场景,在 1.1 的架构下,依然有多条可达的路线。可以有任意两条 link 同时 down 掉。
服务的迁移
这是第一次从传统 Four-post 架构到自研的 Clos 架构迁移。所以需要有快速回滚机制。
迁移的方式就是每一个 ToR 预留 4 个 1G接口,用于连接 4 个之前的商用交换机。因为之前 Four-post 架构用的就是 1G 的口,所以不会占用新架构的 10G up link。这样如果有问题的话,可以一键迁移回到旧的架构。
三、Watchtower
Firehose 1.1 架构最主要的问题就是线太多了,从逻辑架构图就可以看出来,Rack 内的线,Spine- Aggregation 的 full mesh 线,都非常多。第三代架构主要解决了这个问题。
内部连线优化
第一个优化的地方就是减少 Rack 内的连线。Firehose 1.1 是没有背板去连接线卡的,卡之间都是通过网线在外部连接。Watchtower 添加了背板(backplane),在机箱内部就连接多个交换芯片。这样,网线使用就少了很多。交换芯片也进行了升级,现在使用的是 16x10G 芯片。

每一个 watchtower (左上角)一共有8个线卡组成,每一个线卡有 3 个交换芯片,连接逻辑图是左下角。可以看到,每一个线卡可以暴露 8 up 和 8 down,一共可以提供 64 up 和 64 down,总共高达 128x10G 的带宽。右图是 4 个 watcher tower 机箱,每一个只占用半个 Rack。对比 Firehose 1.1 的架构,占用 1 个 Rack 的 Aggregation Block 提供的带宽是 64x10G。Watchtower 是 Rack 减少一倍,能力强了一倍。
这个逻辑线路连线有个细节:之前的 Aggregation Block 是两层的架构,为什么到这里使用三层呢?中间这一层,即没有增加带宽,也没有增加接口数量,用处是什么呢?
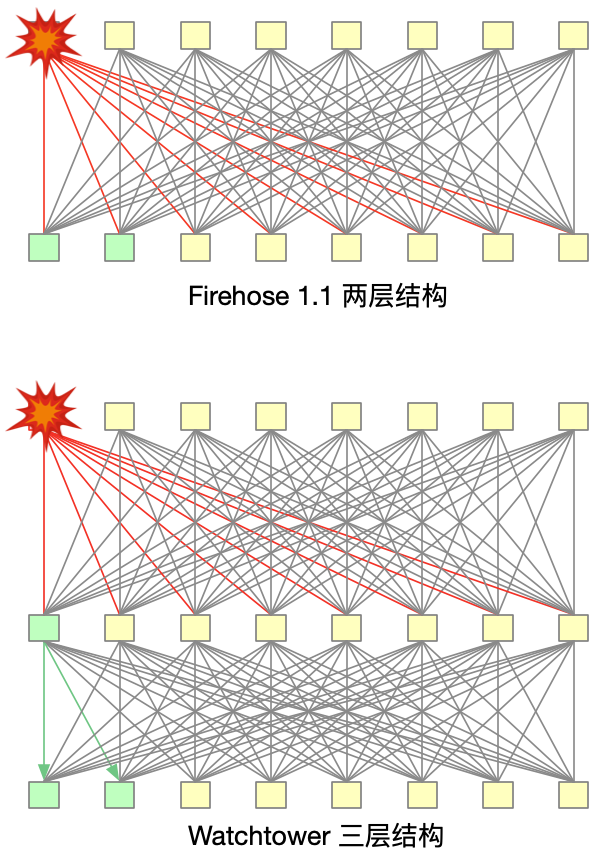
在两层架构,假设有一个交换芯片的流量已经被打满了,那么下面的芯片会有 1/8 的流量被 Blocking 了,是一种 Blocking 的架构。
在三层架构中,如果发生这种情况,下面的芯片依然可以通过中间一层来交换,没有 Blocking 的地方,所以是一种 Nonblocking 架构。
外部连线优化:Fiber bundling
外面无法避免的连线,通过 Fiber bundling 来优化连线。
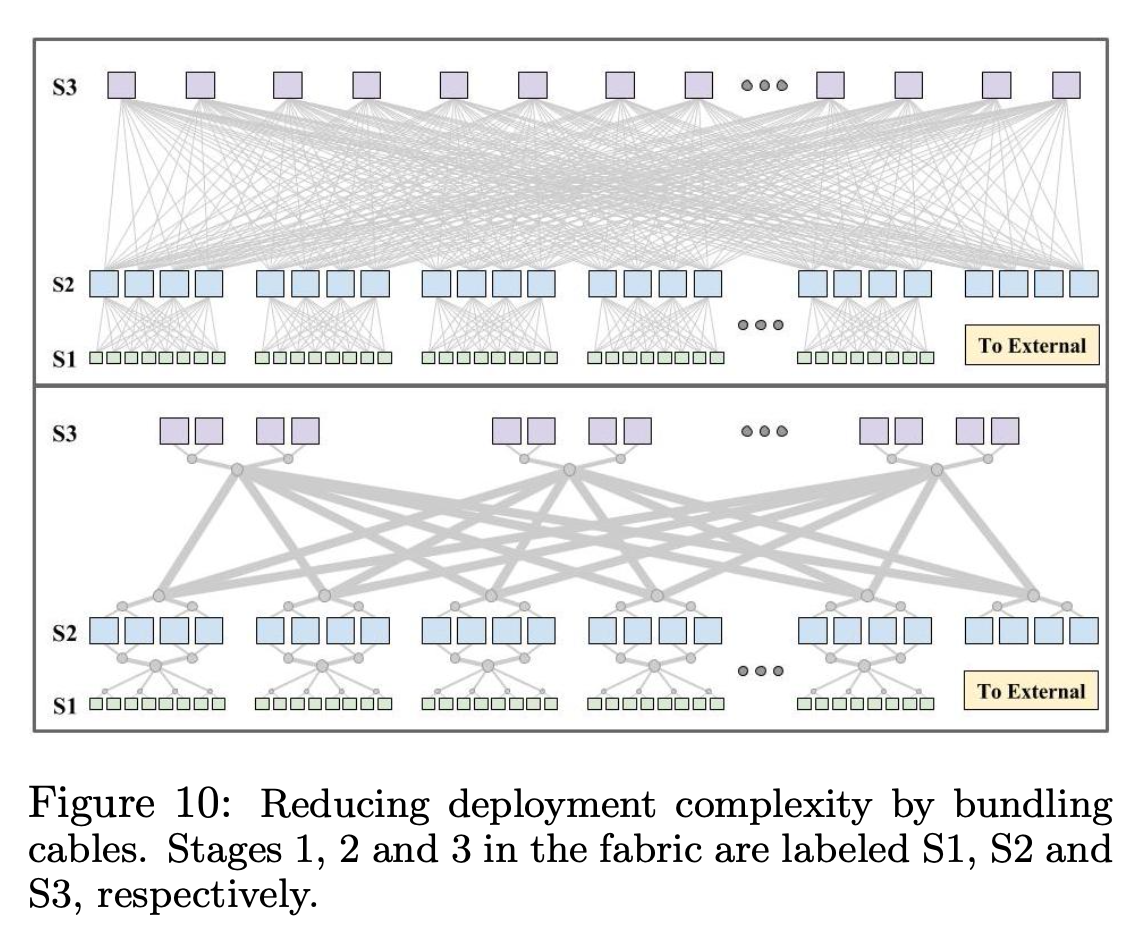
Fiber bundling 有两个好处:
- 部署更加简单;
- 生产成本更低,大约可以节省 40% 的费用;
成本节省的方法
前面提到,Clos 架构的一个好处是可以根据实际带宽需要部署,集群不需要那么高的带宽的时候,可以通过部署更少的成本来节省带宽。
方式主要有两种:A) 节省第二层 Aggregation Block 的交换机数量;B) 节省第三层 Spine Block 的交换机数量。如下图所示。
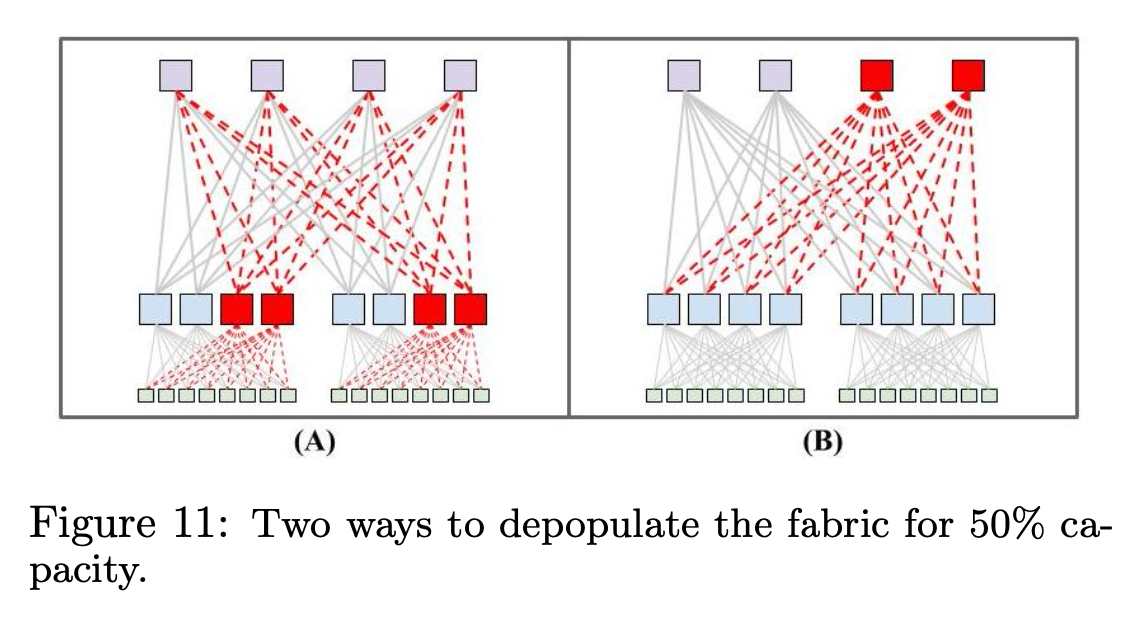
方案 A 和 B 能够提供的总带宽是一样的,都是最大的 50%。
A 方案好处:
- 可以比 B 方案节省多一倍的交换机数量和线材;
B 方案的好处:
- 在 ToR 层的 burst 带宽是 A 方案的两倍;
在 Watchtower 中,使用的是 A 方案,最大化节省成本。在后续的 Saturn 和 Jupiter 网络中,使用的是 B 方案,因为随着网络规模的扩大,部署 Spine Block 的成本相比 Aggregation Block 更高,更高的 ToR burst 带宽带来的收益也更高。
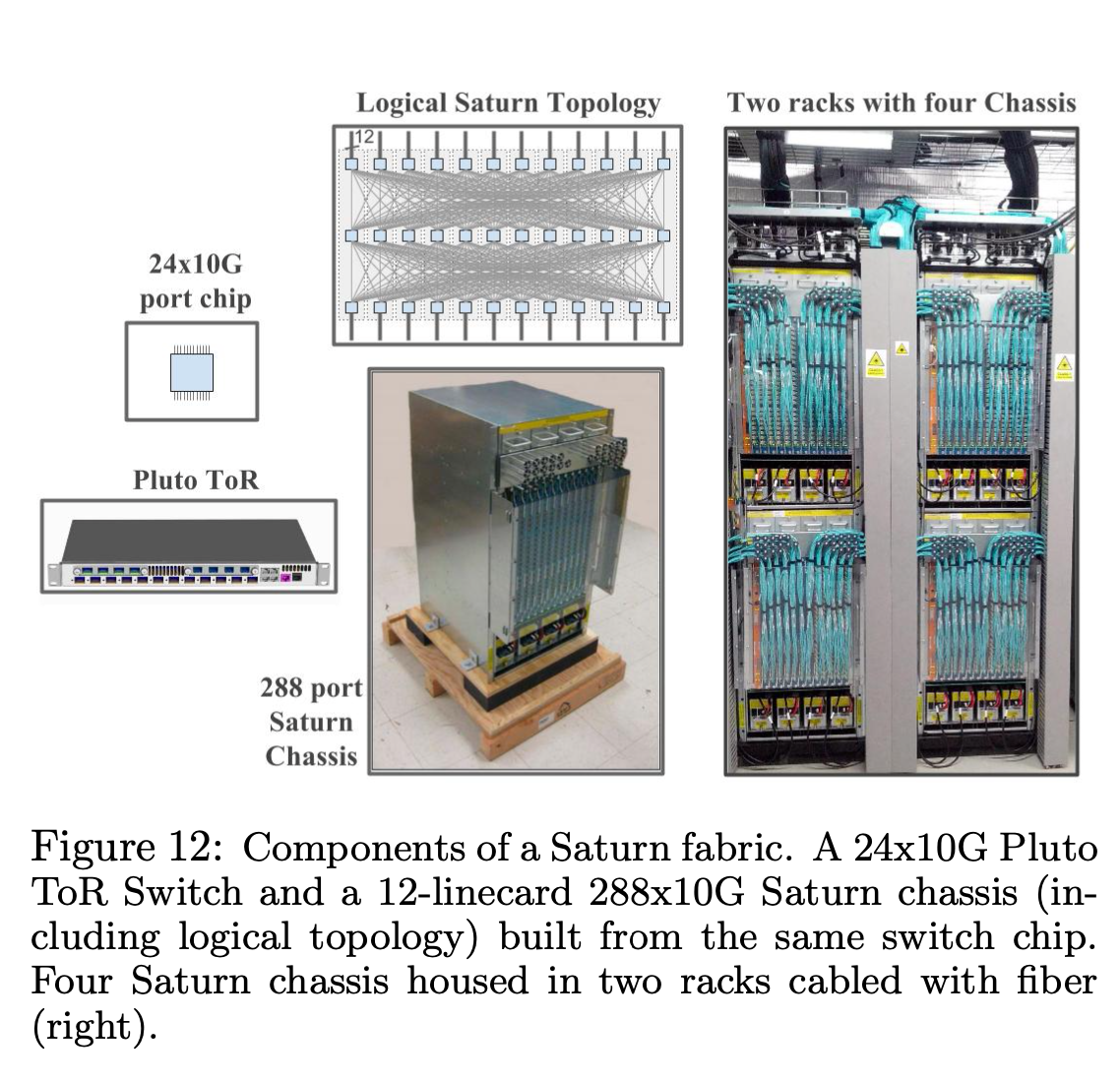
四、Saturn
Saturn 主要的变化是,提供的带宽更高,集群的规模可以更大。
Saturn 用的 Merchant silicon 规格是 24x10G,使用的机箱可以支持 12 个线卡,机箱也是 half rack,相比于前一代,总体带宽从 128x10G 上升到了 288x10G,都是 Nonblocking。
ToR 换成了 Pluto single-chip ToR switch,向上可以提供 4x10G 带宽,向下可以连接 2x20G 到服务器。对带宽有更高需求的服务器,支持配置成 8x10G up, 16x10G down. 每台机器最大带宽 5G.
服务器最大 burst 带宽可以到 10G。
五、Jupiter
Merchant Silicon 的规模已经来到了 40G,下一代网络的设计的目的有两个:使用最新的 Merchant Silicon,设计一个 6 倍于上一代的网络,得到一个前所未有的巨大资源池;应对更加频繁的网络设备维护工作。
在这么大的规模下,网络结构就需要考虑物理建筑的结构了。
之前的设计中的部署单元有两种方式:Firehose 是机箱内部没有连接,都是走外面接线连接线卡;Watchtower 和 Saturn 是通过内部背板连接线卡。
Jupiter 采用了中间的方式,一个部署单元叫做 Centauri 机箱,是一个 4 个 RU (Rack Unit,占用 4 个 Rack 单位)的机箱,可以插 2 个线卡,每一个线卡可以有两个交换芯片,16x40G,总共就是 2 line card x 2 switch chips x 16x40G = 64x40G. 每一个线卡都有单独的 CPU 控制。每一个口都可以配置成 4x10G 模式,或者 40G 模式。机箱内部没有背板连接。
Centauri 因为内部没有连线,所以非常灵活。Jupiter 是通过不同的接线方式组合多个 Centauri 来做 ToR, Spine 和 Aggregation。
下面是 Jupiter 的总体架构图,可以看到,其实 Centauri 出现在了不同的角色中。
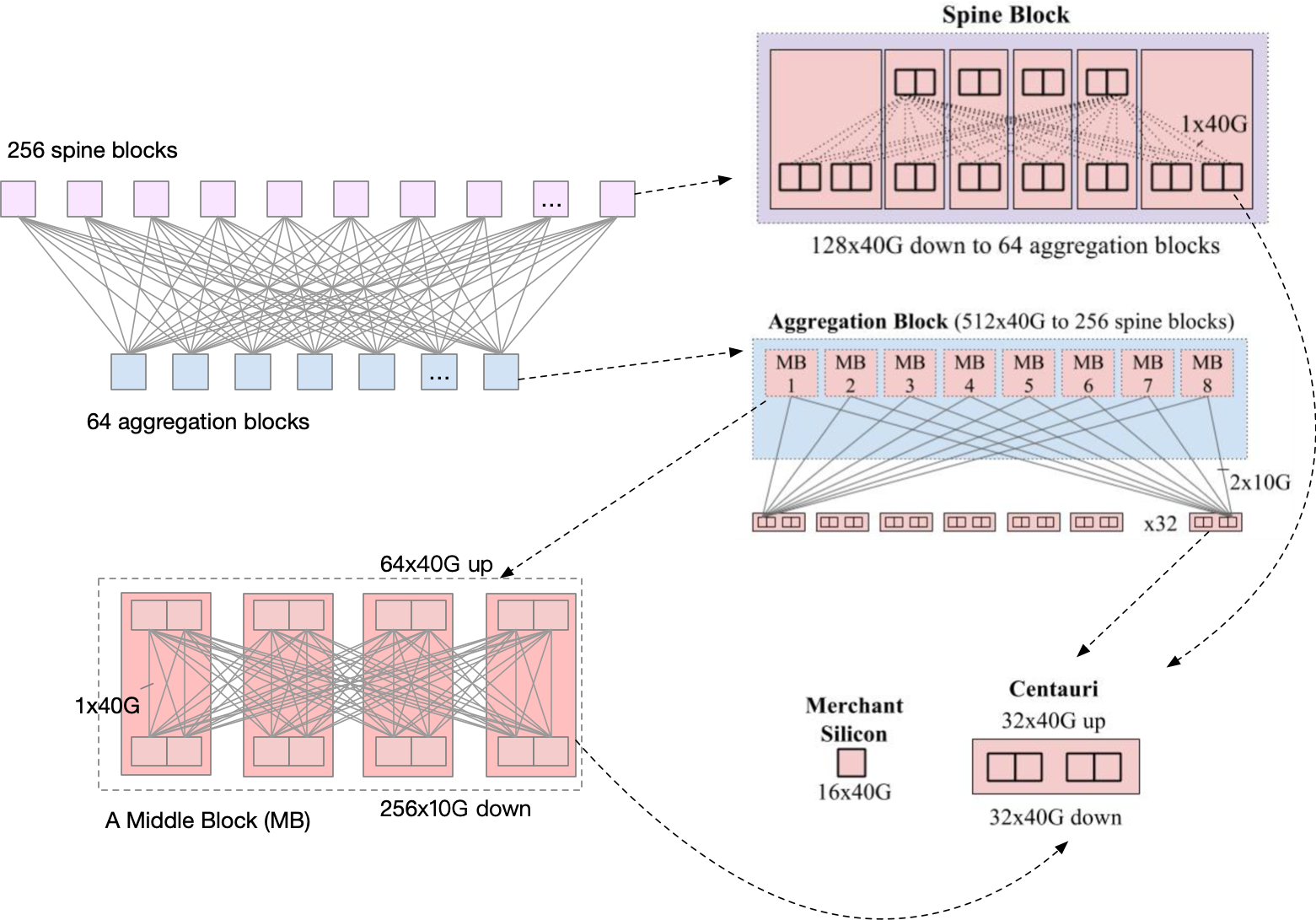
先看 ToR。因为 Centauri 是没有内部连线的,所以作为 ToR 的时候,4 个芯片可以当作 4 个交换机来看待。每一个芯片是 16x10G up, 48x10G down,每一个芯片下的服务器都是一个单独的 subnet。服务器可以 burst 到 40G 带宽。
每一个 ToR 的 16x10G up 去连接 8 个 Middle Block(MB), 和每一个 MB 之间的连接都是双线 10G。
MB 其实就是 4 个 Centauri 的组合,连线方式见图,可以提供 64x40G up, 256x10G down.
Spine Block 也是 Centauri 的组合,使用了 6 台,连线方式见图。可以提供 128x40G down,连接 64 个 Aggregation Block,每一个 Aggregation Block 使用双线 40G 连接 Spine Block 来提供冗余。
可以看到,Aggregation Block 最大是有 512x40G,但是实际只使用了 256x40G,如果有需要,可以通过增加 Spine Block 的数量来提高带宽。
集群的总带宽的计算方法:一个 Spine Block 可以提供 128x40G, 一共有 256 个 Spine Block,总带宽达 64x128x40G= ~1.3Pbps.

图中是两个 Rack,一共 8 个 MB。
以上就是 Google 的 5 代网络了,但是还有其他的问题需要解决。以上介绍的都是一个网络集群是如何连接的,但是一个网络集群是不够的,Google 需要多个网络集群,那么多个集群间如何连接呢?以及集群通向外网的网络如何连接呢?
跨集群(Cluster)连接
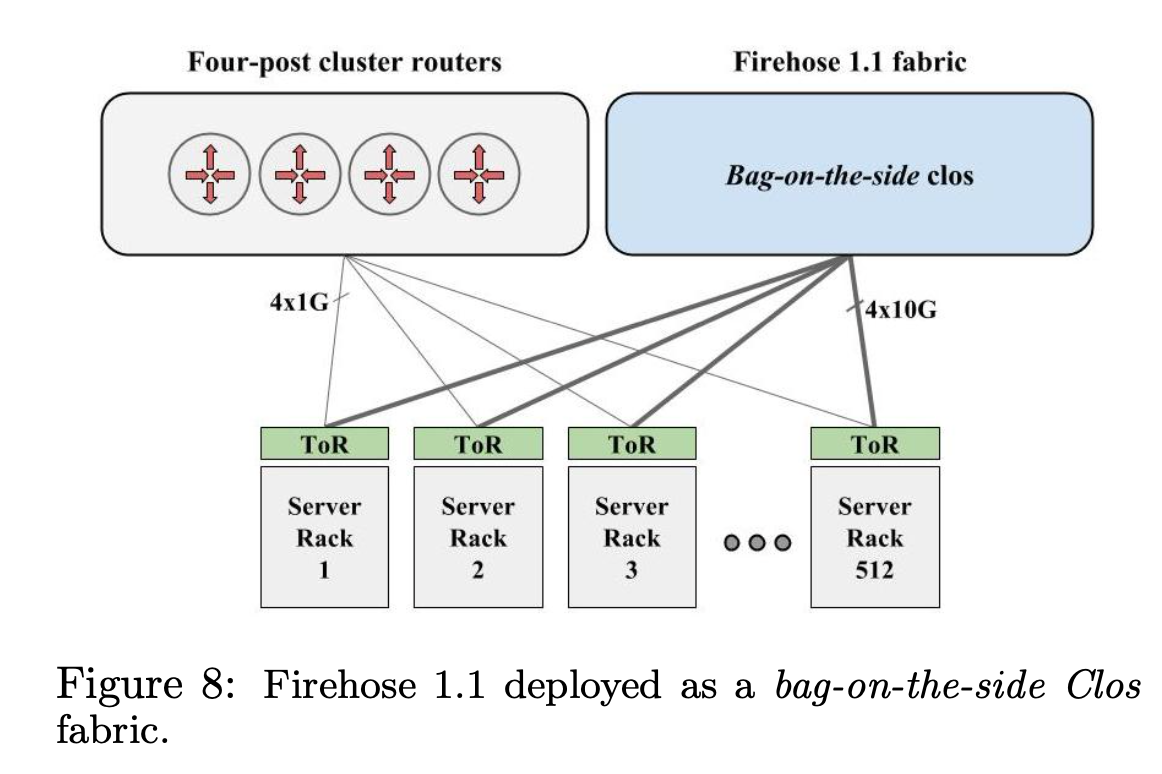
在 Watchtower 刚开始部署的时候,出于安全的考虑,还是 bag-on-the-side 模式部署的。
在这个模式下,Cluster 内部的流量,走 fabric,如果要跨 Cluster,还是要走 Cluster Router。
但是这样部署的复杂度高,成本也高,性能差。尤其是如果在 Cluster 之间拷贝数据或者迁移索引文件,会受到 Cluster Router 的带宽限制。
所以,第一步就是彻底下线掉 Cluster Router。方法就是把跨集群的 Cluster Border Router(CBR) 直接连接到 fabric 上,跨 Cluster 可以直接通过 fabric 去 CBR。
把 CBR 连接到 fabric 的方式有 4 种:
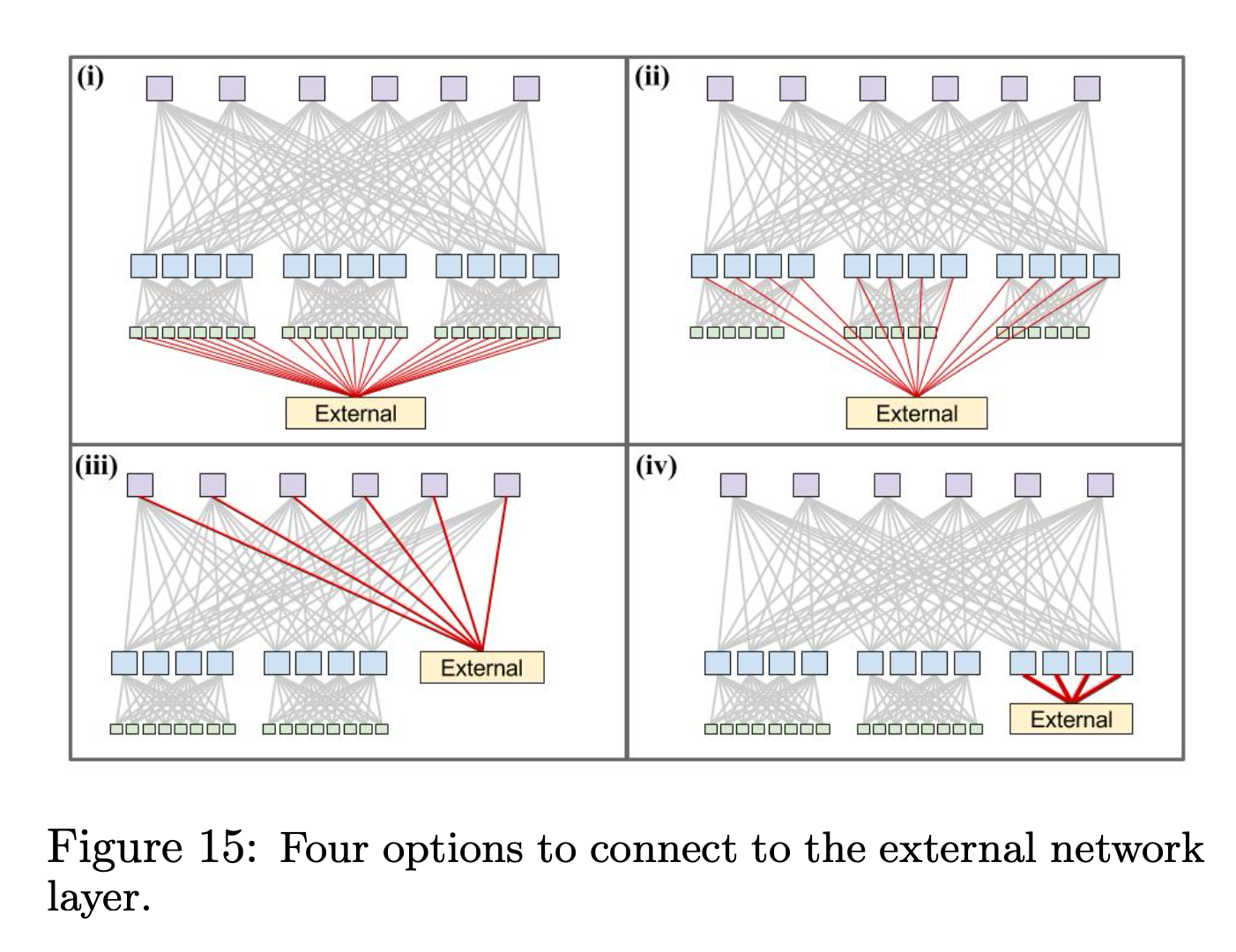
- 从 ToR 拿出来几条线去连接 CBR;
- 从 Aggregation Block 拿出来几条线去连接 CBR;
- 从 Spine Block 拿出来几条线去连接 CBR;
- 将 External 网络当作 Cluster 内部的一个 Aggregation Block,让它作为 fabric 的一个 Block;
其中,(1) 和 bag-on-the-side 的部署模式是类似的, (1) 和 (2) 都无法提高 burst 带宽。因为流量不走 fabric,server -> ToR -> External, ToR -> External 线路是固定的,server -> ToR -> Aggregation Block -> External, 有一定的 burst 能力,但是最多用上同 Aggregation Block 到 External 的带宽。
(3) 和 (4) 的 burst 带宽最高,可以 burst 到全部到 External 的线路。
Google 最后选的方案是 (4), 因为 (4) 可以限制爆炸半径,连接到 External 的网络聚合在一个 Aggregation Block 下面。可以最大减少集群外配置失误而引起的影响。
实际运行中,到集群外带宽大约是 fabric 带宽的 10% 左右,所以会分配大概 1-3 个 Aggregation Block 用于连接到 External。这些 Aggregation Block 和其他连接 ToR 的 Aggregation Block 并没有什么区别,只不过连接的不是 ToR,而是连接 CBR。
CBR 和集群外交换机的连接用 LAG7 连接,运行标准的 eBGP8 协议,然后将学习到的默认路由重分发9到 Cluster 内,集群内路由协议使用的是 Google 自己研发的 IGP,叫 Firepath,后文还会详细介绍。
集群间(inter-cluster)的路由
在数据中心园区中,有多个机房大楼,每一个大楼有多个 Cluster。得益于上面的退役 CR,CBR 直连 fabric 项目,现在 CBR 可以在跨集群间提供超大的带宽,Watchtower 的 Aggregation Block 可以提供 2.56Tbps 带宽,Saturn 可以提供 5.76Tbps。但是再往外面的网路,用的设备就还是商用设备。所以基础设施的任务调度上,考虑到物理距离以及网络成本,要考虑 campus-level 和 building-level 的 locality。
下一步,就是把这部分网络设备也替换成自研的,用来在集群间提供更大的带宽。
核心的思想还是 Clos 架构的 fabric。
首先用路由器为单位,多个路由器组合成一个 Freedome Blocks (FDB), 每一个 FDB 的南向端口是北向端口的 8 倍;
FDB 中有两个角色:
- Freedome Border Router (FBR) 负责北向端口,连接下一级;
- Freedome Edge Router (FER) 负责南向端口,连接 Cluster;
FDB 每一个 Block 内部使用 iBGP,北向端口和南向端口都是用 eBGP 作路由。
基于 FDB 为部署单位,四个 FDB 组成一个 CFD (Campus Freedome) 南向连接 FDB,北向连接 WAN。是一个园区最核心的网络单元,是进出园区的经过组件。
四个 FDB 组成一个 DFD (Datacenter Freedome) 南向连接 Cluster,北向连接园区网 CFD。
到这里我们就可以把一整个园区的图都画出来了,从 WAN 入 CFD,然后进入 DFD,最后通过 CBR 到 Cluster 内部。如下图所示。
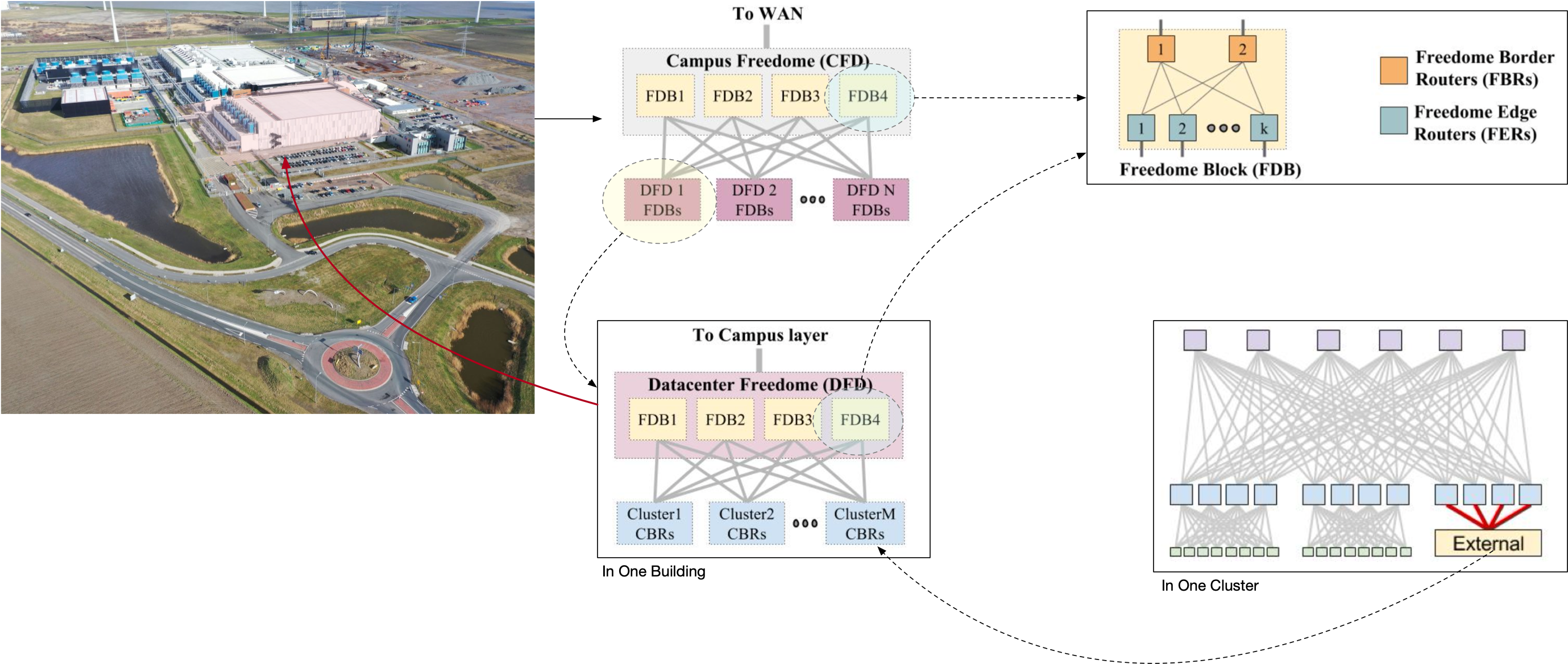
其中,由 4 个 FDB 组成的 CFD 和 DFD,都可以随时损失 25% 的最大带宽进行下线 FDB 维护,非常方便。
有关网络架构方面,我们基本上就讨论完了, 可以看到,Clos 应用在了园区网,集群网,交换机内部,可谓是无处不在。如此庞大的网络,就是由一颗颗交换芯片组成的。
这么大的网络,传统的网络管理方式已经无法工作了,Google 重新设计的自己的控制面和路由协议。
软件部分
在设计控制面的时候,可以选择使用传统的 OSPF/IS-IS/BGP 这种分布式路由协议,优点是已经经过了几十年的验证,足够「正确」;另一种选择是根据自己的需求从头开始设计一个路由协议和控制面。
Google 选择设计自己的路由协议和控制面。原因如下:
- 这部分协议(在当时)对 ECMP10 并没有很好地支持。可以看到,在 Clos 架构中,服务器到服务器有大量的等价的多路可以选择,如果没有 ECMP,可以说这个架构就没有用处了;
- 高质量的路由协议都是闭源的,当时没有高质量的开源路由协议可以用。因为对于像 Cisco 这种网络设备厂商来说,路由协议的软件实现是价值非常大的资产。既然要自己实现,那么为什么不实现一个新的呢?另外,在 Google 设计的交换机上,从线卡接收控制面的包然后让协议进程来处理,要对硬件作出很多修改;
- 在 Clos 的网络架构中,交换机和网线的数量非常庞大。传统路由协议大多是基于 IP Multicast 的,比如 OSPF11,在这么大的 fabric 中,Multicast 可能带来非常大的 overhead;
- 在这么多节点中,用传统分布式的方式来对每一台交换机分别配置,会是非常大的工作量。尤其是对于 BGP 这么复杂的协议来说;
数据中心网络的特点是巨量的多路径(Clos 架构),静态拓扑,每一个交换机角色是根据它的位置来确定的。所以 Google 重新设计了一个 Control Plane network (CPN), 中心化的控制面,通过带外连接 (out-of-band) 控制交换机。
每一个交换机都知道整个网络的拓扑结构。交换机会上报 Link 的状态到控制面,控制面把这个状态变更发送到所有其他的交换机,交换机收到 Link 状态变更之后,加上自己知道的拓扑结构,来重新计算路由。
这个设计本质上是把整个网络当作是一个由上万个接口的交换机。中心化的控制面,也是受之前的分布式存储系统设计的启发。
除了 Jupiter,Google 的 B4 WAN12 也是用了这种控制面的设计方式。
路由
Google 的自研路由协议叫 Firepath,是基于现代 SDN 设计。工作方式如下:
- 所有的交换机都提前配置了预期的拓扑,交换机邻居之间和对等学习真实的配置,和 link 的状态;
- 交换机会把自己视角下的链路发送给中心节点,叫做 Firepath master;
- 中心节点会把全局的链路状态发送给所有的交换机;
- 交换机根据全局拓扑和链路状态来计算转发表;
Firepath master 之间通过选举协议来实现多点部署,提高可用性。
在 fabric 的 edge 节点,运行 BGP 和外部交换路由,然后把通过 BGP 学习到的路由重分发到 Firepath。
Neighbor Discovery
Clos 网络依赖大量的连线,物理接线在实施的时候很容易出现错误,一开始接线对了,后续维护的时候(比如更换线卡)还可能接错。接线错误可能会造成路由环路13。
如果 Link down 了或者错误率过高,交换机也需要发现,并且上报。
Google 开发了 Neighbor Discovery (ND) 来解决这个问题。有点像开放的 LLDP (Link Layer Discovery Protocol) 协议和 Cisco 专有的 CDP (Cisco Discovery Protocol) 协议。但是 ND 做的事情更多。路由器通过自己存储的拓扑结构和自己的 ID,从拓扑中找到自己的位置,得出自己应该连接的 peer ID,然后通过 ND 去得到真实的 peer ID 进行比较,如果不一样,就是接错线了。这样就会在早起发现机房实施中的错误。
交换机内嵌的 Interface Manager(IFM) 模块可以判断 link 状态,只有 PHY UP 和 ND UP 才算是 UP,才会开始参与路由。线卡上有 LED 会展示 ND 的状态,可以辅助定位问题。ND 的状态通过监控系统上报,在监控面板上也可以看到。ND 通过类似 keepalive 的机制不断检测对端的状态,如果对方宕机或者出现 Link 问题,就会从路由中隔离掉。
Firepath
线来看一下网络的划分。二层和三层的分界线在 ToR,ToR 以上运行的是三层,跑的内部 IGP 协议,叫做 Firepath。ToR 以下是一个二层的广播域。连接到同一个 ToR 的服务器在同一个广播域中。ToR 分配到的子网是连续的,并且和 Aggregation Block 对齐,这样,网络的转发表可以比较小。
拓扑中所有链路和节点的状态是中心化的,路由计算依赖两个主要的组件:
- 每一个路由器中都运行一个 Firepath 客户端;
- 一组 Firepath master 运行在 spine block 的一个 subnet 中;
在初次启动的时候,每一个 client 都会加载预先配置好的拓扑图,包含整个 fabric,叫做 cluster config。每一个客户端然后收集本地端口状态,发送给 master。master 基于此创建 Link State Database (LSD),基于全局 ID 递增的方式标识状态变化,然后通过 UDP/IP 走 CPN 发送给路由器。
初始化结束之后,后续只会推送增量变更的部分。
整个网络的 LSD 可以放到一个 64KB 的 payload 中。
当收到 LSD 更新,每一个客户端会重新计算路由,然后修改本地的(硬件)转发表。master 节点会限制发给 client 的 LSD 更新的频率,避免 overload client。
master 和客户端之间还有 keepalive 机制,master 会定期发送自己的 master ID 和 LSD version number,如果 client 发现与此失去同步,就会重新请求 full LSD,相当于重新开始初始化。
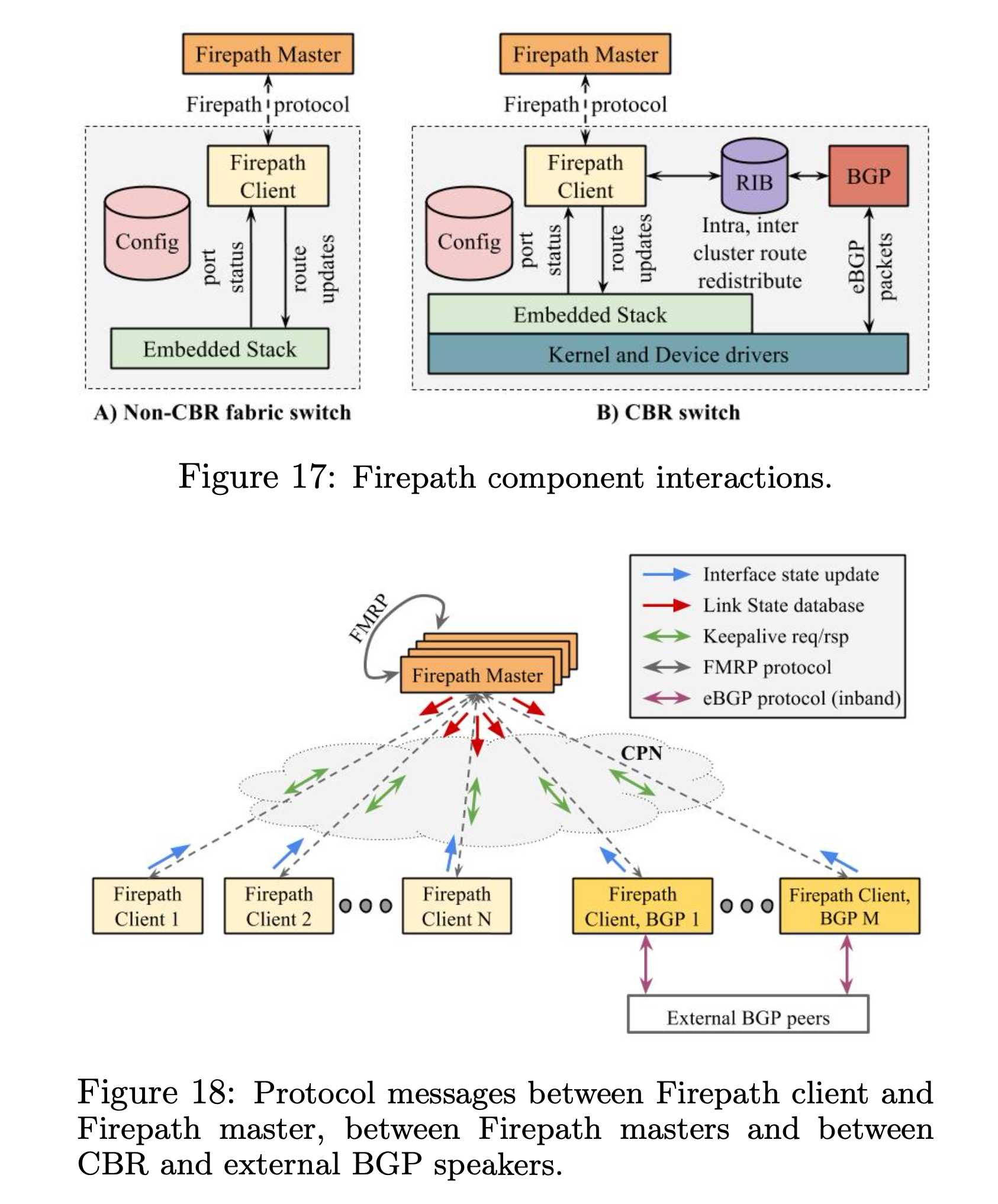
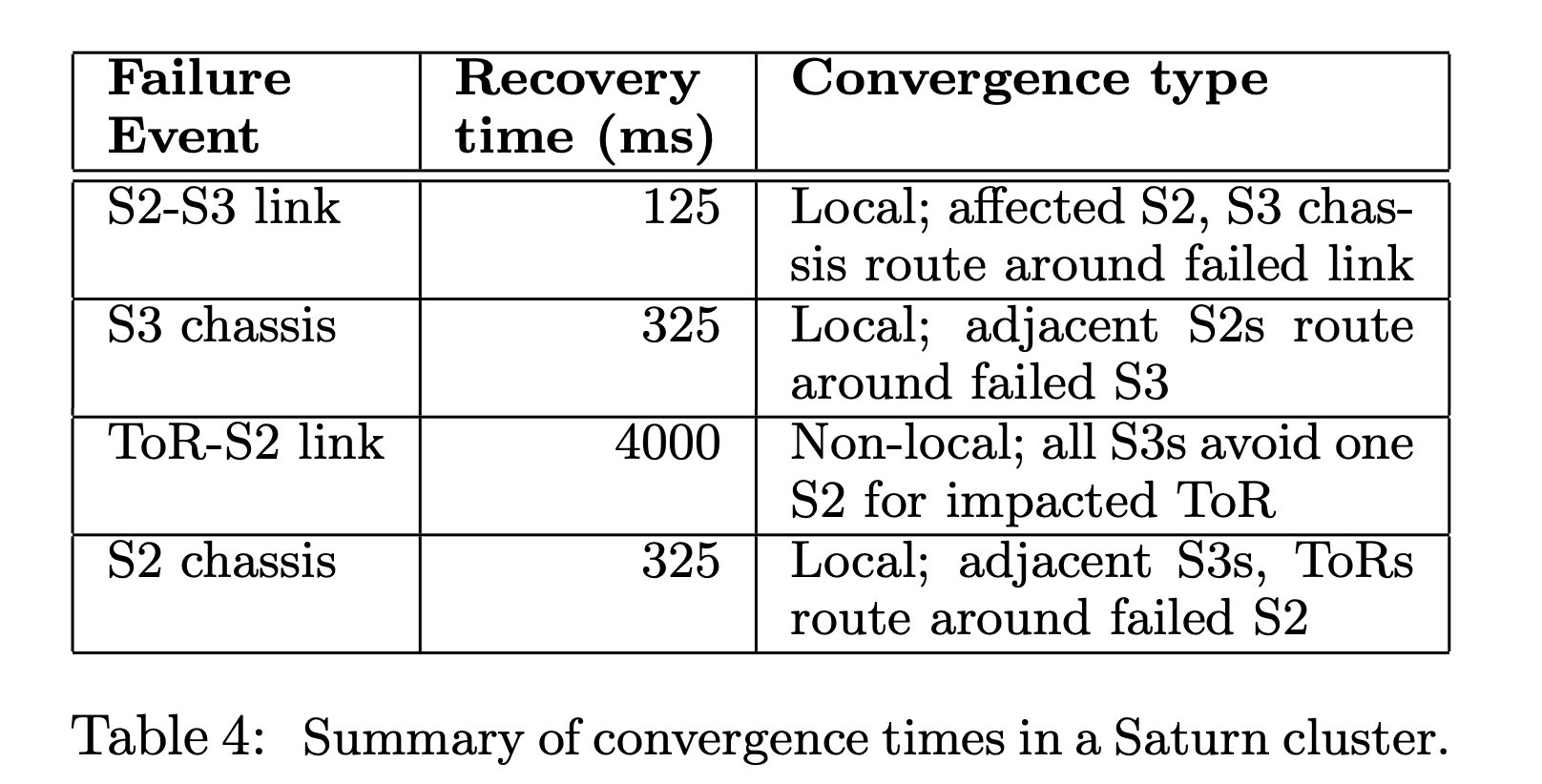
当出现故障的时候,因为大部分的故障点,都是可以本地恢复的,所以恢复速度非常快。本地恢复以为着不需要通知更多的下一级节点来恢复。比如 S3(就是 Spine Block)挂了,那么在 S2(Aggregation Block)的路由中摘除这个 S3 就可以了。一个反例是当 ToR 挂了,首先 S2 要摘除这个 ToR,然后 S3 要摘除路由不通的 S2,核心问题是 ToR 到 S2 的线路不够多。但是相比于传统路由,也都已经很快了。在传统路由,当故障发生的时候,路由要一层一层传下去,整体上恢复速度很慢。而中心化的控制面,交换机告诉 Firepath master,Firepath master 告诉所有其他的交换机,就可以了。
Firepath master 之间的选举协议
为了实现 Firepath master 节点的高可用,Google 部署多个 Firepath masters 作为一组,master 之间通过 Firepath Master Redundancy Protocol (FMRP) 来做 master 选举和保活,这一组叫做 CPN FMRP multicast group。
当启动的时候,master 进入 Init 状态,发送 LSD,然后等待其他的 master。如果从其他的 master 收到 LSD 更新,就进入 backup 状态,否则,就进入 electing 状态开始选举。选举是广播 election 请求到所有的 master 候选。拥有最高 LSD 版本的节点会胜出。胜出的 master 就进入 master 状态。这个过程其实和之前博客中讨论过的 VRRP (HSRP)14 很像。
FMRP 的 master 选举是 sticky 的,意味着如果所有的节点都健康,那么上一个 master 也会在下一次的选举成为 master,所以即使错误配置的 master 节点加入,也不会引起集群震荡。在极端情况下,可能出现多个 master,这时候需要监控发现,人工介入解决。
CBR 与外部的连接
CBR 需要用 eBGP 与外部网络连接。这部分工作主要有两方面:需要和外部运行 eBGP 路由协议;需要作为边界网关,在 EGP 和 IGP 之间同步 (redistribute) 路由。
eBGP 路由是运行在 inband 的,即控制面的 eBGP 包和数据包使用相同的网线。这里是通过嵌入式的 IO 引擎分离出来控制面和数据面,控制面的包拿到之后通过 netdev 交给 eBGP 协议处理。
CBR 上运行着一个代理进程,负责将内部 Firepath 路由写到 BGP RIB 中,也把 BGP RIB 的路由发布到 Firepath 中。但是这里不是做的真正的路由学习,而是做了一个非常简单的假设:对于内部集群,直接发布一个 /0 路由,即所有的出集群流量全部发给 CBR,对外,发布 Cluster prefix 到 BGP 中,即假设 CBR 可以连通集群内部的任意角落。得益于 Clos 高可用性,让路由数据变得很少。
配置管理
整个集群网络自上到下作为一个静态的 fabric 看待,而不是自下到上单独配置每一个设备。整体配置的参数很少,只有一些必要配置,减少了复杂性。
配置的生成是一个 pipeline,输入必要参数:spine 数量,IP 前缀,ToR 和 rack 列表,就可以自动生成多份配置:
- 简化的物料账单列表给供应链团队采购;
- rack 分布细节,cable bundling 和 port mapping,给 DC 人员做实施;
- CPN 设计和交换机地址;
- 监控数据库更新;
- 交换机用的静态配置;
- 整体物理拓扑图;
同一份配置会下发到所有的交换机,非常简单。缺点是当有配置需要变更的时候,需要变更所有的交换机,但是这么做的频率并不高。
交换机管理
Google 不像其他公司一样,区分网络设备和服务器来分开管理,而是将网络设备也当成服务器来管理。比如系统镜像管理和安装,大规模监控,syslog 收集,alerting 等等。
交换机很多程序需要同时 apply 配置,所以配置变更实现了类似二阶段提交的功能。
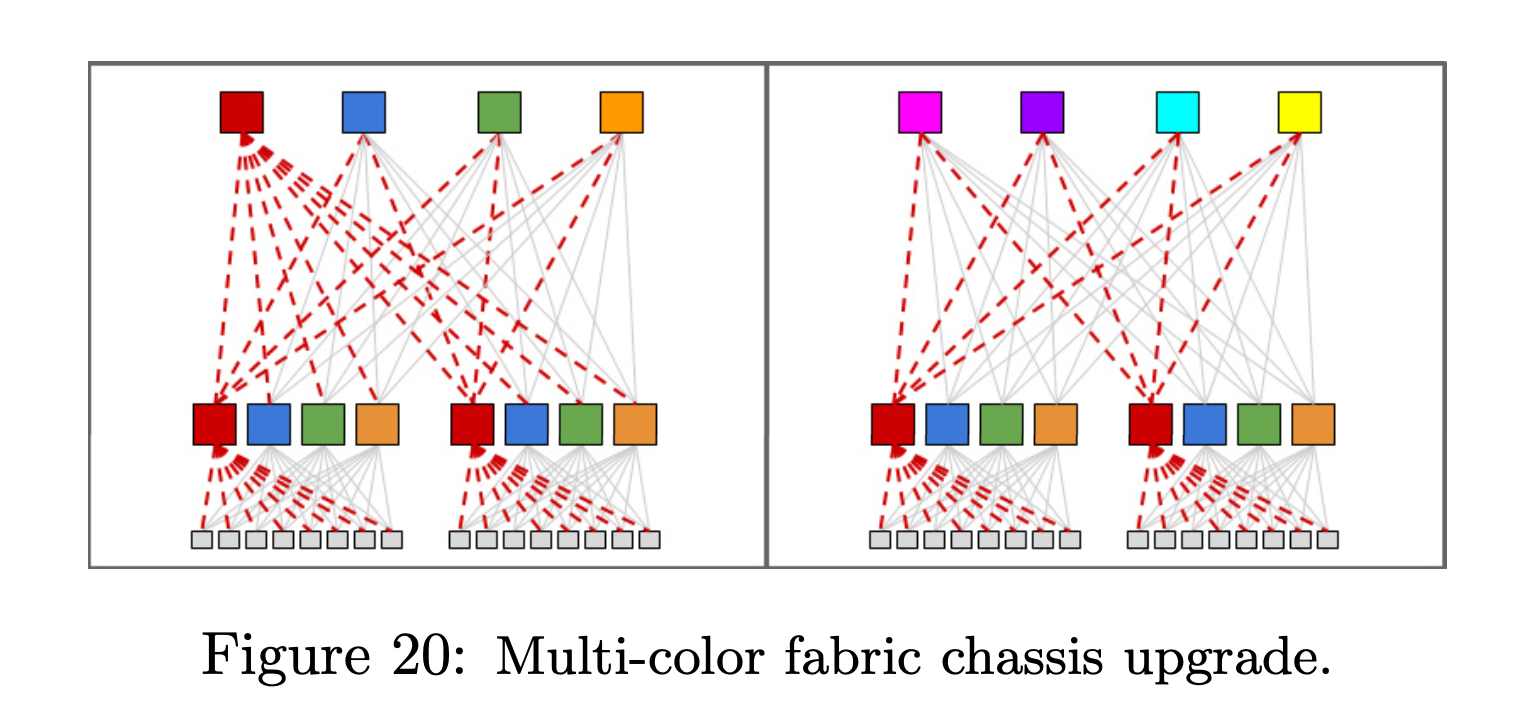
Fabric 管理
商用高端交换机都支持原地不停机升级,是一个非常牛逼(昂贵)的 Feature。但得益于 Clos 高可用的特点,这些不需要啦。升级完全可以先主要 drain 掉设备,牺牲掉 56.25% (75%*75%) 的带宽(下图左)来直接升级 1/4 的设备。图右的方式损失的带宽更小,但是花的时间更多。
经验部分
Fabric Congestion
Fabric 使用率大概 25% 的时候会发生丢包。拥塞主要的原因:
- 短时间的突发流量;
- Google 使用的 merchant silicon 只有很小的 buffer;
- 为了节省成本而故意设计上的 oversubscribe;
- 流量变化的时候,hash 算法不完善;
优化方法如下:
- 通过硬件配置,让丢包发生的时候,根据 QoS 来优先丢弃优先级低的包;
- 调整 Host 的 TCP 拥塞窗口,避免塞满交换机的 buffer;
- 在早期的 fabric 中,如果 oversubscribed 的 link 出现 overload,就会在 ToR 上停止一些 link,来限制下面的带宽;
- 使用 Explicit Congestion Notification (ECN) 让交换机和服务器配合进行拥塞控制;
- 监控 oversubscribed link 的使用情况,按需扩容带宽;
- 优化 hash 算法;
故障
文章中介绍了3个故障案例。
第一个最有意思,还记得上面提到过 ND 和路由计算之间的关系吗?在一次数据中心发生断电重启之后,整个 fabric 的 ND 都在检查链路状态上报,所有的交换机都在计算路由,交换机的 CPU 并不是很强,因为路由本身的设计就比较小。所以大量的路由计算耗光了 CPU,导致交换机无法响应邻居 ND 的 keepalive,邻居认为自己挂了,于是又上报链路状态,带来了更多的计算量。导致集群处于雪崩状态,永远无法恢复。
优化方法是增加类似场景的 stress test,重新检查所有代码中和时间有关的参数,考虑它们在最坏的情况下有没有问题,最后提高 ND 在 CPU 的优先级。
第二个是 CPN 网络,链路错误率很高甚至挂掉,但是链路健康检查并不是很完善,导致 CPN 网络中还认为链路是健康的。
第三个是配置文件 apply 的时候出现了两个进程同时修改配置的问题。
总结
到这里,这篇论文就结束了。论文很慷慨地介绍了 Google 的物理网络架构,软件管理,路由协议,内容颇多。虽然是 2015 年发布的内容了, 但是放在今天来看,依然非常先进。
PS 这篇文章开始,博客用脚注的方式放链接,而不是文字加超链接,这样可以把链接放到同一个地方去,方便读者逐个查看。不知道读者有何反馈?
引用资料汇总
- The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines, Second Edition ↩︎
- The Google File System, Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung ↩︎
- Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network ↩︎
- Open vSwitch ↩︎
- OpenFlow Wikipedia ↩︎
- Peripheral Component Interconnect ↩︎
- 数据中心网络高可用技术之从服务器到交换机:802.3 ad,以及 数据中心网络高可用技术之从服务器到交换机:链路聚合 (balance-xor, balance-rr, broadcast) ↩︎
- Border Gateway Protocol ↩︎
- Route redistribution ↩︎
- ECMP 在之前的博客中提到多次,可以参考四层负载均衡漫谈中的介绍 ↩︎
- Open Shortest Path First 路由协议 ↩︎
- B4: experience with a globally-deployed software defined wan ↩︎
- 网络中的环路和防环技术 ↩︎
- 数据中心网络高可用技术之从服务器到网关:首跳冗余协议 VRRP ↩︎
终于等到你
Blocking 和 nonblocking 的架构可以展开讲讲,为什么三层架构是 nonblocking 的。
这个一开始我也没理解, 请教了一下同事。现在理解就是3层的时候,当一个芯片打满了,不会 block 其他芯片之间的连接,就是 nonblocking 的吧。
最早的 Clos 网络对 non-blocking 的定义来自 1953 年 Clos 发表的 paper,“The requirements for such a system are that the crosspoints be kept at a minimum and yet be able to permit the establishment of as many simultaneous connections through the system as possible”。这时候 Clos 网络还是用于 telephone switching systems,也就是电话交换系统。
那个年代的电话交换系统需要为每一次通话分配一条独占的物理链路,non-blocking 的定义是交换系统两侧的设备可以随时向另一侧的某个设备打电话,交换系统一定能分配出一条物理线路出来给这次通话使用,且不会用到其他设备正在占用的线路。
放在计算机网络里类比的话,我的理解是 non-blocking 意味着只要没有硬件故障,接入这个交换网络的设备即使把所有接入的 NIC 打满 line rate 也不会发生拥塞,可以完全承载住。
– https://ieeexplore.ieee.org/document/6770468
– https://en.wikipedia.org/wiki/Clos_network
按照这么说的话,2层的话,上面接口打满,下面就有几率 block,3层就不会了。
每一个 Aggregation Block 有 32x1G 向下接口
—-
这里我感觉应该是32*10G?
是的,感谢,已经改正。
现在是 25 年了 https://cloud.google.com/blog/products/networking/speed-scale-reliability-25-years-of-data-center-networking
无法追赶了,连 10年前的 Jupiter 都造不出来。